[PYTHON] Sauvegardez la sortie de GAN une par une ~ Avec l'implémentation de GAN par PyTorch ~
Tout en traitant du GAN dans mes recherches de fin d'études, il est devenu nécessaire de sauvegarder les images générées par GAN une par une.
Cependant, même si vous le recherchez, tous les articles qui implémentent GAN ont une sortie comme celle-ci ...

Au lieu de sortir plusieurs feuilles à la fois, elles sont imprimées une par une. Je vais également l'écrire sous forme de mémorandum.
Objectif
Implémentez le GAN et enregistrez les images générées par GAN une par une
GAN GAN (Generative Adversarial Network): Le réseau de génération hostile est un modèle de génération proposé par Ian J. Goodfellow. Generative Adversarial Nets
La structure de base du GAN ressemble à ceci
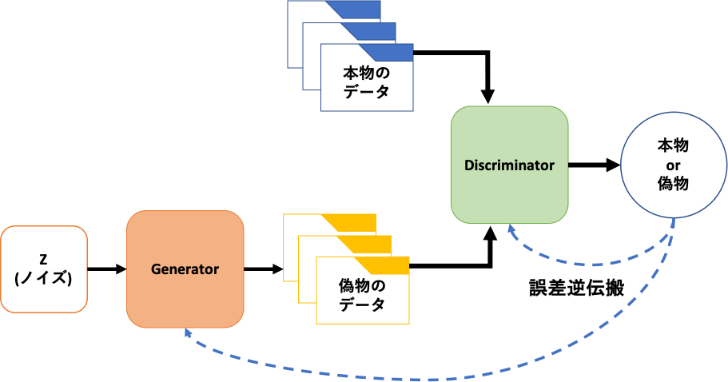
Nous avons deux réseaux et nous continuerons à apprendre tout en étant en concurrence. __Generator: Generator __ Génère une image qui peut tromper __Discriminator: Discriminator __, et Discriminator détermine s'il s'agit d'une image réelle ou d'une fausse image. Divers tels que DCGAN qui a rendu GAN célèbre et StyleGAN qui produit des images incroyablement réalistes. L'architecture est proposée.
Mise en œuvre du GAN
Passons maintenant à la mise en œuvre du GAN. Cette fois, nous allons implémenter DCGAN. Le code utilisé comme référence pour l'implémentation est ici
Environnement d'exécution
Google Colaboratory
importer et créer un répertoire
import argparse
import os
import numpy as np
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
import torch.nn as nn
import torch
os.makedirs("./images", exist_ok=True)
Importez les modules requis. Cette fois, nous allons l'implémenter avec PyTorch. Créez également un répertoire pour enregistrer l'image de sortie du GAN. Puisque ʻexist_ok = True`, si le répertoire existe déjà, il sera transmis.
Argument de ligne de commande et paramètre de valeur par défaut
Vous permet de spécifier des valeurs telles que le numéro d'époque et la taille du lot sur la ligne de commande. En même temps, définissez la valeur par défaut. Pour le nombre d'époques et la taille du lot, l'article ici est facile à comprendre.
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
Si vous pouvez utiliser la ligne de commande, vous pouvez la laisser telle quelle, mais si vous l'implémentez avec Google Colaboratory, l'erreur suivante se produira.
usage: ipykernel_launcher.py [-h] [--n_epochs N_EPOCHS]
[--batch_size BATCH_SIZE] [--lr LR] [--b1 B1]
[--b2 B2] [--n_cpu N_CPU]
[--latent_dim LATENT_DIM] [--img_size IMG_SIZE]
[--channels CHANNELS]
[--sample_interval SAMPLE_INTERVAL]
ipykernel_launcher.py: error: unrecognized arguments: -f /root/.local/share/jupyter/runtime/kernel-ecf689bc-740f-4dea-8913-e0d8ac0b1761.json
An exception has occurred, use %tb to see the full traceback.
SystemExit: 2
/usr/local/lib/python3.6/dist-packages/IPython/core/interactiveshell.py:2890: UserWarning: To exit: use 'exit', 'quit', or Ctrl-D.
warn("To exit: use 'exit', 'quit', or Ctrl-D.", stacklevel=1)
Dans Google Colab, si vous donnez la ligne ʻopt = parser.parse_args () comme ʻopt = parser.parse_args (args = []), elle passera.
Paramètres CUDA et initialisation du poids
cuda = True if torch.cuda.is_available() else False
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
Si vous n'utilisez pas de GPU, l'apprentissage prendra beaucoup de temps, alors rendez possible l'utilisation de CUDA (GPU). N'oubliez pas de modifier le paramètre d'exécution en GPU dans Google Colab.
Generator Générateur: définit le réseau du générateur.
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.init_size = opt.img_size // 4
self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, z):
out = self.l1(z)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
Discriminator Discriminateur: définit le réseau des discriminateurs.
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.model = nn.Sequential(
*discriminator_block(opt.channels, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# The height and width of downsampled image
ds_size = opt.img_size // 2 ** 4
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())
def forward(self, img):
out = self.model(img)
out = out.view(out.shape[0], -1)
validity = self.adv_layer(out)
return validity
Paramètres de la fonction de perte et paramètres réseau
# Loss function
adversarial_loss = torch.nn.BCELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
Créer un DataLoader
Nous allons créer un DataLoader. Cette fois, nous allons générer une image à l'aide du jeu de données MNIST. MNIST: ensemble de données d'images de nombres manuscrits
# Configure data loader
os.makedirs("./data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST("./data/mnist",train=True,download=True,
transform=transforms.Compose([
transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),batch_size=opt.batch_size,shuffle=True,
)
Training Je vais entraîner GAN.
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
valid = Tensor(imgs.shape[0], 1).fill_(1.0)
fake = Tensor(imgs.shape[0], 1).fill_(0.0)
# Configure input
real_imgs = imgs.type(Tensor)
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim)))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png " % batches_done, nrow=5, normalize=True)
Résultat d'exécution
Puisque le résultat est enregistré à intervalles réguliers, nous regarderons le résultat de l'exécution comme une image GIF.

Des nombres que les gens peuvent comprendre clairement sont générés.
Je veux enregistrer les images une par une
Je ne pense pas qu'il y ait beaucoup de gens comme ça, mais je n'ai pas pu les trouver même après les avoir vérifiés, alors je vais les partager. C'était dans la partie Formation ci-dessus
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png " % batches_done, nrow=5, normalize=True)
Si vous modifiez cette partie comme suit, vous pouvez enregistrer une par une.
if batches_done % opt.sample_interval == 0:
save_gen_img = gen_img[0]
save_image(save_gen_imgs, "images/%d.png " % batches_done, normalize=True)
Si vous souhaitez enregistrer plusieurs feuilles une par une, vous pouvez l'utiliser dans l'instruction for. Je pense que ce n'est pas grave si vous répétez l'instruction numérique save_image. ~~ Le temps de formation augmentera considérablement ~~
Avec cela, nous avons atteint l'objectif initial de sauvegarder la sortie du GAN une par une.
Résumé
Cette fois, nous avons implémenté DCGAN avec PyTorch et avons rendu possible la sauvegarde de la sortie de GAN un par un, et confirmé que les numéros manuscrits étaient effectivement générés. Ensuite, j'écrirai sur le GAN conditionnel (cGAN) qui peut contrôler la sortie du GAN. De même, cGAN pourra enregistrer une image pour chaque classe.
Recommended Posts