[PYTHON] estimation personnelle en temps réel (apprentissage en utilisant le GPU localement)
en premier
La dernière fois, j'ai écrit un article avec le titre de faire un nouveau modèle et je l'ai vérifié, mais il s'est avéré être un résultat désastreux que j'ai confondu Matsun de Nogizaka pour Yoda-chan. Je savais donc que le modèle ne fonctionnait pas, mais je ne peux pas abandonner ici, je suis déterminé à recréer le modèle et je vais écrire cet article. Il était difficile de préparer un environnement d'apprentissage à l'aide de GPU.
À propos de l'environnement
OS:windows10 GPU:GTX960 Yolov5
À propos de la construction de l'environnement
J'ai commencé par recréer l'environnement pour exécuter Yolo tout en exécutant le GPU. (1) Introduction de cuda Il est nécessaire d'installer cuda avant d'installer PyTorch décrit dans (2). À propos de l'introduction de cuda Il existe différents sites, mais je pense que cela peut être fait car ce n'est pas si difficile. J'ai probablement introduit cuda 10.1. L'URL est affichée ci-dessous. https://developer.nvidia.com/cuda-10.1-download-archive-base?target_os=Windows&target_arch=x86_64&target_version=10&target_type=exelocal (2) Introduction de PyTorch Présentez PyTorch pour cuda 10.1.
pip install torch==1.6.0+cu101 torchvision==0.7.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
(3) Introduction de Yolov5
Veuillez vérifier cela comme il est écrit ci-dessus.
https://qiita.com/asmg07/items/e3be94a3e0f0195c383b
(4) Test d'apprentissage
Je tourne les époques 50 fois en écrivant cet article, mais comme il n'utilise pas le processeur, l'article est très agréable.
Cette partie montre uniquement les commandes utilisées pour le moment et vérifie après apprentissage. </ S>
python train.py --img 640 --epochs 50 --data data.yaml --cfg ./models/yolov5m.yaml --batch-size 2
J'ai fini d'apprendre en écrivant l'article.
(5) Vérification
 Voici l'image résultante. Eh bien, je ne suis toujours pas sûr.
Cela s'est terminé tôt de manière inattendue, alors j'aimerais essayer les époques 100 fois.
Résultats de 100 fois
Voici l'image résultante. Eh bien, je ne suis toujours pas sûr.
Cela s'est terminé tôt de manière inattendue, alors j'aimerais essayer les époques 100 fois.
Résultats de 100 fois
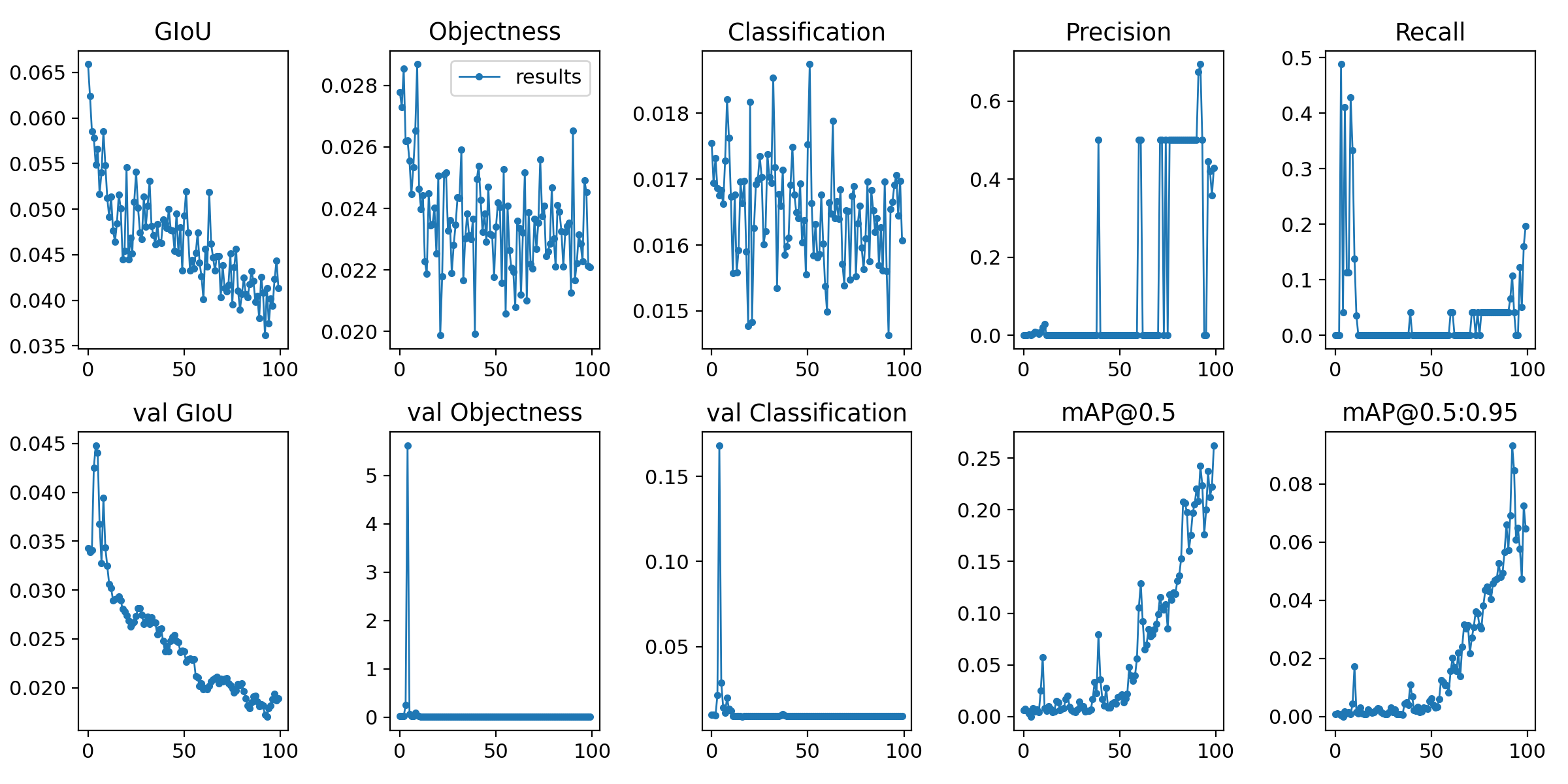
(6) Explication des commandes d'apprentissage
Je ne sais pas encore, mais je vais vous expliquer.
--épochs 50 ➡ fois
--batch-size 2
C'est important --- pourquoi la taille de lot 2 fait cela
J'utilise GTX960 et j'ai 2 Go de mémoire.
Si vous utilisez un nombre plus grand que cela, la mémoire sera plus grande que cela et vous obtiendrez une erreur.
Donc je le fais avec ça, je me demande s'il y a de la mémoire dédiée et de la mémoire partagée dans la mémoire et que seule la mémoire dédiée peut être utilisée.
Veuillez me faire savoir s'il existe également un moyen d'utiliser la mémoire partagée.
finalement
J'ai changé d'environnement pour le moment, donc j'ai à nouveau écrit un nouvel article.
S'il y a un développement, je l'écrirai à nouveau.
PS.
Je veux un commentaire.
・ Mémoire partagée et mémoire dédiée.
・ Comment éviter de déduire dans 2 catégories lorsque vous frappez une troisième image qui n'a pas du tout été formée en le faisant dans 2 catégories.
Je me demande s'il est difficile d'avoir un visage individuel avec une image qui n'a pas été formée
Quand j'ai fait quelque chose de similaire dans le passé, j'ai mis dans une troisième variété de données de visage qui n'avaient rien à voir avec cela et je les ai entraînées dans 3 catégories, mais je ne veux pas faire cela.
Je serais heureux si vous pouviez me parler de ce domaine.
Postscript
⓵ Il semble que la mémoire partagée ne puisse pas être utilisée. ⓶ Je me suis entraîné avec les époques 1000.
python train.py --epochs 1000 --data data.yaml --cfg ./models/yolov5s.yaml --batch-size 1
Environ 80 données d'image dans 2 catégories
Données de sortie après l'entraînement
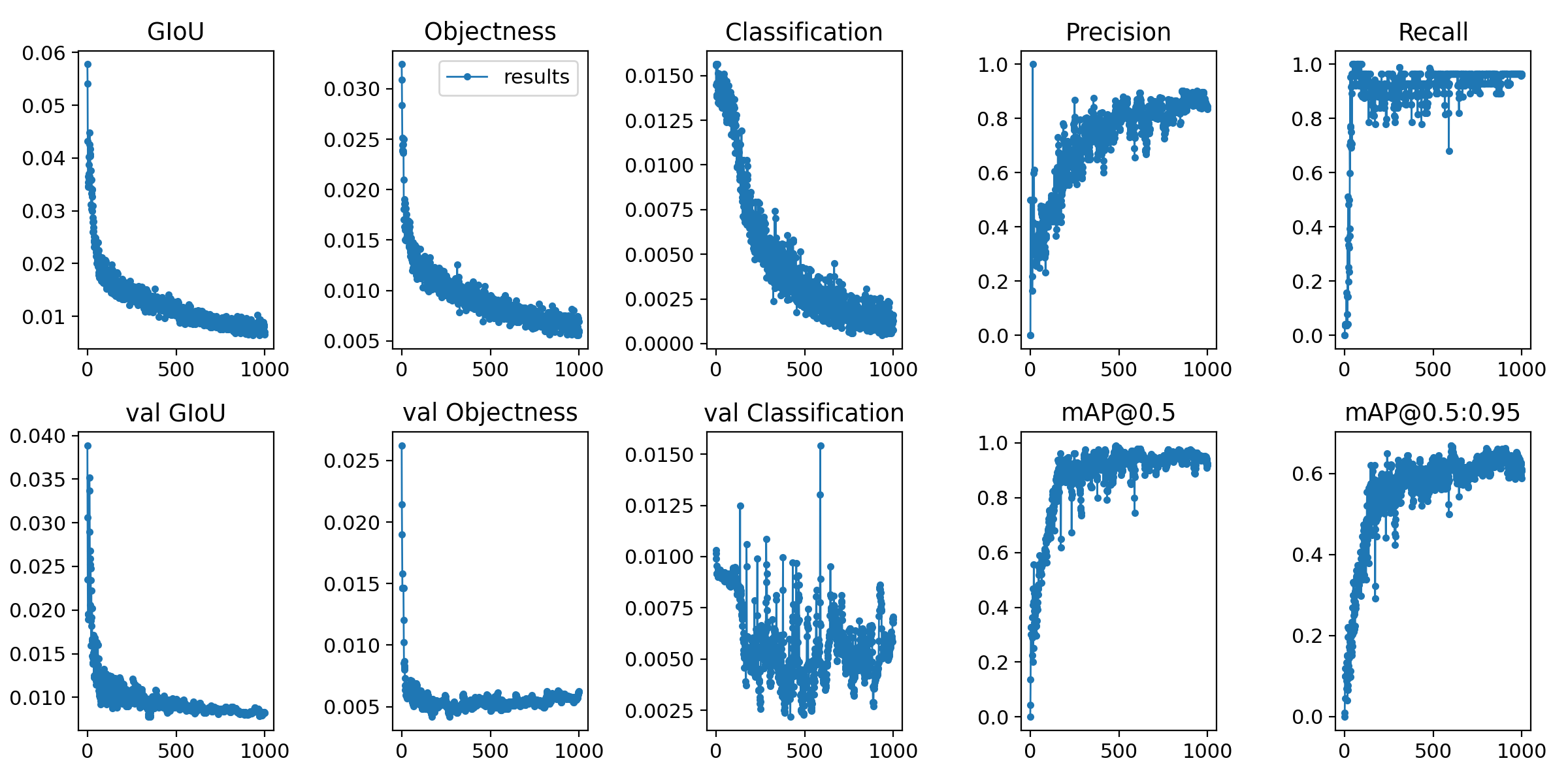 Je me suis demandé si c'était une assez bonne sensation.
・ Résultats des tests réels avec environ 100 feuilles de données
Hors catégorie (non inclus dans la catégorie)
Je me suis demandé si c'était une assez bonne sensation.
・ Résultats des tests réels avec environ 100 feuilles de données
Hors catégorie (non inclus dans la catégorie)


 Dans la catégorie
Dans la catégorie

 L'estimation de Nogisaka-chan inclus dans la catégorie fonctionne bien, mais Nogisaka-chan en dehors de la catégorie (non inclus dans la catégorie)
L'estimation ne fonctionne pas.
problème
-Que faire face au problème de reconnaissance des images en dehors de la catégorie (non incluses dans la catégorie).
En premier lieu, c'est une théorie, mais après tout, c'est peut-être l'un des problèmes qu'il y a trop peu de données d'entraînement.
L'estimation de Nogisaka-chan inclus dans la catégorie fonctionne bien, mais Nogisaka-chan en dehors de la catégorie (non inclus dans la catégorie)
L'estimation ne fonctionne pas.
problème
-Que faire face au problème de reconnaissance des images en dehors de la catégorie (non incluses dans la catégorie).
En premier lieu, c'est une théorie, mais après tout, c'est peut-être l'un des problèmes qu'il y a trop peu de données d'entraînement.
- S'il vous plaît laissez-moi savoir s'il existe une solution.
Problèmes survenus lors de la préparation de l'environnement (question sur github)
https://github.com/ultralytics/yolov5/issues/1094 https://github.com/ultralytics/yolov5/issues/1093
Recommended Posts