[PYTHON] [Français] Tutoriel officiel NumPy "NumPy: les bases absolues pour les débutants"
Présenté par le traducteur
Cet article est une traduction de "NumPy: les bases absolues pour les débutants" dans la documentation officielle de NumPy v.1.19. Ce document a été publié après le passage de la version de développement à cette version.
Python est resté très populaire ces dernières années. L'une des raisons est le boom de l'IA et l'enrichissement de la bibliothèque d'apprentissage automatique de Python. Il semble que les abondantes bibliothèques de Python dans le domaine du calcul scientifique et technologique tel que l'apprentissage automatique entraînent une nouvelle expansion de la bibliothèque et un support non limité aux débutants.
NumPy est le système sous-jacent de ces bibliothèques de calculs scientifiques et technologiques. La raison pour laquelle NumPy est adopté est le problème de vitesse de Python. En raison de la nature du langage, Python est connu pour être très lent pour certaines opérations. Par conséquent, de nombreuses bibliothèques utilisent NumPy implémenté en langage C pour éviter que la vitesse de Python ne devienne un goulot d'étranglement du traitement, et réaliser la vitesse qui peut supporter une grande quantité de traitement de données. est.
NumPy a l'avantage d'être très pratique et rapide, mais il peut être un peu moins collant que Python lui-même. Dans cet article, j'explique clairement les bases de NumPy avec des images. La portée de l'explication couvre plus de la moitié du "Tutoriel de démarrage rapide", alors lisez ce tutoriel sec. Vous devriez au moins pouvoir faire certaines choses.
Vous pouvez également trouver utile de lire [Pour les débutants] Illustrated NumPy et représentation des données. L'auteur est le créateur des images de cet article. Nous vous serions très reconnaissants si vous pouviez signaler toute erreur de traduction.
** Traduit ci-dessous **
Bienvenue dans le guide des débutants complets NumPy! Si vous avez des commentaires ou des suggestions, n'hésitez pas à nous contacter!
Welcome to NumPy!
NumPy (Numerical Python) est une bibliothèque Python open source utilisée dans presque tous les domaines de la science et de l'ingénierie. Numpy est la norme mondiale pour travailler avec des données numériques et est le noyau de Scientific Python et de la famille Pydata [Écosystèmes Pydata: la gamme de produits du développeur Numpy Pydata]. Les utilisateurs de NUmpy vont des nouveaux programmeurs aux chercheurs chevronnés engagés dans la recherche et le développement scientifiques et techniques de pointe. L'API Numpy est largement utilisée dans Pandas, SciPy, Matplotlib, scikit-learn, scikit-image et la plupart des autres packages de science des données et de Python scientifique. La bibliothèque Numpy a des structures de données multidimensionnelles de tableau et de matrice (plus d'informations à ce sujet dans une section ultérieure). Numpy fournit ndarray, un objet tableau à n dimensions du même type [même type de données], ainsi que des méthodes pour traiter efficacement les tableaux. Numpy peut être utilisé pour effectuer diverses opérations mathématiques sur des tableaux. Numpy ajoute de puissantes structures de données à Python qui garantissent un calcul efficace des tableaux et des matrices, et fournit une énorme bibliothèque avec des capacités mathématiques avancées qui fonctionnent avec ces tableaux et matrices. Learn more about NumPy here!
Installez NumPy
Nous vous recommandons vivement d'utiliser une distribution scientifique Python pour installer NumPy. si Si vous avez besoin d'un guide complet pour installer NumPy sur votre système d'exploitation, vous trouverez ici tous les détails (https://www.scipy.org/install.html).
Si vous utilisez déjà Python, vous pouvez installer NumPy avec le code suivant.
conda install numpy
Ou
pip install numpy
Si vous n'avez pas encore Python, vous devriez envisager d'utiliser Anaconda. Anaconda est le moyen le plus simple de démarrer avec Python. L'avantage d'utiliser cette distribution est que vous n'avez pas à vous soucier trop de l'installation de NumPy, les principaux packages utilisés pour l'analyse des données, les pandas, Scikit-Learn, etc. individuellement.
You can find all of the installation details in the InstallationsectionatSciPy.
Comment importer NumPy
Chaque fois que vous souhaitez utiliser un package ou une bibliothèque, vous devez rendre le premier accessible. Pour démarrer avec NumPy et toutes ses fonctionnalités, vous devez importer NumPy. Cela peut être facilement fait avec l'instruction d'importation suivante [instruction].
import numpy as np
(Nous abrégons NumPy par np, pour gagner du temps et normaliser le code afin que quiconque travaille avec lui puisse facilement le comprendre et l'exécuter. .)
Comment lire l'exemple de code
Si votre code n'est pas habitué à lire de nombreux didacticiels, vous ne savez peut-être pas comment comprendre un bloc de code comme celui-ci:
>>> a = np.arange(6)
>>> a2 = a[np.newaxis, :]
>>> a2.shape
(1, 6)
Même si vous n'êtes pas familier avec cette méthode, cette notation est très facile à comprendre. S'il y a >>>, il pointe vers ** input **, c'est-à-dire le code que vous entrerez. Tout ce qui ne contient pas >>> devant le code est ** sortie **, le résultat de l'exécution du code. C'est le style lors de l'exécution de Python sur la ligne de commande, mais lorsque vous utilisez IPython, vous pouvez voir différents styles.
Quelle est la différence entre la liste Python et le tableau NumPy?
NumPy dispose de nombreux moyens rapides et efficaces pour créer des tableaux et manipuler des données numériques. Les listes Pyhon peuvent avoir différents types de données dans une seule liste, mais dans un tableau NumPy, tous les éléments du tableau doivent être du même type. Si le tableau est mélangé avec d'autres types de données, les opérations mathématiques qui devraient fonctionner sur le tableau seront gravement inefficaces.
Pourquoi NumPy est-il utilisé?
Les tableaux NumPy sont plus rapides et plus concis que les listes Python. Le tableau [Python] utilise moins de mémoire et est pratique à utiliser. En comparaison, NumPy utilise beaucoup moins de mémoire pour stocker les données et dispose d'un mécanisme pour identifier les types de données. Cela permet une optimisation supplémentaire du code.
Qu'est-ce qu'un tableau?
Un tableau est l'une des principales structures de données de la bibliothèque NumPy. Un tableau est une grille de valeurs, qui contient des informations sur les données brutes, des informations sur la manière d'organiser les éléments et des informations sur la manière d'interpréter les éléments. La grille constituée de divers éléments de NumPy peut être indexée par diverses méthodes. Je vais. Les éléments sont tous homogènes et sont représentés par «dtype» dans le tableau.
Un tableau peut être indexé par un tuple d'entiers positifs, de booléens, d'un autre tableau ou d'un entier. Le «rang» du tableau est le nombre de dimensions. La «forme» d'un tableau est un tuple entier qui représente la taille du tableau le long de chaque dimension. Une façon d'initialiser un tableau NumPy est de l'initialiser à partir d'une liste Python. Utilisez une liste imbriquée pour les données comportant plus de deux dimensions.
Exemple:
>>> a = np.array([1, 2, 3, 4, 5, 6])
Ou
>>> a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
Utilisez des crochets clés pour accéder aux éléments du tableau. N'oubliez pas que l'index NumPy commence à 0 lors de l'accès aux éléments du tableau. Cela signifie que si vous souhaitez accéder au premier élément du tableau, vous accéderez au tableau "0".
>>> print(a[0])
[1 2 3 4]
En savoir plus sur les tableaux
- Cette section traite de
1D array,2D array,ndarray,vector,matrix*
Vous avez peut-être parfois vu un tableau intitulé "ndarray". C'est une abréviation pour "tableau à N dimensions". Un tableau à N dimensions est simplement un tableau avec un nombre quelconque de dimensions. Vous avez peut-être aussi vu "** 1-D " ou des tableaux à une dimension, " 2-D **" ou des tableaux à deux dimensions, etc ... La classe ndarray de NumPy est utilisée pour représenter à la fois des matrices et des vecteurs. ** Vector ** est un tableau à une dimension (il n'y a pas de différence entre les vecteurs de ligne et de colonne), et ** matrice ** fait référence à un tableau à deux dimensions. Pour les tableaux de ** 3D ** et supérieurs, le terme ** tenseur ** est également couramment utilisé.
** Que sont les attributs de tableau? ** **
Un tableau est généralement un conteneur de taille fixe d'éléments du même type et de la même taille. Le nombre de dimensions et d'éléments d'un tableau est défini par la forme du tableau. La forme du tableau est un taple de nombres naturels qui définit la taille de chaque dimension. Dans NumPy, les dimensions sont appelées ** axes **. Autrement dit, si vous avez la séquence suivante
[[0., 0., 0.],
[1., 1., 1.]]
Ce tableau a deux axes. La longueur du premier axe est de 2 et la longueur du second est de 3. Comme avec n'importe quel conteneur Python, vous pouvez accéder et modifier le contenu du tableau par indexation et découpage. Mais contrairement aux objets conteneurs classiques, les mêmes données peuvent être partagées dans différents tableaux, de sorte que les modifications apportées à un tableau peuvent apparaître dans un autre.
Les ** attributs ** d'un tableau reflètent des informations spécifiques au tableau. Si vous devez obtenir ou définir les propriétés d'un tableau sans en créer un nouveau, vous accédez souvent au tableau via les attributs du tableau.
Read more about array attributes hereandlearnaboutarrayobjectshere.
Comment créer un tableau simple
_ Dans cette section np.array (), np.zeros (), np.ones (), np.empty (), np.arange (), np.linspace () , dtype est géré_
Pour créer un tableau NumPy, utilisez la fonction np.array ().
Tout ce que vous avez à faire pour créer un tableau simple est de passer une liste. Vous pouvez également spécifier le type de données de la liste si vous le souhaitez. Vous pouvez trouver plus d'informations sur les types de données ici.
>>> import numpy as np
>>> a = np.array([1, 2, 3])
Vous pouvez visualiser le tableau comme suit:  Notez que ces visualisations visent à rendre le concept plus facile à comprendre et à donner une compréhension de base du fonctionnement des idées et des mécanismes de NumPy. Les tableaux et les opérations de tableaux sont beaucoup plus complexes que ceux représentés ici.
En plus du tableau créé à partir d'une série d'éléments, vous pouvez facilement créer un tableau rempli de «0».
Notez que ces visualisations visent à rendre le concept plus facile à comprendre et à donner une compréhension de base du fonctionnement des idées et des mécanismes de NumPy. Les tableaux et les opérations de tableaux sont beaucoup plus complexes que ceux représentés ici.
En plus du tableau créé à partir d'une série d'éléments, vous pouvez facilement créer un tableau rempli de «0».
>>> np.zeros(2)
array([0., 0.])
Vous pouvez également créer un tableau rempli de «1».
>>> np.ones(2)
array([1., 1.])
Ou même un tableau vide! La fonction ʻempty` crée un tableau dont le contenu initial est aléatoire et dépend de l'état de la mémoire. La raison d'utiliser la fonction «vide» de préférence à la fonction «zéro» (ou quelque chose de similaire) est la vitesse. N'oubliez pas de remplir tous les éléments plus tard!
>>> # Create an empty array with 2 elements
>>> np.empty(2)
array([ 3.14, 42. ]) # may vary
Vous pouvez créer un tableau d'éléments contigus:
>>> np.arange(4)
array([0, 1, 2, 3])
Vous pouvez également créer un tableau de colonnes régulièrement espacées. Pour ce faire, spécifiez ** premier numéro **, ** dernier numéro ** et le nombre d'étapes.
>>> np.arange(2, 9, 2)
array([2, 4, 6, 8])
Vous pouvez utiliser np.linspace () pour créer un tableau avec des valeurs espacées linéairement à des intervalles spécifiés.
>>> np.linspace(0, 10, num=5)
array([ 0. , 2.5, 5. , 7.5, 10. ])
** Spécifiez le type de données **
Le type de données par défaut est virgule flottante (np.float64), mais vous pouvez spécifier explicitement le type de données que vous souhaitez utiliser avec le mot clé dtype.
>>> x = np.ones(2, dtype=np.int64)
>>> x
array([1, 1])
Learn more about creating arrays here
Ajouter / supprimer / trier des éléments
- Cette section traite de
np.sort (),np.concatenate ()*
Lors du tri des éléments, il est facile d'utiliser np.sort (). Lors de l'appel de cette fonction, vous pouvez spécifier l'axe, le type et l'ordre.
Prenant ce tableau comme exemple
>>> arr = np.array([2, 1, 5, 3, 7, 4, 6, 8])
Cela vous permet de trier rapidement par ordre croissant.
>>> np.sort(arr)
array([1, 2, 3, 4, 5, 6, 7, 8])
sort renvoie une copie triée dans un tableau, mais vous pouvez également utiliser:
· ʻArgsort](https://numpy.org/doc/stable/reference/generated/numpy.argsort.html#numpy.argsort): tri indirect par l'axe spécifié · [Lexsort](https://numpy.org/doc/stable/reference/generated/numpy.lexsort.html#numpy.lexsort): tri stable indirect sur plusieurs clés] · [Searchsorted`: Découvrez des éléments d'un tableau trié
Partition: tri partiel
Prenez ces séquences comme exemple:
>>> a = np.array([1, 2, 3, 4])
>>> b = np.array([5, 6, 7, 8])
Vous pouvez concaténer ces tableaux avec np.concatenate ().
>>> np.concatenate((a, b))
array([1, 2, 3, 4, 5, 6, 7, 8])
Aussi, en prenant ce tableau comme exemple:
>>> x = np.array([[1, 2], [3, 4]])
>>> y = np.array([[5, 6]])
De cette façon, vous pouvez concaténer:
>>> np.concatenate((x, y), axis=0)
array([[1, 2],
[3, 4],
[5, 6]])
Pour supprimer un élément du tableau, il est facile d'utiliser l'index pour sélectionner l'élément que vous souhaitez conserver.
Si vous voulez en savoir plus sur la concaténation, voir à droite: concatenate.
Comment connaître la forme et la taille d'un tableau?
- Cette section traite de
ndarray.ndim,ndarray.size,ndarray.shape*
ndarray.ndim indique le nombre d'axes dans le tableau, c'est-à-dire le nombre de dimensions.
ndarray.size affiche le nombre total d'éléments dans le tableau. C'est le produit de la taille du tableau.
ndarray.shape affiche un tuple entier qui indique le nombre d'éléments stockés dans chaque dimension du tableau. Par exemple, si vous avez un tableau bidimensionnel 2 par 3, la forme du tableau est (2,3).
Par exemple, supposons que vous créez le tableau suivant:
>>> array_example = np.array([[[0, 1, 2, 3],
... [4, 5, 6, 7]],
... [[0, 1, 2, 3],
... [4, 5, 6, 7]],
... [[0 ,1 ,2, 3],
... [4, 5, 6, 7]]])
Pour connaître le nombre de dimensions dans un tableau:
>>> array_example.ndim
3
Pour connaître le nombre total d'éléments dans un tableau:
>>> array_example.size
24
Et pour connaître la forme du tableau, procédez comme suit:
>>> array_example.shape
(3, 2, 4)
Puis-je transformer le tableau?
- Cette section traite de ʻarr.reshape () `*
bien sûr! Vous pouvez utiliser ʻarr.reshape () `pour donner une nouvelle forme à un tableau sans changer les données. Lorsque vous utilisez cette méthode de transformation, gardez à l'esprit que le tableau que vous souhaitez créer doit avoir le même nombre d'éléments que le tableau d'origine. Si vous transformez un tableau de 12 éléments, vous devez vous assurer que le nouveau tableau contient également un total de 12 éléments. Si vous utilisez ce tableau:
>>> a = np.arange(6)
>>> print(a)
[0 1 2 3 4 5]
Vous pouvez utiliser reshape () pour transformer le tableau. Par exemple, vous pouvez transformer ce tableau en un tableau 3 par 2:
>>> b = a.reshape(3, 2)
>>> print(b)
[[0 1]
[2 3]
[4 5]]
Il est possible de spécifier certains paramètres avec np.shape (). ::
>>> numpy.reshape(a, newshape=(1, 6), order='C')]
array([[0, 1, 2, 3, 4, 5]])
ʻAest un tableau qui change de forme. newshape est la forme du nouveau tableau. Vous pouvez spécifier un entier ou un entier taple. Si vous spécifiez un entier, un tableau de cette longueur entière est créé. La forme doit être compatible avec la forme d'origine. ʻOrder: `` C signifie lire et écrire dans un ordre d'index de type C, et F signifie lire et écrire dans un ordre d'index de type Fortran. Un moyen utilise un ordre d'index de type Fortran si l'élément est contigu en mémoire Fortran, sinon utilisez un index de type C (il s'agit d'un paramètre facultatif et doit être spécifié. Pas besoin de).
If you want to learn more about C and Fortran order, you can read more about the internal organization of NumPy arrays here. Essentially, C and Fortran orders have to do with how indices correspond to the order the array is stored in memory. In Fortran, when moving through the elements of a two-dimensional array as it is stored in memory, the first index is the most rapidly varying index. As the first index moves to the next row as it changes, the matrix is stored one column at a time. This is why Fortran is thought of as a Column-major language. In C on the other hand, the last index changes the most rapidly. The matrix is stored by rows, making it a Row-major language. What you do for C or Fortran depends on whether it’s more important to preserve the indexing convention or not reorder the data.
Learn more about shape manipulation here.
Comment convertir un tableau 1D en tableau 2D (comment ajouter un nouvel axe au tableau)
- Cette section traite de
np.newaxis,np.expand_dims*
Vous pouvez utiliser np.newaxis et np.expand_dims pour augmenter les dimensions d'un tableau existant.
L'utilisation de np.newaxis augmentera la dimension du tableau d'une dimension s'il n'est utilisé qu'une seule fois. Autrement dit, un tableau 1D devient un tableau 2D, un tableau 2D devient un tableau 3D, et ainsi de suite.
Par exemple, dans la séquence suivante
>>> a = np.array([1, 2, 3, 4, 5, 6])
>>> a.shape
(6,)
Vous pouvez ajouter un nouvel axe en utilisant np.newaxis. ::
>>> a2 = a[np.newaxis, :]
>>> a2.shape
(1, 6)
Vous pouvez explicitement transformer un tableau 1D à partir d'un vecteur ligne ou d'un vecteur colonne en utilisant np.newaxis. Par exemple, vous pouvez convertir un tableau 1D en vecteur de ligne en insérant un axe sur la première dimension.
>>> row_vector = a[np.newaxis, :]
>>> row_vector.shape
(1, 6)
Vous pouvez également insérer un axe dans la deuxième dimension dans le vecteur de colonne:
>>> col_vector = a[:, np.newaxis]
>>> col_vector.shape
(6, 1)
Vous pouvez également développer le tableau en insérant les axes spécifiés dans np.expand_dims. Par exemple, dans ce tableau:
>>> a = np.array([1, 2, 3, 4, 5, 6])
>>> a.shape
(6,)
Vous pouvez utiliser np.expand_dims pour ajouter un axe à la position d'index 1. ::
>>> b = np.expand_dims(a, axis=1)
>>> b.shape
(6, 1)
Pour ajouter un axe à la position d'index 0: ::
>>> c = np.expand_dims(a, axis=0)
>>> c.shape
(1, 6)
Indexation et découpage
L'accès en indice et le découpage des tableaux Numpy peuvent être effectués de la même manière que le découpage des listes Python.
>>> data = np.array([1, 2, 3])
>>> data[1]
2
>>> data[0:2]
array([1, 2])
>>> data[1:]
array([2, 3])
>>> data[-2:]
array([2, 3])
Cela peut être visualisé comme suit:
Vous devrez peut-être extraire des parties du tableau ou des éléments spécifiques du tableau pour une analyse ou une manipulation plus approfondie. Pour ce faire, vous devrez sous-ensemble, découper et / ou indexer la séquence.
Si vous souhaitez extraire des valeurs d'un tableau qui remplissent certaines conditions, NumPy est facile.
Par exemple, prenez le tableau suivant comme exemple.
>>> a = np.array([[1 , 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
Vous pouvez facilement afficher les nombres inférieurs à 5 dans le tableau.
>>> print(a[a < 5])
[1 2 3 4]
Vous pouvez également, par exemple, sélectionner un nombre de 5 ou plus et utiliser cette condition pour indexer le tableau.
>>> five_up = (a >= 5)
>>> print(a[five_up])
[ 5 6 7 8 9 10 11 12]
Vous pouvez également extraire des éléments divisibles par 2. ::
>>> divisible_by_2 = a[a%2==0]
>>> print(divisible_by_2)
[ 2 4 6 8 10 12]
Vous pouvez également utiliser les opérateurs & et | pour récupérer des éléments qui remplissent deux conditions:
>>> c = a[(a > 2) & (a < 11)]
>>> print(c)
[ 3 4 5 6 7 8 9 10]
Vous pouvez également utiliser les opérateurs logiques ** & ** et ** | ** pour renvoyer une valeur booléenne indiquant si la valeur du tableau répond à certaines conditions. Ceci est utile pour les tableaux avec des noms ou des valeurs dans différentes catégories.
>>> five_up = (a > 5) | (a == 5)
>>> print(five_up)
[[False False False False]
[ True True True True]
[ True True True True]]
Vous pouvez également utiliser np.nonzero () pour sélectionner un élément ou un index dans un tableau.
Commençons par le tableau suivant:
>>> a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
Vous pouvez utiliser np.nonzero () pour afficher l'index d'un élément, inférieur à 5 dans ce cas:
>>> b = np.nonzero(a < 5)
>>> print(b)
(array([0, 0, 0, 0]), array([0, 1, 2, 3]))
Cet exemple renvoie un tapple du tableau. Un seul taple est renvoyé pour chaque dimension. Le premier tableau représente l'index de ligne qui a la valeur qui répond à la condition, et le second tableau montre l'index de colonne qui a la valeur qui répond à la condition.
Si vous souhaitez générer une liste de coordonnées avec un élément, vous pouvez compresser ce tableau et parcourir la liste des coordonnées pour l'afficher. Par exemple:
>>> list_of_coordinates= list(zip(b[0], b[1]))
>>> for coord in list_of_coordinates:
... print(coord)
(0, 0)
(0, 1)
(0, 2)
(0, 3)
Vous pouvez également utiliser np.nonzero () pour afficher moins de 5 éléments dans un tableau:
>>> print(a[b])
[1 2 3 4]
```shell
Si l'élément que vous recherchez n'existe pas dans le tableau, le tableau d'index de retour sera vide. Par exemple:
```shell
>>> not_there = np.nonzero(a == 42)
>>> print(not_there)
(array([], dtype=int64), array([], dtype=int64))
Comment créer un tableau à partir de données existantes
- Cette section traite de
tranchage et indexation,np.vstack (),np.hstack (),np.hsplit (),.view (),copy ()*
Vous pouvez facilement créer un tableau à partir d'une partie d'un tableau existant. Supposons que vous ayez la séquence suivante:
>>> a = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Vous pouvez toujours créer un nouveau tableau à partir de la partie du tableau en spécifiant la partie du tableau que vous souhaitez découper.
>>> arr1 = a[3:8]
>>> arr1
array([4, 5, 6, 7, 8])
Ici, la plage de la position d'index 3 à la position d'index 8 est spécifiée.
Vous pouvez concaténer deux tableaux existants verticalement ou horizontalement. Supposons que vous ayez les deux tableaux suivants, ʻa1, ʻa2.
>>> a1 = np.array([[1, 1],
... [2, 2]])
>>> a2 = np.array([[3, 3],
... [4, 4]])
Vous pouvez les empiler verticalement en utilisant vstack.
>>> np.vstack((a1, a2))
array([[1, 1],
[2, 2],
[3, 3],
[4, 4]])
Et vous pouvez les empiler côte à côte avec hstack.
>>> np.hstack((a1, a2))
array([[1, 1, 3, 3],
[2, 2, 4, 4]])
Vous pouvez diviser le tableau en plusieurs tableaux plus petits avec hsplit. Vous pouvez spécifier le nombre de tableaux isomorphes dans lesquels le tableau doit être divisé et le nombre de colonnes après la division.
Disons que vous avez ce tableau:
>>> x = np.arange(1, 25).reshape(2, 12)
>>> x
array([[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24]])
Si vous souhaitez diviser ce tableau en trois tableaux de même forme, exécutez le code suivant.
>>> np.hsplit(x, 3)
[array([[1, 2, 3, 4],
[13, 14, 15, 16]]), array([[ 5, 6, 7, 8],
[17, 18, 19, 20]]), array([[ 9, 10, 11, 12],
[21, 22, 23, 24]])]
Si vous souhaitez fractionner le tableau après les 3e et 4e colonnes, exécutez le code suivant.
>>> np.hsplit(x, (3, 4))
[array([[1, 2, 3],
[13, 14, 15]]), array([[ 4],
[16]]), array([[ 5, 6, 7, 8, 9, 10, 11, 12],
[17, 18, 19, 20, 21, 22, 23, 24]])]
Learn more about stacking and splitting arrays here.
Vous pouvez utiliser la méthode view pour créer un nouveau tableau qui référence les mêmes données que le tableau d'origine (copie superficielle).
Les vues sont l'un des concepts clés de NumPy. Les fonctions NumPy renvoient des vues dans la mesure du possible, similaires à des opérations telles que l'accès en indice et le découpage. Cela économise de la mémoire et est rapide (pas besoin de faire une copie des données). Mais il y a une chose à garder à l'esprit: changer les données dans la vue modifiera également le tableau d'origine.
Supposons que vous créez un tableau comme celui-ci:
>>> a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
Maintenant coupez ʻa pour faire b1et changez le premier élément deb1`. Cette opération modifie également l'élément correspondant de «a».
>>> b1 = a[0, :]
>>> b1
array([1, 2, 3, 4])
>>> b1[0] = 99
>>> b1
array([99, 2, 3, 4])
>>> a
array([[99, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
Utilisez la méthode copy pour faire une copie complète du tableau et de ses données (copie complète). Pour l'utiliser pour un tableau, exécutez le code suivant.
>>> b2 = a.copy()
Fonctionnement de base d'un tableau
- Cette section traite de l'addition, de la soustraction, de la multiplication, de la division, etc. *
Une fois que vous avez créé un tableau, vous pouvez commencer à l'utiliser. Par exemple, disons que vous avez créé deux tableaux appelés "data" et "ones". 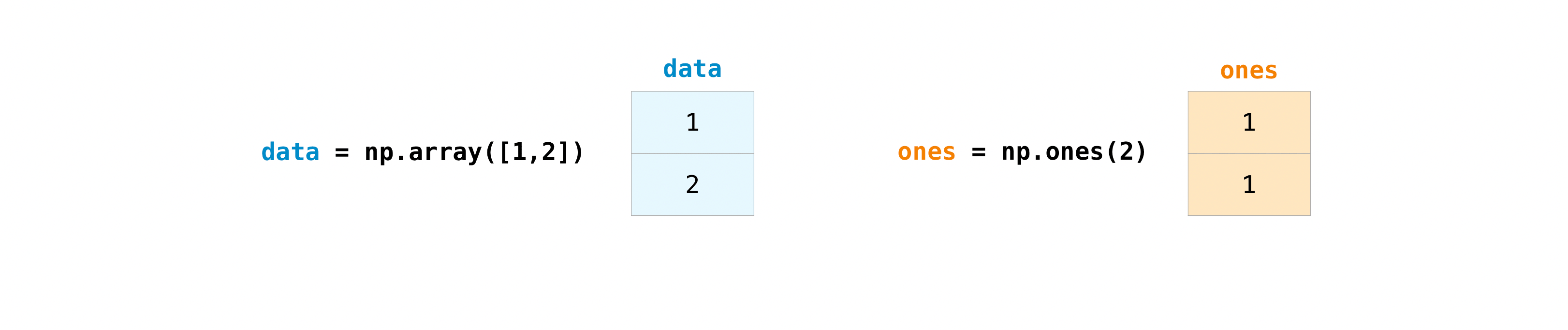
Vous pouvez ajouter des tableaux en utilisant le signe plus.
>>> data = np.array([1, 2])
>>> ones = np.ones(2, dtype=int)
>>> data + ones
array([2, 3])
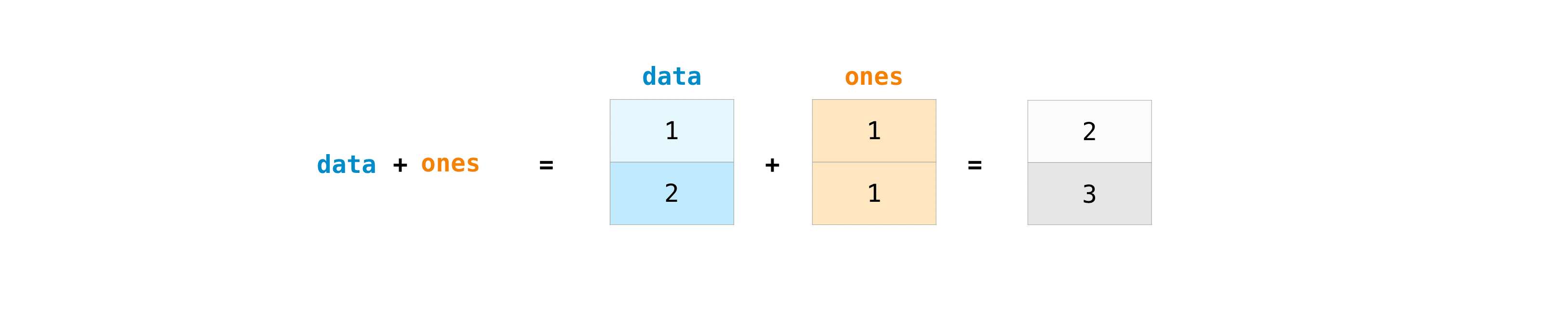
Bien sûr, vous pouvez faire plus que simplement ajouter!
>>> data - ones
array([0, 1])
>>> data * data
array([1, 4])
>>> data / data
array([1., 1.])
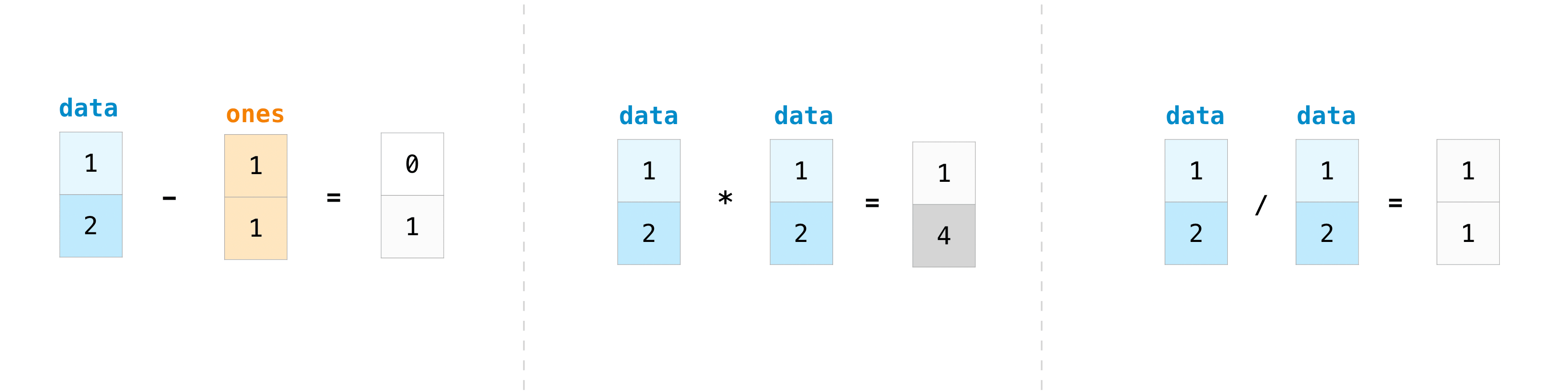
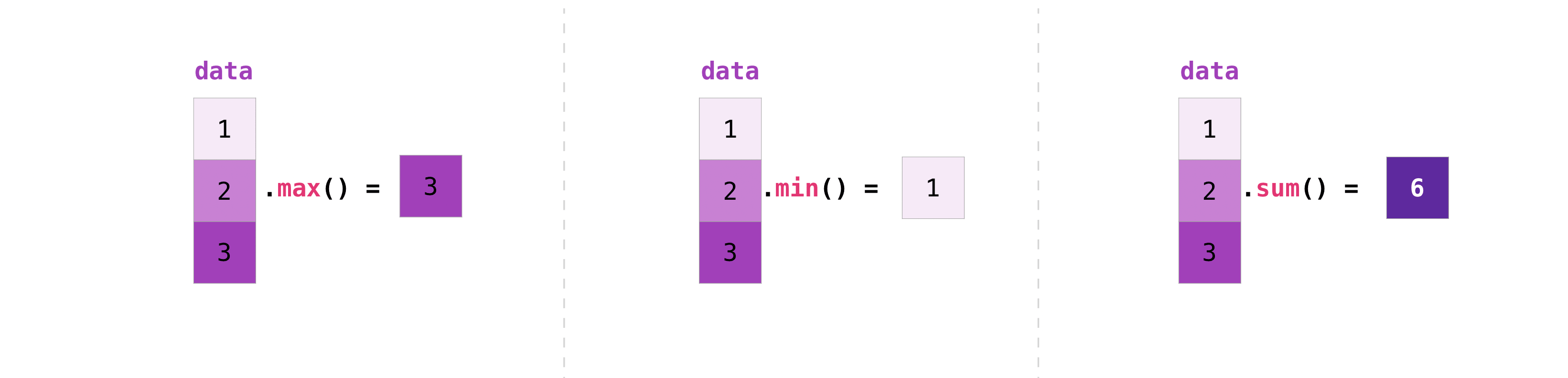
L'opération de base est facile avec NumPy. Si vous voulez connaître la somme des séquences, utilisez sum (). Il fonctionne dans les tableaux 1D, 2D et supérieurs.
>>> a = np.array([1, 2, 3, 4])
>>> a.sum()
10
Si vous souhaitez ajouter des colonnes ou des lignes dans un tableau à deux dimensions (pour ajouter les lignes ou les colonnes dans un tableau 2D), spécifiez les axes. Si vous commencez avec ce tableau:
>>> b = np.array([[1, 1], [2, 2]])
Les lignes peuvent être additionnées comme suit:
>>> b.sum(axis=0)
array([3, 3])
Les colonnes peuvent être additionnées comme suit: ::
>>> b.sum(axis=1)
array([2, 4])
Broadcasting
Il y a des moments où vous souhaitez effectuer une opération entre un tableau et un seul nombre, ou entre des tableaux de tailles différentes (le premier est également appelé opération entre un vecteur et un scalaire). Par exemple, supposons qu'un tableau (appelé «données») contienne des informations sur le nombre de kilomètres et que vous souhaitez les convertir en kilomètres. Vous pouvez le faire comme suit:
>>> data = np.array([1.0, 2.0])
>>> data * 1.6
array([1.6, 3.2])
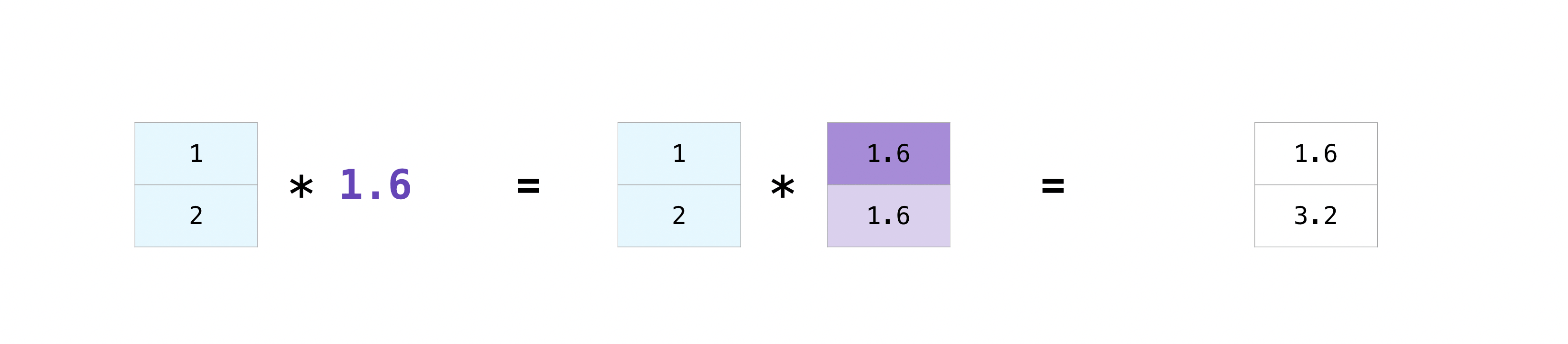
NumPy comprend que la multiplication doit être effectuée dans chaque cellule. Ce concept s'appelle ** Broadcast **. Broadcastet est un mécanisme permettant à NumPy d'effectuer des opérations sur des tableaux de différentes formes. Les dimensions du tableau doivent être compatibles. Par exemple, si les deux tableaux ont la même dimension ou si l'un a une dimension. Sinon, vous obtiendrez une ValueError.
Opérations de baie plus pratiques
This section covers maximum, minimum, sum, mean, product, standard deviation, and more
NumPy exécute également des fonctions d'agrégation. En plus de «min», «max», «sum», «mean» pour obtenir la moyenne, «prod» pour obtenir le résultat de la multiplication des éléments, «std» pour obtenir l'écart type, etc. sont faciles. Peut être exécuté.
>>> data.max()
2.0
>>> data.min()
1.0
>>> data.sum()
3.0
Commençons par ce tableau, "a"
>>> a = np.array([[0.45053314, 0.17296777, 0.34376245, 0.5510652],
... [0.54627315, 0.05093587, 0.40067661, 0.55645993],
... [0.12697628, 0.82485143, 0.26590556, 0.56917101]])
Il est très courant de vouloir agréger le long de lignes et de colonnes. Par défaut, toutes les fonctions d'agrégation NumPy renvoient la somme du tableau entier. Si vous souhaitez connaître la somme ou la valeur minimale des éléments d'un tableau, utilisez le code suivant.
>>> a.sum()
4.8595784
Ou:
>>> a.min()
0.05093587
Vous pouvez spécifier sur quel axe vous souhaitez que la fonction d'agrégation fonctionne. Par exemple, vous pouvez trouver la valeur minimale dans chaque colonne en définissant axis = 0.
>>> a.min(axis=0)
array([0.12697628, 0.05093587, 0.26590556, 0.5510652 ])
Les quatre nombres ci-dessus correspondent aux nombres dans les lignes du tableau d'origine. Avec un tableau à quatre lignes, vous pouvez obtenir quatre valeurs en conséquence.
Faire une file d'attente
Vous pouvez transmettre une liste Python et utiliser NumPy pour créer un tableau 2D (ou «matrice») qui représente ce tableau.
>>> data = np.array([[1, 2], [3, 4]])
>>> data
array([[1, 2],
[3, 4]])

Les opérations d'accès en indice et de découpage sont utiles lorsque vous travaillez avec des matrices.
>>> data[0, 1]
2
>>> data[1:3]
array([[3, 4]])
>>> data[0:2, 0]
array([1, 3])

Vous pouvez manipuler la matrice de la même manière que vous manipulez le vecteur.
>>> data.max()
4
>>> data.min()
1
>>> data.sum()
10
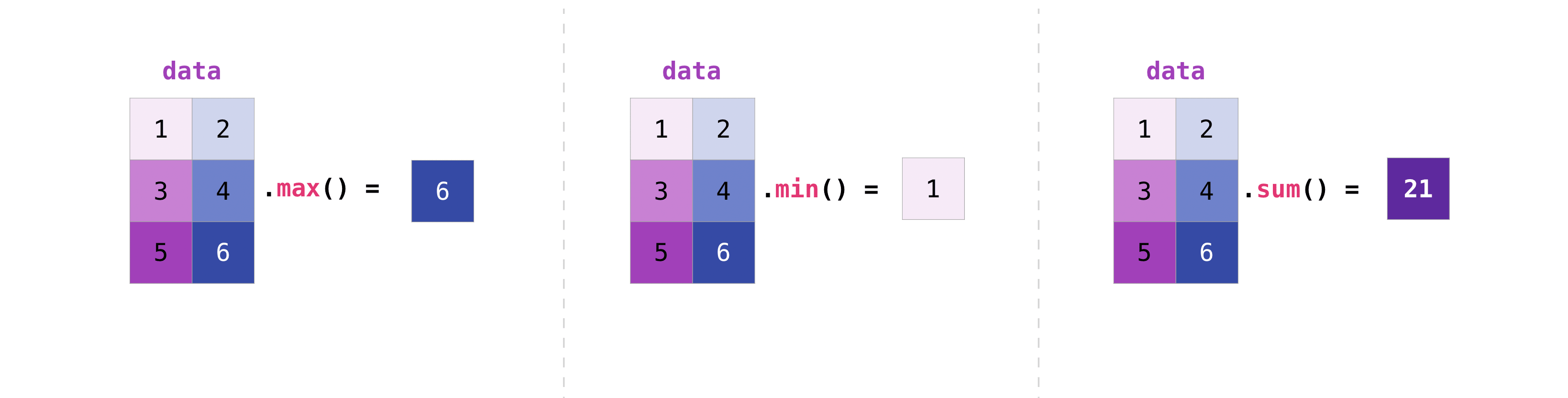
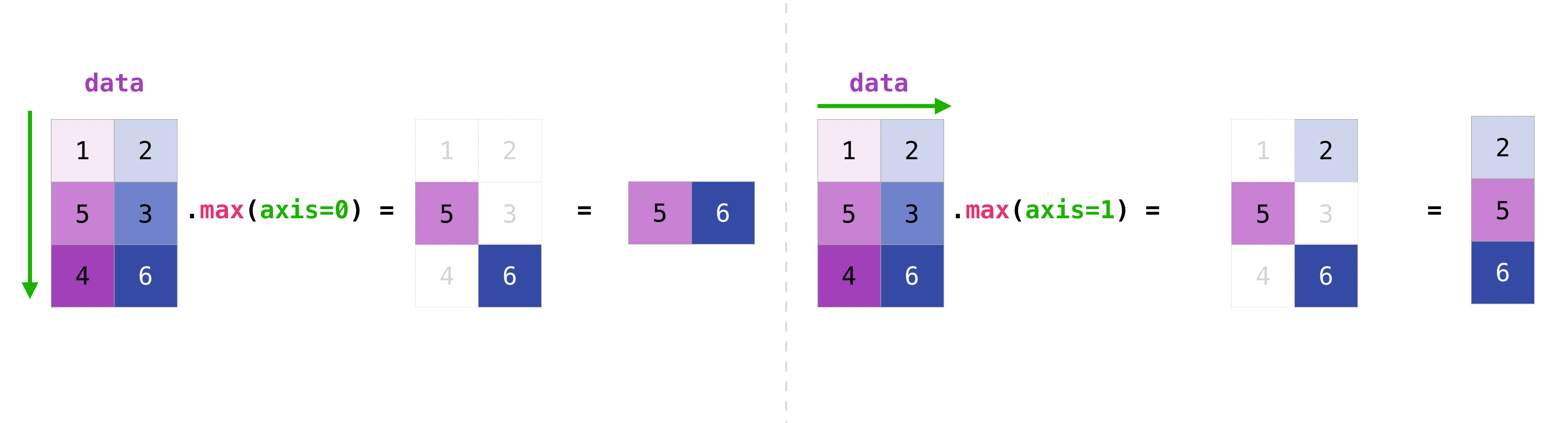
Vous pouvez agréger toutes les valeurs d'une matrice ou utiliser des paramètres d'axe pour les agréger sur des colonnes ou des lignes.
>>> data.max(axis=0)
array([3, 4])
>>> data.max(axis=1)
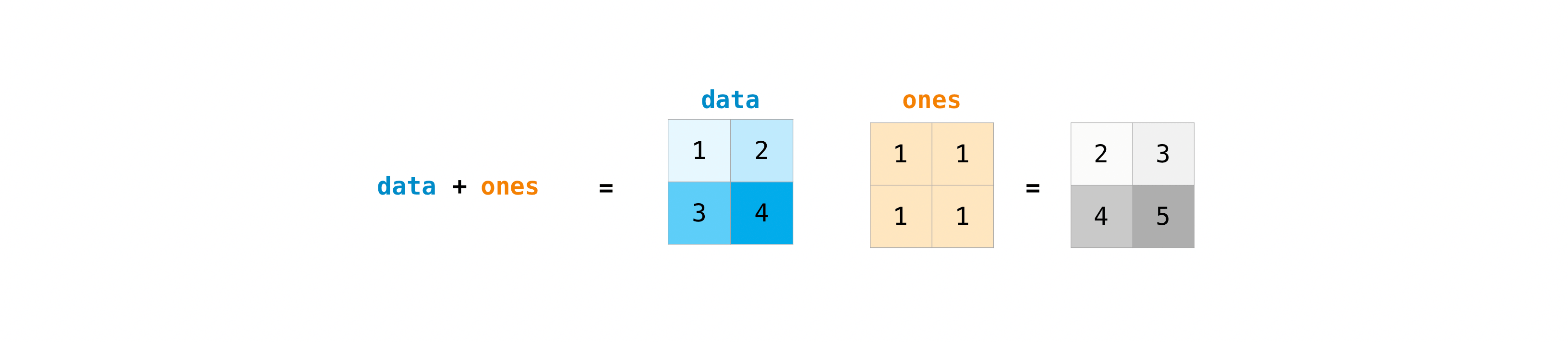
array([2, 4])
Une fois que vous avez créé une matrice, si vous avez deux matrices de même taille, vous pouvez utiliser des opérateurs arithmétiques pour ajouter ou multiplier.
>>> data = np.array([[1, 2], [3, 4]])
>>> ones = np.array([[1, 1], [1, 1]])
>>> data + ones
array([[2, 3],
[4, 5]])
Vous pouvez effectuer ces opérations arithmétiques sur des matrices de tailles différentes, mais uniquement si une matrice n'a qu'une seule ligne ou une seule colonne. Dans ce cas, NumPy utilise des règles de diffusion pour l'opération.
>>> data = np.array([[1, 2], [3, 4], [5, 6]])
>>> ones_row = np.array([[1, 1]])
>>> data + ones_row
array([[2, 3],
[4, 5],
[6, 7]])
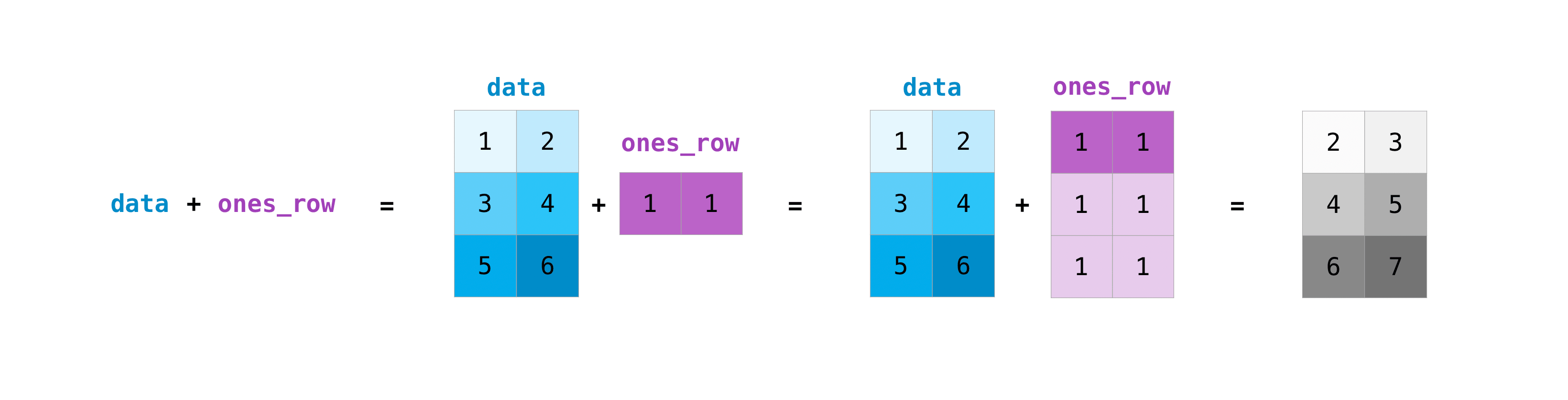
Notez que lorsque NumPy affiche un tableau à N dimensions, le dernier axe effectue le plus de boucles, tandis que le premier axe effectue une boucle lâche [12 fois pour la colonne, qui est le dernier axe dans l'exemple suivant. Il y a 4 boucles sur le premier axe]. Par exemple
>>> np.ones((4, 3, 2))
array([[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]]])
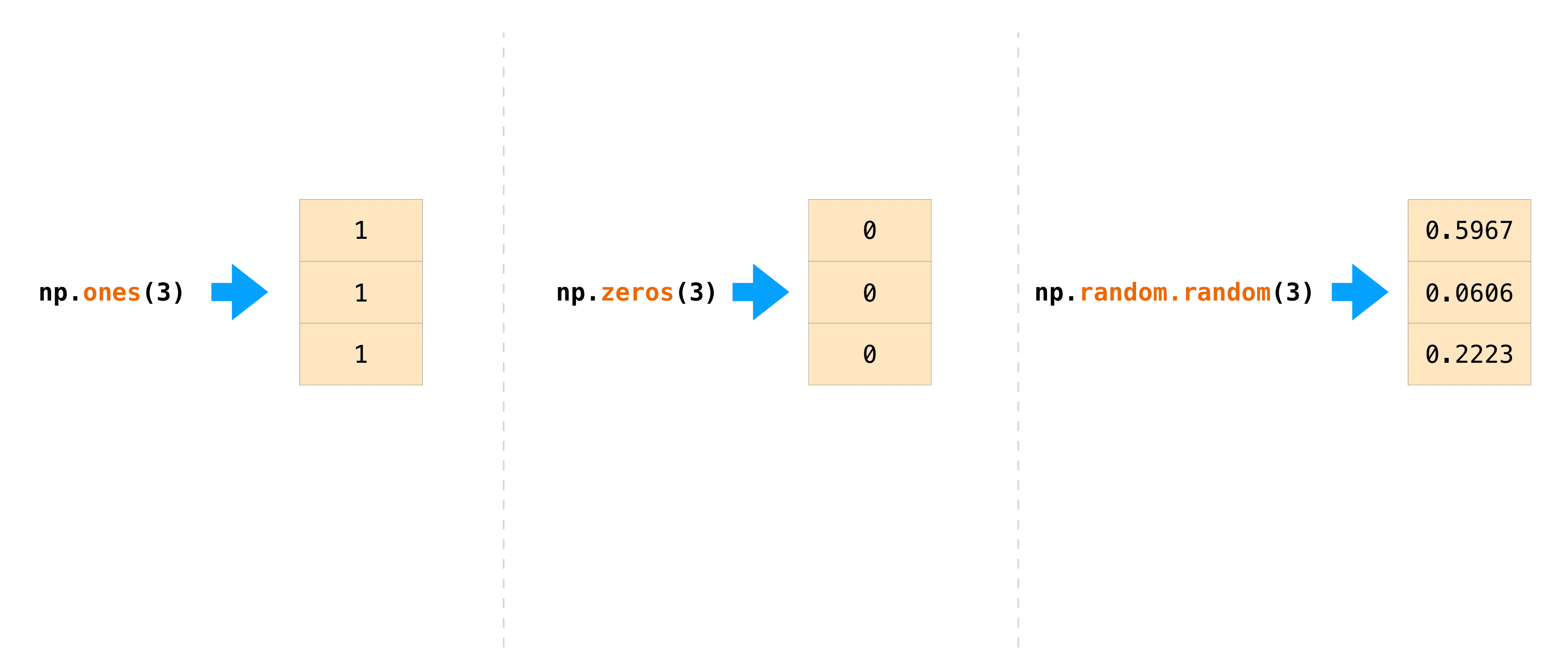
Vous souhaitez souvent initialiser un tableau avec NumPy. NumPy fournit des fonctions telles que ʻones () et zeros () et la classe random.Generator` pour la génération de nombres aléatoires. Tout ce que vous avez à faire pour l'initialisation est de passer le nombre d'éléments que vous souhaitez générer.
>>>np.ones(3)
array([1., 1., 1.])
>>> np.zeros(3)
array([0., 0., 0.])
# the simplest way to generate random numbers
>>> rng = np.random.default_rng(0)
>>> rng.random(3)
array([0.63696169, 0.26978671, 0.04097352])
 この関数やメソッドに二次元の行列を表すタプルを与えれば、
この関数やメソッドに二次元の行列を表すタプルを与えれば、ones()、zeros()とrandom() を使って二次元配列も生成可能です。
>>> np.ones((3, 2))
array([[1., 1.],
[1., 1.],
[1., 1.]])
>>> np.zeros((3, 2))
array([[0., 0.],
[0., 0.],
[0., 0.]])
>>> rng.random((3, 2))
array([[0.01652764, 0.81327024],
[0.91275558, 0.60663578],
[0.72949656, 0.54362499]]) # may vary
Générer des nombres aléatoires
L'utilisation de la génération de nombres aléatoires est une partie importante du placement et de l'évaluation de nombreux algorithmes mathématiques ou d'apprentissage automatique. Initialisation aléatoire du poids du réseau de neurones artificiels, division en ensembles aléatoires ou brassage aléatoire des ensembles de données, dans tous les cas, manque de capacité à générer des nombres aléatoires (en fait, le nombre de nombres pseudo-aléatoires reproductibles) Je ne peux pas. Vous pouvez utiliser Generator.integers pour sortir un entier aléatoire du minimum au maximum (notez que Numpy inclut le minimum et non le maximum). Vous pouvez définir ʻendpoint = True` pour générer un nombre aléatoire contenant la valeur la plus élevée.
Vous pouvez générer une matrice 2x4 composée d'entiers aléatoires de 0 à 4:
>>> rng.integers(5, size=(2, 4))
array([[2, 1, 1, 0],
[0, 0, 0, 4]]) # may vary
Comment récupérer et compter les éléments qui ne se chevauchent pas
- Cette section traite de
np.unique ()*
Vous pouvez récupérer les éléments d'un tableau un par un avec Np.unique sans duplication.
Prenez ce tableau comme exemple.
>>> a = np.array([11, 11, 12, 13, 14, 15, 16, 17, 12, 13, 11, 14, 18, 19, 20])
Vous pouvez utiliser Np.unique pour trouver les valeurs uniques du tableau.
>>>
>>> unique_values = np.unique(a)
>>> print(unique_values)
[11 12 13 14 15 16 17 18 19 20]
Pour obtenir l'index des valeurs uniques du tableau Numpy (le premier index de chaque valeur unique du tableau), passez l'argument return_index avec le tableau à np.unique ().
>>> unique_values, indices_list = np.unique(a, return_index=True)
>>> print(indices_list)
[ 0 2 3 4 5 6 7 12 13 14]
Vous pouvez passer l'argument return_counts avec le tableau à np.unique () pour savoir combien de valeurs uniques chaque tableau Numpy a.
>>> unique_values, occurrence_count = np.unique(a, return_counts=True)
>>> print(occurrence_count)
[3 2 2 2 1 1 1 1 1 1]
Cela fonctionne également pour les tableaux à deux dimensions!
>>> a_2d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [1, 2, 3, 4]])
De cette façon, vous pouvez trouver des valeurs uniques.
>>> unique_values = np.unique(a_2d)
>>> print(unique_values)
[ 1 2 3 4 5 6 7 8 9 10 11 12]
Si aucun argument d'axe n'est passé, le tableau à deux dimensions sera aplati à une dimension.
Si vous souhaitez connaître une ligne ou une colonne unique, assurez-vous de transmettre l'argument axe. Spécifiez ʻaxis = 0 pour les lignes uniques et ʻaxis = 1 pour les colonnes.
>>> unique_rows = np.unique(a_2d, axis=0)
>>> print(unique_rows)
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
Pour obtenir une colonne, une position d'index et un nombre d'occurrences uniques:
>>> unique_rows, indices, occurrence_count = np.unique(
... a_2d, axis=0, return_counts=True, return_index=True)
>>> print(unique_rows)
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
>>> print(indices)
[0 1 2]
>>> print(occurrence_count)
[2 1 1]
Translocation et transformation de la matrice
- Cette section traite de ʻarr.reshape ()
, ʻarr.transpose (), ʻarr.T () `* Il est souvent nécessaire de transposer la matrice. Le tableau Numpy a la propriété «T» pour transposer la matrice.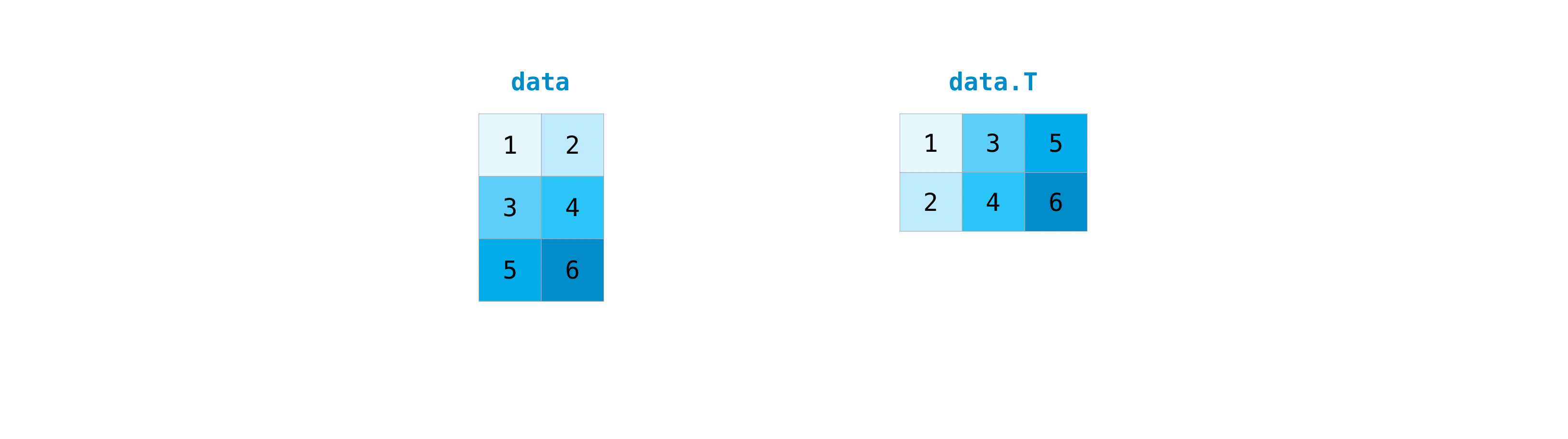
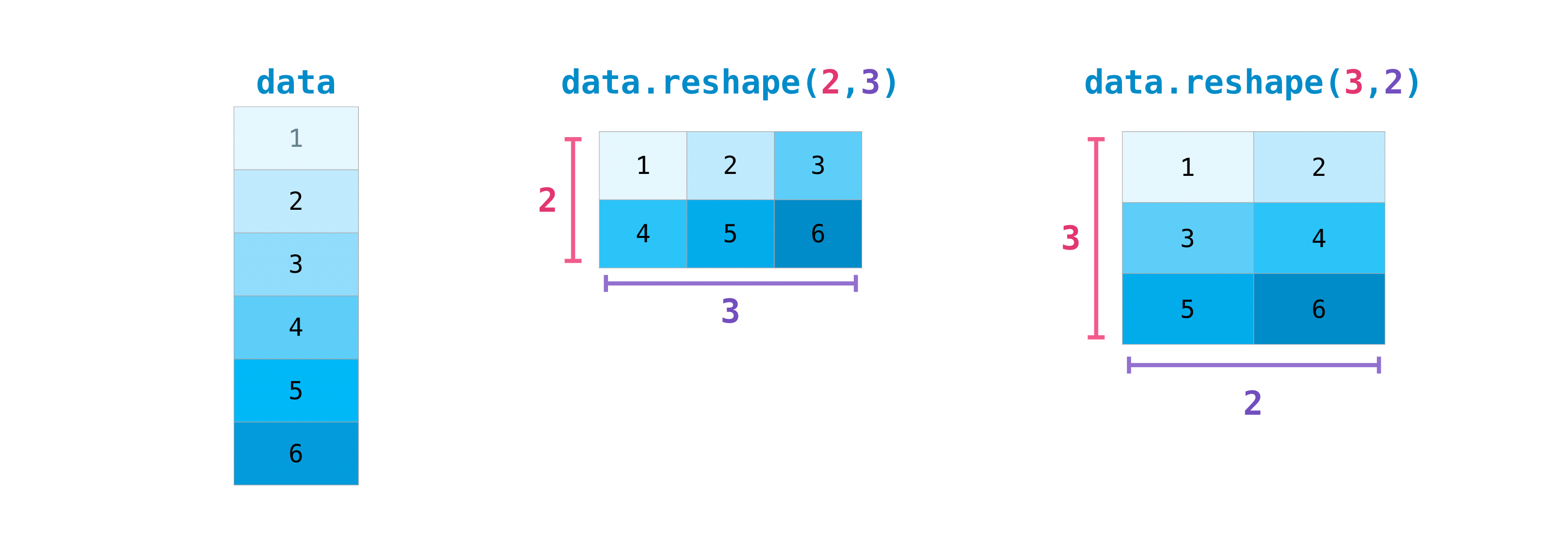
Vous devrez peut-être également permuter les dimensions du tableau. Cela se produit, par exemple, si vous avez un modèle qui suppose un tableau d'entrées différent de l'ensemble de données. La méthode de remodelage est utile dans de tels cas. Tout ce que vous avez à faire est de transmettre les nouvelles dimensions [dimensions] dont vous avez besoin pour la matrice.
>>> data.reshape(2, 3)
array([[1, 2, 3],
[4, 5, 6]])
>>> data.reshape(3, 2)
array([[1, 2],
[3, 4],
[5, 6]])
Vous pouvez également utiliser .transpose pour inverser ou modifier les axes du tableau en fonction de la valeur spécifiée.
Prenez ce tableau comme exemple:
>>> arr = np.arange(6).reshape((2, 3))
>>> arr
array([[0, 1, 2],
[3, 4, 5]])
Vous pouvez transposer un tableau en utilisant ʻarr.transpose () `.
>>> arr.transpose()
array([[0, 3],
[1, 4],
[2, 5]])
Comment inverser un tableau
- Cette section traite de
np.flip*
«Np.flip ()» de NumPy peut inverser l'axe d'un tableau par rapport à l'axe. Lorsque vous utilisez np.flip (), spécifiez le tableau et l'axe que vous voulez retourner. Si aucun axe n'est spécifié, NumPy inverse le tableau donné pour tous les axes.
Inverser le tableau 1D
Prenons l'exemple du tableau unidimensionnel suivant:
>>> arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
Vous pouvez inverser le tableau de cette façon:
>>> reversed_arr = np.flip(arr)
Si vous voulez voir le tableau inversé, exécutez ce code:
>>> print('Reversed Array: ', reversed_arr)
Reversed Array: [8 7 6 5 4 3 2 1]
Inverser le tableau 2D
Les tableaux 2D sont inversés de la même manière.
Prenez ce tableau comme exemple:
>>> arr_2d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
Vous pouvez inverser le contenu de toutes les colonnes et lignes.
>>> reversed_arr = np.flip(arr_2d)
>>> print(reversed_arr)
[[12 11 10 9]
[ 8 7 6 5]
[ 4 3 2 1]]
C'est le seul moyen d'inverser les lignes uniquement:
>>> reversed_arr_rows = np.flip(arr_2d, axis=0)
>>> print(reversed_arr_rows)
[[ 9 10 11 12]
[ 5 6 7 8]
[ 1 2 3 4]]
Pour ne retourner que les colonnes:
>>> reversed_arr_columns = np.flip(arr_2d, axis=1)
>>> print(reversed_arr_columns)
[[ 4 3 2 1]
[ 8 7 6 5]
[12 11 10 9]]
Vous pouvez également inverser une seule ligne ou colonne. Par exemple, vous pouvez inverser la ligne avec l'index 1 (deuxième ligne):
>>> arr_2d[1] = np.flip(arr_2d[1])
>>> print(arr_2d)
[[ 1 2 3 4]
[ 8 7 6 5]
[ 9 10 11 12]]
Vous pouvez également inverser la colonne d'index 1 (deuxième colonne):
>>> arr_2d[:,1] = np.flip(arr_2d[:,1])
>>> print(arr_2d)
[[ 1 10 3 4]
[ 8 7 6 5]
[ 9 2 11 12]]
Comment remodeler et aplatir un tableau multidimensionnel
- Cette section traite de
.flatten (),ravel ()*
Il existe deux méthodes courantes pour aplatir un tableau. «.flatten ()» et «.ravel ()». La principale différence entre les deux est que la séquence créée à l'aide de .ravel () est en fait une référence (ou "vue") à la séquence parent. Par conséquent, si vous modifiez quoi que ce soit dans le nouveau tableau, le tableau parent changera également. ravel ne fait pas de copie, c'est donc une mémoire efficace.
>>> x = np.array([[1 , 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
Vous pouvez utiliser flatten pour transformer un tableau en un tableau 1D.
>>> x.flatten()
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
Avec flatten ', les modifications apportées au tableau ne sont pas appliquées au tableau parent.
Par exemple:
>>> a1 = x.flatten()
>>> a1[0] = 99
>>> print(x) # Original array
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
>>> print(a1) # New array
[99 2 3 4 5 6 7 8 9 10 11 12]
Mais avec ravel, les modifications apportées au tableau ne sont pas appliquées au tableau parent.
>>> a2 = x.ravel()
>>> a2[0] = 98
>>> print(x) # Original array
[[98 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
>>> print(a2) # New array
[98 2 3 4 5 6 7 8 9 10 11 12]
Visitez le docstring pour en savoir plus
Cette section traite de help (), ?, ??.
En ce qui concerne l'écosystème de la science des données, Python et NumPy sont conçus en pensant à l'utilisateur. Un bon exemple de ceci est qu'il a accès à la documentation. Chaque objet a une référence à une chaîne, connue sous le nom de docstring. Dans la plupart des cas, cette docstring contient un aperçu bref et concis de l'objet et de son utilisation. Python a une fonction d'aide intégrée qui vous aide à accéder à la docstring. Cela signifie que lorsque vous avez besoin de plus d'informations, vous pouvez généralement utiliser help () pour trouver rapidement les informations dont vous avez besoin.
Par exemple
>>> help(max)
Help on built-in function max in module builtins:
max(...)
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> value
With a single iterable argument, return its biggest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
With two or more arguments, return the largest argument.
L'accès à plus d'informations peut être très utile, alors qu'en est-il d'IPython? Sert d'abréviation pour accéder à d'autres informations liées à la documentation. IPython est un shell de commande pour les calculs interactifs qui peut être utilisé dans plusieurs langues. En savoir plus sur IPython.
Par exemple
In [0]: max?
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> value
With a single iterable argument, return its biggest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
With two or more arguments, return the largest argument.
Type: builtin_function_or_method
Cette notation peut même être utilisée pour les méthodes objet et même les objets eux-mêmes.
Supposons que vous ayez créé la séquence suivante:
>>> a = np.array([1, 2, 3, 4, 5, 6])
Cela vous donnera beaucoup d'informations utiles (d'abord les détails de l'objet lui-même, suivis de la docstring du ndarray où a est une instance).
In [1]: a?
Type: ndarray
String form: [1 2 3 4 5 6]
Length: 6
File: ~/anaconda3/lib/python3.7/site-packages/numpy/__init__.py
Docstring: <no docstring>
Class docstring:
ndarray(shape, dtype=float, buffer=None, offset=0,
strides=None, order=None)
An array object represents a multidimensional, homogeneous array
of fixed-size items. An associated data-type object describes the
format of each element in the array (its byte-order, how many bytes it
occupies in memory, whether it is an integer, a floating point number,
or something else, etc.)
Arrays should be constructed using `array`, `zeros` or `empty` (refer
to the See Also section below). The parameters given here refer to
a low-level method (`ndarray(...)`) for instantiating an array.
For more information, refer to the `numpy` module and examine the
methods and attributes of an array.
Parameters
----------
(for the __new__ method; see Notes below)
shape : tuple of ints
Shape of created array.
...
Cela fonctionne également pour les fonctions et autres objets que vous créez. Pourtant. N'oubliez pas de mettre la docstring à l'intérieur de la fonction en utilisant le caractère littéral (mettez le document entre " "" "" " ou '' '').
Par exemple, si vous créez la fonction suivante
>>> def double(a):
... '''Return a * 2'''
... return a * 2
Pour obtenir des informations sur cette fonction:
In [2]: double?
Signature: double(a)
Docstring: Return a * 2
File: ~/Desktop/<ipython-input-23-b5adf20be596>
Type: function
Vous pouvez obtenir un niveau d'informations différent en lisant le code source de l'objet qui vous intéresse. Vous pouvez accéder au code source en utilisant le double point d'interrogation (??).
Par exemple
In [3]: double??
Signature: double(a)
Source:
def double(a):
'''Return a * 2'''
return a * 2
File: ~/Desktop/<ipython-input-23-b5adf20be596>
Type: function
Si l'objet est compilé dans un langage autre que Python, l'utilisation de ?? renverra les mêmes informations que?. Cela peut être vu dans de nombreux objets et types intégrés. Par exemple
In [4]: len?
Signature: len(obj, /)
Docstring: Return the number of items in a container.
Type: builtin_function_or_method
Et:
In [5]: len??
Signature: len(obj, /)
Docstring: Return the number of items in a container.
Type: builtin_function_or_method
Ils ont la même sortie car ils sont compilés dans un langage autre que Python.
Gérer les formules mathématiques
L'une des raisons pour lesquelles NumPy est si largement utilisé dans la communauté scientifique Python est qu'il facilite la mise en œuvre de formules qui fonctionnent sur des tableaux.
Par exemple, il s'agit de l'erreur quadratique moyenne (la formule centrale utilisée dans les modèles d'apprentissage automatique supervisé qui traitent de la régression).
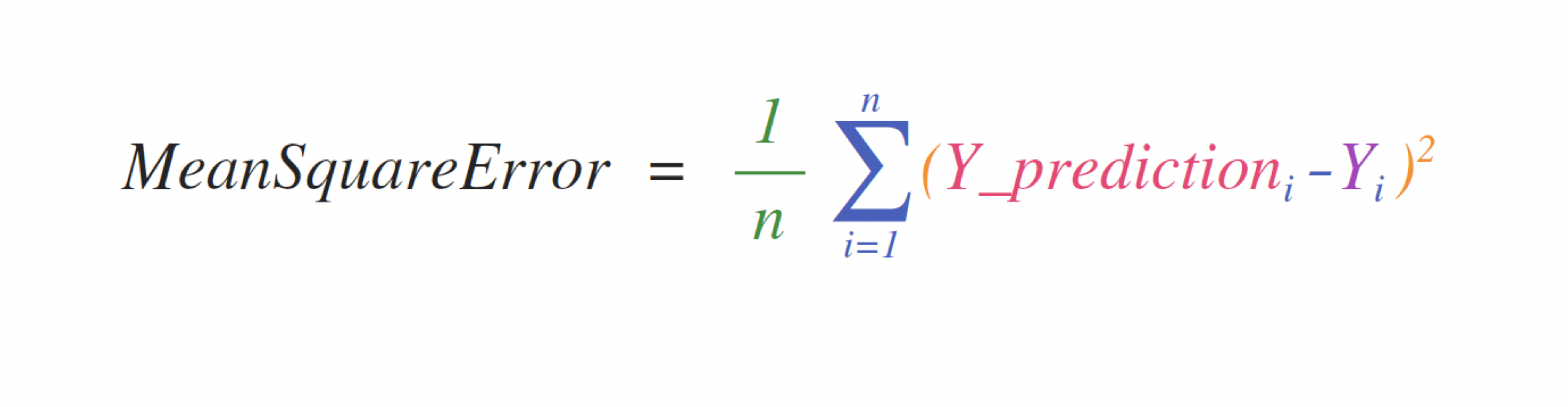
L'implémentation de cette expression est simple dans NumPy et est la même que l'expression:
error = (1/n) * np.sum(np.square(predictions - labels))
Cela fonctionne très bien car il peut contenir une ou 1000 valeurs et étiquettes prédites. Tout ce dont vous avez besoin est que la valeur prédite et l'étiquette soient de la même taille.
Cela peut être visualisé comme suit:

Dans cet exemple, la prédiction et l'étiquette sont des Bertholds avec trois valeurs, donc n prend la valeur trois. Après la soustraction, la valeur du vecteur est mise au carré. NumPy additionne ensuite les valeurs et le résultat est un score d'erreur prédite et de qualité du modèle.

Comment enregistrer et charger NumPy
- Cette section traite de
np.save,np.savez,np.savetxt,np.load,np.loadtxt*
À un moment donné, vous souhaiterez peut-être enregistrer la matrice sur le disque et la charger sans avoir à réexécuter le code. Heureusement, NumPy a plusieurs façons d'enregistrer et de charger des objets. L'objet ndarray peut charger et enregistrer des fichiers texte normaux avec les fonctions loadtxt et savetxt, et gérer les fichiers binaires NumPy avec l'extension .npz avec les fonctions load et save. Et vous pouvez travailler avec des fichiers Numpy avec l'extension .npz avec la fonction Savez.
Les fichiers **. Npy ** et **. Npz ** stockent des données, des formes, des dtypes et d'autres informations nécessaires pour reconstruire le ndarray afin que les fichiers puissent être récupérés correctement sur différentes architectures. Je suis.
Si vous souhaitez enregistrer un objet ndarray, utilisez np.save pour l'enregistrer en tant que fichier .npy. Si vous souhaitez enregistrer plusieurs ndarrays dans un tableau, utilisez np.savez et enregistrez-le sous .npz. Vous pouvez également enregistrer plusieurs tableaux dans un seul fichier en enregistrant au format npz compressé avec savez_compressed.
Il est facile de sauvegarder, de charger et de créer un tableau avec np.save (). Il est facile de sauvegarder et de charger et de créer un tableau avec np.save (). N'oubliez pas de spécifier le tableau et le nom de fichier que vous souhaitez enregistrer. Par exemple, si vous créez ce tableau
>>> a = np.array([1, 2, 3, 4, 5, 6])
Vous pouvez l'enregistrer sous "filename.npy".
>>> np.save('filename', a)
Vous pouvez restaurer le tableau avec np.load ().
>>> b = np.load('filename.npy')
Si vous souhaitez voir la séquence, vous pouvez exécuter ce code.
>>> print(b)
[1 2 3 4 5 6]
Vous pouvez utiliser np.savetxt pour enregistrer les fichiers NumPy sous forme de texte brut comme les fichiers .csv et .txt.
Par exemple, si vous créez la séquence suivante
>>> csv_arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
```shell
You can easily save it as a .csv file with the name “new_file.csv” like this:
```shell
>>> np.savetxt('new_file.csv', csv_arr)
Vous pouvez facilement charger un fichier texte enregistré en utilisant loadtxt ().
>>> np.loadtxt('new_file.csv')
array([1., 2., 3., 4., 5., 6., 7., 8.])
Les fonctions savetxt () et loadtxt () acceptent des paramètres supplémentaires tels que les en-têtes, les pieds de page et les délimiteurs. Les fichiers texte sont pratiques pour le partage, tandis que les fichiers .npy et .npz sont petits et rapides à lire et à écrire. Si vous avez besoin d'une gestion plus sophistiquée des fichiers texte (par exemple, lorsque vous traitez avec une matrice [lignes] contenant des valeurs manquantes), genfromtxt Vous devrez utiliser la fonction .genfromtxt.html # numpy.genfromtxt).
Lorsque vous utilisez savetxt, vous pouvez spécifier des en-têtes, des pieds de page, des commentaires, etc.
Learn more about input and output routines here.
Comment importer / exporter un fichier CSV
Il est facile de lire un fichier CSV contenant des informations existantes. Le moyen le plus simple est d'utiliser Pandas.
>>> import pandas as pd
>>> # If all of your columns are the same type:
>>> x = pd.read_csv('music.csv', header=0).values
>>> print(x)
[['Billie Holiday' 'Jazz' 1300000 27000000]
['Jimmie Hendrix' 'Rock' 2700000 70000000]
['Miles Davis' 'Jazz' 1500000 48000000]
['SIA' 'Pop' 2000000 74000000]]
>>> # You can also simply select the columns you need:
>>> x = pd.read_csv('music.csv', usecols=['Artist', 'Plays']).values
>>> print(x)
[['Billie Holiday' 27000000]
['Jimmie Hendrix' 70000000]
['Miles Davis' 48000000]
['SIA' 74000000]]
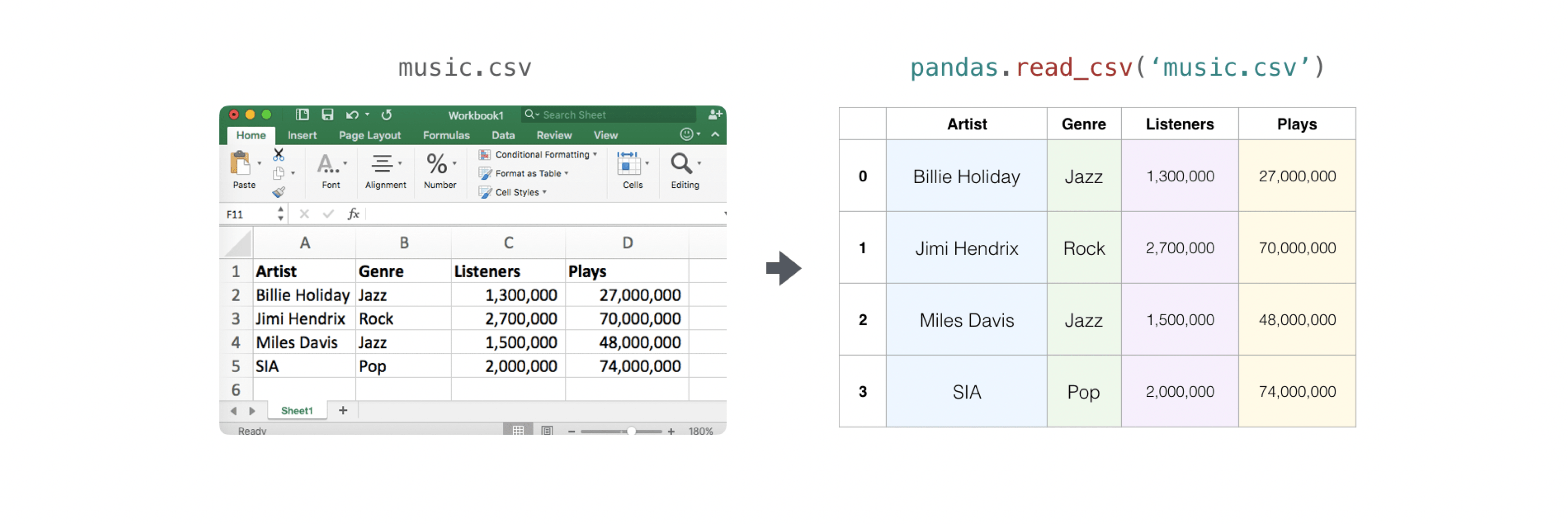
L'exportation d'un tableau est également facile avec Pandas. Si vous êtes nouveau dans NumPy, c'est une bonne idée de créer une trame de données Pandas à partir de valeurs de tableau et d'écrire cette trame de données dans un fichier CSV avec Pandas.
Disons que vous avez créé le tableau "a".
>>> a = np.array([[-2.58289208, 0.43014843, -1.24082018, 1.59572603],
... [ 0.99027828, 1.17150989, 0.94125714, -0.14692469],
... [ 0.76989341, 0.81299683, -0.95068423, 0.11769564],
... [ 0.20484034, 0.34784527, 1.96979195, 0.51992837]])
Vous pouvez créer un bloc de données Pandas comme suit:
>>> df = pd.DataFrame(a)
>>> print(df)
0 1 2 3
0 -2.582892 0.430148 -1.240820 1.595726
1 0.990278 1.171510 0.941257 -0.146925
2 0.769893 0.812997 -0.950684 0.117696
3 0.204840 0.347845 1.969792 0.519928
Vous pouvez enregistrer le bloc de données comme suit:
>>> df.to_csv('pd.csv')
CSV est comme ça
>>> data = pd.read_csv('pd.csv')
 NumPyのsavetxtメソッドを使って保存することもできます。
NumPyのsavetxtメソッドを使って保存することもできます。
>>> np.savetxt('np.csv', a, fmt='%.2f', delimiter=',', header='1, 2, 3, 4')
Si vous utilisez la ligne de commande, vous pouvez toujours charger le CSV enregistré avec une commande comme celle-ci:
$ cat np.csv
# 1, 2, 3, 4
-2.58,0.43,-1.24,1.60
0.99,1.17,0.94,-0.15
0.77,0.81,-0.95,0.12
0.20,0.35,1.97,0.52
Vous pouvez également l'ouvrir dans un éditeur de texte à tout moment.
Pour en savoir plus sur Pandas, consultez la documentation officielle de Pandas. Pour plus d'informations sur l'installation de Pandas, consultez informations d'installation officielles de Pandas.
Tracer le tableau avec Matplotlib
Si vous avez besoin de créer un tracé de valeurs, Matplotlib est très facile à utiliser.
Par exemple, vous pourriez avoir un tableau comme celui-ci:
>>> a = np.array([2, 1, 5, 7, 4, 6, 8, 14, 10, 9, 18, 20, 22])
Si Matplotlib est déjà installé, vous pouvez l'importer comme ceci:
>>> import matplotlib.pyplot as plt
# If you're using Jupyter Notebook, you may also want to run the following
# line of code to display your code in the notebook:
%matplotlib inline
Aucun travail fastidieux n'est nécessaire pour tracer les valeurs.
>>> plt.plot(a)
# If you are running from a command line, you may need to do this:
# >>> plt.show()
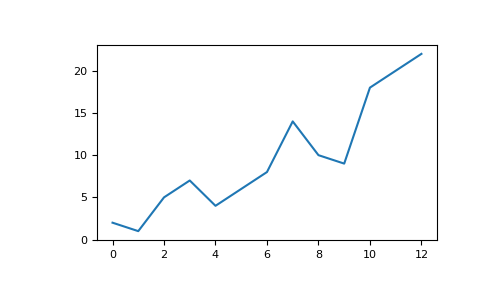
Par exemple, vous pouvez tracer un tableau 1D comme suit:
‘>>> x = np.linspace(0, 5, 20)
>>> y = np.linspace(0, 10, 20)
>>> plt.plot(x, y, 'purple') # line
>>> plt.plot(x, y, 'o') # dots
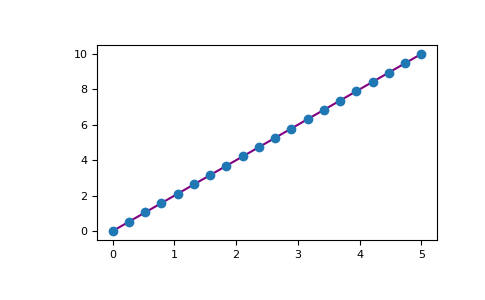
Matplotlib offre un grand nombre d'options de visualisation.
>>> from mpl_toolkits.mplot3d import Axes3D
>>> fig = plt.figure()
>>> ax = Axes3D(fig)
>>> X = np.arange(-5, 5, 0.15)
>>> Y = np.arange(-5, 5, 0.15)
>>> X, Y = np.meshgrid(X, Y)
>>> R = np.sqrt(X**2 + Y**2)
>>> Z = np.sin(R)
>>> ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='viridis')
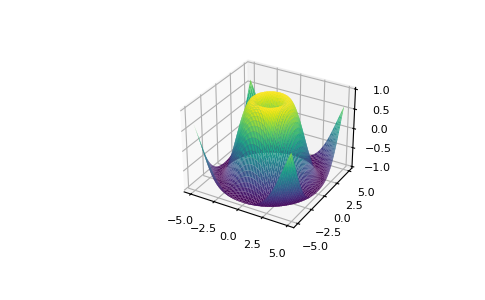
To read more about Matplotlib and what it can do, take a look at the official documentation.FordirectionsregardinginstallingMatplotlib,seetheofficialinstallationsection.
mage credits: Jay Alammar http://jalammar.github.io/
Recommended Posts