[PYTHON] Identifier les caractères importants-itemgetter et TfidfVectorizer-
Déclencheur
Avec l'élément Getter apparu dans Code de la 1ère place au concours Mercari Je n'ai pas vraiment compris TfidfVectorizer.
Résumé
itemgetter → Tout élément peut être extrait des itérables (objets qui peuvent être écrits dans des instructions telles que des listes et des chaînes de caractères).
TfidfVectorizer → Utilisé lors du calcul des caractères importants dans une phrase. Plus le score est élevé, plus la fréquence d'apparition dans le document est élevée, ce qui indique que les caractères sont moins susceptibles d'apparaître dans d'autres documents.
itemgetter
L'objet appelable qui obtient l'élément name est renvoyé dans la première ligne. Seul l'élément de nom est extrait dans la deuxième ligne.
qiita.rb
from operator import itemgetter
item=itemgetter("name")
item({'name':['taro','yamada'], 'age':[5,6]})

TfidfVectorizer
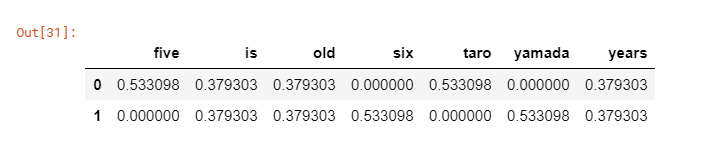
Il est utilisé lors du calcul de TF-IDF. TF-IDF est utilisé pour identifier les chaînes importantes dans un document. Lors du concours, il est utilisé pour quantifier les noms de marque des produits exposés. Dans l'exemple ci-dessous, cinq, six, taro et yamada apparaissent fréquemment et n'apparaissent pas dans d'autres documents, le score est donc élevé.
qiita.rb
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer as Tfidf
sample_string= np.array(['taro is five years old','yamada is six years old'])
tfidf=Tfidf(max_features=100000, token_pattern='\w+')
x=tfidf.fit_transform(sample_string)
pd.DataFrame(y.toarray(), columns=tfidf.get_feature_names())

Utilisation combinée de itemgetter, TfidfVectorizer, Pipeline
Il pipelines une instance de itemgetter ("nom") et une instance de Tfidf. Une fois que l'élément de nom est extrait par .transform, l'importance de l'élément de nom est calculée. Cliquez ici pour le pipeline
qiita.rb
from sklearn.pipeline import make_pipeline, make_union, Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer as Tfidf
from operator import itemgetter
from sklearn.preprocessing import FunctionTransformer
import pandas as pd
def on_field(f: str, *vec) -> Pipeline:
return make_pipeline(FunctionTransformer(itemgetter(f), validate=False), *vec)
df=pd.DataFrame({'string':['taro is five years old','yamada is six years old'], 'age':[5,6]})
Pipeline=on_field('string', Tfidf(max_features=100000, token_pattern='\w+'))
Pipeline.fit(df)
data=Pipeline.transform(df)
pd.DataFrame(data.toarray(),columns=tfidf.get_feature_names())
Recommended Posts