[PYTHON] [Sentence classification] I tried various pooling methods of Convolutional Neural Networks
Introduction
In sentence classification, max pooling is often used for Convolutional Neural Networks (CNN), but I wondered if other pooling methods would be useless.
data
- Source code --Implemented with Chainer.
- data set --I'm using Stanford Sentiment Treebank (SST). -You can download it at here. --Word distributed expression --I'm using the trained model of word2vec (GoogleNews-vectors-negative300.bin.gz). You can download it at here.
What is sentence classification?
The task of labeling statements. For example, in the SST above, each sentence has a positive and negative label.
[positive]She has a good personality and, above all, a good style.
[Negative]This season's anime is poor.
SST is in English, but the Japanese example looks like this. In addition to positive negatives, there are also datasets that address topics such as sports and politics.
Network model
Based on Convolutional Neural Networks for Sentence Classification [Kim, 2014]. In the field of natural language processing, this paper is often cited when talking about CNN.

pooling layer
The Max-over-time pooling (max pooling) part in the figure above is the pooling layer. This time the story here. In addition to max pooling, CNN may also use average pooling. max pooling retrieves the largest value from the feature map, while average pooling retrieves the average of the features map values. This paper has already reported that max pooling had a higher accuracy rate for text classification in some datasets than average pooling.
Padding
Then max pooling is fine, but However, in natural language processing, the lengths of input sentences are not the same, so a process called padding is required to make the input sentence lengths uniform. Therefore, strictly speaking, the average is not taken by the sentence length, but is taken by the maximum sentence length of the input. (Maybe the paper introduced above is also ...) In that case, I wondered if the average pooling version was not the version that averaged the feature map length (maximum sentence length), but the version that averaged the sentence length.
(Example.)

↑ The result of convolving \
Code (network part)
cnn_average.py
class CNN_average(Chain):
def __init__(self, vocab_size, embedding_size, input_channel, output_channel_1, output_channel_2, output_channel_3, k1size, k2size, k3size, pooling_units, output_size=args.classtype, train=True):
super(CNN_average, self).__init__(
w2e = L.EmbedID(vocab_size, embedding_size),
conv1 = L.Convolution2D(input_channel, output_channel_1, (k1size, embedding_size)),
conv2 = L.Convolution2D(input_channel, output_channel_2, (k2size, embedding_size)),
conv3 = L.Convolution2D(input_channel, output_channel_3, (k3size, embedding_size)),
l1 = L.Linear(pooling_units, output_size),
)
self.output_size = output_size
self.train = train
self.embedding_size = embedding_size
self.ignore_label = 0
self.w2e.W.data[self.ignore_label] = 0
self.w2e.W.data[1] = 0 #Non-character
self.input_channel = input_channel
def initialize_embeddings(self, word2id):
#w_vector = word2vec.Word2Vec.load_word2vec_format('./vector/glove.840B.300d.txt', binary=False) # GloVe
w_vector = word2vec.Word2Vec.load_word2vec_format('./vector/GoogleNews-vectors-negative300.bin', binary=True) # word2vec
for word, id in sorted(word2id.items(), key=lambda x:x[1])[1:]:
if word in w_vector:
self.w2e.W.data[id] = w_vector[word]
else:
self.w2e.W.data[id] = np.reshape(np.random.uniform(-0.25,0.25,self.embedding_size),(self.embedding_size,))
def __call__(self, x):
h_list = list()
ox = copy.copy(x)
if args.gpu != -1:
ox.to_gpu()
b = x.shape[0]
emp_array = xp.array([len(xp.where(x[i].data != 0)[0]) for i in range(b)], dtype=xp.float32).reshape(b,1,1,1)
x = xp.array(x.data)
x = F.tanh(self.w2e(x))
b, max_len, w = x.shape # batch_size, max_len, embedding_size
x = F.reshape(x, (b, self.input_channel, max_len, w))
c1 = self.conv1(x)
b, outputC, fixed_len, _ = c1.shape
tf = self.set_tfs(ox, b, outputC, fixed_len) # true&flase
h1 = self.average_pooling(F.relu(c1), b, outputC, fixed_len, tf, emp_array)
h1 = F.reshape(h1, (b, outputC))
h_list.append(h1)
c2 = self.conv2(x)
b, outputC, fixed_len, _ = c2.shape
tf = self.set_tfs(ox, b, outputC, fixed_len) # true&flase
h2 = self.average_pooling(F.relu(c2), b, outputC, fixed_len, tf, emp_array)
h2 = F.reshape(h2, (b, outputC))
h_list.append(h2)
c3 = self.conv3(x)
b, outputC, fixed_len, _ = c3.shape
tf = self.set_tfs(ox, b, outputC, fixed_len) # true&flase
h3 = self.average_pooling(F.relu(c3), b, outputC, fixed_len, tf, emp_array)
h3 = F.reshape(h3, (b, outputC))
h_list.append(h3)
h4 = F.concat(h_list)
y = self.l1(F.dropout(h4, train=self.train))
return y
def set_tfs(self, x, b, outputC, fixed_len):
TF = Variable(x[:,:fixed_len].data != 0, volatile='auto')
TF = F.reshape(TF, (b, 1, fixed_len, 1))
TF = F.broadcast_to(TF, (b, outputC, fixed_len, 1))
return TF
def average_pooling(self, c, b, outputC, fixed_len, tf, emp_array):
emp_array = F.broadcast_to(emp_array, (b, outputC, 1, 1))
masked_c = F.where(tf, c, Variable(xp.zeros((b, outputC, fixed_len, 1)).astype(xp.float32), volatile='auto'))
sum_c = F.sum(masked_c, axis=2)
p = F.reshape(sum_c, (b, outputC, 1, 1)) / emp_array
return p
Experiment contents
Compare the following four pooling methods using the Stanford Sentiment Treebank (SST) as a dataset
- max pooling --average pooling (1 / max len) ← The one who takes the average with the maximum sentence length --average pooling (1 / sent len) ← The one who takes the average for each sentence length --attention pooling ← I tried using the Attention mechanism for the pooling layer. For more information here
Experimental result
| pooling method | SST-2 | SST-5 |
|---|---|---|
| max | 86.3 (0.27) | 46.5 (1.13) |
| average (1/max len) | 84.6 (0.38) | 46.0 (0.69) |
| average (1/sent len) | 86.6 (0.51) | 47.3 (0.44) |
| attention | 86.0 (0.20) | 47.2 (0.37) |
The value is the average after 5 trials, and the value in () is the standard deviation. SST-5 is a task to classify 5 values of very negative, negative, neutral, positive and very positive, and SST-2 is a task to classify positive and negative excluding neutral.
max pooling It shakes quite a bit, and the result is that the average pooling, which is averaged by the length of the sentence, is the best. Average pooling, which takes the average with the maximum sentence length, is certainly weaker than max pooling. ..
Visualize the state of the feature map
[very positive] I admired this work a lot.
I tried to check how the feature map of max pooling CNN and average pooling (1 / sent len) CNN is learned for the sentence.
admired(Admire)A word that expresses the positive meaning of, and emphasizes ita lotIs the point of prediction.
The window size of CNN here is 3. The number of feature maps is 100.
First, max pooling. .. .. This guy mistakes this sentence for ``` [positive]` `` and predicts it. I'm sorry.

Since it is max pooling, the darkest part of each feature map will be extracted after this.
admired this workThere are many feature maps from which the part of is extracted.
admired this work and lot. <PAD>Is extracted in a separate feature map.
Next, average pooling. .. .. This guy correctly answers `` `[very positive]` ``. Cute guy.
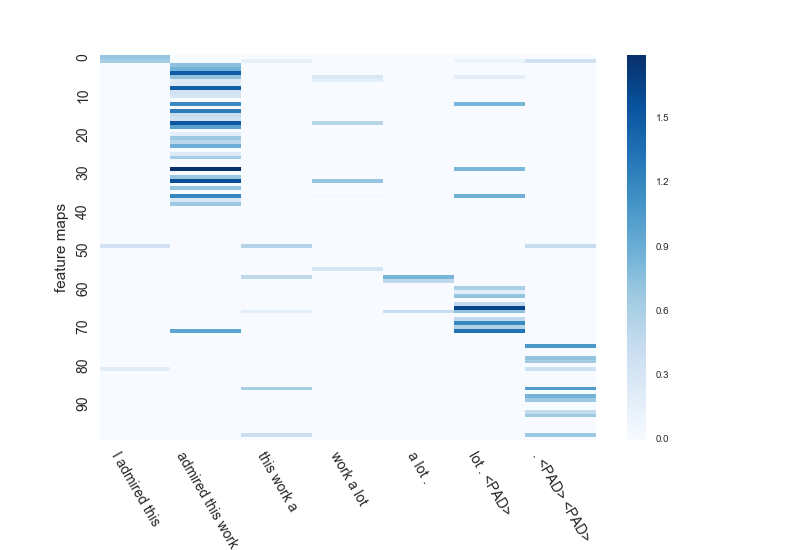
Since it is average pooling, you can consider multiple things such as the second and third in addition to the darkest part.
#### **`admired this work and lot. <PAD>You can also see a feature map that extracts.`**
``` <PAD>You can also see a feature map that extracts.
It seems that the learning results are quite different even with the same CNN between max pooling, which uses only the maximum value, and average pooling, which uses all the values to obtain the average value.
# Consideration
Whereas max pooling can only extract one feature from one feature map
Average pooling and attention pooling can extract multiple features from one feature map.
In the above example, it is possible to consider ```admired``` and ```a lot``` which are a little apart from each other in one feature map at the same time. I wonder if this was good. .. ..
# in conclusion
In natural language processing, max pooling is often used, but it turned out that average pooling can also be used unexpectedly if it is properly divided by the sentence length.
Intuitively, I feel that average pooling is better.
It's true that the calculation time is longer than max, but it doesn't bother me so much because CNN itself is fast. (It was much faster than the RNN using LSTM.)
When I do CNN from now on, I want to try average pooling at the same time.
Recommended Posts