[PYTHON] Why did Deep Learning become so popular? (Simple explanation using terms)
Introduction
It's more content now, but I will post it as an article because it is a great deal to summarize in the assignment. Please let us know in the comments if you have any mistakes or inappropriate expressions.
Preface: Until the advent of Deep Learning

The big wave of the 3rd AI boom Source: "Is artificial intelligence surpassing humans? What lies beyond deep learning" Yutaka Matsuo (Author) Published by KADOKAWA
Deep Learning (Machine Learning), often referred to as ** AI **, There is a gap with the image of technology that has recently appeared, and its history goes back 60 years.
1st AI boom
The first AI boom is called the ** "era of reasoning and exploration" **, and the main method is to search the search tree thoroughly and give an action plan to make it look as if it is intelligent. There was no such rich technology as it is today. Even so, it was possible to give instructions in a maze or words to operate building blocks, or to challenge chess or shogi. However, when I calmly look back at the reality, ** It turns out that acting as if it were intelligent is not really a problem in limited circumstances ** In the chess example, it was found that it is possible to select the next move for each scene, but it is not possible to fight strategically considering the pattern of the opponent's move.
Although it was the expected artificial intelligence, the limit was felt and the first AI boom entered the winter era.
Second AI boom
In the second AI boom, giving "knowledge" to AI is the main era. If you give knowledge of illness, you can take the place of a doctor, and if you give knowledge of law, you can judge a crime! ?? Expectations increased for tasks that had limitations in search.
However, the reality is not sweet and some problems have emerged.
1. Difficulty in giving knowledge
The difficulty of giving knowledge is the difficulty of systematically evaluating knowledge. Words have a hierarchical relationship, and can be broadly divided into part of relationships and is-a problems. I won't write in detail For example, "wheels are a part of a bicycle", but "wheels" can be established without a bicycle, but "bicycles" cannot be established without wheels. Also, "a tree is a part of the forest", but unlike the example of a bicycle, the forest is a forest even if one tree disappears. It is very difficult to describe all such systematic evaluations of knowledge and give it to a computer, which is still a research in itself. (Ontology research)
2. Difficulty in giving knowledge
This is a problem caused by the inability to perform "processing that humans unconsciously perform" even if they are given knowledge. This is a "frame problem" that you can come up with forever without extracting only the necessary knowledge. There are two "symbol grounding problems" in which it is not possible to determine what a thing is by "feature + family name".
Faced with the difficulty of giving this knowledge, the AI boom has entered its second winter.
The emergence of machine learning
Artificial intelligence has been forgotten by the public because of its limits, but recently the third boom has come. The ignition agent was ** "The spread of computers and the enormous amount of data that accompanies them" **.
I think the image is easy, but in the last few years, IT such as personal computers, the Internet, smartphones, and various Internet services has exploded. This has made it easier to acquire a wide variety of data, and the field of ** data-based ** machine learning has grown rapidly. Among them, ** DeepLearning, which is included in machine learning, has also grown **.
Popularization of deep learning
Deep Learning utilizes neural networks, which have been studied for a long time. Deep Learning itself has a certain history since its predecessor, Perceptron, started in 1957, but the winter era was reached in the latter half of the 1990s due to the lack of useful mechanisms and the lack of elucidation of the brain in the first place. It has become popular recently.
The impact of deep learning
Deep Learning is a part of machine learning and is based on classification and regression, but its application destinations greatly contribute to modern technologies such as language processing, image recognition, and speech recognition. As a typical event ・ 2012 Professor Hinton of the University of Toronto wins overwhelmingly with a system using DL at a global artificial intelligence competition ・ 2016 Artificial Intelligence Go Program "AlphaGo" Wins Korean Professional Go Player And so on.
From such a local place, it began to attract attention and was used in business, and the neighborhood began to rise. And nowadays, it has spread to "education based on ML/DL and data science". I investigated what kind of background there was.
Fired by the advent of big data
Digitalization has created ** "a large amount of data" ** that was previously only available in some industries. Along with that, detailed data can be collected, and ** useful features can be secured **. It attracted attention because it is possible to expect results in a wide range of fields by digitizing all fields.
Improved computer performance
DL requires a large amount of calculation because it performs neural network operations (reproduction of the brain) with a large amount of data. Easy-to-understand examples include ** "supercomputers" ** and ** "quantum computers" **. The supercomputer is the pinnacle of conventional von Neumann computers. Currently, the calculation speed of Tomitake, which is the number one in the world, is ** 41K 5530 trillion times per second **. Furthermore, quantum computers enable operations in large units based on completely different principles.
Last fall, a research group led by Google announced that the world's fastest supercomputer at the time performed 10,000-year-old calculations on a quantum computer developed by the company in 3 minutes and 20 seconds. Of particular note is not only the calculation speed, but also the difference in the number of elements that make up the two. Only 53 quantum devices have surpassed supercomputers with more than 1K semiconductor devices at orders of magnitude faster. (Quote: Domestic supercomputer "Tomitake" ranked first in the world! Quantum computer is better than that?)
As the top performance has improved, the performance of general level machines has also improved dramatically. The power-ups of these machines have improved the future and the hurdles for training engineers. I think it is a prerequisite for the spread of DL.
① GPU Since DL performs a very large amount of operations, the CPU is often insufficient. Therefore, the calculation speed is increased by letting the GPU with a large number of cores perform parallel processing. In recent years, the development of GPUs has been tremendously thought to be for games, but it has contributed significantly to DL. GPU giant NVIDIA is in control, and algorithms are often optimized for NVIDIA's CUDA.
② TPU TPU is an integrated circuit developed by Google ** specially developed for machine learning **. Abbreviation for Tensor Processing Unit, which specializes in Tensor (multidimensional array). It is optimized for the machine learning library "TensorFlow" provided by the company. We took the top spot in the results of the machine learning benchmark "MLPerf v0.5" held in December 2018.
- Currently, NVIDIA's GPU A100 is the top NVIDIA sets 16 AI performance records in the latest MLPerf benchmark
③ intel FPGA FPGA is an integrated circuit that can be modified in hardware language on the spot. New engineer's blush blog "What is FPGA? Super Beginner "
Intel has developed a high-performance product for this. Intel's new FPGA "Agilex" realizes high flexibility (1/3) This enables high-speed data utilization computing.
④ IBM ASIC An ASIC is an integrated circuit customized to the user. It is developed in hardware like FPGA, but cannot be modified. It also requires development costs and development period. However, it is possible to achieve high performance and reduce component costs because the minimum configuration is tailored to the user. The mounting area can also be reduced.
IBM is leading the development of this ASIC IBM-derived 5nm ASIC, Marvell launches business
Reference: I understand this! !! Differences between Processors, FPGAs and ASICs
Inventing an excellent network
The number of researchers has increased as both the hard and psychological hurdles to tackle ML/DL have been improved. Thanks to that, inventions and improvements in the field will accelerate.
Existence and limits of perceptron
There was ** Perceptron ** as the whole body of DL. Let's dig into the simplest algorithm, Perceptron.
1st generation: Simple perceptron (1960 ~)
Linear combination of input values + non-linear transformation by activation function
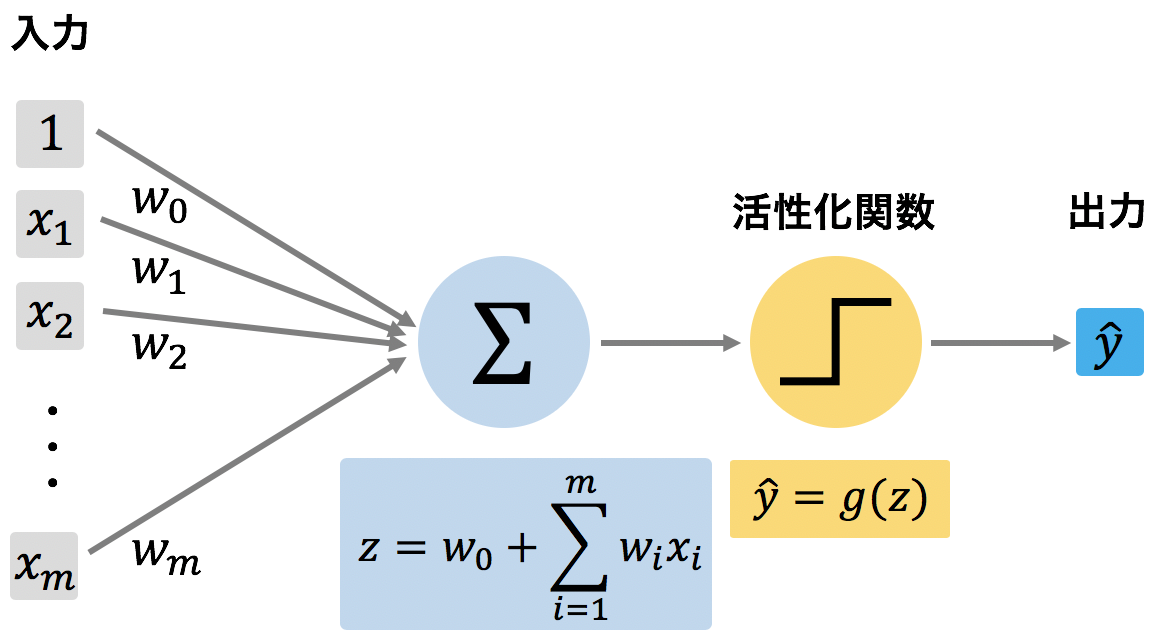 Source: Agricultural Information Science-Perceptron
Source: Agricultural Information Science-Perceptron
2nd generation: Multilayer perceptron (1980 ~)
A large number of simple perceptrons are combined hierarchically, and the sigmoid function is adopted as the activation function.
The parameters are updated by the backpropagation method.
Data that could not be linearly separated can now be separated by combining perceptrons.
However, in reality, there were problems such as slow back propagation and easy overfitting.
(Excessive adaptation to training data)
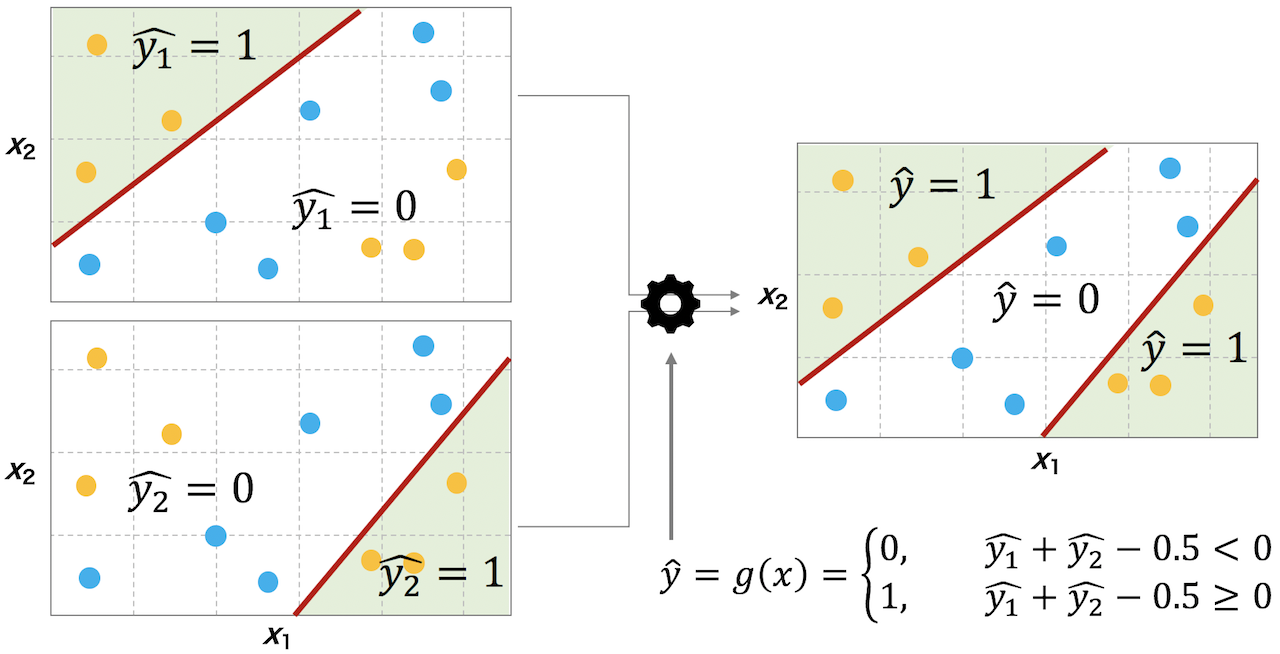
This is where mechanisms such as forward propagation, back propagation, error functions, and gradients come into play.
** Forward propagation (feedforward neural network) ** Calculate along the constructed network to obtain the predicted value. Input layer-> intermediate layer-> output layer-> probability
** Backpropagation ** When the error is obtained by forward propagation, the parameter is updated by the reverse transmission number based on the error function. (Error back propagation) As the name suggests, it propagates back to the output layer ← establishment.
** Error function (objective function) ** The index that evaluates the network is called the objective function, and among them, the error function (error between the predicted value and the true value) Is often used. ・ Cross entropy in classification ・ Mean square error in regression Use it properly according to the purpose.
** Gradient ** The slope of the point where the function is The slope is 0 = the minimum value of the function. Gradient method is used to find the minimum value of the error function
** Optimization algorithm ** The algorithm for optimizing the above-mentioned objective function (error function) (minimizing the gradient) It is an optimization algorithm. There are various variants, including the steepest effect method.
Neural network learning process problems
By increasing the number of layers of perceptron, it became clear that the shape of the boundary also approached from a straight line to a donut shape, and I saw light in the method of making it multi-layered, but there was another big problem. That is ** "local optimization" and "gradient disappearance" **. With conventional optimization methods, the gradient could not be reduced, and it sometimes converged to the local minimum value or overfitting occurred. In addition, there was a problem that the gradient disappearance (+ gradient explosion) caused the gradient to move toward the S-shaped end of the sigmoid function and the error stopped decreasing. Actually, it seems that these problems caused problems such as being unable to identify the past form of English.
In addition to still having network problems, we have entered a period of stagnation due to the wave of new statistical learning models such as ** SVM ** and ** Random Forest **.
3rd generation: Deep Learning
By devising a neural network with more layers than before (currently more than 20 layers) It has demonstrated its performance in various fields such as voice recognition, image recognition, and natural language processing.
A typical breakthrough is the case of winning over humans in image recognition and Go
Since then, DL has entered a stable period and has moved to the phase of improving accuracy and efficiency.
The power and benefits of large companies and universities
I touched on Google and NVIDIA in terms of machine performance, but those companies are broadly and deeply contributing to the DL world these days.
Provision of DL framework
There are many methods and parameters in ML/DL, and it is difficult to build them all programmatically. That's where the ** DL Framework ** comes into play. The framework contains a number of algorithms that can be easily used by simply calling a method. Take a typical example
- TensorFlow (Google)
- Chainer (PFN)
- Caffe (Yangqing Jia, UC Barkeley) --MXNet (University of Washington)
- PyTorch (Facebook)
- The Microsoft Cognitive Toolkit (CNTK) (Microsoft) --Theano (University of Montreal)
And so on.
Reference: Rough list of Qiita --Deep Learning frameworks
These tools are available for free in the DL area, and there are plenty of references. Researchers running on the front line are working hard as rivals, In addition, we are spending considerable effort to lower the hurdles for using technology. This also shows the momentum of the industry and its attitude toward development.
Improvement of various methods
In DL, some roles are divided in the procedure and it works by combining them. There is no perfect method. You need to choose the best method for your purpose. On top of that, algorithms have been devised and improved to minimize some issues.
Improvement of activation function
Mainly in the activation function that is the key to the output
- accuracy --Calculation speed -** Gradient disappearance / gradient explosion ** --Input values that you are not good at
And so on. There is no problem in recognizing that there is a trade-off between accuracy and calculation speed, Recently, simple and highly accurate functions such as ** ReLU function ** have appeared.
** Gradient disappearance ** is the stoppage of error fluctuation caused by the bias of the gradient. This was also resolved with the ReLU function. ** Gradient explosion ** is a problem in which the matrix product of the activation function is repeated and the gradient size increases by stacking layers. This is solved by adding an operation called ** clipping ** and adding an upper limit to the gradient.
Improvement of objective function
We will deal with the loss function here. There are also different types of loss functions for evaluating predicted values, each with its own characteristics. What you have to consider --Effect of outliers --Calculation speed --Is it appropriate?
And so on. A typical method is --Mean Squared Error --Most major. Easy to understand, but vulnerable to outliers. --Mean Absolute Error --Strong against outliers. --Mean Squared Logarithmic Error --The predicted value tends to exceed the actual value. --Cross entropy error --For classification problems.
And so on. Since the framework is different for regression and classification, it is necessary to make a selection for each task and its nature.
Reference: I tried to sort out the types of loss functions that are often used in machine learning Loss function to be suppressed by machine learning (classification)
Improvement of optimization method
There are also types of optimizers used to minimize the objective function. --Accuracy (local solution) --Convergent speed
- Stability
And so on.
The following figure is easy to understand the difficulty of optimization
 Citation: Benchmark function summary to evaluate optimization algorithm
Citation: Benchmark function summary to evaluate optimization algorithm
For details, Introduction to Optimization
Reference: [2020 definitive edition] Super easy-to-understand optimization algorithm
Suppression of overfitting: Weight Decay
To prevent ** overfitting ** where the network overfits teacher data An operation called ** Weight Decay ** has also been devised. Also called regularization. Strictly speaking, it works with the objective function. The combination of optimization and weight attenuation prevents overfitting.
Reference: [DL] What is weight decay?
Suppression of overfitting: Dropout
DL is proportional to model complexity and overfitting. Therefore, the simple model has higher generalization performance. ** Dropout ** was devised based on this principle. It disables some nodes and forcibly reduces the degree of freedom of the model to prevent overfitting.
Suppression of overfitting: Batch Normalization
This is a method to prevent gradient disappearance and explosion. Unlike traditional objective functions, optimizations, weight attenuation, and Dropout The purpose is to stabilize the entire network.
By stabilizing the entire network --Speed up learning --Escape from the dependence of the initial value --Overfitting suppression
Etc. can be expected.
These methods are being devised and improved at high speed.
Types of neural networks
There are also types of NN (neural networks), which are also being researched for devising and improving. There is a model specialized for each task. It can be said that the development of specialized algorithms has led to adaptation to a wide range of fields, leading to the spread of DL.
CNN (Convolutional Neural Network)
In NN, there is a ** fully connected layer ** where the nodes of each layer are tightly connected, In addition to these, CNN processes features by filtering ** convolutional layer, pooling layer **.
It is mainly used for analysis of image data and discontinuous data.
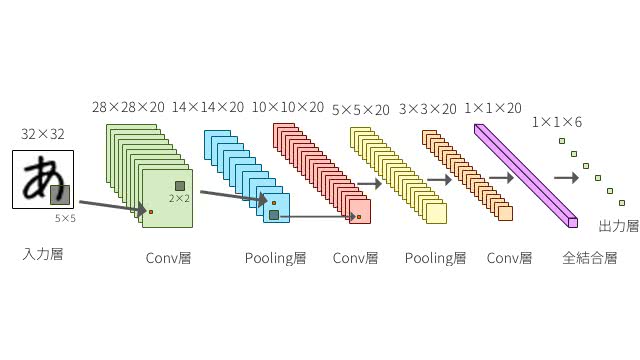 Source: DeepAge-Understanding the classic Convolutional Neural Network from scratch
Source: DeepAge-Understanding the classic Convolutional Neural Network from scratch
RNN (Recurrent Neural Network)
RNN is a network that specializes in time series data. Make better predictions by using other data points of continuous data.

Source: AISIA --Recurrent Neural Network_RNN (Vol.17)
Other
In addition to the above two typical networks --LSTM: Specializes in long-term time series data. Active in natural language processing --BERT: A recently introduced bidirectional Transformer. Record breaking in many benchmarks. --GAN: The latest generative model. It consists of two NNs.
There are various networks such as, and a considerable number of networks including derivative forms have been proposed.
High spirit
Different datasets have different algorithms for the same task. In the ML/DL world, research is often conducted with the goal of ** SOTA ** (state-of-the-art: latest technology). Algorithms are ranked using benchmarks for each task as indicators.
A number of datasets are available just for natural language processing text classification You can see that there is no absolute algorithm and that there are many types of algorithms.
Reference: Browse SoTA > Natural Language Processing > Text Classification
Data analysis competitions are also held frequently, and New methods that have just been published are often tested and talked about in competitions. Example: XGBoost (a method that allows algorithms called the ensemble method to make a majority vote)
Reference: List of "Data Analysis Competitions" that can be participated from Japan [World Version Summary]
Summary
To summarize the flow of DL spread

I recognize that it is like that.