[PYTHON] J'étais ravi de penser que j'étais en mesure de créer un programme de calice qui atteindrait un taux de précision de prédiction de taux FX (dollar-yen) de 88% avec l'apprentissage en profondeur, mais quand je l'ai prédit avec des données de production, c'était un talent pour répéter "je ne sais pas."
À propos de cet article
Je suis désolé pour le titre de l'article comme Narurou. "Avec le Deep Learning (CNN), créez un programme de prédiction dollar-yen et soyez millionnaire!" Par enthousiasme, c'est une histoire qui a échoué __. __ Par contre, veuillez vous référer uniquement à ceux qui veulent être enseignant __.
Description du livrable
Je ne veux pas trop expliquer, mais je vais expliquer les livrables.
Apprenez à prédire les taux avec un grand nombre d'images de graphiques avec CNN (Convolution Neural Network)
J'ai créé un programme qui génère 3 choix de «haut», «bas» et «ne sais pas» le taux après 24 heures.
 Le résultat de l'inférence était un bon résultat avec un taux de réponse correcte de 88%.
Cependant, si vous le prédisez avec des données réelles, il y aura beaucoup de "je ne sais pas". ..
Il a fallu 3 jours pour le créer, donc je ne sais pas comment c'est fait.
J'ai beaucoup appris du processus de création, je vais donc le laisser en sortie.
Le résultat de l'inférence était un bon résultat avec un taux de réponse correcte de 88%.
Cependant, si vous le prédisez avec des données réelles, il y aura beaucoup de "je ne sais pas". ..
Il a fallu 3 jours pour le créer, donc je ne sais pas comment c'est fait.
J'ai beaucoup appris du processus de création, je vais donc le laisser en sortie.
Environnement de construction
Construit sur Google Colaboratory. Python 3.6 Tensorflow 1.13.1
Prétraitement des données
Préparation des données d'image
CNN est un apprentissage en profondeur de la classification d'images.
Vous devez donc préparer de nombreuses images de graphiques.
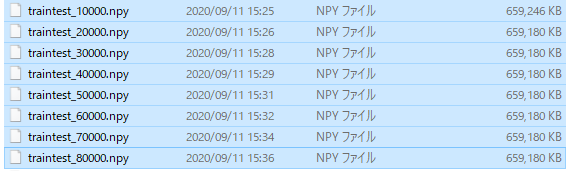
Nous avons préparé environ 80 000 données d'image comme ci-dessous.
 De plus, bien qu'il ait fallu environ 8 heures pour créer 80 000 images, j'en ai utilisé 30 000 pour la raison décrite plus loin.
Veuillez consulter cet article pour savoir comment créer une image de graphique.
De plus, bien qu'il ait fallu environ 8 heures pour créer 80 000 images, j'en ai utilisé 30 000 pour la raison décrite plus loin.
Veuillez consulter cet article pour savoir comment créer une image de graphique.
Disposition des données d'image et stockage au format binaire
Le travail d'apprentissage ne peut pas être effectué avec des données d'image telles quelles. J'ai besoin de convertir les données d'image en un tableau numpy, et je l'ai enregistré au format npy toutes les 10000 feuilles.
import glob
import cv2
import numpy as np
X=[]
#Lister les images cibles
img_list = glob.glob('<Dossier de destination d'enregistrement d'image>/*.png')
#Redimensionner l'image
for i in range(len(file_list)):
file_name = '../Make_img/USDJPY/' + str(i) + '.png'
img = cv2.imread(file_name)
img = cv2.resize(img, dsize=(150, 150)) #redimensionner
X.append(img) #Ajouter à la liste
#Enregistrez toutes les 10000 feuilles au format binaire
if (i > 0) and (i % 10000 == 0):
#Convertir en numpy et enregistrer en binaire
X = np.array(X)
npy_name = 'traintest_' + str(i) + '.npy'
np.save(npy_name, X)
X = []
Ensuite, il y a 0,7 Go de fichiers npy par un,
Avec 80 000 feuilles, la capacité est devenue proche de 6 Go.
Cette fois, les données enregistrées sur Google Drive, Je prévois de le charger avec Google Colob et d'y travailler. Il n'est pas bon de télécharger un fichier aussi volumineux. Compressez plusieurs fichiers npy en un seul et combinez-les au format npz.
- Je me rendrai compte plus tard qu'il n'était pas nécessaire de convertir le tableau en npy et de le sauvegarder depuis le début.
arr1 = np.load('traintest_10000.npy')
arr2 = np.load('traintest_20000.npy')
arr3 = np.load('traintest_30000.npy')
arr4 = np.load('traintest_40000.npy')
arr5 = np.load('traintest_50000.npy')
arr6 = np.load('traintest_60000.npy')
arr7 = np.load('traintest_70000.npy')
arr8 = np.load('traintest_80000.npy')
np.savez_compressed('traintest_all.npz', arr1 , arr2, arr3, arr4, arr5, arr6, arr7, arr8)
Une fois compressé, il est devenu environ 0,7 Go.

Au départ, je l'ai redimensionné à 250 * 250, À la suite du chargement avec Google Colab, la mémoire s'est plantée et j'ai changé la taille en 150 * 150. Avec cette taille, certaines parties sont floues et je me demande si je peux bien saisir la quantité de fonctionnalités. C'est peut-être l'une des raisons pour lesquelles cette prédiction a échoué.
Lisez les données d'entraînement, les données de test et les étiquettes de réponse correctes avec Google Colab
Téléchargez le fichier npz créé sur Google Drive et Démarrez GoogleColab et chargez-le.
#Importation de package
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.layers import Activation, Add, BatchNormalization, Conv2D, Dense, GlobalAveragePooling2D, Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.regularizers import l2
from tensorflow.keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
#Monture Google Drive
from google.colab import drive
drive.mount('/content/drive')
#Lire le npz qui est la source de l'ensemble de données
loadnpz = np.load(r'/content/drive/My Drive/traintest_all.npz')
Assurez-vous que 8 éléments ont été lus correctement.

Ensuite, séparez les images pour la formation et la vérification. Lisez 10 000 feuilles chacune.
- Si vous en lisez plus, la mémoire plantera pendant l'apprentissage.
#Ensemble de données d'image d'entraînement et de test
train_images = loadnpz['arr_0']
test_images = loadnpz['arr_1']
Après avoir lu le fichier CSV contenant l'étiquette de réponse correcte avec DataFrame, il est converti en tableau. Après la conversion, séparez les étiquettes de réponse correctes pour la formation et la vérification.
#Ensemble d'étiquettes correctes
df = pd.read_csv(r'/content/drive/My Drive/Colab Notebooks/fichier npy/tarintest_labels.csv')
df['target'] = df['target'].replace('Up', '0')
df['target'] = df['target'].replace('Down', '1')
df['target'] = df['target'].replace('Flat', '2')
df['target'] = df['target'].astype('int')
labels_arr = df['target'].to_numpy() #Convertir une partie d'étiquette en tableau
#Données d'étiquette séparées
train_labels = labels_arr[0:10001] #Pour s'entraîner
test_labels = labels_arr[10001:20001] #Pour vérification
Les données d'étiquette sont converties au format OneHot.
#Convertir au format OneHot
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
Si vous pouvez faire cela, vérifions le nombre de formes.

La modélisation
Vient ensuite la création du modèle. Cette fois, nous allons le créer avec une structure appelée ResNet. Si vous vous demandez ce qu'est ResNet, veuillez consulter cet article .
Si les données d'image à lire sont trop volumineuses, la mémoire plantera à plusieurs reprises et ne fonctionnera pas du tout. Dans ce cas, il est nécessaire de réduire le batch_size pendant l'apprentissage ou les données d'image elles-mêmes. Dans mon cas, j'ai initialement utilisé 250 * 250 données d'image et je n'ai pas pu continuer tout le chemin en raison d'une série de pannes de mémoire, alors je l'ai redimensionnée à 150 * 150.
#Génération de couche convolutive
def conv(filters, kernel_size, strides=1):
return Conv2D(filters, kernel_size, strides=strides, padding='same', use_bias=False,
kernel_initializer='he_normal', kernel_regularizer=l2(0.0001))
#Génération du bloc résiduel A
def first_residual_unit(filters, strides):
def f(x):
# →BN→ReLU
x = BatchNormalization()(x)
b = Activation('relu')(x)
#Couche pliante → BN → ReLU
x = conv(filters // 4, 1, strides)(b)
x = BatchNormalization()(x)
x = Activation('relu')(x)
#Couche pliante → BN → ReLU
x = conv(filters // 4, 3)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
#Couche pliante →
x = conv(filters, 1)(x)
#Ajuster la taille de la forme du raccourci
sc = conv(filters, 1, strides)(b)
# Add
return Add()([x, sc])
return f
#Génération du bloc résiduel B
def residual_unit(filters):
def f(x):
sc = x
# →BN→ReLU
x = BatchNormalization()(x)
x = Activation('relu')(x)
#Couche pliante → BN → ReLU
x = conv(filters // 4, 1)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
#Couche pliante → BN → ReLU
x = conv(filters // 4, 3)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
#Couche pliante →
x = conv(filters, 1)(x)
# Add
return Add()([x, sc])
return f
#Génération du bloc résiduel A et du bloc résiduel B x 17
def residual_block(filters, strides, unit_size):
def f(x):
x = first_residual_unit(filters, strides)(x)
for i in range(unit_size-1):
x = residual_unit(filters)(x)
return x
return f
#Forme des données d'entrée
input = Input(shape=(150,150, 3))
#Couche pliante
x = conv(16, 3)(input)
#Bloc résiduel x 54
x = residual_block(64, 1, 18)(x)
x = residual_block(128, 2, 18)(x)
x = residual_block(256, 2, 18)(x)
# →BN→ReLU
x = BatchNormalization()(x)
x = Activation('relu')(x)
#Couche de regroupement
x = GlobalAveragePooling2D()(x)
#Couche entièrement connectée
output = Dense(3, activation='softmax', kernel_regularizer=l2(0.0001))(x)
#Créer un modèle
model = Model(inputs=input, outputs=output)
#Conversion en modèle TPU
import tensorflow as tf
import os
tpu_model = tf.contrib.tpu.keras_to_tpu_model(
model,
strategy=tf.contrib.tpu.TPUDistributionStrategy(
tf.contrib.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
)
)
#compiler
tpu_model.compile(loss='categorical_crossentropy', optimizer=SGD(momentum=0.9), metrics=['acc'])
#Préparation d'ImageDataGenerator
train_gen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True)
test_gen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True)
#Pré-calculer les statistiques pour l'ensemble de données
for data in (train_gen, test_gen):
data.fit(train_images)
Apprentissage
Effectuer un travail d'apprentissage. Même si je l'ai converti en modèle TPU, cela prend près de 5 heures à cause de la capacité.
#Préparation à LearningRateScheduler
def step_decay(epoch):
x = 0.1
if epoch >= 80: x = 0.01
if epoch >= 120: x = 0.001
return x
lr_decay = LearningRateScheduler(step_decay)
#Apprentissage
batch_size = 32
history = tpu_model.fit_generator(
train_gen.flow(train_images, train_labels, batch_size=batch_size),
epochs=100,
steps_per_epoch=train_images.shape[0] // batch_size,
validation_data=test_gen.flow(test_images, test_labels, batch_size=batch_size),
validation_steps=test_images.shape[0] // batch_size,
callbacks=[lr_decay])
Après apprentissage, le taux de réponse correcte (val_acc) dans les données de vérification sera de 88%!
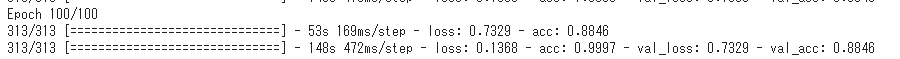
Prédiction avec des données réelles
Chargez de nouvelles données de vérification dans test_images et essayez de faire une prédiction.
test_predictions = new_model.predict_generator(
test_gen.flow(test_images[0:10000], shuffle = False, batch_size=16),
steps=16)
test_predictions = np.argmax(test_predictions, axis=1)[0:10000]
Le résultat de la prédiction est sorti avec 3 choix: "0: monter", "1: descendre" et "2: ne sait pas". Allons vérifier.

"2: je ne sais pas" est répété ... À certains endroits, il y avait "0: monter" et "1: descendre", Le taux de réponse correcte était un résultat désastreux de moins de 50% ...
Pourquoi avez-vous échoué?
Je pense que les deux suivants sont importants.
- La taille de l'image après le redimensionnement était trop petite et les caractéristiques trop grossières.
- Trop peu d'images pendant la période de vérification
1 peut être résolu en augmentant la taille de l'image, L'environnement gratuit de Google Colab est difficile. Si vous devenez un membre payant avec des frais mensuels de 10 $, il semble que vous pourrez utiliser deux fois plus de mémoire, donc cela peut être résolu.
2 peut s'améliorer dans une certaine mesure car vous pouvez apprendre différents modèles de graphiques en mélangeant toutes les images. Il peut également être possible de simplifier délibérément l'image elle-même et d'augmenter le nombre de graphiques similaires. La bande de Bollinger est utilisée dans l'article, mais elle peut être améliorée en la supprimant et en ne traçant que le cours de clôture et la ligne de moyenne mobile.
Countermeasure 2 peut être fait gratuitement, je vais donc l'essayer pendant mon temps libre.