[PYTHON] Character dialogue generation and tone conversion by CVAE
1. 1. Overview
Good evening. This time, as the title suggests, I tried to generate the character's dialogue with CVAE (Conditional Variational Auto-encoder). Using the same method, I am also trying to change the tone of the character.
- 170624: There was a problem with the code on github, so I fixed it.
2. Related articles (existing research)
There are many articles that generate dialogue in RNN system. [Evangelion] Try to automatically generate Asuka-like lines with Deep Learning
These articles had the following challenges:
- There is little learning data for the character (1000 sentences at most. Moreover, if you mix the lines of other characters with the learning data, it will not work).
- Since only the lines already spoken by the character are used for the learning data, the character will not utter words that do not appear in the lines.
I would like to solve these problems with CVAE. Since CVAE can learn the characteristics of each category (character in this case), it is possible to improve the accuracy of dialogue generation for each character even if the dialogue of different characters is added to the learning data.
3. 3. model
Following the article I wrote last time, "Make character settings with VAE.", I also use LST MVAE as a model. The LSTM, VAE, and Encoder-Decoder models will not be discussed in depth here, so if you are not familiar with them, please refer to the following articles.
- Overview of LSTM network
- Auto-Encoding Variational Bayes [arXiv:1312.6114]
- Chainer, RNN and machine translation
VAE is a model that turned Deep NeuralNet into a generative model, but there was a problem that it was not possible to control what kind of data was generated. CVAE has solved this problem.
CVAE is a model that combines VAE with a category vector (a vector that expresses a category, which is also a parameter).
As an application example of VAE, MNIST (Numeric Character Recognition) image generation is introduced in the paper.

In normal VAE, numbers are randomly generated, but in CVAE, you can specify numbers from 0 to 9 to generate.
By using the same method, I verified whether it was possible to specify a character and generate a line.
The configuration of the CVAE model is basically the same as the LST MVAE in Previously written article.
Just add the category vector to the initial values of the encoder and decoder hidden layers.
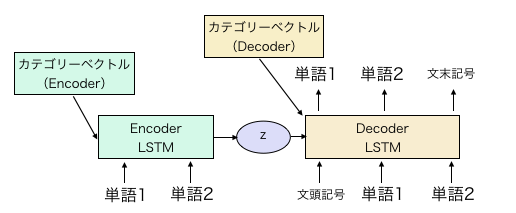
A simple illustration shows the model shown above. The category vector in the above figure is a parameter to be changed and learned for each character. At the time of learning, it is put in both Encoder and Decoder, but at the time of generation, the dialogue of the faced character can be generated by combining the distribution of the intermediate representation z and the category vector of Decoder.
The encoder is Bidirectional LSTM and the dimension of each hidden layer is 300. The dimension of the middle layer z is 600. The hidden layer dimension of the decoder is set to 600. The word vector is 300 for both encoder and decoder. Morphological analysis is performed by sentence piece, and the number of words is about 16000.
Later, I wasn't confident about the following, but the category vector is made for both the h and c hidden layers of the LSTM. Since the encoder is Bidirectional, there are a total of 6 types of category vectors in 2x3. The dimension is the same as the dimension of the hidden layer (300 for encoder, 600 for decoder) The code is as usual https://github.com/ashwatthaman/LSTMVAE It is placed in. src/each_case/sampleCVAESerif.py The code for executing Conditional VAE is written in. However, this time the data cannot be released from a copyright point of view, so Only dummy data is placed.
4. data
This was crawled from the following sites.
- What you should love-Introduction of anime lines-
- Anime Transcripts @ Anime in English A total of 218 characters and about 120,000 sentences are being learned. In the above 120,000 sentences, only the lines of characters with 100 or more lines are used.
5. result
5.1. Sentence generation for each character
The result. Rei Ayanami's line was the one I said best (I think), so I'll post it here.
It's a lie. I'm the only one.
Ah, I should protect the first machine
I think I was looking for me.
Ikari failed very much.
Alive
I don't know. I make the first machine sortie.
It has a face called Rei Ayanami.
...House. Then...Only for you
I'm coming with a bad feeling?
No. I really can't move.
What do you say However, there is no favor. I don't know what I did.
Thank you thank you. I'm in the door of the day
You're done with what's called Rei Ayanami.
Shut up and beat someone.
Yes. This object is grateful to one and intends to do so.
It's scary to take care of that, as time goes by.?
Because this is the situation. Everyone was worried.
Congrats!
Why are you alive?
So I ran away from your dad
No, I'm me. I lived my life!
No, don't run away!
It's subjective, but it seems that more like sentences are generated than just using RNN. "Lie. I'm the only one." </ B> "So I ran away from your dad" </ b> I'd like you to say something like Rahen or Ayanami, but it's okay to have a line that isn't said.
Next is Misato.
It's okay to sortie out for recovery?
I'm sorry
Anyway, cut to Nerv's backup power supply!
But I want to be happy.
From the report from the headquarters, I will finish it a little early in the morning
Follow Shinji's orders.
I'm sorry, I have it. Then I have to go early
I'll open it, Japan.
Such an unreasonable wish
...Asuka, a spare fortress
A guy who can't make jokes as usual.
Is it on your mother's wound??
The committee cuts off the standby power supply. And turn the first machine
Kamochi-kun, I'll bomb you?
Stupid...
You have an idea?
Scary!What kind of face did you have while listening to loneliness??
I have a face like you. You're a father
Apostle?
That, Asuka, Ray?Unit 0 is?
I hate it!
...Eva pilot has an emergency signal...Wow
And, no, no, no, I'm not wearing this...
so.
What was that!?
That the Dara Saschi of letting you hit...
Good!
change?
First, second, second qualification, what rescue.
Aska
I hate it, I know that!
I know!He made it for me, so lend me my mom's lunch box.
Mom?
He brought me a bath with Mr. Kamochi?
Annoying!
...It's okay, I really hate it!
Hate...
Wait a minute here!
Mama, idiot
Okay, Sheggy Ete Yoi!
Stupid!あんたなんかStupidにすんのよ!
that?
I'm going, I'm going.
That way, I'm an adult right now.
I hate it!Stupid!
...That idiot...
I'm waiting here for a moment. Please go!Mr. Kamochi!
First, I'm in the first phase
Even if I hate it, he made it for me, and it's not another one.
Replaced, back up the second machine, yourself.
Don't tell people's stories
What is this?
Evangelion No. 2 and No. 2!
It's a strange child.
Hah...
I know.
...Mr. Kamochi is noisy...
Don't call you either!
The sync rate is the fourth in about two weeks.
What a lie, that
I hate it, first.
Take this for the time being!
You've been riding for a long time even though you haven't woken up yet
Wait a minute here!
You stupid?First chilled first!
What, the mouth is from each mouth, get along well!
Okay, Shejoie Teyoi! </ B> Sudden Pop Team Epic.
The lines of other characters https://github.com/ashwatthaman/LSTMVAE/tree/master/src/each_case/serif/test28_Public.txt It is in. There are Gundam, Code Geass, Haruhi, Lucky Star, Nichijou, Squid Girl and so on. It seems that the generation accuracy is quite different depending on the character.
5.2. Tone conversion
Next, try to change the tone. As for what to do, I mentioned earlier that CVAE adds category vectors to both encoders and decoders. Normally, the same category vector is inserted in the encoder and decoder, but is it possible to convert the dialogue of the encoder character into another character style by inserting different vectors? I tried that.
Nao Tomori's dialogue "Please see everyone" </ b> Will be converted to a squid girl.
Then ...
"Everyone, do it!" </ B>
Was output. I'm sorry ... It would have been perfect if I had seen it instead of doing it.
Next, Asuka's dialogue "Halo ~ Misato! How are you?" </ B> Is converted to Shinji style.
"As Misato says. Let's contact Rei Ayanami." </ B>
have become. Well, it's subtle.
Another one Char's dialogue "Guney has stopped the enemy's nuclear missiles. That's the job of a boosted man." </ B> To ques.
"I'll forgive you for telling me that Guney stopped the enemy's nuclear missiles." </ B> Now this. I feel that this can be converted relatively.
But relatively like this? There is no one in ten that worked. In most cases, it was converted into words with completely different meanings. It seems that a little more ingenuity is needed to convert the tone with AutoEncoder.
6. Consideration or impression
6.1. Dialogue generation
First, I raised two challenges with existing methods.
- You cannot learn well due to lack of learning data.
- If you learn only with one character's dialogue, do not say words that the character has not said before. It is two points.
We have not quantitatively evaluated 1., but I think it was confirmed that the quality of the sentences can be improved by including the lines of other characters in the learning data. Compared to existing methods, the percentage of grammatically broken sentences is low. What's more, it doesn't just say what is in the original line.
About 2. In the example above, Ray says "door" and Misato says "fortress". Since these words do not appear in the original dialogue sentence, it can be said that they have succeeded in issuing new words. However, the ratio is lower than expected.
6.2. Tone conversion
By changing the category vector with encoder and decoder, we showed the possibility of changing the tone and style. (Although it is not yet at a practical level)
The results of word addition and subtraction in word2vec and image addition and subtraction (removing and putting on glasses) in GAN are known, but it seems that there is no research to change the meaning and style by adding and subtracting sentences. I will. Of course, you can change the writing style by using the encoder-decoder model, but it is not realistic from the viewpoint that you have to collect a large amount of corresponding sentences.
The accuracy of conversion using CVAE may be improved to some extent by increasing the training data, but it is unknown at this point how far it can be achieved. There is a little more room for research.
7. Future issues
- If you really want to verify whether you can convert the tone and style, it seems better to use data with more sentences in each category.
- Even if there are 120,000 sentences, grammatically incorrect sentences may be generated. I think this can be solved by increasing the learning data.
- This time, instead of MeCab, Sentencepiece is used for morpheme division, so if the conditions are met, MeCab should be used for comparison. However, I don't think it will change so much depending on how the morpheme is divided, so I think CVAE is working.
- I found it difficult to get the character to say a word that was not spoken in the learning data. Well, do you need something prior distributed?
8. Reference site (Thank you for your help)
article
- [Evangelion] Try to automatically generate Asuka-like lines with Deep Learning
- Make character settings with VAE.
- Overview of LSTM Network
- Auto-Encoding Variational Bayes [arXiv:1312.6114]
- Chainer, RNN and Machine Translation
paper
Training data