[PYTHON] 100 Language Processing Knock 2015 Chapitre 5 Analyse des dépendances (40-49)
J'ai essayé de résoudre le "Chapitre 5 Analyse des dépendances (40-49)" de 100 coups. Ceci est une continuation de Chapitre 4 Analyse morphologique (30-39).
environnement
- OS X El Capitan Version 10.11.4
- Python 3.5.1
Page référencée
J'étais assez accro à l'introduction de CaboCha, pydot, Graphviz et "49. Extraction de chemins de dépendances entre nomenclature", mais j'ai réussi à le résoudre en me référant au site suivant.
- 100 coups de traitement du langage naturel Chapitre 5 Analyse des dépendances (première moitié)
- 100 coups de traitement du langage naturel Chapitre 5 Analyse des dépendances (seconde moitié)
- 100 langue de traitement Knock 2015 version (46-49)
- Site officiel de CaboCha
- Analyse des dépendances à partir de CaboCha
- Résumé de la façon de dessiner des graphiques en graphviz et en langage à points
- Dessinez une arborescence en Python 3 en utilisant graphviz
- [AttributeError: module 'pydot' has no attribute 'graph_from_dot_data' in spyder] (http://stackoverflow.com/questions/35285142/attributeerror-module-pydot-has-no-attribute-graph-from-dot-data-in-spyder)
Préparation
Bibliothèque à utiliser
import CaboCha
import pydotplus
import subprocess
Enregistrement du texte analysé dépendant
Utilisez CaboCha pour intercepter et analyser le texte (neko.txt) du roman de Natsume Soseki "Je suis un chat" et enregistrer le résultat dans un fichier appelé neko.txt.cabocha. Utilisez ce fichier pour implémenter un programme qui répond aux questions suivantes.
def make_analyzed_file(input_file_name: str, output_file_name: str) -> None:
"""
Analysez de manière dépendante un fichier de phrases japonais brut et enregistrez-le dans un fichier.
(Supprimer les blancs.)
:param input_file_name Nom du fichier de phrases en japonais
:param output_file_name Nom du fichier texte analysé dépendant
"""
c = CaboCha.Parser()
with open(input_file_name, encoding='utf-8') as input_file:
with open(output_file_name, mode='w', encoding='utf-8') as output_file:
for line in input_file:
tree = c.parse(line.lstrip())
output_file.write(tree.toString(CaboCha.FORMAT_LATTICE))
make_analyzed_file('neko.txt', 'neko.txt.cabocha')
40. Lecture du résultat de l'analyse des dépendances (morphologie)
Implémentez la classe Morph qui représente la morphologie. Cette classe a une forme de surface (surface), une forme de base (base), un mot de partie (pos) et une sous-classification de mot de partie 1 (pos1) en tant que variables membres. De plus, lisez le résultat de l'analyse de CaboCha (neko.txt.cabocha), exprimez chaque phrase comme une liste d'objets Morph et affichez la chaîne d'éléments morphologiques de la troisième phrase.
class Morph:
"""
Une classe qui représente une morphologie
"""
def __init__(self, surface, base, pos, pos1):
"""
Il a une forme de surface (surface), une forme de base (base), une partie du discours (pos) et une sous-classification de partie du discours 1 (pos1) comme variables membres..
"""
self.surface = surface
self.base = base
self.pos = pos
self.pos1 = pos1
def is_end_of_sentence(self) -> bool: return self.pos1 == 'Phrase'
def __str__(self) -> str: return 'surface: {}, base: {}, pos: {}, pos1: {}'.format(self.surface, self.base, self.pos, self.pos1)
def make_morph_list(analyzed_file_name: str) -> list:
"""
Lisez le fichier de phrases analysé par les dépendances et exprimez chaque phrase sous la forme d'une liste d'objets Morph.
:param analyzed_file_name Nom du fichier texte analysé dépendant
:liste de retour Une liste d'une phrase représentée comme une liste d'objets Morph
"""
sentences = []
sentence = []
with open(analyzed_file_name, encoding='utf-8') as input_file:
for line in input_file:
line_list = line.split()
if (line_list[0] == '*') | (line_list[0] == 'EOS'):
pass
else:
line_list = line_list[0].split(',') + line_list[1].split(',')
#À ce point ligne_la liste ressemble à ceci
# ['début', 'nom', 'Avocat possible', '*', '*', '*', '*', 'début', 'Hajime', 'Hajime']
_morph = Morph(surface=line_list[0], base=line_list[7], pos=line_list[1], pos1=line_list[2])
sentence.append(_morph)
if _morph.is_end_of_sentence():
sentences.append(sentence)
sentence = []
return sentences
morphed_sentences = make_morph_list('neko.txt.cabocha')
#Afficher la chaîne d'élément de formulaire de la troisième phrase
for morph in morphed_sentences[2]:
print(str(morph))
41. Lecture du résultat de l'analyse des dépendances (expression / dépendance)
En plus de> 40, implémentez la classe de clause Chunk.
Cette classe a une liste d'éléments morph (objets Morph) (morphs), une liste de numéros d'index de clause associés (dst) et une liste de numéros d'index de clause d'origine (srcs) associés en tant que variables membres. De plus, lisez le résultat de l'analyse de CaboCha du texte d'entrée, exprimez une phrase sous la forme d'une liste d'objets Chunk, et affichez la chaîne de caractères et le contact de la phrase de la huitième phrase. Pour le reste des problèmes du chapitre 5, utilisez le programme créé ici.
Il existe de nombreuses méthodes dans la classe Chunk, mais tout ce dont vous avez besoin ici est __init__ et __str__. D'autres méthodes ont été ajoutées à chaque fois que les questions suivantes ont été résolues.
class Chunk:
def __init__(self, morphs: list, dst: str, srcs: str) -> None:
"""
Il contient une liste d'éléments morph (objets Morph) (morphs), une liste de numéros d'index de clause associés (dst) et une liste de numéros d'index de clause d'origine (srcs) associés en tant que variables membres.
"""
self.morphs = morphs
self.dst = int(dst.strip("D"))
self.srcs = int(srcs)
#Voici les méthodes que nous utiliserons plus tard.
def join_morphs(self) -> str:
return ''.join([_morph.surface for _morph in self.morphs if _morph.pos != 'symbole'])
def has_noun(self) -> bool:
return any([_morph.pos == 'nom' for _morph in self.morphs])
def has_verb(self) -> bool:
return any([_morph.pos == 'verbe' for _morph in self.morphs])
def has_particle(self) -> bool:
return any([_morph.pos == 'Particule' for _morph in self.morphs])
def has_sahen_connection_noun_plus_wo(self) -> bool:
"""
"Nomenclature de connexion Sahen+Renvoie si contient ou non "(auxiliaire)".
"""
for idx, _morph in enumerate(self.morphs):
if _morph.pos == 'nom' and _morph.pos1 == 'Changer de connexion' and len(self.morphs[idx:]) > 1 and \
self.morphs[idx + 1].pos == 'Particule' and self.morphs[idx + 1].base == 'À':
return True
return False
def first_verb(self) -> Morph:
return [_morph for _morph in self.morphs if _morph.pos == 'verbe'][0]
def last_particle(self) -> list:
return [_morph for _morph in self.morphs if _morph.pos == 'Particule'][-1]
def pair(self, sentence: list) -> str:
return self.join_morphs() + '\t' + sentence[self.dst].join_morphs()
def replace_noun(self, alt: str) -> None:
"""
Remplacer la nomenclature.
"""
for _morph in self.morphs:
if _morph.pos == 'nom':
_morph.surface = alt
def __str__(self) -> str:
return 'srcs: {}, dst: {}, morphs: ({})'.format(self.srcs, self.dst, ' / '.join([str(_morph) for _morph in self.morphs]))
def make_chunk_list(analyzed_file_name: str) -> list:
"""
Lisez le fichier de phrases analysé par dépendance et exprimez chaque phrase sous la forme d'une liste d'objets Chunk.
:param analyzed_file_name Nom du fichier texte analysé dépendant
:liste de retour Une liste d'une phrase représentée comme une liste d'objets Chunk
"""
sentences = []
sentence = []
_chunk = None
with open(analyzed_file_name, encoding='utf-8') as input_file:
for line in input_file:
line_list = line.split()
if line_list[0] == '*':
if _chunk is not None:
sentence.append(_chunk)
_chunk = Chunk(morphs=[], dst=line_list[2], srcs=line_list[1])
elif line_list[0] == 'EOS': # End of sentence
if _chunk is not None:
sentence.append(_chunk)
if len(sentence) > 0:
sentences.append(sentence)
_chunk = None
sentence = []
else:
line_list = line_list[0].split(',') + line_list[1].split(',')
#À ce point ligne_la liste ressemble à ceci
# ['début', 'nom', 'Avocat possible', '*', '*', '*', '*', 'début', 'Hajime', 'Hajime']
_morph = Morph(surface=line_list[0], base=line_list[7], pos=line_list[1], pos1=line_list[2])
_chunk.morphs.append(_morph)
return sentences
chunked_sentences = make_chunk_list('neko.txt.cabocha')
#Afficher la chaîne d'élément de formulaire de la troisième phrase
for chunk in chunked_sentences[2]:
print(str(chunk))
42. Affichage de la phrase de l'intéressé et de l'intéressé
Extraire tout le texte de la clause originale et de la clause liée au format délimité par des tabulations. Cependant, n'émettez pas de symboles tels que les signes de ponctuation.
Je vais résumer chaque phrase pour faciliter son utilisation en 44.
def is_valid_chunk(_chunk, sentence):
return _chunk.join_morphs() != '' and _chunk.dst > -1 and sentence[_chunk.dst].join_morphs() != ''
paired_sentences = [[chunk.pair(sentence) for chunk in sentence if is_valid_chunk(chunk, sentence)] for sentence in chunked_sentences if len(sentence) > 1]
print(paired_sentences[0:100])
43. Extraire les clauses contenant la nomenclature relative aux clauses contenant des verbes
Lorsque des clauses contenant une nomenclature se rapportent à des clauses contenant des verbes, extrayez-les au format délimité par des tabulations. Cependant, n'émettez pas de symboles tels que les signes de ponctuation.
C'est facile car diverses méthodes pratiques sont implémentées dans la classe Chunk.
for sentence in chunked_sentences:
for chunk in sentence:
if chunk.has_noun() and chunk.dst > -1 and sentence[chunk.dst].has_verb():
print(chunk.pair(sentence))
44. Visualisation des arbres dépendants
Visualisez l'arbre de dépendance d'une phrase donnée sous forme de graphe orienté. Pour la visualisation, convertissez l'arborescence des dépendances en langage DOT et utilisez Graphviz. De plus, pour visualiser des graphiques dirigés directement à partir de Python, utilisez pydot.
def sentence_to_dot(idx: int, sentence: list) -> str:
head = "digraph sentence{} ".format(idx)
body_head = "{ graph [rankdir = LR]; "
body_list = ['"{}"->"{}"; '.format(*chunk_pair.split()) for chunk_pair in sentence]
return head + body_head + ''.join(body_list) + '}'
def sentences_to_dots(sentences: list) -> list:
_dots = []
for idx, sentence in enumerate(sentences):
_dots.append(sentence_to_dot(idx, sentence))
return _dots
def save_graph(dot: str, file_name: str) -> None:
g = pydotplus.graph_from_dot_data(dot)
g.write_jpeg(file_name, prog='dot')
dots = sentences_to_dots(paired_sentences)
for idx in range(101, 104):
save_graph(dots[idx], 'graph{}.jpg'.format(idx))
[Exemple] Arbre dépendant de la 101e phrase

[Exemple] Arbre dépendant de la 102ème phrase

[Exemple] Arbre dépendant de la 103ème phrase
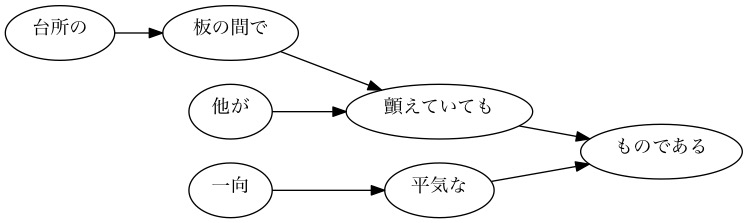
- Au fait, il semble que «se balancer» soit lu comme «secouer».
45. Extraction de modèles de cas verbaux
Je voudrais considérer la phrase utilisée cette fois comme un corpus et enquêter sur les cas possibles de prédicats japonais. Considérez les verbes comme des prédicats et les assistants verbaux liés aux verbes comme des cas, et affichez les prédicats et les cas au format délimité par des tabulations. Cependant, assurez-vous que la sortie répond aux spécifications suivantes.
--Dans une clause contenant un verbe, la forme de base du verbe le plus à gauche est utilisée comme prédicat. --La casse est le mot auxiliaire lié au prédicat --S'il existe plusieurs mots auxiliaires (phrases) liés au prédicat, arrangez tous les mots auxiliaires dans l'ordre du dictionnaire, séparés par des espaces.
Prenons l'exemple de la phrase (8ème phrase de neko.txt.cabocha) que "j'ai vu un être humain pour la première fois ici". Cette phrase contient deux verbes, «commencer» et «voir», et la phrase liée à «commencer» a été analysée comme «ici», et la phrase liée à «voir» a été analysée comme «je suis» et «chose». Dans ce cas, la sortie doit être la suivante.
Au début À voir
Enregistrez la sortie de ce programme dans un fichier et vérifiez les éléments suivants à l'aide des commandes UNIX.
--Combinaison de prédicats et de modèles de cas qui apparaissent fréquemment dans le corpus --Le modèle de casse des verbes "faire", "voir" et "donner" (organiser par ordre de fréquence d'apparition dans le corpus)
def case_patterns(_chunked_sentences: list) -> list:
"""
Modèle de cas de verbe(Combinaison de verbe et d'auxiliaire)Renvoie une liste de.("Kaku" est en anglais"Case"Il paraît que.)
:param _chunked_phrases Une liste de morphologies fragmentées répertoriées par phrase
:modèle de cas de retour(Par exemple['donner', ['À', 'À']])Liste de
"""
_case_pattern = []
for sentence in _chunked_sentences:
for _chunk in sentence:
if not _chunk.has_verb():
continue
particles = [c.last_particle().base for c in sentence if c.dst == _chunk.srcs and c.has_particle()]
if len(particles) > 0:
_case_pattern.append([_chunk.first_verb().base, sorted(particles)])
return _case_pattern
def save_case_patterns(_case_patterns: list, file_name: str) -> None:
"""
Modèle de cas de verbe(Combinaison de verbe et d'auxiliaire)Enregistrer la liste dans un fichier.
:param _case_motifs(Par exemple['donner', ['À', 'À']])Liste de
:param file_nom Enregistrer le nom du fichier de destination
"""
with open(file_name, mode='w', encoding='utf-8') as output_file:
for _case in _case_patterns:
output_file.write('{}\t{}\n'.format(_case[0], ' '.join(_case[1])))
save_case_patterns(case_patterns(chunked_sentences), 'case_patterns.txt')
def print_case_pattern_ranking(_grep_str: str) -> None:
"""
Corpus(case_pattern.txt)Utilisez les commandes UNIX pour afficher les 20 premiers éléments par ordre décroissant de fréquence d'occurrence..
`cat case_patterns.txt | grep '^Faire\t' | sort | uniq -c | sort -r | head -20`Est en train d'imprimer en exécutant une commande Unix comme.
La partie grep est l'argument`_grep_str`S'ajoute selon.
:param _grep_str Verbe de condition de recherche
"""
_grep_str = '' if _grep_str == '' else '| grep \'^{}\t\''.format(_grep_str)
print(subprocess.run('cat case_patterns.txt {} | sort | uniq -c | sort -r | head -10'.format(_grep_str), shell=True))
#Combinaisons de prédicats et de modèles de cas qui apparaissent fréquemment dans le corpus (top 10)
#Modèles de casse des verbes "faire", "voir" et "donner" (10 premiers par ordre de fréquence d'apparition dans le corpus)
for grep_str in ['', 'Faire', 'à voir', 'donner']:
print_case_pattern_ranking(grep_str)
46. Extraction d'informations sur le cadre de la casse verbale
Modifiez le programme> 45 et affichez le terme (la clause elle-même liée au prédicat) au format délimité par des tabulations en suivant le modèle de prédicat et de cas. En plus de la spécification> 45, assurez-vous que les spécifications suivantes sont respectées.
--Le terme doit être une chaîne de mots de la clause liée au prédicat (il n'est pas nécessaire de supprimer le verbe de fin) --S'il y a plusieurs clauses liées au prédicat, disposez-les dans le même standard et dans le même ordre que les mots auxiliaires, séparés par des espaces.
Prenons l'exemple de la phrase (8ème phrase de neko.txt.cabocha) que "j'ai vu un être humain pour la première fois ici". Cette phrase contient deux verbes, «commencer» et «voir», et la phrase liée à «commencer» a été analysée comme «ici», et la phrase liée à «voir» a été analysée comme «je suis» et «chose». Dans ce cas, la sortie doit être la suivante.
Commencez ici Regarde ce que je vois
def sorted_double_list(key_list: list, value_list: list) -> tuple:
"""
Prend deux listes comme arguments, dicte une liste comme clé et l'autre liste comme valeur, trie par clé, puis se décompose en deux listes et retourne sous forme de taple.
:param key_liste Une liste de clés pour le tri
:param value_Liste triée par clé de liste
:return key_Deux taples de liste triés par liste
"""
double_list = list(zip(key_list, value_list))
double_list = dict(double_list)
double_list = sorted(double_list.items())
return [pair[0] for pair in double_list], [pair[1] for pair in double_list]
def case_frame_patterns(_chunked_sentences: list) -> list:
"""
Le modèle de cadre de cas de verbe(Combinaison de verbe et d'auxiliaire)Renvoie une liste de.
:param _chunked_phrases Une liste de morphologies fragmentées répertoriées par phrase
:modèle de cas de retour(Par exemple['Faire', ['main', 'Est'], ['泣いmain', 'いた事だけEst']])Liste de
"""
_case_frame_patterns = []
for sentence in _chunked_sentences:
for _chunk in sentence:
if not _chunk.has_verb():
continue
clauses = [c.join_morphs() for c in sentence if c.dst == _chunk.srcs and c.has_particle()]
particles = [c.last_particle().base for c in sentence if c.dst == _chunk.srcs and c.has_particle()]
if len(particles) > 0:
_case_frame_patterns.append([_chunk.first_verb().base, *sorted_double_list(particles, clauses)])
return _case_frame_patterns
def save_case_frame_patterns(_case_frame_patterns: list, file_name: str) -> None:
"""
Modèle de cas de verbe(Combinaison de verbe et d'auxiliaire)Enregistrer la liste dans un fichier.
:param _case_frame_cadre de cas de modèles(Par exemple['Faire', ['main', 'Est'], ['泣いmain', 'いた事だけEst']])Liste de
:param file_nom Enregistrer le nom du fichier de destination
"""
with open(file_name, mode='w', encoding='utf-8') as output_file:
for case in _case_frame_patterns:
output_file.write('{}\t{}\t{}\n'.format(case[0], ' '.join(case[1]), ' '.join(case[2])))
save_case_frame_patterns(case_frame_patterns(chunked_sentences), 'case_frame_patterns.txt')
47. Exploration de la syntaxe des verbes fonctionnels
Je voudrais prêter attention uniquement lorsque le verbe wo case contient une nomenclature de connexion sa-variant. Modifiez 46 programmes pour répondre aux spécifications suivantes.
--Uniquement lorsque la phrase consistant en "nom de connexion sahen + (verbe auxiliaire)" est liée au verbe --Le prédicat est "nom de connexion sahen + est la forme de base du + verbe", et quand il y a plusieurs verbes dans une phrase, le verbe le plus à gauche est utilisé. --S'il existe plusieurs mots auxiliaires (phrases) liés au prédicat, arrangez tous les mots auxiliaires dans l'ordre du dictionnaire, séparés par des espaces. --S'il y a plusieurs clauses liées au prédicat, arrangez tous les termes séparés par des espaces (alignez-vous sur l'ordre des mots auxiliaires).
Par exemple, la sortie suivante doit être obtenue à partir de la phrase «Le maître répondra à la lettre, même si elle vient à un autre endroit».
Quand je réponds à la lettre, mon mari
Enregistrez la sortie de ce programme dans un fichier et vérifiez les éléments suivants à l'aide des commandes UNIX.
--Prédicats qui apparaissent fréquemment dans le corpus (nomenclature de connexion sahénienne + + verbe) --Prédicats et modèles de verbes qui apparaissent fréquemment dans le corpus
def sahen_case_frame_patterns(_chunked_sentences: list) -> list:
"""
Le modèle de cadre de cas de verbe(Combinaison de verbe et d'auxiliaire)Renvoie une liste de.
:param _chunked_phrases Une liste de morphologies fragmentées répertoriées par phrase
:modèle de cas de retour(Par exemple['Faire', ['main', 'Est'], ['泣いmain', 'いた事だけEst']])Liste de
"""
_sahen_case_frame_patterns = []
for sentence in _chunked_sentences:
for _chunk in sentence:
if not _chunk.has_verb():
continue
sahen_connection_noun = [c.join_morphs() for c in sentence if c.dst == _chunk.srcs and c.has_sahen_connection_noun_plus_wo()]
clauses = [c.join_morphs() for c in sentence if c.dst == _chunk.srcs and not c.has_sahen_connection_noun_plus_wo() and c.has_particle()]
particles = [c.last_particle().base for c in sentence if c.dst == _chunk.srcs and not c.has_sahen_connection_noun_plus_wo() and c.has_particle()]
if len(sahen_connection_noun) > 0 and len(particles) > 0:
_sahen_case_frame_patterns.append([sahen_connection_noun[0] + _chunk.first_verb().base, *sorted_double_list(particles, clauses)])
return _sahen_case_frame_patterns
def save_sahen_case_frame_patterns(_sahen_case_frame_patterns: list, file_name: str) -> None:
"""
Modèle de cas de verbe(Combinaison de verbe et d'auxiliaire)Enregistrer la liste dans un fichier.
:param _sahen_case_frame_cadre de cas de modèles(Par exemple['Faire', ['main', 'Est'], ['泣いmain', 'いた事だけEst']])Liste de
:param file_nom Enregistrer le nom du fichier de destination
"""
with open(file_name, mode='w', encoding='utf-8') as output_file:
for case in _sahen_case_frame_patterns:
output_file.write('{}\t{}\t{}\n'.format(case[0], ' '.join(case[1]), ' '.join(case[2])))
save_sahen_case_frame_patterns(sahen_case_frame_patterns(chunked_sentences), 'sahen_case_frame_patterns.txt')
#Prédicats qui apparaissent fréquemment dans le corpus+À+動詞)ÀUNIXコマンドÀ用いて確認
print(subprocess.run('cat sahen_case_frame_patterns.txt | cut -f 1 | sort | uniq -c | sort -r | head -10', shell=True))
#Utilisez les commandes UNIX pour vérifier les prédicats et les modèles de verbes qui apparaissent fréquemment dans le corpus
print(subprocess.run('cat sahen_case_frame_patterns.txt | cut -f 1,2 | sort | uniq -c | sort -r | head -10', shell=True))
48. Extraction des chemins de la nomenclature aux racines
Pour une clause contenant toute la nomenclature de la phrase, extrayez le chemin de cette clause jusqu'à la racine de l'arbre de syntaxe. Cependant, le chemin sur l'arbre de syntaxe doit satisfaire aux spécifications suivantes.
--Chaque clause est représentée par une séquence morphologique (superficielle) --Concaténer les expressions de chaque clause avec "->" de la clause de début à la clause de fin du chemin.
A partir de la phrase "J'ai vu un être humain pour la première fois ici" (8ème phrase de neko.txt.cabocha), le résultat suivant devrait être obtenu.
je suis->vu ici->Commencer avec->Humain->Des choses->vu Humain->Des choses->vu Des choses->vu
Vous pouvez écrire clairement en appelant la fonction de manière récursive.
def path_to_root(_chunk: Chunk, _sentence: list) -> list:
"""
Clause donnée en argument(`_chunk`)Si est root, renvoie cette clause.
Clause donnée en argument(`_chunk`)Si n'est pas root, renvoie la clause et le chemin de la clause à laquelle il appartient à root sous forme de liste.
:param _La clause qui est le point de départ de la racine de bloc
:param _phrase Le texte à analyser
:return list _Chemin du morceau à la racine
"""
if _chunk.dst == -1:
return [_chunk]
else:
return [_chunk] + path_to_root(_sentence[_chunk.dst], _sentence)
def join_chunks_by_arrow(_chunks: list) -> str:
return ' -> '.join([c.join_morphs() for c in _chunks])
#Sortez uniquement les 10 premières phrases et vérifiez le fonctionnement
for sentence in chunked_sentences[0:10]:
for chunk in sentence:
if chunk.has_noun():
print(join_chunks_by_arrow(path_to_root(chunk, sentence)))
49. Extraction de chemins de dépendance entre nomenclature
Extraire le chemin de dépendance le plus court qui relie toutes les paires de nomenclatures de la phrase. Cependant, lorsque les numéros de clause de la paire de nomenclatures sont i et j (i <j), le chemin de dépendance doit satisfaire aux spécifications suivantes.
--Semblable au problème 48, le chemin est exprimé en concaténant les expressions (éléments morphologiques de surface) de chaque phrase de la clause de début à la clause de fin avec "->". --Remplacer la nomenclature contenue dans les clauses i et j par X et Y, respectivement.
De plus, la forme du chemin de dépendance peut être considérée des deux manières suivantes.
--Si la clause j existe sur le chemin de la clause i à la racine de l'arbre de syntaxe: Afficher le chemin de la clause i à la clause j --Autre de ce qui précède, lorsque la clause i et la clause j se croisent en une clause commune k sur le chemin de la clause j à la racine de l'arbre de syntaxe: le chemin immédiatement avant la clause i vers la clause k et le chemin immédiatement avant la clause j vers la clause k, Afficher le contenu de la clause k en les concaténant avec "|"
Par exemple, à partir de la phrase "J'ai vu un être humain pour la première fois ici" (8ème phrase de neko.txt.cabocha), la sortie suivante devrait être obtenue.
X est|En Y->Commencer avec->Humain->Des choses|vu X est|Appelé Y->Des choses|vu X est|Oui|vu En X->Commencer avec-> Y En X->Commencer avec->Humain-> Y Appelé X-> Y
Je ne savais pas ce que je voulais faire en lisant l'énoncé du problème, mais 100 traitements du langage naturel frappent Chapitre 5 Analyse des dépendances (seconde moitié) et [Language] Traitement 100 coups édition 2015 (46-49)](http://kenichia.hatenablog.com/entry/2016/02/11/221513) J'ai lu et compris que c'est le cas.
Si vous commencez à écrire le code tout en décomposant le problème sans le savoir, vous le comprendrez progressivement. Expliquez comment vous avez décomposé le problème en écrivant un peu plus de commentaires dans le code ci-dessous. J'espère que ce sera utile.
def noun_pairs(_sentence: list):
"""
Renvoie une liste de toutes les paires qui peuvent être faites à partir de toutes les clauses de nomenclature de la phrase passée en argument.
"""
from itertools import combinations
_noun_chunks = [_chunk for _chunk in _sentence if _chunk.has_noun()]
return list(combinations(_noun_chunks, 2))
def common_chunk(path_i: list, path_j: list) -> Chunk:
"""
Si la clause i et la clause j se croisent au niveau d'une clause commune k sur le chemin vers la racine de l'arbre syntaxique, alors la clause k est renvoyée..
"""
_chunk_k = None
path_i = list(reversed(path_i))
path_j = list(reversed(path_j))
for idx, (c_i, c_j) in enumerate(zip(path_i, path_j)):
if c_i.srcs != c_j.srcs:
_chunk_k = path_i[idx - 1]
break
return _chunk_k
for sentence in chunked_sentences:
#Liste des paires de nomenclatures
n_pairs = noun_pairs(sentence)
if len(n_pairs) == 0:
continue
for n_pair in n_pairs:
chunk_i, chunk_j = n_pair
#Remplacez la nomenclature contenue dans les clauses i et j par X et Y, respectivement.
chunk_i.replace_noun('X')
chunk_j.replace_noun('Y')
#Chemin des clauses i et j à la racine(Liste des types de blocs)
path_chunk_i_to_root = path_to_root(chunk_i, sentence)
path_chunk_j_to_root = path_to_root(chunk_j, sentence)
if chunk_j in path_chunk_i_to_root:
#Lorsque la clause j existe sur le chemin de la clause i à la racine de l'arbre syntaxique
#Index sur le chemin de la clause i de la clause j à la racine de l'arbre syntaxique
idx_j = path_chunk_i_to_root.index(chunk_j)
#Afficher le chemin de la clause i à la clause j
print(join_chunks_by_arrow(path_chunk_i_to_root[0: idx_j + 1]))
else:
#Autre que ce qui précède, lorsque la clause i et la clause j se croisent à une clause commune k sur la route à partir de la racine de l'arbre de syntaxe
#Obtenir la clause k
chunk_k = common_chunk(path_chunk_i_to_root, path_chunk_j_to_root)
if chunk_k is None:
continue
#Index sur le chemin de la clause i de la clause k à la racine de l'arbre syntaxique
idx_k_i = path_chunk_i_to_root.index(chunk_k)
#Index sur le chemin de la clause j de la clause k à la racine de l'arbre syntaxique
idx_k_j = path_chunk_j_to_root.index(chunk_k)
#Le chemin immédiatement avant le passage i vers la clause k, le chemin immédiatement avant le passage j vers la clause k et le contenu de la clause k"|"Affichage en se connectant avec
print(' | '.join([join_chunks_by_arrow(path_chunk_i_to_root[0: idx_k_i]),
join_chunks_by_arrow(path_chunk_j_to_root[0: idx_k_j]),
chunk_k.join_morphs()]))
Recommended Posts