[PYTHON] Emotional polarity judgment of sentences using the text classifier fastText
Introduction
I have created a script that automatically determines the emotional polarity (positive, negative) for any sentence, so I would like to summarize it.
In the field of judging emotional polarity from sentences (documents), it is also called Sentiment Analysis or reputation analysis. In the past, the orthodox method was to register polarity values (positive and negative values) for each word in a word polarity dictionary and use them to determine polarity. However, with that method, there is a problem that it is not possible to calculate when a word that is not in the polarity dictionary appears, and is it possible to uniquely determine the polarity of the word in the first place? There is a problem. (e.g. Even one word "cheap" is cheap and bargain! When you say cheap is positive, but when you say that you are cheap, you get a negative impression.)
Therefore, in this article, we will introduce a script that automatically calculates the emotional polarity of a sentence using a text classifier and review data from an EC site. By learning from the review data, ** the point that you can save the trouble of creating a polarity dictionary and the point that you can judge the emotional polarity by considering syntactic information (the polarity value of the word can be changed flexibly) ** Maybe it tastes good! I made it with the expectation.
fastText fastText [^ 1] is a machine learning that supports word vectorization and text classification developed by facebook.
The structure itself is a three-layer neural network structure as shown in the figure below, and has a structure very similar to the CBoW model proposed by Mikolov et al.
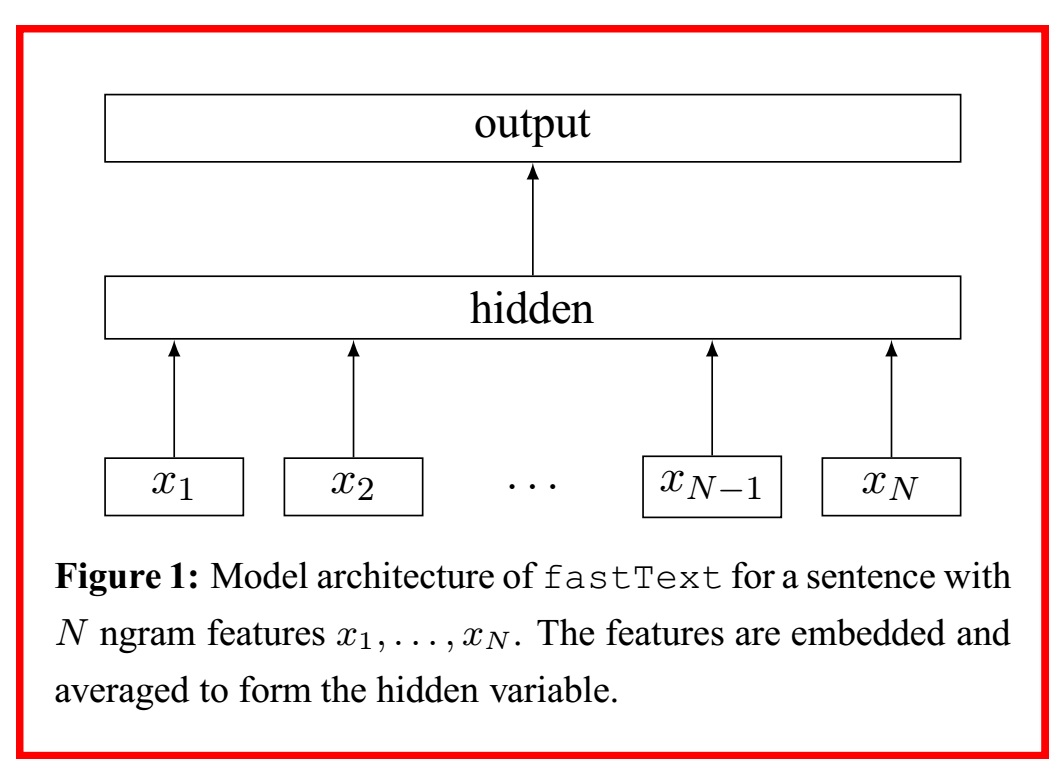
In the input layer, the one-hot vector of the words contained in the $ i $ th document is given, and in the output layer, the probability distribution that each document belongs to each class by softmax $ {\ bf p} = (p_1, p_2, .. ., p_n) Get $. The exclusive classification method (outputting any one class) outputs the class with the highest probability value of $ {\ bf p} $.
Training data
This time, we created a sentence polarity judgment model using the review data of EC sites (Amazon and Rakuten). Of the reviews for the product, prepare the number of stars as the correct label and the review text as learning data. If you want fastText to learn, you can create a list like the one below. The correct label is \ ___ label \ ___ **, and the learning background is a divided document.
train.lst
__label__1,My daughter wasn't interested in reading, so please take a look. It's black and white, and the illustrations aren't cute, so I opened it once ... I can't read it aloud.
did .
__label__1,It seems that it was sold out in 3 minutes after the start. I couldn't buy it.
Learning fastText
Learning fastText is very easy. When the training data (train.lst) is input_file and the save destination of the trained model is output, it can be trained with only the following code.
learning.py
argvs = sys.argv
input_file = argvs[1]
output = argvs[2]
classifier = ft.supervised(input_file, output)
Judgment of emotional polarity of sentences
Find the emotional polarity of the sentence given as input according to the following formula.
-$ e_i $: Evaluation value for $ i $ ($ e = \ {e_1 = 1, e_2 = 2, ..., e_5 = 5 \}
In the above formula, $ p_i $ indicates the value of the output layer of fastText, and $ e_i $ indicates the number of stars. The emotional polarity value $ score $ of a sentence is judged to be positive as it approaches 5, and negative as it approaches 1. ** If the text you enter is close to the nature of a star-studded review, $ score $ will be higher. ** **
estimation.py
# -*- coding: utf-8 -*-
import sys
import commands as cmd
import fasttext as ft
def text2bow(obj, mod):
# input:Mod for files="file", input:Mod for strings="str"
if mod == "file":
morp = cmd.getstatusoutput("cat " + obj + " | mecab -Owakati")
elif mod == "str":
morp = cmd.getstatusoutput("echo " + obj.encode('utf-8') + " | mecab -Owakati")
else:
print "error!!"
sys.exit(0)
words = morp[1].decode('utf-8')
words = words.replace('\n','')
return words
def Scoring(prob):
score = 0.0
for e in prob.keys():
score += e*prob[e]
return score
def SentimentEstimation(input, clf):
prob = {}
bow = text2bow(input, mod="str")
estimate = clf.predict_proba(texts=[bow], k=5)[0]
for e in estimate:
index = int(e[0][9:-1])
prob[index] = e[1]
score = Scoring(prob)
return score
def output(score):
print "Evaluation Score = " + str(score)
if score < 1.8:
print "Result: negative--"
elif score >= 1.8 and score < 2.6:
print "Result: negative-"
elif score >= 2.6 and score < 3.4:
print "Result: neutral"
elif score >= 3.4 and score < 4.2:
print "Result: positive+"
elif score >= 4.2:
print "Result: positive++"
else:
print "error"
sys.exit(0)
def main(model):
print "This program is able to estimate to sentiment in sentence."
print "Estimation Level:"
print " negative-- < negative- < neutral < positive+ < positive++"
print " bad <----------------------------------------> good"
print "Input:"
while True:
input = raw_input().decode('utf-8')
if input == "exit":
print "bye!!"
sys.exit(0)
score = SentimentEstimation(input, model)
output(score)
if __name__ == "__main__":
argvs = sys.argv
_usage = """--
Usage:
python estimation.py [model]
Args:
[model]: The argument is a model for sentiment estimation that is trained by fastText.
""".rstrip()
if len(argvs) < 2:
print _usage
sys.exit(0)
model = ft.load_model(argvs[1])
main(model)
Execution method
Execute as follows from the command line.
estimatin.py
$ python estimation.py [model]
-[model]: Learned fastText model (file called **. Bin)
Execution result
Here is the result of actually executing and judging the emotion polarity of the sentence. By the way, once it is executed, it becomes interactive, so enter "exit" when you want to exit.
This program is able to estimate to sentiment in sentence. Estimation Level: negative-- < negative- < neutral < positive+ < positive++ bad <----------------------------------------> good Input: The ramen shop I went to yesterday was really good! Evaluation Score = 4.41015725 Result: positive++ The ramen shop I went to yesterday was a little dirty, but it was very delicious! Evaluation Score = 4.27148227 Result: positive++ The ramen shop I went to yesterday was a fashionable shop, but the taste was not good Evaluation Score = 2.0507823 Result: negative- The ramen shop I went to yesterday was dirty, bad and terrible Evaluation Score = 1.12695298578 Result: negative-- exit bye!!
Somehow the result is like that! It conveys the feeling that the polarity can be judged by considering the end of the sentence, rather than the syntactic information.
Summary
This time, using the text classifier fastText and the review data of the EC site, I made a script that automatically judges the emotion polarity of the sentence. There is no problem if there is a review sentence and evaluation value of the EC site, so I think that the same thing can be done with Amazon or Pompare Mall data.
Recommended Posts