[PYTHON] Essais et erreurs pour accélérer la génération de cartes thermiques
Je faisais un programme pour calculer la carte thermique (RVB) à partir d'une valeur allant de 0 à 255. La source que j'ai écrite au début (GPU + Cupy) était trop lente, je vais donc laisser le résultat d'essais et d'erreurs.
** * cv2.applyColorMap (grayscale_image, cv2.COLORMAP_JET) a tout résolu, mais je l'ai fait moi-même (dommage). ** **
Voici le traitement de la taille d'image 320x180.
Le code n'est que la partie principale.
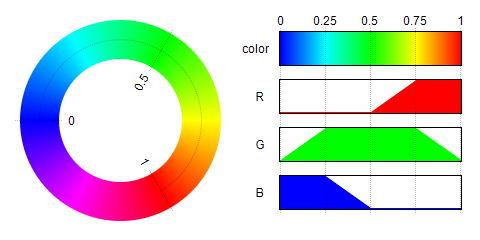
De plus, la carte thermique est une version simplifiée (fonction triangulaire non utilisée) pour trouver des valeurs approximatives.
(Diagramme linéaire de Convertir la grandeur de la valeur en couleur de type thermographie).
GPU+Cupy(for) C'est le code que j'ai écrit à l'origine. C'est un code de groupe perdant qui est traité en le tournant pour honnêtement.
def conv_v_to_heat(v):
image = cuda.cupy.zeros((v.shape[0], array.v[1], 4))
for i, w in enumerate(image):
for j, h in enumerate(w):
image[i,j,0] = get_heat_r(array[i][j])
image[i,j,1] = get_heat_g(array[i][j])
image[i,j,2] = get_heat_b(array[i][j])
image[i,j,3] = array[i][j] #Alpha convient
def get_heat_r(v):
if v <= 127:
return 0
elif v <= 190:
return (v-127)*4
else:
return 255
sec: 20.43495798110962
CPU+Numpy(for) N'est-il pas préférable d'arrêter d'utiliser le GPU plutôt que de l'utiliser pour? Je l'ai changé en CPU (source omise).
sec: 0.6369609832763672
Le processeur était beaucoup plus rapide.
CPU+Numba+Numpy(for) J'ai mis Numba.
@jit
def conv_v_to_heat(v):
@jit
def get_heat_r(v):
sec: 0.20061397552490234
C'est encore plus rapide.
CPU+Numba+Numpy(filter) En premier lieu, c'est un perdant lors de l'utilisation de pour pour Numpy, donc J'ai essayé de le gérer en filtrant.
def conv_v_to_heat(v):
image = np.zeros((v.shape[0], v.shape[1], 4))
image[:, :, 0] = get_r(array)
image[:, :, 1] = get_g(array)
image[:, :, 2] = get_b(array)
image[:, :, 3] = v
def get_heat_r(v):
out = np.zeros((v.shape))
out[...] = 255
out[(v<=190)] = (v[(v<=190)]-127)*4
out[(v<=127)] = 0
return out
sec: 0.0013210773468017578
C'est extrêmement plus rapide.
CPU+Numpy(filter) En guise de test, je supprimerai Numba.
sec: 0.001230478286743164
C'est plus rapide. C'est plutôt un niveau d'erreur.
GPU+Cupy(filter) Alors qu'en est-il du GPU?
sec: 0.008527278900146484
Je suis en retard.
Résumé
| la mise en oeuvre | time(sec) |
|---|---|
| GPU+Cupy(for) | 20.43495798110962 |
| CPU+Numpy(for) | 0.63696098327637 |
| CPU+Numba+Numpy(for) | 0.20061397552490 |
| CPU+Numba+Numpy(filter) | 0.00132107734680 |
| CPU+Numpy(filter) | 0.00123047828674 |
| GPU+Cupy(filter) | 0.00852727890015 |
CPU + Numpy (filtre) était le meilleur. Je pense qu'il y a une mise en œuvre plus rapide, mais personnellement, c'est une vitesse satisfaisante. Après tout, si vous utilisez pour, vous perdrez.
Recommended Posts