[PYTHON] Un amateur a créé son propre jeu d'IA à partir de zéro dans une étude gratuite pendant les vacances d'été
0. Introduction
C'est un record que l'auteur d'un étudiant de troisième année qui n'avait aucune connaissance sur l'apprentissage par renforcement jusqu'à il y a un mois (presque aucune connaissance de l'apprentissage automatique jusqu'à il y a deux mois) a tenté de faire un petit jeu d'IA en tâtonnant. Ceci est un article de niveau. Je suis une personne inexpérimentée
--Organisez et confirmez votre compréhension —— Faire rattraper par des personnes compétentes les points qui ne peuvent être atteints «Je ne sais rien de l'apprentissage par renforcement, mais ça m'intéresse. Mais je n'ai pas de matériel pédagogique sous la main. J'espère que ce sera un tutoriel pour ceux qui disent
Je suis venu écrire cet article dans le but de frapper. Si vous êtes intéressé, veuillez le lire chaleureusement. Vos commentaires et suggestions sont les bienvenus.
0-1. Références
Lorsque j'ai appris l'apprentissage par renforcement, j'ai lu pour la première fois le livre «Introduction à la théorie du renforcement de l'apprentissage pour les ingénieurs informatiques» (Etsuji Nakai)](https://enakai00.hatenablog.com/entry/2020/06/18/084700). Je l'ai acheté comme manuel et je l'ai lu collant. Merci beaucoup pour votre aide à la rédaction, je vais donc la présenter ici.
De plus, je voudrais noter qu'une partie du code source de l'article est très similaire à celui de ce livre. Notez s'il vous plaît.
Ensuite, avant d'apprendre l'apprentissage par renforcement, j'ai lu deux livres, "Introduction à l'apprentissage automatique à partir de Python" et "Deep Learning from Zero" (tous deux par O'Reilly Japan), et j'ai lu dans une certaine mesure sur l'apprentissage automatique et l'apprentissage profond, donc je posterai également ceci. Mettre. En particulier, ce dernier peut être utile pour comprendre la partie implémentation de l'IA.
0-2. Flux approximatif d'articles
Dans cet article, nous allons d'abord présenter les jeux que l'IA apprendra et fixerons des objectifs. Ensuite, j'organiserai l'histoire théorique de l'apprentissage par renforcement et de l'algorithme DQN utilisé cette fois, et enfin j'exposerai le code source, vérifierai le résultat de l'apprentissage et listerai les problèmes et les plans d'amélioration qui se sont présentés. .. Je vous serais reconnaissant de bien vouloir consulter uniquement les parties qui vous intéressent.
Postscript. Quand je l'ai rédigée, l'édition théorique est devenue plus lourde que ce à quoi je m'attendais. Si vous êtes un théoricien comme moi, il peut être amusant d'être collant. Si vous n'avez pas ce genre de motivation, il vaut peut-être mieux la garder dans une trace modérée.
0-3. Langue à utiliser
Avec l'aide de Python. L'auteur utilise le notebook jupyter. (Peut-être que cela fonctionne dans d'autres environnements que la fonction de visualisation sur le tableau, mais je ne l'ai pas confirmé. La fonction de visualisation n'est pas un gros problème, vous n'avez donc pas à vous inquiéter autant.)
Aussi, à l'apogée, j'utiliserai un peu le framework d'apprentissage profond "TensorFlow". Je veux exécuter le code jusqu'à la fin! Pour ceux qui disent, l'installation est nécessaire pour exécuter la partie concernée, alors s'il vous plaît seulement là. Aussi, ici, si un GPU est disponible, il peut être traité à grande vitesse, mais comme je n'ai pas un tel environnement ou connaissance, je l'ai poussé avec un CPU (ordinaire). Si vous utilisez Google Colab, etc., vous pouvez utiliser le GPU gratuitement, mais j'ai évité l'accident en raison de la coupure de la session. Je laisserai le jugement ici.
0-4. Connaissances préalables
Si vous venez de lire l'article et d'en avoir une idée, vous n'avez besoin d'aucune connaissance particulière.
Pour bien comprendre la théorie, il suffit de comprendre dans une certaine mesure les mathématiques du lycée (probabilité, formule graduelle), et pour lire l'implémentation sans stress, il suffit de connaître la grammaire de base de Python (classe). Si le concept vous inquiète, vous devriez le revoir légèrement). De plus, si vous avez une connaissance préalable des algorithmes (planification dynamique, etc.), ce sera plus facile à comprendre.
Le seul point est que le réseau de neurones est un domaine qui changera considérablement si vous ne l'expliquez pas dans cet article et si vous avez des connaissances. Je vais faire une déclaration comme "S'il vous plaît pensez-y comme ceci", donc je pense que cela ne gênera pas votre compréhension si vous l'avalez, mais si vous voulez le savoir correctement, je vous recommande de le faire séparément.
Passons à l'histoire principale! !!
1. Présentation des jeux que nous gérons
J'ai choisi ** 2048 jeux ** comme thème d'apprentissage (↓ comme ça). Savez-vous

J'expliquerai les règles plus tard, mais c'est tellement simple que vous le comprendrez. Il existe de nombreuses applications pour smartphones et versions Web, alors essayez-les.
1-1. Règles
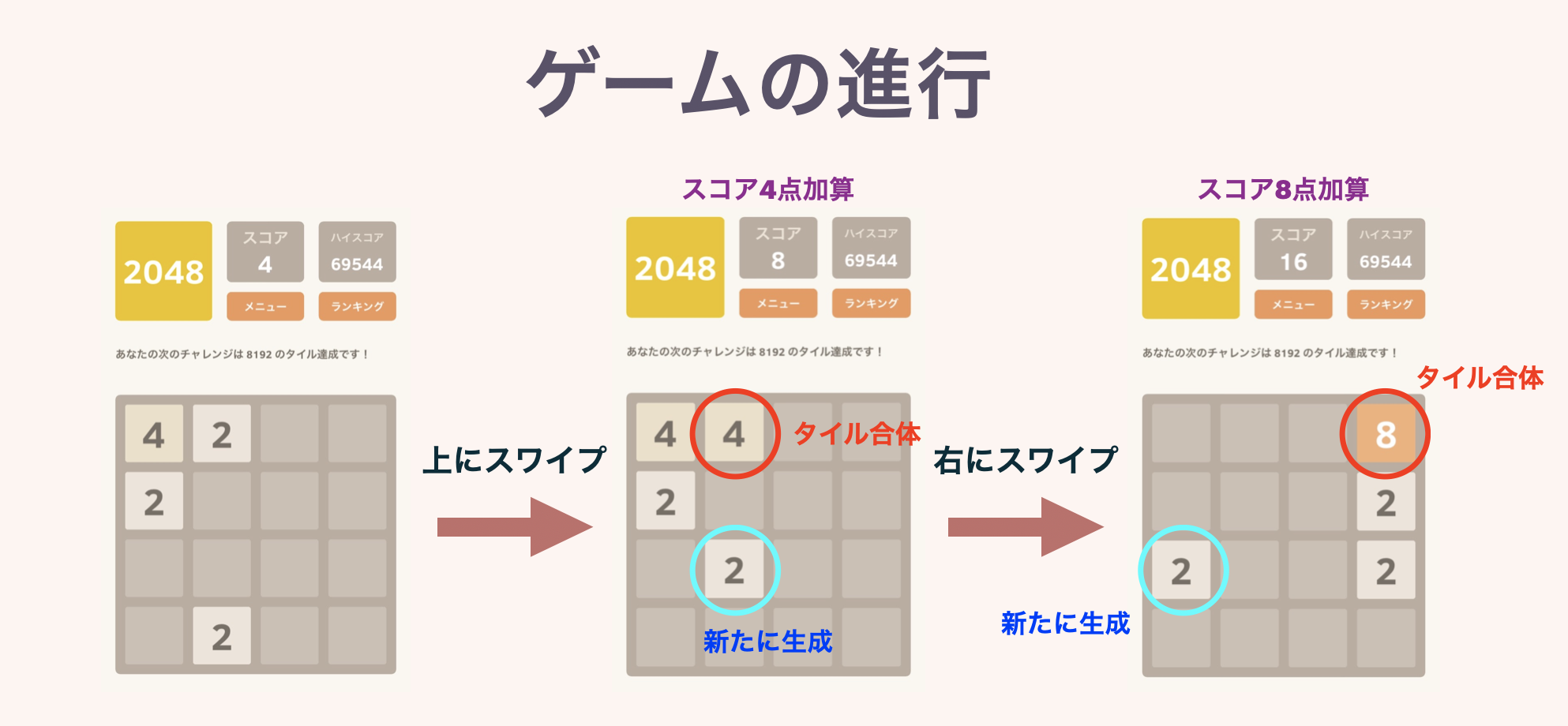
Une tuile d'une puissance de 2 est placée sur le plateau de 4 $ \ fois 4 $ carrés. Au début du jeu, les tuiles «2» ou «4» sont placées dans 2 cases choisies au hasard.
À chaque tour, le joueur choisit l'une des quatre directions, haut, bas, gauche et droite, et glisse ou appuie sur un bouton. Ensuite, toutes les tuiles du plateau glissent dans cette direction. À ce moment, si des tuiles avec le même nombre entrent en collision, elles fusionneront et le nombre augmentera, formant une seule tuile. À ce moment, les nombres écrits sur les tuiles créées seront ajoutés en tant que scores.
A la fin de chaque tour, une nouvelle tuile "2" ou "4" sera créée dans l'une des cases vides. Si vous ne pouvez vous déplacer dans aucune direction, le jeu est terminé. Visez un score élevé d'ici là! C'est un jeu appelé. Comme le nom de ce jeu l'indique, le but est de "faire 2048 tuiles" dans un premier temps.
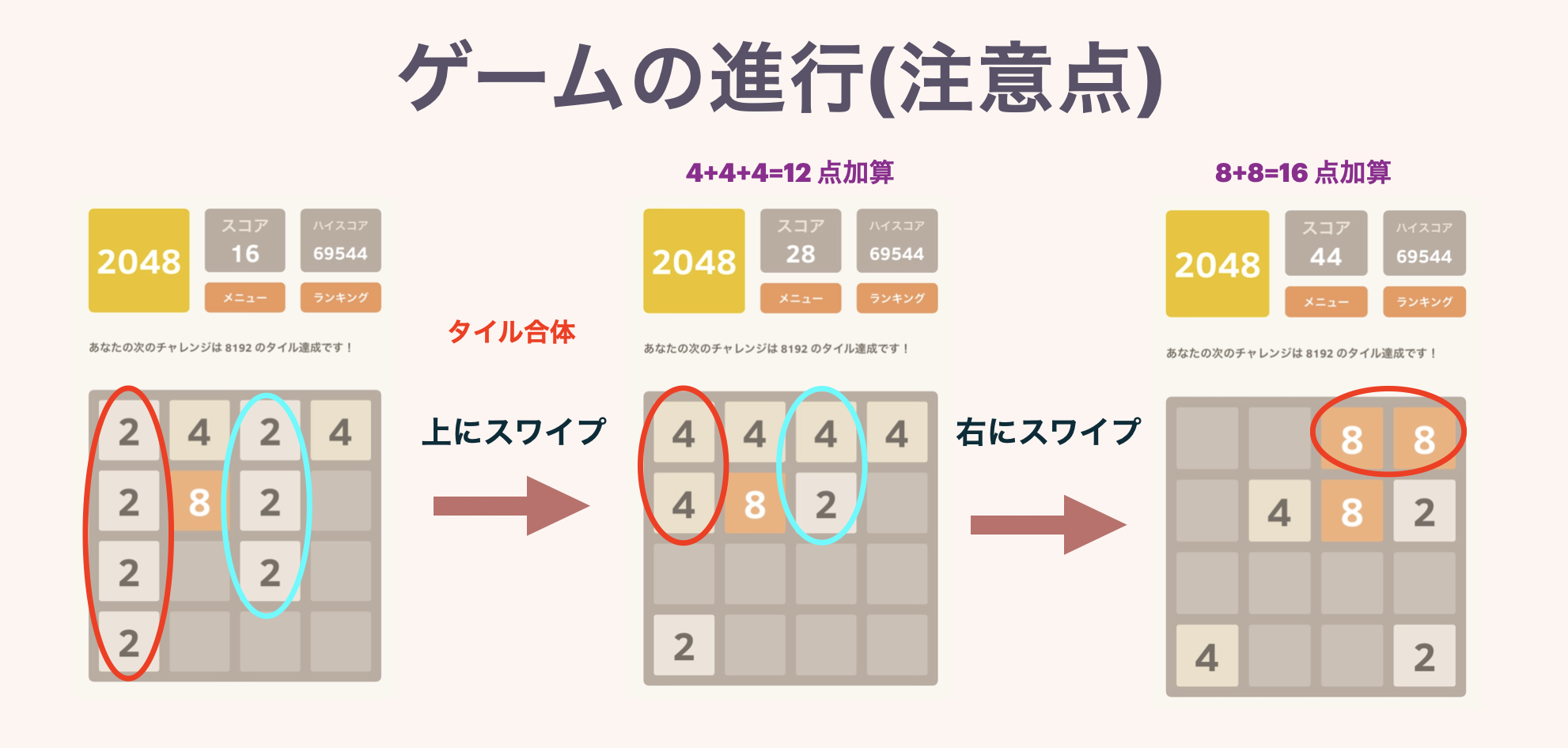
↓ C'est une illustration. Les règles sont vraiment simples.
La deuxième figure montre le comportement lorsque trois tuiles ou plus avec le même numéro sont alignées. Si plusieurs tuiles sont complétées en même temps, le score sera ajouté correctement.

1-2. Conseils pour ce jeu
Il y a de la chance dans ce jeu, mais le score reflète probablement la compétence du joueur. En d'autres termes, c'est un «jeu que vous pouvez améliorer en étudiant et en vous entraînant». Plus tard, je demanderai à l'IA de pratiquer le jeu, mais j'écrirai brièvement les astuces de ce jeu que j'ai reçues à ce moment. Ce serait formidable si l'IA pouvait apprendre cette astuce par elle-même.
Cependant, si vous voulez connaître le niveau d'IA que vous pouvez atteindre, ** je vous recommande de jouer plusieurs fois sans voir cette astuce. ** Si vous connaissez votre capacité initiale, il sera un peu plus facile de comprendre à quel niveau vous vous trouvez dans le futur processus d'apprentissage de l'IA. (Si cela ne vous dérange pas, vous pouvez l'ouvrir normalement.)
Veuillez lire ce contenu après avoir compris ce qui précède (cliquez sur le triangle à gauche). Dans ce jeu, au début, ce n'est pas grave car les tuiles fusionnent quelque part, peu importe la façon dont vous les déplacez, mais finalement les plus grands nombres se mettent en travers et le plateau devient de plus en plus étroit. Par conséquent, il est très efficace d'adopter la politique de ** collecte de grands nombres dans certains coins **. (Il y a plusieurs astuces pour les récupérer dans le coin.) Dans la figure de gauche, les grands nombres sont collectés dans la direction supérieure gauche. Si vous glissez vers le bas sur ce plateau, "256" et "128" deviendront des tuiles obstructives au milieu, et il deviendra instable à la fois (il va vraiment jouer à la fois). ). Si vous jouez prudemment pour ne pas perdre cette forme, vous pouvez l'amener sur le plateau comme indiqué sur la figure de droite. De là, vous pouvez voir que vous pouvez aller directement à "2048". Le moment de collecter des tuiles à la fois est le point le plus agréable de ce jeu.
1-3. Objectif
Pour le moment, je vais fixer cet objectif (rêve). L'idéal est "une IA qui peut obtenir un score plus élevé que moi". Je pense que je comprends ce jeu dans une certaine mesure, et le score élevé de 69544 dans le sukusho que je vous ai montré plus tôt est assez élevé, mais si l'IA dépasse cela, je serai impressionné.
À titre indicatif pour le score, si une personne qui ne connaît pas ce jeu joue pour la première fois, le jeu sera terminé avec environ 1000 à 3000 points. Si vous jouez plusieurs fois et que vous vous habituez au jeu, vous pourrez obtenir environ 5000 à 7000 points. (C'est juste que les gens autour de moi avaient cette tendance. Comme il y a peu d'échantillons, veuillez l'utiliser comme référence). Comme je l'expliquerai plus tard, si vous choisissez votre main de manière complètement aléatoire, vous n'obtiendrez qu'en moyenne environ 1000 points.
Maintenant que nous avons parlé de 2048 jeux, entrons dans le sujet principal de l'apprentissage par renforcement!
2. Armé de théorie
Avant la mise en œuvre, nous organiserons la théorie qui est à la base de ce jeu de création d'IA ~~ ou quelque chose ~~. Je voudrais suivre le flux des bases de l'apprentissage par renforcement au DQN utilisé cette fois. L'auteur écrira également étape par étape tout en faisant obenkyo, alors faisons de notre mieux ensemble.
2-1. À propos du renforcement de l'apprentissage
En premier lieu, l'apprentissage par renforcement est un domaine avec l'apprentissage automatique, avec l'apprentissage supervisé et l'apprentissage non supervisé. L'apprentissage par renforcement consiste à définir un ** agent ** qui se déplace dans un environnement, à poursuivre le processus d'apprentissage tout en collectant des données à plusieurs reprises et à apprendre le comportement optimal qui maximise la «récompense» qui peut être obtenue. C'est le flux de. Il semble que l'apprentissage par renforcement soit appliqué dans l'IA du shogi and go qui est souvent entendu, et dans la technologie de conduite automatique.
Dans ce qui suit, je définirai le thème des jeux 2048, mais je vais également incorporer des termes un peu plus techniques et les organiser.
2-1-1. Politique d'action
Pour démarrer l'apprentissage par renforcement, définissez d'abord le "** agent " qui joue réellement au jeu (c'est subtil si on dit que l'agent lui-même a été défini dans cette implémentation, mais même virtuellement le jeu Je pense que c'est bien d'être conscient de l'existence de jouer). De plus, définissez " Récompense " dans le jeu pour donner à l'agent le but de "maximiser la récompense à la fin du jeu". La manière de définir la récompense est un facteur important. De plus, pendant le jeu, l'agent rencontre différents plateaux et est obligé de sélectionner « l'action » à y effectuer. Chaque planche est appelée " état **" en termes d'apprentissage par renforcement.
L'achèvement de la formation des agents signifie finalement que «la meilleure action a est connue pour tous les États». C'est facile à comprendre si vous considérez "○ × jeu" comme exemple. Ce match sera toujours un match nul tant que les deux parties continueront de faire de leur mieux. Cela signifie que si vous «mémorisez» tous les états possibles (tableaux), vous serez un maître du jeu ○ × invaincu sans même connaître les règles extrêmes.
Ici, nous définissons le terme «** politique de comportement **». Il s'agit d'une "règle dans laquelle l'agent sélectionne une action pour chaque état". Un agent avec une politique de comportement fixe joue le jeu en sélectionnant le coup suivant selon certaines règles (enfin, c'est une machine) comme une machine. L'objectif de l'apprentissage intensif peut être reformulé comme l'optimisation de cette politique comportementale et la recherche d'une politique comportementale optimale. Dans l'exemple du jeu ○ ×, suivre les meilleurs coups qui auraient dû être mémorisés est la politique d'action optimale.
De plus, il semble qu'il soit courant d'exprimer la politique de comportement avec le symbole $ \ pi $.
2-1-2. Fonction de valeur d'état
J'ai appris il y a quelque temps, mais je vais commencer à parler de la façon d'apprendre concrètement.
Tout d'abord, définissez la ** fonction de valeur d'état ** $ v_ \ pi (s) $. C'est une fonction qui suppose une politique d'action spécifique π et prend l'état s comme argument. La valeur de retour est "la valeur attendue du total des récompenses obtenues après le présent en partant de l'état s et en continuant à sélectionner des actions selon la politique d'action π jusqu'à la fin de la partie".
?? C'est peut-être le cas, mais si vous y réfléchissez, ce n'est pas grave. Lorsque la politique d'action est fixée, la valeur de la fonction de valeur d'état représente «la qualité de chaque carte».
Je vais le montrer car il est préférable (personnellement) d'utiliser la formule. Tous les symboles qui apparaissent soudainement donnent un sens.
Oui, c'est l'équation que la fonction de valeur d'état satisfait généralement. C'est ce qu'on appelle l'équation de Bellman **.
- $ p (r, s '\ | \ s, a) $ représente "la probabilité conditionnelle que r soit obtenue comme récompense lorsque l'action a est sélectionnée dans l'état s et passe à l'état s'". Je vais. (Même si vous sélectionnez la même action sur le même plateau, cette mesure est prise car vous n'obtenez pas toujours la même destination de récompense / transition. Par exemple, dans 2048 parties, la position des tuiles nouvellement générées est aléatoire. .)
- $ r + v_ \ pi (s ') $ est "quand a est sélectionné dans la première action, la récompense r est acquise et l'état passe à l'état s', puis la politique d'action π est suivie jusqu'à la fin de la partie. , La valeur attendue de la somme des récompenses qui peuvent être obtenues désormais ».
- $ \ pi (a \ | \ s) $ représente "la probabilité conditionnelle que l'action a soit sélectionnée dans l'état s dans la politique d'action π". (Si π n'inclut pas la sélection d'action probabiliste, cela peut être supprimé.)
Pour résumer ce qui précède, le sigma interne exprime "la valeur attendue de la somme des récompenses qui peuvent être obtenues à partir de maintenant lorsque l'action a est sélectionnée dans l'état courant s et agit ensuite selon π". De plus, en sommant les actions avec le sigma extérieur, elle devient "la valeur attendue de la récompense totale obtenue en fin de partie si l'action est sélectionnée en continu selon la politique d'action π à partir de l'état courant s".
Informations supplémentaires sur le "taux de remise" Dans l'équation de Belman de (1), un paramètre appelé ** taux d'actualisation ** est généralement introduit (le symbole est γ). Cependant, cette fois, j'ai décidé de ne pas m'en occuper car la formule est équivalente à (1) car $ \ gamma = 1 $ a été défini dans la partie implémentation et le degré de compréhension de l'auteur est peu profond. Pardon.
L'équation (1) ci-dessus montre la méthode de calcul plutôt que la définition de la fonction de valeur d'état. Un seul point, si la valeur de la fonction de valeur d'état pour l'état final (jeu à la mer) est définie à l'avance comme 0, la fonction de valeur d'état pour tous les états peut être retracée à l'état précédent et à l'état précédent. Vous pouvez calculer la valeur de. C'est une image que la valeur de la fonction de valeur d'état correcte se propage progressivement à partir de l'état final. En mathématiques au secondaire, c'est une formule graduelle, et en termes d'algorithmes, c'est une ** méthode de planification dynamique **.
Je ne m'étendrai pas davantage sur la planification dynamique. Cependant, il peut être utile de garder à l'esprit qu'au moins tous les états doivent être bouclés pour effectuer ce calcul.
Eh bien, j'ai défini la fonction de valeur d'état elle-même, mais à la fin, ce que fait "l'apprentissage" n'est pas encore montré. Je répondrai ensuite à cette question.
2-1-3. Fonction de valeur d'état de comportement
La fonction de valeur d'état décrite ci-dessus détermine si chaque état est bon ou mauvais en partant du principe que la politique d'action π est fixe. En d'autres termes, il ne peut pas améliorer à lui seul la politique comportementale π. Voici comment obtenir une meilleure politique comportementale. Cependant, ici, le fait que la politique d’action soit «meilleure» signifie "Pour tout état s, $ v_ {\ pi1} (s) \ leq v_ {\ pi2} (s) $ tient." Il est déterminé que. (Π2 est une «meilleure» politique de comportement que π1.)
Il a un nom très similaire, mais définit la ** fonction de valeur d'état d'action ** $ q_ \ pi (s, a) $. Ceci représente "la valeur attendue de la récompense totale qui peut être obtenue à partir de maintenant si l'action a est sélectionnée dans l'état courant s puis l'action est sélectionnée en continu selon la politique d'action π". cette? Comme certains d'entre vous l'ont peut-être pensé, cela apparaît entièrement dans une partie de l'équation (1). C'est,
est. En utilisant cela, l'équation (1) devient
Peut être exprimé comme.
Maintenant, je vais faire une conclusion à la fois. Comment améliorer votre politique comportementale ** "Pour toutes les actions a qui peuvent être sélectionnées dans l'état actuel s, reportez-vous à la valeur de la fonction de valeur d'état d'action $ q_ {\ pi} (s, a) $ et sélectionnez l'action a qui maximise cela. Corriger "**.
L'essentiel est: "Ignorez la politique comportementale actuelle pour un seul mouvement, regardez un monde différent et modifiez la politique pour choisir le mouvement qui semble être le meilleur." Je pense que vous pouvez comprendre intuitivement que si vous continuez à faire cette amélioration, vous obtiendrez de plus en plus de «meilleures» politiques. Il est possible de le montrer mathématiquement, mais c'est plutôt gênant, je vais donc l'omettre ici.
2-1-4. Résumé à ce jour
J'ai beaucoup dit, mais pour le moment, je me suis calmé, alors je vais le résumer brièvement. Le flux jusqu'à ce que l'agent apprenne la politique de comportement optimale est
- Pour le moment, définissez la politique d'action $ \ pi $ de manière appropriée. --Calculer la fonction de valeur d'état $ v_ {\ pi} (s) $ par programmation dynamique. --Action - La fonction de valeur d'état $ q_ {\ pi} (s, a) $ est calculée par l'équation (2). --Créez une nouvelle politique de comportement $ \ pi '$ par la méthode décrite ci-dessus.
- Remplacez ce $ \ pi '$ par la première politique d'action π et répétez la même opération.
est. En répétant cela tout le temps, l'agent peut obtenir une politique de comportement de mieux en mieux. C'est le mécanisme de «l'apprentissage» dans l'apprentissage par renforcement.
Supplément: À propos d'un petit point triché J'ai parlé de la façon dont vous pouvez théoriquement apprendre en répétant la boucle ci-dessus, mais lorsque vous essayez réellement de calculer, $ p (r, s '\ | \ s, a qui apparaît dans (1) et (2) ) Nous sommes confrontés à la question de savoir la valeur de $. C'est bien si vous avez une compréhension complète des spécifications du jeu (comme nous les programmeurs) et sont théoriquement nécessaires, mais vous ne le savez peut-être pas lorsque vous jouez à un jeu inconnu. Je recueillerai ceci plus tard par la «méthode 2-2-3. TD».
2-2. Q-Learning
L'algorithme résumé ci-dessus est indéniablement l'algorithme d'apprentissage correct, mais il présente l'inconvénient que la politique ne s'améliore pas avant la fin d'un jeu, et "la politique de comportement actuelle ne mène pas toujours à la fin du jeu". Il y a. Ce n'est pas le cas avec 2048 jeux, mais c'est un gros problème lors de son application à des jeux généraux (par exemple, des labyrinthes). La solution à ce stade est l'algorithme ** Q-Learning **, qui a été implémenté cette fois et sera expliqué ci-dessous.
2-2-1. Hors politique
Ici, nous ne définissons que les termes. Nous visons uniquement à améliorer la politique de comportement, mais si vous y réfléchissez attentivement, lorsqu'un agent joue et recueille des données, il n'est pas nécessaire de collecter des données selon la politique de comportement optimal actuelle. Par conséquent, considérons une méthode de "déplacement d'un agent selon une politique différente de la politique à améliorer et de collecte de données". C'est ce qu'on appelle la collecte de données ** hors politique **.
2-2-2. Politique cupide
Cela me rappelle un peu maintenant, mais je définis le terme ** Politique avide **. Il s'agit d'une «politique d'action qui n'a pas d'éléments probabilistes et qui continue de sélectionner des actions». La politique est telle que la probabilité conditionnelle $ \ pi (a \ | \ s) $ qui apparaît dans les équations (1) et (3) est 1 uniquement pour un a spécifique et 0 pour les autres actions. Il peut également être reformulé comme.
Dans la politique Greedy π, si l'état s est défini, une action est fixée, de sorte que l'action est exprimée comme $ \ pi (s) $.
A ce moment, en général,
Est obtenu. C'est ce qu'on appelle l'équation ** comportement-Bellman pour la fonction de valeur d'état **. Par cette formule, la valeur sur le côté gauche est calculée à l'aide de la récompense r lorsque l'action a est sélectionnée dans l'état s et l'état s ', $ q_ {\ pi} (s', \ pi (s ')) $ de la destination de la transition. Vous pouvez réessayer. De plus, avec cette formule, il n'est pas nécessaire de passer par la fonction de valeur d'état.
Ce qui suit est un aperçu de Q-Learning qui utilise l'équation (5).
2-2-3. Méthode TD
Dans l'algorithme expliqué au début, il était indiqué que la politique ne pouvait pas être améliorée sans attendre la fin d'une partie. D'autre part, il existe une méthode pour effectuer un traitement de mise à jour au moment où les données d'un tour sont collectées. C'est ce qu'on appelle la "** méthode TD (méthode de différence temporelle) **", et la méthode TD qui collecte les données hors politique est appelée Q-Learning. Dans ce cas, l'IA peut être intelligente lors de la collecte de données, vous pouvez donc éviter la situation où vous ne pouvez pas atteindre l'objectif du labyrinthe pour toujours.
La mise à jour est effectuée à l'aide de l'équation (5). La valeur de $ p (r, s '\ | \ s, a) $ est initialement inconnue, une valeur approximative est calculée à partir des données obtenues, et en collectant les données, la valeur se rapproche de la valeur vraie. Dans le même temps, la valeur de la fonction de valeur d'état d'action est également modifiée.
Cependant, dans le Q-Learning réel, il semble que la valeur soit corrigée par la formule suivante au lieu de la formule (5). (Le sentiment de rapprocher la valeur de la fonction de valeur de l'état d'action de $ r + q_ {\ pi} (s ', \ pi (s')) $ reste le même.)
α est un paramètre qui ajuste le poids de la correction, et est appelé ** taux d'apprentissage **. (C'est tout à fait ce que j'attends, mais c'est de la mémoire de conserver et de mettre à jour la valeur de $ p (r, s '\ | \ s, a) $ pour toutes les paires (s, a). Je pense qu'il y a de nombreux cas où c'est difficile.)
Oui. Je l'ai expliqué un peu vaguement vers la fin, mais pour être honnête, je n'ai pas utilisé cette formule dans la partie implémentation, donc j'étais un peu moins motivé. Quoi qu'il en soit, ce qui est important, c'est l'idée que vous pouvez obtenir une meilleure politique de comportement en mettant à jour la fonction de valeur d'état d'action tout en collectant des données avec hors politique et en choisissant l'action qui maximise cette valeur **. Le mécanisme de l'algorithme de production basé sur cela est montré ci-dessous, et la longue section de théorie est fermée.
2-3. DQN
Dans la section théorie, nous avons d'abord expliqué le mécanisme de base de l'apprentissage par renforcement, puis décrit une méthode appelée Q-Learning qui le rend plus efficace. Cependant, l'algorithme actuel a toujours un problème fatal. Le fait est que le processus d'apprentissage ne se termine pas lorsqu'il y a trop d'états possibles.
Avec les algorithmes conventionnels, même sous-estimés, le nombre d'états possibles doit être calculé et la valeur de la fonction de valeur d'état d'action doit être calculée pour tous les états (bien sûr, cela est répété plusieurs fois. Vous obtiendrez une meilleure politique). Le nombre d'opérations que Python peut effectuer par seconde est au maximum de 10 $ ^ {7} $ fois environ, tandis que le nombre d'états dans 2048 jeux est de 16 carrés sur le plateau, et il semble être d'environ 12 $ ^ {16} $. C'est vrai. Considérant que cela fait plusieurs fois le tour d'une boucle de cette longueur, il semble que l'apprentissage n'est jamais terminé. Si vous commencez à parler du nombre d'états du shogi et que vous partez, cela ne s'arrêtera jamais. (Je ne connais pas très bien la vitesse de calcul de Python, alors je l'ai écrit, mais cela ne s'arrête pas pour le moment.)
Afin de résoudre ce problème, ** DQN ** consiste à faire ressortir un excellent ** réseau de neurones ** et à faire du Q-Learning. DQN est un acronyme pour Deep Q Network.
2-3-1. Réseau neuronal
Encore une fois, je ne suivrai pas la théorie détaillée et le mécanisme des réseaux de neurones dans cet article. Ici, je décrirai la vision minimale du monde nécessaire pour comprendre le mécanisme d'apprentissage de 2048 Game AI. (En fait, je suis aussi une personne inexpérimentée, donc je suis désolée de ne pas connaître la profondeur.)
Les réseaux de neurones sont utilisés dans ** l'apprentissage en profondeur **, mais pour le dire clairement, il s'agit d'une «fonction». (L'entrée multi-variable et la sortie multi-variable sont les valeurs par défaut). Préparez un grand nombre de fonctions linéaires simples, passez-y l'entrée et ajoutez un peu de traitement. Après avoir répété cette opération dans plusieurs couches, la sortie est sortie sous une certaine forme. C'est un réseau neuronal. En modifiant le nombre de fonctions internes, le type de traitement et le nombre de couches, vous pouvez vraiment vous transformer de manière flexible en diverses fonctions. (Ci-après, le réseau neuronal est parfois abrégé en «NN».)
Et le réseau neuronal a une autre fonction importante. C'est le ** réglage des paramètres **. Auparavant, le contenu de NN était fixé et fonctionnait comme une fonction, mais en donnant la sortie de "bonne réponse" à NN en même temps que l'entrée, la valeur du paramètre inclus dans la fonction interne est sortie de sorte qu'une valeur proche de la bonne réponse soit sortie. Peut être modifié. Cela signifie que le réseau neuronal peut «apprendre» pour devenir une fonction avec les propriétés souhaitées.
Cette fois, nous utiliserons la puissance du framework ** TensorFlow ** pour l'implémentation, donc je pense qu'il est normal de comprendre le contenu pour le moment. Obenkyo saisira une autre occasion.
2-3-2. Réseau neuronal convolutif (CNN)
Il existe un type de NN appelé ** Convolution Neural Network **. C'est le type utilisé pour la reconnaissance d'image, etc., et il est préférable de saisir les caractéristiques de l'étalement bidimensionnel de l'entrée (tout comme la surface de la carte) plutôt que de simplement donner la valeur d'entrée. Je vais donc l'utiliser cette fois. C'est tout pour le moment.
2-3-3. Incorporer dans Q-Learning
La manière d'utiliser NN est de "créer un réseau neuronal qui calcule la valeur de la fonction de valeur d'état d'action à partir de l'état et de l'action de la carte". Il a été dit que la méthode conventionnelle pour trouver $ q_ {\ pi} (s, a) $ pour tous les états / actions était impossible, mais si un tel NN pouvait être créé, il serait "en quelque sorte similaire". Vous pouvez vous attendre à pouvoir choisir le meilleur coup en regardant le tableau qui dit "il y a une partie qui communique".
Je le comprends avec une expression. Similaire aux équations (5) et (6), le but de Q-Learning est de mettre à jour la valeur de $ q_ {\ pi} (s, a) $. Par conséquent, l'entrée de NN est également l'état de la carte elle-même + l'action sélectionnée.
Puisque nous voulons rapprocher le résultat du calcul de $ r + q_ {\ pi} (s ', \ pi (s')) $, nous utiliserons ceci comme "valeur de réponse correcte" et effectuerons le traitement d'apprentissage NN. Bien que ce ne soit que dans le domaine de "l'approximation des fonctions", on peut s'attendre à ce que les performances (précision approximative) s'améliorent régulièrement en répétant le processus de collecte de données et d'apprentissage.
Ce qui précède est une vue d'ensemble du DQN utilisé cette fois. Je pense que c'est plus rapide de regarder le code de l'histoire spécifique, donc je le posterai plus tard.
2-4. Résumé de la vision du monde
La section théorique est devenue plus longue que prévu (Gachi). Réorganisons l'ensemble de l'image ici et passons à la partie implémentation.
Dans l'apprentissage par renforcement, la politique d'action est améliorée afin que l'agent joue le jeu et que la récompense obtenue soit maximisée. --Action - Si la valeur de la fonction de valeur d'état peut être calculée avec précision pour chaque état / action, le meilleur mouvement sur toutes les cartes est connu. --Q-Learning consiste à collecter des données avec une politique hors-politique et à mettre à jour la valeur de la fonction de valeur d'état d'action à tout moment.
- Si le nombre d'états est trop grand, il est incontrôlable tel quel, de sorte que la fonction de valeur d'état de comportement est approximée et calculée à l'aide d'un réseau neuronal, et des données sont collectées pour effectuer ce processus d'apprentissage NN. (DQN)
Je vous remercie pour votre travail acharné! Même si vous ne comprenez pas bien, vous pouvez le comprendre en lisant le code, alors faites des allers-retours. Je suis désolé si mon résumé théorique n'est tout simplement pas bon. Au moins, il devrait y avoir des parties manquantes, donc si vous voulez étudier plus correctement, je pense que vous devriez essayer d'autres livres.
Cette fois c'est vraiment la fin de la théorie Passons au code ↓ ↓
3. Mise en œuvre
Ensuite, je mettrai de plus en plus de code. Peut-être que si vous le collez par le haut, il sera possible de le reproduire (bien qu'il ne soit pas possible d'obtenir exactement le même résultat car il est plein de codes impliquant des nombres aléatoires). Aussi, pardonnez-moi si vous pouvez voir du code inesthétique à divers endroits.
Pour le moment, seuls les éléments à importer sont collés ici. Veuillez faire tous les codes suivants sur cette hypothèse. (Veuillez noter qu'il peut en fait contenir des modules inutiles)
2048.py
import numpy as np
import copy, random, time
from tensorflow.keras import layers, models
from IPython.display import clear_output
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib
matplotlib.rcParams['font.size'] = 20
import pickle
from tensorflow.keras.models import load_model
3-1. Définition de la classe de jeu
Tout d'abord, implémentez 2048 jeux sur le code. C'est long, mais le contenu est mince, alors regardez-le avec cette intention. Il n'est pas limité à ce code, mais il vaut peut-être mieux le regarder car il a un commentaire japonais à la fin. Puis.
2048.py
class Game:
def __init__(self):
self.restart()
def restart(self):
self.board = np.zeros([4,4])
self.score = 0
y = np.random.randint(0,4)
x = np.random.randint(0,4)
self.board[y][x] = 2
while(True):
y = np.random.randint(0,4)
x = np.random.randint(0,4)
if self.board[y][x]==0:
self.board[y][x] = 2
break
def move(self, a):
reward = 0
if a==0:
for y in range(4):
z_cnt = 0
prev = -1
for x in range(4):
if self.board[y][x]==0: z_cnt += 1
elif self.board[y][x]!=prev:
tmp = self.board[y][x]
self.board[y][x] = 0
self.board[y][x-z_cnt] = tmp
prev = tmp
else:
z_cnt += 1
self.board[y][x-z_cnt] *=2
reward += self.board[y][x-z_cnt]
self.score += self.board[y][x-z_cnt]
self.board[y][x] = 0
prev = -1
elif a==1:
for x in range(4):
z_cnt = 0
prev = -1
for y in range(4):
if self.board[y][x]==0: z_cnt += 1
elif self.board[y][x]!=prev:
tmp = self.board[y][x]
self.board[y][x] = 0
self.board[y-z_cnt][x] = tmp
prev = tmp
else:
z_cnt += 1
self.board[y-z_cnt][x] *= 2
reward += self.board[y-z_cnt][x]
self.score += self.board[y-z_cnt][x]
self.board[y][x] = 0
prev = -1
elif a==2:
for y in range(4):
z_cnt = 0
prev = -1
for x in range(4):
if self.board[y][3-x]==0: z_cnt += 1
elif self.board[y][3-x]!=prev:
tmp = self.board[y][3-x]
self.board[y][3-x] = 0
self.board[y][3-x+z_cnt] = tmp
prev = tmp
else:
z_cnt += 1
self.board[y][3-x+z_cnt] *= 2
reward += self.board[y][3-x+z_cnt]
self.score += self.board[y][3-x+z_cnt]
self.board[y][3-x] = 0
prev = -1
elif a==3:
for x in range(4):
z_cnt = 0
prev = -1
for y in range(4):
if self.board[3-y][x]==0: z_cnt += 1
elif self.board[3-y][x]!=prev:
tmp = self.board[3-y][x]
self.board[3-y][x] = 0
self.board[3-y+z_cnt][x] = tmp
prev = tmp
else:
z_cnt += 1
self.board[3-y+z_cnt][x] *= 2
reward += self.board[3-y+z_cnt][x]
self.score += self.board[3-y+z_cnt][x]
self.board[3-y][x] = 0
prev = -1
while(True):
y = np.random.randint(0,4)
x = np.random.randint(0,4)
if self.board[y][x]==0:
if np.random.random() < 0.2: self.board[y][x] = 4
else: self.board[y][x] = 2
break
return reward
J'ai décidé de laisser la classe Game gérer le "board" et le "score". Comme son nom l'indique, il s'agit du tableau et du score actuel. board est représenté par un tableau numpy à deux dimensions.
Par la méthode «restart», les tuiles de «2» sont placées à deux endroits aléatoires sur le plateau, le score est fixé à 0 et le jeu est lancé. (Dans l'explication des règles au chapitre 1, j'ai dit que "2" ou "4" est placé sur le plateau initial, mais que "2" apparaît dans le code. C'est alors que j'ai implémenté la classe Game. Au début, j'ai mal compris qu'il ne s'agissait que de "2". Veuillez pardonner car cela n'a pratiquement aucun effet sur le jeu.)
La méthode move prend le type d'action comme argument, change le tableau en conséquence et ajoute le score. En tant que valeur de retour, le score ajouté dans ce tour est retourné, qui sera utilisé plus tard. (Dans cette étude, le score en jeu a été utilisé tel quel comme "récompense" que l'agent obtient). Les actions sont représentées par des nombres entiers de 0 à 3 et sont associées respectivement à gauche, haut, droite et bas. La mise en œuvre des changements de carte est un malaxage d'index inutilement long, probablement moins lisible. Vous n'êtes pas obligé de le lire sérieusement. Il est peut-être possible d’écrire plus joliment, mais pardonnez-moi ici (´ × ω × `)
De plus, dans la dernière boucle while, une nouvelle tuile est générée. Cela peut aussi être une implémentation inefficace en termes d'algorithme, mais je l'ai frappé de force. Je regrette ça. Une tuile de "2" ou "4" est générée, mais à la suite des statistiques de lumière de l'auteur, il s'agissait de "2 va surgir avec une probabilité de 80%", donc je l'ai implémentée de cette façon. En fait, c'est peut-être un peu décalé, mais cette fois, nous le ferons.
Notez que la méthode move suppose qu'une action" sélectionnable "est entrée. (Parce que la direction dans laquelle le plateau ne bouge pas ne peut pas être sélectionnée pendant la lecture.) Pour cela, utilisez la fonction suivante.
3-2. Jugement des actions sélectionnables
Dans le futur, il y aura de nombreuses situations où vous voudrez savoir si chaque action est "sélectionnable" sur chaque carte, comme lors de l'entrée dans la méthode move ci-dessus. Par conséquent, nous avons préparé ʻis_invalid_action` comme fonction de jugement. Veuillez noter qu'il donne le tableau et l'action, et renvoie Vrai si c'est une action qui ne peut pas être sélectionnée.
De plus, ce code est très similaire à la méthode move et est simplement inutilement long, il est donc plié dans le triangle ci-dessous. Veuillez le fermer dès que vous copiez et collez le contenu. Parce que ce n'est pas bon.
`is_invalid_action`
2048.py
def is_invalid_action(state, a):
spare = copy.deepcopy(state)
if a==0:
for y in range(4):
z_cnt = 0
prev = -1
for x in range(4):
if spare[y][x]==0: z_cnt += 1
elif spare[y][x]!=prev:
tmp = spare[y][x]
spare[y][x] = 0
spare[y][x-z_cnt] = tmp
prev = tmp
else:
z_cnt += 1
spare[y][x-z_cnt] *= 2
spare[y][x] = 0
prev = -1
elif a==1:
for x in range(4):
z_cnt = 0
prev = -1
for y in range(4):
if spare[y][x]==0: z_cnt += 1
elif spare[y][x]!=prev:
tmp = spare[y][x]
spare[y][x] = 0
spare[y-z_cnt][x] = tmp
prev = tmp
else:
z_cnt += 1
spare[y-z_cnt][x] *= 2
spare[y][x] = 0
prev = -1
elif a==2:
for y in range(4):
z_cnt = 0
prev = -1
for x in range(4):
if spare[y][3-x]==0: z_cnt += 1
elif spare[y][3-x]!=prev:
tmp = spare[y][3-x]
spare[y][3-x] = 0
spare[y][3-x+z_cnt] = tmp
prev = tmp
else:
z_cnt += 1
spare[y][3-x+z_cnt] *= 2
spare[y][3-x] = 0
prev = -1
elif a==3:
for x in range(4):
z_cnt = 0
prev = -1
for y in range(4):
if spare[3-y][x]==0: z_cnt += 1
elif spare[3-y][x]!=prev:
tmp = state[3-y][x]
spare[3-y][x] = 0
spare[3-y+z_cnt][x] = tmp
prev = tmp
else:
z_cnt += 1
spare[3-y+z_cnt][x] *= 2
spare[3-y][x] = 0
prev = -1
if state==spare: return True
else: return False
3-3. Visualisation de la surface du panneau
L'IA peut apprendre sans aucun problème même s'il n'y a pas de fonction pour montrer le tableau, mais nous l'avons fait parce que nous, les humains, sommes seuls. Cependant, le sujet principal n'est pas là, donc j'ai beaucoup coupé avec l'excuse.
2048.py
def show_board(game):
fig = plt.figure(figsize=(4,4))
subplot = fig.add_subplot(1,1,1)
board = game.board
score = game.score
result = np.zeros([4,4])
for x in range(4):
for y in range(4):
result[y][x] = board[y][x]
sns.heatmap(result, square=True, cbar=False, annot=True, linewidth=2, xticklabels=False, yticklabels=False, vmax=512, vmin=0, fmt='.5g', cmap='prism_r', ax=subplot).set_title('2048 game!')
plt.show()
print('score: {0:.0f}'.format(score))
Je n'ai reproduit que les fonctions minimales en utilisant la carte de chaleur (vraiment le minimum). Vous n'avez pas besoin de lire les détails à ce sujet, je pense que vous pouvez simplement copier la mort cérébrale. Voici à quoi cela ressemble réellement.
Supplément: Conflits liés aux cartes thermiques C'est une histoire vraiment ridicule, mais lors de la mise en œuvre du jeu 2048, il y avait une idée "d'utiliser des nombres simplement comme 1,2,3 ... au lieu d'une puissance de 2." La raison en est qu'il n'y a qu'un seul point, et cette fonction de visualisation colorera le tableau plus joliment. Cependant, cela ne ressemblait pas à 2048 en tant que jeu, et j'avais l'intuition que je ne pouvais pas bien apprendre le tableau, donc ça s'est terminé comme ça. En conséquence, comme vous pouvez le voir, les petits nombres sont de couleur très proche et difficiles à voir. N'y a-t-il pas une carte thermique qui change de couleur sur l'axe logarithmique?
3-4. Jouer
Si vous voulez juste apprendre, cette étape est complètement inutile, mais comme c'est un gros problème, jouons au jeu python version 2048, j'ai donc écrit une telle fonction. C'est aussi assez bâclé et vous n'avez pas à le lire sérieusement. Si vous faites de votre mieux, vous pouvez rendre l'interface utilisateur aussi confortable que vous le souhaitez, mais ce n'est pas le sujet principal, je vais donc le laisser.
2048.py
def human_play():
game = Game()
show_board(game)
while True:
a = int(input())
if(is_invalid_action(game.board.tolist(),a)):
print('cannot move!')
continue
r = game.move(a)
clear_output(wait=True)
show_board(game)
Maintenant, si vous exécutez human_play (), le jeu démarre. Entrez un nombre de 0 à 3 pour déplacer le plateau.
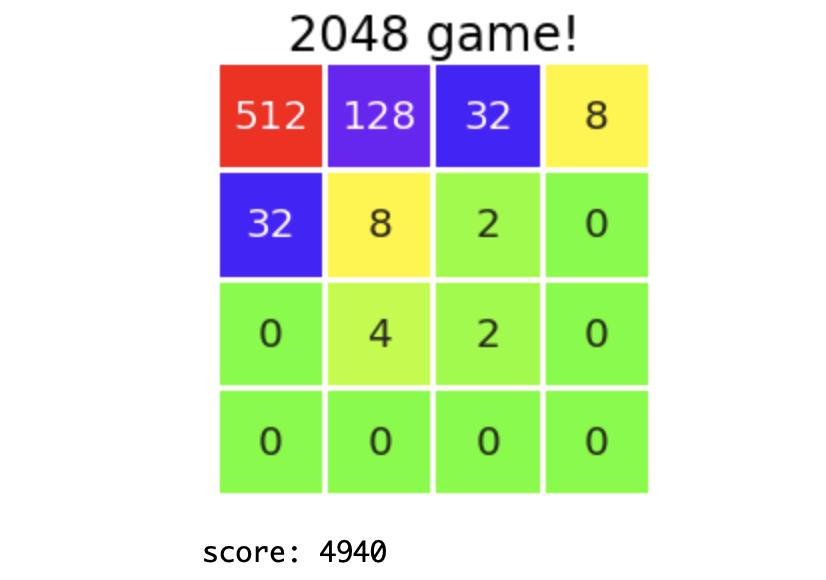
Le tableau apparaît comme ceci et vous pouvez jouer. Après tout, il est difficile de voir le tableau. À propos, avec ce code, au moment où vous entrez accidentellement autre chose qu'un nombre, le jeu est terminé sans poser de questions. Je ne connais pas l'interface utilisateur. De plus, comme cela n'a pas de jugement de fin de jeu, si vous ne pouvez pas le déplacer, sortons du jeu en faisant une entrée étrange en profitant des spécifications précédentes. Je ne connais pas l'interface utilisateur.
Laissons l'ordinateur jouer à ce jeu à ce moment.
2048.py
def random_play(random_scores):
game = Game()
show_board(game)
gameover = False
while(not gameover):
a_map = [0,1,2,3]
is_invalid = True
while(is_invalid):
a = np.random.choice(a_map)
if(is_invalid_action(game.board.tolist(),a)):
a_map.remove(a)
if(len(a_map)==0):
gameover = True
is_invalid = False
else:
r = game.move(a)
is_invalid = False
time.sleep(1)
clear_output(wait=True)
show_board(game)
random_scores.append(game.score)
Je vous ai dit de laisser jouer l'ordinateur, mais c'est une fonction qui vous permet de voir ce qui se passe lorsque vous choisissez une main de manière complètement aléatoire. Prenez un tableau approprié comme argument (ligne cachée). Cet argument n'a pas d'importance pour la visualisation, alors exécutons-le de manière appropriée comme random_play ([]). Le jeu progresse comme une animation.
Comme vous pouvez le voir sur la vue, à ce stade, il n'y a aucune sensation de jouer avec la volonté (naturellement parce que c'est aléatoire). Par conséquent, saisissons la capacité (score moyen, etc.) à ce stade. J'ai pris un tableau comme argument pour faire cela. Dans la fonction random_play, commentez le code lié à la visualisation de la carte (3ème ligne à partir du haut et 2ème à 4ème lignes à partir du bas), puis exécutez le code suivant.
2048.py
random_scores = []
for i in range(1000):
random_play(random_scores)
print(np.array(random_scores).mean())
print(np.array(random_scores).max())
print(np.array(random_scores).min())
J'ai fait un test de jeu 1000 fois et j'ai vérifié le score moyen, le score le plus élevé et le score le plus bas. L'exécution se termine bientôt de manière inattendue. Le résultat changera légèrement en fonction de l'exécution, mais entre mes mains
- Score moyen: ** 1004,676 points **
- Meilleur score: ** 2832 points **
- Score le plus bas: ** 80 points **
J'ai eu le résultat. On peut dire que c'est la puissance de l'IA qui n'a rien appris. Donc, si vous obtenez bien au-dessus de 1000 points en moyenne, vous pouvez dire que vous avez un peu appris. De plus, comme le score le plus élevé de 1000 pièces correspond à ce niveau, on peut considérer qu'un score supérieur à 3000 est un domaine difficile à atteindre avec de la chance seule. Considérons les résultats d'apprentissage ultérieurs basés sur ce domaine.
3-5. Création d'un réseau neuronal
Ici, nous allons mettre en œuvre un réseau de neurones, qui est la personne qui calcule la valeur de la fonction de valeur d'état de comportement et reçoit également les données collectées pour l'apprentissage. Cependant, toute cette partie gênante prend la forme d'un lancer rond dans ** TensorFlow **, vous pouvez donc considérer la boîte noire comme une boîte noire. Pour le moment, tenez le code.
2048.py
class QValue:
def __init__(self):
self.model = self.build_model()
def build_model(self):
cnn_input = layers.Input(shape=(4,4,1))
cnn = layers.Conv2D(8, (3,3), padding='same', use_bias=True, activation='relu')(cnn_input)
cnn_flatten = layers.Flatten()(cnn)
action_input = layers.Input(shape=(4,))
combined = layers.concatenate([cnn_flatten, action_input])
hidden1 = layers.Dense(2048, activation='relu')(combined)
hidden2 = layers.Dense(1024, activation='relu')(hidden1)
q_value = layers.Dense(1)(hidden2)
model = models.Model(inputs=[cnn_input, action_input], outputs=q_value)
model.compile(loss='mse')
return model
def get_action(self, state):
states = []
actions = []
for a in range(4):
states.append(np.array(state))
action_onehot = np.zeros(4)
action_onehot[a] = 1
actions.append(action_onehot)
q_values = self.model.predict([np.array(states), np.array(actions)])
times = 0
first_a= np.argmax(q_values)
while(True):
optimal_action = np.argmax(q_values)
if(is_invalid_action(state, optimal_action)):
q_values[optimal_action][0] = -10**10
times += 1
else: break
if times==4:
return first_a, 0, True #gameover
return optimal_action, q_values[optimal_action][0], False #not gameover
Il est implémenté sous la forme de la classe QValue. Cette instance devient la cible d'apprentissage elle-même (pour être exact, sa variable membre «model»). Et la méthode build_model dans la première moitié est une fonction qui est exécutée au moment de l'instanciation et crée un réseau neuronal.
Je donnerai un aperçu de la méthode build_model, mais je n'expliquerai pas chaque" langage NN "en détail. Hmmm, je pense que ça va. Je pense que ceux qui sont bien informés valent la peine d'être lus. (En même temps, il peut y avoir place à l'amélioration. S'il vous plaît, apprenez-moi ...)
J'utiliserai le réseau de neurones convolutifs (CNN) dont j'ai parlé dans la section théorie. C'est parce que je m'attendais à capturer l'étendue bidimensionnelle de la planche. En entrée, nous prenons un tableau 4x4 qui correspond à la surface de la carte et un tableau de longueur 4 qui correspond à la sélection des actions. La sélection d'action est effectuée par le ** codage à chaud **, dans lequel l'un des quatre emplacements est représenté par un tableau de 1 et le reste est représenté par un tableau de 0, au lieu d'entrer de 0 à 3. Huit types de filtres 3x3 sont utilisés pour le pliage. Il spécifie également la fonction de remplissage, de biais et d'activation. En tant que couches cachées, nous avons préparé une couche avec 2048 neurones et une couche avec 1024 neurones, et finalement défini la couche de sortie. ReLU est utilisé comme fonction d'activation de la couche cachée. De plus, l'erreur quadratique minimale est adoptée comme fonction d'erreur utilisée pour le réglage des paramètres.
L'explication sur NN est arrondie ici. Même si vous ne comprenez pas du tout, ce n'est pas grave si vous pensez simplement que vous avez défini NN, même si vous ne connaissez pas le contenu.
Il existe une autre méthode appelée get_action. Cela correspond à l'étape de "calcul de la valeur de la fonction de valeur d'état d'action avec un réseau neuronal". En prenant l'état de la carte «state» comme argument, préparez des expressions one-hot pour quatre types d'actions et insérez quatre entrées dans le NN. Cette intrusion peut être effectuée avec la méthode "prédire" fournie à l'origine par tensorflow. En tant que sortie de NN, la valeur de la fonction de valeur d'état d'action pour quatre types d'actions dans l'état est renvoyée. Le rôle général de cette méthode est d'obtenir l'action avec la plus grande valeur avec la fonction np.argmax.
Je me trompe dans la seconde moitié, mais cela vérifie si l'action sélectionnée à partir de la valeur de la fonction de valeur d'état d'action peut être sélectionnée (mobile) sur le tableau. Si cela n'est pas possible, sélectionnez à nouveau l'action qui augmente la valeur de la fonction de valeur d'état d'action. En plus de cela, cette méthode détermine également que le jeu est terminé. Il y a trois valeurs de retour pour la méthode get_action, mais dans cet ordre," l'action sélectionnée, l'action pour ce plateau / action - la valeur de la fonction de valeur d'état, et si le plateau est game over ou non ".
3-6. Jouez au jeu basé sur l'apprentissage
J'ai essayé de le jouer de manière complètement aléatoire plus tôt, mais cette fois, je vais le jouer en incorporant les résultats d'apprentissage. La fonction suivante get_episode jouera une partie. (Dans l'apprentissage par renforcement, un jeu est souvent appelé ** épisode **.)
2048.py
def get_episode(game, q_value, epsilon):
episode = []
game.restart()
while(True):
state = game.board.tolist()
if np.random.random() < epsilon:
a = np.random.randint(4)
gameover = False
if(is_invalid_action(state, a)):
continue
else:
a, _, gameover = q_value.get_action(state)
if gameover:
state_new = None
r = 0
else:
r = game.move(a)
state_new = game.board.tolist()
episode.append((state, a, r, state_new))
if gameover: break
return episode
Préparez un tableau appelé «épisode», jouez à un jeu, créez un ensemble «état actuel, action sélectionnée, récompense obtenue à ce moment-là, état de destination de la transition» et stockez-le de plus en plus dans le tableau. C'est l'opération de base. Les données collectées ici seront utilisées pour un traitement d'apprentissage ultérieur. Pour sélectionner une action, utilisez la méthode q_value.get_action définie précédemment. Cela sélectionnera le meilleur coup sur place (et avec vos capacités actuelles). De plus, la fin de l'épisode est détectée en utilisant le jeu sur le jugement effectué par cette méthode.
Une chose à noter est que «il ne suit pas toujours les résultats d'apprentissage à chaque tour». La fonction get_episode prend un argument de ʻepsilon`, qui est la" probabilité de sélectionner aléatoirement une action pendant la lecture sans suivre le résultat d'apprentissage ". En mélangeant des sélections d'actions aléatoires, vous pouvez apprendre des tableaux plus diversifiés et espérer devenir une IA plus intelligente.
De cette manière, la politique d'action qui "sélectionne essentiellement une action avec la politique Greedy, mais mélange des actions aléatoires avec une probabilité de $ \ epsilon $" est appelée la ** politique ε-Greedy **. Dans quelle mesure fixer la valeur de ε est une question importante et difficile. (Habituellement, il est d'environ 0,1 à 0,2.)
Cette fonction peut également être jouée avec la politique Greedy en définissant ʻepsilon = 0. En d'autres termes, c'est un jeu de "pleine puissance de l'IA" à ce moment-là, sans compter les actions aléatoires. La fonction show_sample` pour mesurer la capacité d'AI-kun est illustrée ci-dessous.
2048.py
def show_sample(game, q_value):
epi = get_episode(game, q_value, epsilon=0)
n = len(epi)
game = Game()
game.board = epi[0][0]
# show_board(game)
for i in range(1,n):
game.board = epi[i][0]
game.score += epi[i-1][2]
# time.sleep(0.2)
# clear_output(wait=True)
# show_board(game)
return game.score
Cependant, la base est d'exécuter la fonction get_episode sous ʻepsilon = 0, et après cela, le tableau est reproduit en utilisant l'enregistrement de l'épisode. C'est comme suivre le score d'échecs en shogi. Il y a une partie commentée dans la fonction, mais si vous annulez cela, vous pouvez la voir avec une animation. (Comme pour la fonction random_play, vous pouvez contrôler la vitesse de l'animation en ajustant la valeur donnée à time.sleep.) Le score final est affiché comme valeur de retour. En utilisant ceci, vous pouvez approximativement saisir le résultat de l'apprentissage en insérant show_sample` entre les processus d'apprentissage.
Maintenant, implémentons l'algorithme d'apprentissage!
3-7. Processus d'apprentissage
Définissez une fonction «train» qui entraîne NN. C'est un peu long, mais ce n'est pas si difficile, alors lisez-le calmement. Je vais l'expliquer un peu attentivement.
2048.py
def train(game, q_value, num, experience, scores):
for c in range(num):
print()
print('Iteration {}'.format(c+1))
print('Collecting data', end='')
for n in range(20):
print('.', end='')
if n%10==0: epsilon = 0
else: epsilon = 0.1
episode = get_episode(game, q_value, epsilon)
experience += episode
if len(experience) > 50000:
experience = experience[-50000:]
if len(experience) < 5000:
continue
print()
print('Training the model...')
examples = experience[-1000:] + random.sample(experience[:-1000], 2000)
np.random.shuffle(examples)
states, actions, labels = [], [], []
for state, a, r, state_new in examples:
states.append(np.array(state))
action_onehot = np.zeros(4)
action_onehot[a] = 1
actions.append(action_onehot)
if not state_new:
q_new = 0
else:
_1, q_new, _2 = q_value.get_action(state_new)
labels.append(np.array(r+q_new))
q_value.model.fit([np.array(states), np.array(actions)], np.array(labels), batch_size=250, epochs=100, verbose=0)
score = show_sample(game, q_value)
scores.append(score)
print('score: {:.0f}'.format(score))
Il y a 5 arguments, dans l'ordre "Game class instance game, modèle à entraîner (instance QValue) q_value, nombre de fois à apprendre num, tableau pour stocker les données collectées ʻexperience`, résultat d'apprentissage C'est un tableau "scores" "à mettre (scores). Faites un suivi pour plus de détails.
La boucle est tournée de la quantité de «num». Ici, «l'apprentissage ponctuel» est complètement différent du jeu en une seule partie. Je vais expliquer le déroulement d'un apprentissage.
L'apprentissage est divisé en deux étapes: la collecte des données et la mise à jour de NN. Dans la partie collecte de données, la fonction get_episode est activée 20 fois (en bref, le jeu est joué 20 fois). Fondamentalement, les données sont collectées par la politique ε-Greedy de ε = 0,1, mais seulement deux fois sur 20, jouez avec la politique Greedy (ε = 0) qui ne mélange pas les actions aléatoires et collecte les données. En mélangeant ainsi les deux types de jeu, il semble qu'il sera plus facile d'apprendre un large éventail de plateaux et d'incorporer le plateau lorsque le jeu progresse longtemps.
Toutes les données collectées seront mises en «expérience». Si la longueur de ce tableau dépasse 50000, les données les plus anciennes seront supprimées. La prochaine étape de mise à jour du modèle est ignorée jusqu'à ce que 5000 éléments de données soient collectés.
Pour mettre à jour le modèle, extrayez les données de ʻexperience et créez un nouveau tableau ʻexample. A ce moment, 1000 pièces sont sélectionnées à partir des dernières données et 2000 pièces sont sélectionnées au hasard dans la partie restante et mélangées. En faisant cela, il semble que les résultats d'apprentissage sont moins susceptibles d'être biaisés lors de l'incorporation de nouvelles données dans l'apprentissage.
Dans la prochaine instruction for, nous examinerons le contenu de «exemple» un par un. Puisqu'il est plus efficace en termes de vitesse de calcul de saisir les NN collectivement que de recevoir des données individuelles, nous nous y préparerons. Dans states, ʻactions et labels`, entrez le tableau actuel, l'expression one-hot de l'action à sélectionner et la valeur" correcte "de la fonction de valeur d'état d'action à ce moment.
Concernant la valeur de la bonne réponse, celle-ci est définie comme $ r + q_ {\ pi} (s ', \ pi (s')) $ comme expliqué dans l'édition théorique "2-2-3. Méthode TD". Ce faisant, la sortie de NN sera modifiée pour se rapprocher ici. Cela équivaut à «r + q_new» dans le code. q_new est la" valeur attendue de la récompense qui sera obtenue si vous agissez selon la politique actuelle à partir de l'état de destination de la transition ", c'est le deuxième état lorsque l'état suivant est donné à la méthode q_value.get_action. Puisqu'il correspond à la sortie (l'état suivant et l'action pour le meilleur déplacement - la valeur de la fonction de valeur d'état), il est acquis comme tel. De plus, q_new est mis à 0 pour l'état de game over.
NN s'entraîne avec la méthode q_value.model.fit suivante. Veuillez laisser ce contenu séparément. NN entrées «states» et «actions» sont données comme arguments, et «labels» sont donnés comme des valeurs correctes. Vous n'avez pas à vous soucier de batch_size et epochs, mais la définition de ces valeurs affectera la précision de votre apprentissage (je ne suis pas entièrement sûr que ce soit le bon réglage). verbose = 0 supprime uniquement les sorties de journal inutiles.
Une fois le processus d'apprentissage par la méthode fit terminé, démarrez la fonction show_sample et laissez AI jouer de toutes ses forces. Lors de la sortie du score final sous forme de journal, il est stocké dans le tableau scores et utilisé plus tard pour calculer le score moyen. Ce qui précède est le tableau complet de "un apprentissage". La fonction train répète cela.
Supplément sur `batch_size` et ʻepochs` J'ai dit que vous n'avez pas à vous en soucier, mais je pense que cela vaut la peine d'en connaître le contour, alors je vais les organiser légèrement. Dans l'apprentissage NN, au lieu d'apprendre les données d'entrée en une seule fois, elles sont divisées en petits morceaux appelés ** mini-batch **, puis chaque lot est appris. La taille de ce lot est «batch_size». Dans le code ci-dessus, la taille d'entrée est de 3000 et batch_size est de 250, il est donc divisé en 12 mini-lots. Ensuite, effectuer le processus d'apprentissage une fois pour toutes les données d'entrée est compté dans l'unité de ** epoch **. Dans le code ci-dessus, 3000 entrées et 12 lots feront 1 époque. Le paramètre «epochs» indique combien d'époques le processus d'apprentissage doit être répété. Puisque epochs = 100 est défini ici, le flux de division par lots → l'apprentissage de tout sera répété 100 fois. C'est un résumé approximatif, mais les réseaux de neurones sont difficiles \ (^^) /
4. Exécution et observation de l'apprentissage
C'est la fin de l'implémentation du modèle / de la fonction. Après cela, apprenons et voyons comment cela se développe! J'écris aussi facilement des articles ...
Attention: À propos des résultats d'apprentissage affichés ici C'est comme si le code que vous avez exécuté et le résultat étaient publiés dans l'article tels quels, mais en réalité, le processus d'apprentissage est partiellement différent car vous avez procédé à l'apprentissage en le bricolant et en le modifiant. (Plus précisément, les données ont été collectées avec ε = 0,2 pour les 30 premières fois, et autrefois, les spécifications de la méthode `get_action` étaient légèrement différentes. Les données ont été supprimées au milieu). Veuillez noter que seulement. De plus, la sortie de 10 fois d'apprentissage affichée immédiatement après cela est complétée par la ré-exécution du code plus tard (la sortie à ce moment-là a été époustouflée), et elle est différente de l'enregistrement d'apprentissage du modèle à considérer dans le futur. .. Ne regardez pas de trop près> <
4-1. Essayez le train
Tout d'abord, créez une instance de la classe Game et de la classe QValue, et d'autres.
2048.py
game1 = Game()
q_value1 = QValue()
exp1 = []
scores1 = []
La numérotation 1 n'a pas de signification particulière. En quelque sorte. Avec cela, la préparation à l'apprentissage est terminée. Commençons la fonction train.
2048.py
%%time
train(game1, q_value1, 10, exp1, scores1)
Seulement ça. Cela fera 10 sessions d'apprentissage. Le %% time sur la première ligne est comme une commande magique et mesure le temps nécessaire à l'exécution. La raison en est que l'apprentissage prend beaucoup de temps. Cela prend environ 30 minutes juste pour ces 10 fois. Cependant, puisque la fonction «train» est implémentée de telle sorte que l'état d'avancement soit affiché à tout moment, c'est plus facile que de traverser l'obscurité invisible. Jetons un coup d'œil à la sortie.
Iteration 1
Collecting data....................
Iteration 2
Collecting data....................
Iteration 3
Collecting data....................
Training the model...
score: 716
Iteration 4
Collecting data....................
Training the model...
score: 908
Iteration 5
Collecting data....................
Training the model...
score: 596
...
Comme ʻIteration 3, vous pouvez voir immédiatement combien de boucles vous bouclez actuellement. La partie de collecte de données est affichée pendant que Collecting data ... 'est affiché, et la partie de mise à jour du modèle est affichée pendant que Training the model ...' est affiché. Dans les deux premiers temps, la longueur de ʻexp1 n'a pas atteint 5000 et la mise à jour du modèle est ignorée.
Après chaque apprentissage, une partie est jouée sans aucune action aléatoire et le score est affiché. Ce résultat est stocké dans scores1, vous pouvez donc collecter des statistiques plus tard.
Tout ce que vous avez à faire est de répéter ceci. Exécutez le code suivant pour effectuer 90 apprentissages supplémentaires.
2048.py
%%time
train(game1, q_value1, 90, exp1, scores1)
ʻExp1etscores1` sont réutilisés, et l'apprentissage procède complètement de la suite précédente.
Comme vous pouvez le voir, cet apprentissage prend vraiment du temps. Dans mon environnement, il semble que 5 à 6 heures par 100 fois. Récemment, Mac-kun gémissait toute la nuit pendant que je dormais. Si vous êtes intéressé, vous pouvez avoir la même expérience en trouvant du temps et en procédant au calcul.
En supposant que 100 apprentissages ont été achevés, traçons grossièrement les changements du «score de pleine puissance» pendant cette période. Utilisez scores1.
2048.py
x = np.arange(len(scores1))
plt.plot(x, scores1)
plt.show()
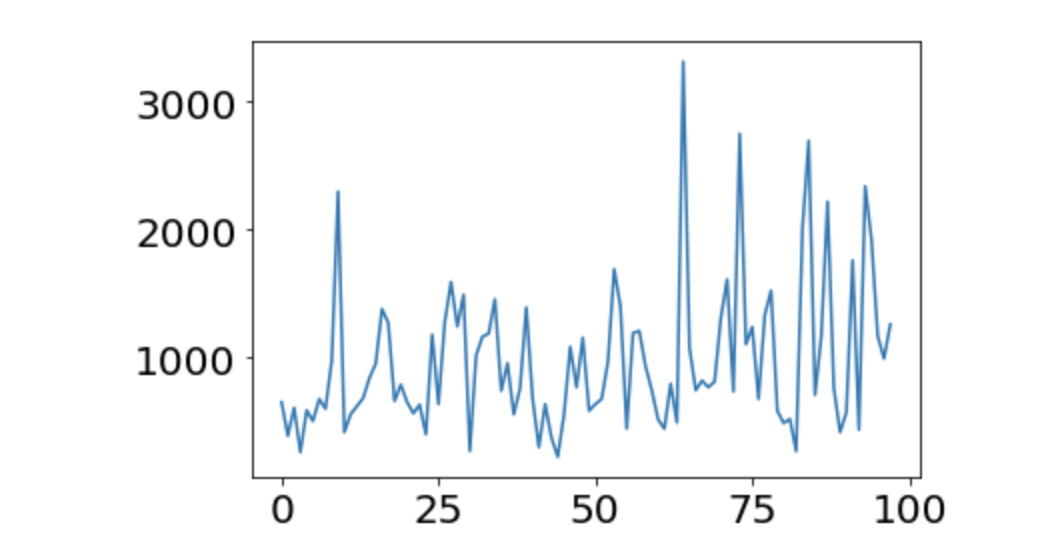
Hmm. Il est difficile de dire que c'est un peu appris. Le score moyen était de 974,45. Ça ne grandit pas du tout. Il semble qu'un peu plus d'apprentissage soit nécessaire.
4-2. Enregistrer temporairement les résultats d'apprentissage
Cet apprentissage est susceptible d'être un long voyage, alors établissons uniquement la méthode de conservation. Vous pouvez enregistrer ʻexp1 et scores1` avec la fonction ** pickle ** de python. Pickle ne peut pas être utilisé pour le modèle tensorflow, mais la fonction de sauvegarde est fournie à l'origine. Le code est affiché ci-dessous, alors enregistrez-le avec un nom descriptif.
2048.py
wfile = open('filename1.pickle', 'wb')
pickle.dump(exp1, wfile)
pickle.dump(scores1, wfile)
wfile.close()
q_value1.model.save('q_backup.h5')
Pour récupérer l'objet enregistré, procédez comme suit.
2048.py
myfile = open('filename1.pickle', 'rb')
exp1_r = pickle.load(myfile)
scores1_r = pickle.load(myfile)
q_value1_r = QValue()
q_value1_r.model = load_model('q_backup.h5')
Le r après le nom est censé être un acronyme pour restaurer. q_value1 y stocke le modèle, pas l'instance QValue, donc après avoir créé uniquement l'instance, chargez le modèle et remplacez-le. Comme l'instance de classe Game n'est pas spécialement apprise, il n'y a pas de problème si vous en créez une nouvelle si nécessaire.
Il est recommandé de garder une trace de l'apprentissage diligemment comme ceci. Non seulement cela peut être une contre-mesure lorsque les données volent au milieu, mais il est également possible de tirer le modèle au milieu de l'apprentissage plus tard et de comparer les performances. (Je regrette de ne pas avoir fait ça.)
4-3. Répéter le train
J'ai senti que le modèle entraîné 100 fois était encore inexpérimenté, alors j'ai simplement activé la fonction train. De la conclusion, je leur ai fait apprendre 1500 fois. Cela prend environ 4 jours, même sans interruption, alors soyez prêt si vous voulez imiter ...
Pour le moment, j'ai légèrement analysé 1500 fois des «scores». Les scores ont été appris 100 fois chacun, et la bande de score a été divisée par 1000 points, et le tableau montre si les scores pour chaque bande de score ont été obtenus. J'ai également calculé le score moyen, donc je vais les organiser. Ce n'est pas facile à expliquer avec des mots, alors je vais garder la table. (Pour référence, je publierai également la distribution des scores des 1000 jeux complètement aléatoires de Tokizoya.)
| Nombre d'apprentissage | 0000~ | 1000~ | 2000~ | 3000~ | 4000~ | 5000~ | average |
|---|---|---|---|---|---|---|---|
| Aléatoire | 529 | 415 | 56 | 0 | 0 | 0 | 1004.68 |
| 1~100 | 61 | 30 | 6 | 1 | 0 | 0 | 974.45 |
| 101~200 | 44 | 40 | 9 | 6 | 1 | 0 | 1330.84 |
| 201~300 | 33 | 52 | 12 | 1 | 0 | 0 | 1234.00 |
| 301~400 | 35 | 38 | 18 | 7 | 2 | 0 | 1538.40 |
| 401~500 | 27 | 52 | 18 | 3 | 0 | 0 | 1467.12 |
| 501~600 | 49 | 35 | 11 | 4 | 1 | 0 | 1247.36 |
| 601~700 | 23 | 50 | 20 | 5 | 2 | 0 | 1583.36 |
| 701~800 | 45 | 42 | 11 | 2 | 0 | 0 | 1200.36 |
| 801~900 | 38 | 42 | 16 | 4 | 0 | 0 | 1396.08 |
| 901~1000 | 19 | 35 | 40 | 4 | 0 | 2 | 1876.84 |
| 1001~1100 | 21 | 49 | 26 | 3 | 1 | 0 | 1626.48 |
| 1101~1200 | 22 | 47 | 18 | 13 | 0 | 0 | 1726.12 |
| 1201~1300 | 18 | 55 | 23 | 4 | 0 | 0 | 1548.48 |
| 1301~1400 | 25 | 51 | 21 | 2 | 1 | 0 | 1539.04 |
| 1401~1500 | 33 | 59 | 7 | 1 | 0 | 0 | 1249.40 |
HM. Et ça. Au fur et à mesure que l'apprentissage progresse, le score moyen augmente progressivement. Même une ligne de 3000 points, qui ne pouvait être atteinte même une fois sur 1000 parties aléatoires, est sortie tellement après un peu d'apprentissage. Pour le moment, on peut dire qu '«il y a des traces d'apprentissage».
De plus, quand je regardais la pièce d'AI-kun après avoir appris, j'ai ressenti une sorte d'intention contrairement à avant (enfin, les humains ont juste trouvé la régularité par eux-mêmes). Il peut être difficile de comprendre si ce n'est que la surface momentanée de la planche, mais je vais la présenter parce que j'ai découpé la scène.
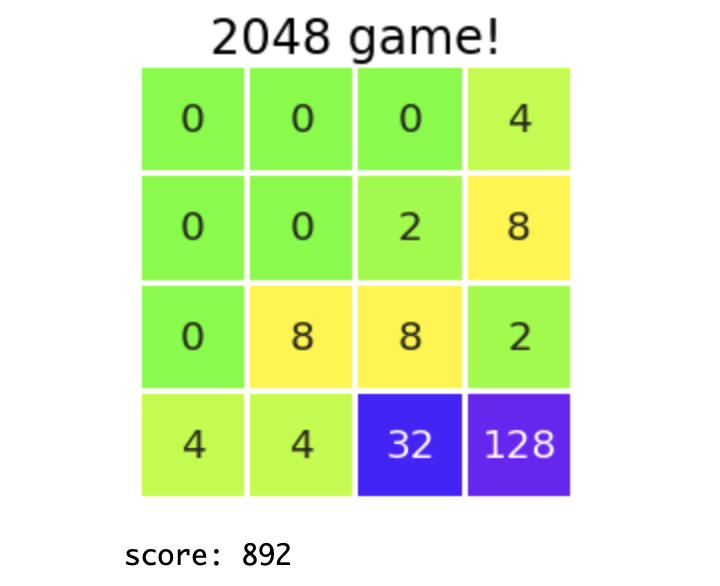
Il y a de nombreuses aspérités, mais la politique était de collecter un grand nombre dans le coin inférieur droit. C'est la même méthode que j'ai introduite dans "1-2. Conseils pour ce jeu". C'est intéressant que j'ai pu apprendre cette astuce même si je ne l'ai pas implémentée comme "apprendre à collecter des nombres énormes dans les coins" à partir d'ici. Personnellement, j'ai été très impressionné.
Cependant, la réalité est qu'il est encore difficile d'obtenir plus de 4000 points. J'ai arrêté d'apprendre 1500 fois simplement parce que ce n'était qu'une question de temps et, comme vous pouvez le voir, le score semblait cesser de croître. En fait, je ne sais pas, mais j'ai senti que même si je continuais à appliquer le même algorithme d'apprentissage, je ne pouvais pas m'attendre à beaucoup d'amélioration des performances.
La raison pour laquelle le score n'a pas augmenté en seconde période, mais plutôt qu'il semblait déprimé, peut être due à la malchance, mais j'ai senti que la performance s'était détériorée normalement. Pour le dire un peu plus correctement, j'imagine que la qualité du contenu des données «expérience» utilisées pour l'apprentissage s'est détériorée (le tableau avancé est tombé dans un cercle vicieux où l'apprentissage n'est pas tellement). Quoi qu'il en soit, je ne pense pas que le modèle après 1500 entraînements soit le plus fort actuellement.
En regardant de près le tableau ci-dessus, j'ai choisi «le modèle à la fin de 1200 apprentissages» comme IA provisoire la plus forte. Eh bien, c'est 50 étapes et 100 étapes. C'était bien de le garder congelé. La raison pour laquelle j'ai choisi le plus fort est que je vais implémenter "un algorithme qui semble choisir un meilleur coup tout en gardant le modèle entraîné tel quel".
C'est pourquoi je vais charger le modèle à ce moment. Laissons cet enfant faire de son mieux.
2048.py
game1200 = Game()
q_value1200 = QValue()
q_value1200.model = load_model('forth_q_value1_1200.h5')
- Puisque je viens de sauvegarder le modèle avec ce nom, il est généralement impossible de coller ce code solidement. À l'avenir, il est actuellement impossible de se reproduire à moins de procéder à l'apprentissage dans votre propre environnement et de créer un modèle. Pardon. C'est compliqué de partager le modèle entraîné quelque part, mais je me demande s'il y a une demande ...
4-4.1 Lire les serviteurs
Il n'y a pas d'apprentissage dans le futur. En conservant le modèle NN tel qu'il est, nous créerons une politique d'action qui nous permettra de mieux jouer au jeu. (Je suis désolé de dire que le code est terminé. Il y en a encore.)
Jusqu'à présent, la politique de comportement consistait à "calculer la valeur de la fonction de valeur d'état d'action pour toutes les actions et sélectionner l'action qui la maximise" pour un état donné. C'est le processus qui a été effectué par la méthode get_action. Nous allons améliorer cela et implémenter un algorithme qui "lit un coup de plus dans l'état suivant et sélectionne le coup qui semble être le meilleur". Tout d'abord, collez le code.
2048.py
def get_action_with_search(game, q_value):
update_q_values = []
for a in range(4):
board_backup = copy.deepcopy(game.board)
score_backup = game.score
state = game.board.tolist()
if(is_invalid_action(state, a)):
update_q_values.append(-10**10)
else:
r = game.move(a)
state_new = game.board.tolist()
_1, q_new, _2 = q_value.get_action(state_new)
update_q_values.append(r+q_new)
game.board = board_backup
game.score = score_backup
optimal_action = np.argmax(update_q_values)
if update_q_values[optimal_action]==-10**10: gameover = True
else: gameover = False
return optimal_action, gameover
C'est une fonction qui remplace la méthode conventionnelle get_action, get_action_with_search. Tournez la boucle for pour 4 actions. À partir de l'état actuel, sélectionnez d'abord l'action une fois pour passer à l'état suivant. Tenez la récompense r à ce moment et considérez le prochain mouvement de l'état suivant. C'est q_value.get_action (state_new). Cette méthode renvoie la valeur de la fonction de valeur d'état d'action pour la meilleure action comme deuxième sortie, elle la prend donc comme q_new. Ici, «r + q_new» est «la somme de la récompense obtenue en sélectionnant l'action a à partir de l'état actuel et l'action à partir de la destination de transition - la valeur maximale de la fonction de valeur d'état». Le mécanisme de cette fonction est de trouver cette valeur pour quatre types d'action a et de sélectionner l'action qui la maximise. (Le jeu sur le jugement est également exécuté en même temps.)
Puisque cette politique lit un mouvement plutôt qu'une métaphore, on peut s'attendre à ce que la précision du choix du meilleur coup soit plus élevée que la sélection d'action conventionnelle. Incluez également get_action_with_search dans d'autres fonctions.
`get_episode2`
2048.py
def get_episode2(game, q_value, epsilon):
episode = []
game.restart()
while(True):
state = game.board.tolist()
if np.random.random() < epsilon:
a = np.random.randint(4)
gameover = False
if(is_invalid_action(state, a)):
continue
else:
# a, _, gameover = q_value.get_action(state)
a, gameover = get_action_with_search(game, q_value)
if gameover:
state_new = None
r = 0
else:
r = game.move(a)
state_new = game.board.tolist()
episode.append((state, a, r, state_new))
if gameover: break
return episode
`show_sample2`
2048.py
def show_sample2(game, q_value):
epi = get_episode2(game, q_value, epsilon=0)
n = len(epi)
game = Game()
game.board = epi[0][0]
# show_board(game)
for i in range(1,n):
game.board = epi[i][0]
game.score += epi[i-1][2]
# time.sleep(0.2)
# clear_output(wait=True)
# show_board(game)
show_board(game)
print("score: {}".format(game.score))
return game.score
Cela dit, c'est exactement la même chose sauf que la fonction de sélection d'action est vraiment remplacée, donc je vais la plier. Veuillez le fermer dès que vous voyez le contenu et que vous l'avez compris.
C'est vraiment la fin du scratch. Enfin, vérifiez les résultats et terminez!
4-5. Résultat final
Je vais vous apporter q_value1200, qui a été certifié comme le plus fort provisoire il y a quelque temps. J'ai demandé à cet enfant de jouer 100 fois de toutes ses forces et je l'ai analysé comme s'il l'avait fait en "4-3. Répéter le train" (je le posterai plus tard).
2048.py
scores1200 = []
for i in range(100):
scores1200.append(show_sample(game1200, q_value1200))
De plus, en utilisant le même modèle, nous leur avons demandé de jouer 100 fois en utilisant l'algorithme d'anticipation à une main.
2048.py
scores1200_2 = []
for i in range(100):
scores1200_2.append(show_sample2(game1200, q_value1200))
Organisez les résultats.
| modèle | 0000~ | 1000~ | 2000~ | 3000~ | 4000~ | 5000~ | 6000~ | average |
|---|---|---|---|---|---|---|---|---|
| Ordinaire | 15 | 63 | 17 | 5 | 0 | 0 | 0 | 1620.24 |
| 1 Regard vers l'avenir | 5 | 41 | 32 | 11 | 6 | 2 | 3 | 2388.40 |
Oui. L'algorithme conventionnel a les mêmes performances que les modèles que nous avons vus auparavant, mais celui qui a introduit 1 look-ahead a clairement amélioré les performances. heureux. Surtout, il est bon qu'il y ait un potentiel pour viser un score élevé si le flux est bon, avec 3 fois plus de 6000 points. Le score le plus élevé sur 100 était de ** 6744 points **. La dernière planche à ce moment est placée.
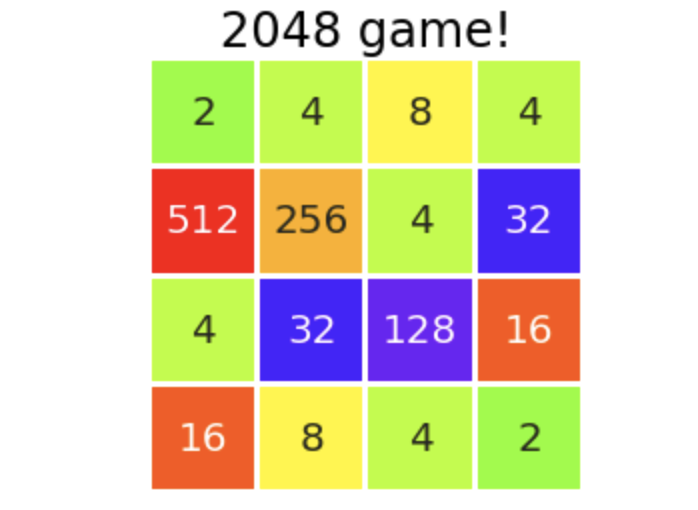
C'est le dernier, donc c'est dérangé, mais il semble que nous pouvons jouer à ce niveau, même si nous les humains le faisons, nous perdrons le chien. Je n'ai pas atteint l'objectif "d'obtenir un score plus élevé que moi" que je me suis fixé il y a longtemps, mais je vais arrêter de l'améliorer pour le moment. Les vacances d'été sont terminées. (Non, mon score élevé de 69544 n'est pas trop fort ...?)
5. Conclusion
Je vous remercie pour votre travail acharné! (Si vous souhaitez lire jusqu'ici, merci beaucoup. Je suis désolé d'avoir écrit une longue ligne de mon côté.
Avec le recul, je voulais vraiment améliorer un peu plus les performances. Ce n'est pas mal pour un score élevé, mais en moyenne, c'est aussi intelligent qu'un jeu humain pour la première fois ...
En fait, je pensais envisager un peu plus le plan d'amélioration d'ici, mais il semble que ce sera trop long et que le cours commencera soudainement à partir de demain (actuellement 3h00 du matin), il s'agit donc d'écrire des notes. Je vais me le transmettre à l'avenir.
- Répétez simplement un peu plus l'apprentissage. (Je pense que c'est un peu difficile, mais ...)
- Essayez de changer la valeur de ʻepsilon
. (Je ne sais pas si elle doit être augmentée ou abaissée. Cependant, il peut être utile d'essayer de réduire ε au fur et à mesure que l'apprentissage progresse.) --Augmenter la longueur de ʻexperienceet ʻexample`? Je vais essayer. (À mesure que l'apprentissage progresse, un épisode s'allonge. La situation actuelle peut ne pas être très appropriée.) - Essayez de diviser l'entrée du tableau de CNN en tuiles au lieu de les regrouper. (Je pense que c'est assez prometteur. À l'heure actuelle, NN peut ne pas être en mesure de faire la distinction entre les tuiles "2" et "4". Préoccupations. Probablement la quantité de calcul augmentera, mais chaque tuile a une signification claire. Parce qu'ils sont différents, je pense qu'ils devraient être saisis séparément.)
--Faible
batch_sizeetepochs. (C'est un manque de compréhension, mais cela affecte la précision de l'apprentissage ... Je n'ai pas l'impression de pouvoir trouver une valeur appropriée.) - Voyons comment vous (l'auteur) jouez. (Cela semble assez ennuyeux en termes de temps, mais cela semble produire des résultats. J'entends dire que Shogi apprend les échecs professionnels. Je me demande si cela peut être bien implémenté ...) ――Lisez et jouez plus loin. (Eh bien, mais je ne sais pas ... le sentiment est mauvais)
Est-ce à peu près comme ça? Au mieux, c'est un plan auquel je peux penser en raison du manque d'auto-apprentissage et d'étude, donc je serais très heureux si vous pouviez me dire que je devrais essayer cela davantage. (Au contraire, veuillez essayer ces plans d'amélioration en mon nom.)
Quand j'ai rassemblé tout cela sérieusement jusqu'à présent, je suis très heureux que les erreurs et les nouvelles découvertes de Hoi Hoi soient issues de la théorie que j'avais l'intention de comprendre une fois. De plus, si vous effectuez un jour des recherches gratuites avec des puces, vous pouvez écrire un article comme celui-ci, alors attendez le nouveau travail. Nous pouvons poursuivre un peu plus l'IA du jeu 2048.
C'est vraiment ça. Si vous trouvez cela intéressant, allez plus loin dans le monde de l'apprentissage amélioré!
La fin
J'ai raté la fin des vacances d'été pour une seule journée. Pardonne-moi.
Recommended Posts