[PYTHON] 7 conseils pour éviter la frustration en A3C après avoir obtenu son diplôme DQN
introduction
Quand j'ai essayé de reproduire moi-même A3C en regardant de nombreux codes sur le net et en lisant la littérature, j'ai senti qu'il y avait trop de pièges et que l'obscurité était profonde, donc je serai le dernier à rester coincé dans une telle obscurité. Par conséquent, j'ai essayé de résumer les endroits auxquels j'étais accro sous forme de conseils Si vous envisagez d'écrire votre propre code et de faire de votre mieux, j'espère que vous ne vous retrouverez pas dans l'obscurité même un peu après avoir vu cela.
Qu'est-ce que A3C
A3C est une abréviation d'Asynchronous Advantage Actor-Critic, annoncée par Deep Mind, une société familière avec DQN en 2016.
――Fast: l'apprentissage progresse rapidement car l'apprentissage se fait en utilisant Asynchronous et Advantage!
- Bon marché: le Deep Learning renverse la sagesse conventionnelle des GPU et vous permet de calculer avec juste un processeur peu coûteux! --Bon: meilleures performances que DQN (et d'autres méthodes de comparaison)!
C'est une méthode d'apprentissage de renforcement en profondeur comme un bol de boeuf avec les trois battements En un mot, DQN est vieux et A3C est nouveau et meilleur (fondamentalement, sinon absolument).
Comme ça ↓

Asynchronous Chez DQN, l'expérience acquise par un agent agissant a été échantillonnée au hasard (car l'expérience ne devient pas iid une fois en ligne) et utilisée comme données de formation. Étant donné que seule l'expérience d'un agent est utilisée, la vitesse à laquelle les échantillons d'apprentissage sont collectés est lente, et comme l'expérience a été une fois accumulée sous la forme de ReplayMemory puis apprise, il est difficile d'apprendre à partir de données chronologiques telles que LSTM. Il y avait Par conséquent, dans la partie asynchrone A3C, plusieurs agents (max 16 dans l'article) sont déplacés en même temps, et les expériences individuelles sont collectées et apprises de sorte que l'expérience globale soit échantillonnée au hasard et apprise en ligne. J'essaye d'être En même temps, j'ai acquis beaucoup d'expérience, donc j'ai pu progresser plus rapidement dans l'apprentissage.
Advantage Dans l'apprentissage TD normal, la somme de la récompense $ r $ obtenue à la suite de l'action et la valeur estimée de l'état suivant $ V (s_ {t + 1}) $ (divisée par le taux d'actualisation $ \ gamma $) Et, en utilisant la différence de la valeur estimée de l'état actuel $ \ Delta $, nous mettrons à jour la valeur de l'état
Inversement, si l'estimation de l'état suivant est incorrecte, l'estimation de l'état actuel ne sera pas mise à jour correctement en premier lieu. En outre, la valeur estimée de l'état suivant doit être correcte pour la valeur estimée suivante, et la valeur estimée de l'état suivant est dans une chaîne avec ..., donc ce n'est qu'une longueur d'avance. La méthode de mise à jour devrait prendre un certain temps pour converger vers la valeur correcte Par conséquent, dans A3C, en profitant de la possibilité d'apprendre en ligne, c'est-à-dire en utilisant des données chronologiques, nous mettrons à jour la valeur estimée en utilisant le montant suivant appelé Avantage.
Ici, $ k $ est une constante qui indique la durée de l'anticipation à effectuer. Puisque l'information la plus probable dans l'estimation de la valeur de l'apprentissage intensif est la récompense $ r $ réellement obtenue, le montant de l'avantage est la valeur actuelle la plus probable compte tenu de la récompense k avance au lieu d'une avance. On peut dire qu'il s'agit d'une erreur d'estimation de A3C utilise ce montant pour l'apprentissage,
――Parce que c'est une valeur plus probable, l'apprentissage progresse plus vite ―― Étant donné que nous considérons jusqu'à plusieurs étapes à venir, l'apprentissage progresse plus rapidement que si vous ne regardez qu'une longueur d'avance.
On pense que c'est une méthode qui a rendu l'apprentissage plus efficace en prévision de ces deux points.
Actor-Critic
Dans DQN, nous avons formé une estimation de la valeur de l'exécution de l'action $ a $ dans un certain état $ s $, qui est appelée la valeur Q. Étant donné que la valeur d'une action dans un certain état est estimée, il y avait un problème en ce que le nombre de combinaisons à estimer devenait énorme lorsque l'action était continue (par exemple, lorsque vous vouliez apprendre la vitesse de rotation d'un moteur). Actor-Critic est une méthode d'apprentissage améliorée qui apprend tout en estimant indépendamment la probabilité qu'une action $ \ pi $ se produise dans un certain état et la valeur estimée $ V $ de l'état, et les valeurs estimées sont indépendantes. , Il est facile à apprendre même si l'action est continue Je ne sais pas dans quelle mesure Actor-Critic contribue aux performances d'A3C lui-même, mais en raison des caractéristiques ci-dessus, l'adoption d'Actor-Critic par A3C est une mesure discrète ou continue. Peut être appris, et on peut dire qu'il est devenu polyvalent.
7 conseils pour éviter la frustration
L'introduction est devenue plus longue Puisqu'il existe de nombreuses implémentations A3C auxquelles on peut faire référence, comme le référentiel GitHub ci-dessous.
À partir de maintenant, mis à part les détails sur la façon d'implémenter A3C, je l'ai implémenté pour ceux qui veulent écrire, écrire ou qui veulent écrire du code par eux-mêmes dans une certaine mesure, plutôt que de se précipiter. Cependant, lorsque l'apprentissage ne progresse pas, ou lorsque l'apprentissage progresse mais que le résultat du papier est complètement différent, je présenterai les points à faire attention et vérifierai comme des pièges et des astuces auxquels je suis accro.
Pièges / Astuces Partie 1 L'hyperparamètre est un mystère
Au fur et à mesure que vous procédez à la mise en œuvre, il y aura des points peu clairs tels que les paramètres de RMSProp et comment réduire le taux d'apprentissage. Heureusement, les ancêtres ont déjà [publié] les paramètres à utiliser (https://github.com/muupan/async-rl/wiki), vous pouvez donc rechercher vous-même des hyper paramètres ou vous soucier de choses étranges. Arrêtons-nous
Pièges / Astuces Partie 2 Piège à différenciation automatique
Il y a deux lignes dans la description de l'implémentation A3C décrite dans l'article:
Il n'y a rien de mal à cela, mais comme le réseau de reproduction Atari est divisé en deux parties et partage certains paramètres, $ \ theta ': d \ theta \ leftarrow d \ theta + \ nabla_ { \ theta '} \ log \ pi (a_i | s_i; \ theta') \ bigl (RV (s_i; \ theta_v ') \ bigr) $ est $ V (s_i; \ theta_v') si implémenté tel quel Puisque la $ part n'est pas à l'origine une fonction de $ \ theta '$, dans le cas du tensorflow, si $ V (s_i; \ theta_v') $ n'a pas de valeur scalaire, le calcul du gradient sera incorrect du fait de la différenciation automatique. Masu
Pièges / Astuces Partie 3 OpenCV2 Drame Slow Problem
Si vous utilisez OpenCV pour la mise à l'échelle des gris des images, l'affichage des images, etc., vous devez confirmer que vous utilisez OpenCV3. Si je ne remarquais pas qu'OpenCV semblait être un goulot d'étranglement, j'ai utilisé OpenCV2, et lorsque je suis passé à OpenCV3, la vitesse d'exécution a augmenté plusieurs fois.
Pièges / Astuces # 4 Arcade Learning Environment ne prend pas en charge le multithreading
Si vous l'implémentez en multi-processus, cela n'a pas d'importance, mais si vous l'implémentez en multi-thread, vous devez y penser. Cela ne veut pas dire que cela ne fonctionne pas du tout parce que je n'ai pris aucune mesure, mais il n'y a pas de solution drastique, et pour autant que je sache, il n'y a qu'un remède symptomatique pour la relaxation qui est probablement acceptable. Il y a aussi miyosuda / async_deep_reinforce, mais un correctif comme dire que le code source de l'environnement d'apprentissage arcade est un peu falsifié et que les variables statiques ne sont pas statiques est efficace. Semble être Cependant, il semble toujours être dans un état étrange de temps en temps dans la plage que j'ai essayée (car honnêtement, je ne sais pas si mon code est bogué ou ALE est bogué), et le reste est comme de la chance. Aussi, j'ai senti que le code de l'environnement d'apprentissage arcade était plus stable dans mon environnement en modifiant le code de la v0.5.1 que le dernier master (peut-être à cause de mon esprit ... pour référence). )
Pièges / Astuces # 5 Conversion de l'échelle en plage 0-1 avec prétraitement d'image
L'image en échelle de gris obtenue à partir de la bière est comprise entre 0 et 255, mais d'après ma propre expérimentation, il semble que les performances s'amélioreront si vous divisez par 255 et modifiez l'échelle globale dans la plage de 0 à 1 ( Il est difficile d'apprendre si vous montez et divisez par 255)
Pièges / Astuces Partie 6 Mettre en œuvre fidèlement dans le document
C'est naturel! Il semble que vous vous fâcherez, mais j'écrirai ici avec prudence qu'il doit être mis en œuvre fidèlement au papier. Ce à quoi vous devriez prêter une attention particulière, c'est le nombre d'étapes d'avantage, et comme je l'ai écrit ci-dessus, l'avantage est pré-lu, donc en théorie, il semble que le résultat est meilleur si vous pouvez pré-lire beaucoup, donc ce n'est pas 5 dans le papier. N'est-il pas préférable d'avoir un plus grand nombre tel que 10 ou 20? DeepMind est-il stupide? Je veux penser comme un génie! Je pense que c'est un problème causé par la façon dont la récompense du jeu que vous voulez apprendre est donnée et la méthode d'apprentissage appelée Actor-Critic, mais dans le jeu Breakout que j'ai essayé, cela doit être $ t_ {max} = 5 $ sur le chemin. L'apprentissage a progressé plus vite que la thèse, l'apprentissage s'est mal passé autour de ce que je pensais être bon (environ 13 millions de pas), le réseau était cassé et je n'ai pas pu récupérer. En revanche, à Pong, 20 semble fonctionner, donc ce nombre d'étapes ne doit pas être simplement augmenté, mais doit être sélectionné avec soin. Cela signifie, et si vous souhaitez le reproduire, vous devez le changer après la reproduction.
Pièges / Astuces Partie 7 Vérifiez si vous êtes en pente ascendante
Dans cette méthode, il est nécessaire de corriger le gradient du réseau politique dans le sens de l'augmentation de la récompense et de l'augmentation de l'entropie, de sorte que le calcul sera étrange à moins qu'un signe négatif ne soit ajouté à la perte pour qu'il devienne ascension au lieu de descente de gradient. Dans le cas du tensorflow, cela ressemble à ce qui suit
policy_loss = - tf.reduce_sum(log_pi_a_s * advantage) - entropy * self.beta #Je veux changer la valeur dans le sens de l'augmentation, alors ajoutez moins aux deux
value_loss = tf.nn.l2_loss(self.reward_input - self.value) #Je veux réduire l'erreur de la valeur estimée, alors laissez-la telle quelle
Pièges / Astuces Extra Edition Avez-vous à vous soucier de Global Interpreter Lock?
Vous devez être prudent, mais cela dépend de la bibliothèque que vous utilisez et de la vitesse à laquelle vous voulez qu'elle s'exécute. Au moins Tensorflow semble être relativement conscient des problèmes de GIL il semble être implémenté, et pour moi, c'est un environnement Ryzen7 1800X. C'était environ 2M pas / heure en dessous À 2 M pas / heure, il faut environ 40 heures pour atteindre 80 M pas, ce qui est écrit dans le papier. Presque entièrement en python Chainer est conscient de GIL et multitraitement c'est inutile si vous ne l'implémentez pas
en conclusion
Le code que j'ai écrit pour le reproduire est posté sur GitHub (la version LSTM n'est pas encore), veuillez donc vous y référer. Les résultats d'apprentissage seront publiés plus tard ~~
Résultat d'apprentissage
Voici les données quand cela a pris environ 40 heures avec Ryzen 1800X (je voulais vraiment le faire avec 16Thread, mais il ne supportait pas le noyau, donc 8)

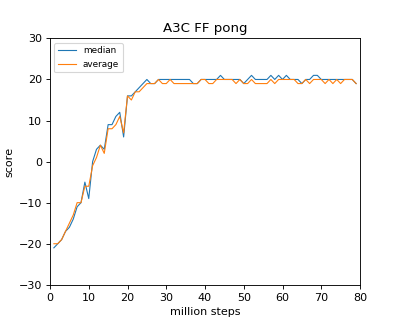
Pour autant que j'ai lu l'article, il semble que le même résultat soit obtenu pour Breakout / Pong. Dans le cas de Breakout / Pong, il semble qu'il converge presque à un stade relativement précoce (20 millions de pas).
Les références
Asynchronous Methods for Deep Reinforcement Learning Reinforcement learning in continuous time: advantage updating
Recommended Posts