[PYTHON] Difference in morphological analysis results by mecab dictionary
About this article
--Sentence made to explain mecab somewhere --Basically describe the difference between mecab and mecab-ipadic-NEologd ――When you salvage.
What is morphological analysis?
Morphological analysis is one of the natural language processing methods that are also used in search engines. It decomposes a sentence / phrase into "minimum units (= words) that have meaning". It is used to judge the content of sentences and phrases.
Reference site
About mecab
Overview
MeCab is an open source morphological analysis engine developed through the joint research unit project of the Graduate School of Informatics, Kyoto University-Nippon Telegraph and Telephone Corporation, Research Institute for Communication Science. The basic policy is a general-purpose design that does not depend on language, dictionary, or corpus. Conditional Random Fields (CRF) is used for parameter estimation. It also runs faster than ChaSen, Juman, and KAKASI on average. By the way, Wakame seaweed is a favorite of the author.
Feature
-Dictionary, corpus independent general purpose design -High analysis accuracy based on conditional random field (CRF) -Faster than ChaSen and KAKASI -Adopts Double-Array, which is a high-speed TRIE structure, for the dictionary lookup algorithm / data structure. -Reentrant library -Various scripting language bindings (perl / ruby / python / java / C #)
Comparison
| mecab | chasen | juman | kakasi | |
|---|---|---|---|---|
| Analysis model | bi-gram Markov model | Variable length Markov model | bi-gram Markov model | Longest match |
| Learning model | CRF (Discriminative model) | HMM (Generative model) | ||
| Dictionary lookup algorithm | Double Array | Double Array | Patricia tree | Hash? |
| Solution search algorithm | Viterbi | Viterbi | Viterbi | Definitive? |
| Implementation of articulated table | 2D Table | automaton | 2D Table? | No articulation table? |
| Part of speech hierarchy | Unlimited multi-layer part of speech | Unlimited multi-layer part of speech | 2-step fixed | No concept of part of speech? |
| Unknown word processing | Character type(Action definition can be changed) | Character type(Unchangeable) | Character type(Unchangeable) | |
| Constraint analysis | Possible | 2.4.0でPossible | 不Possible | 不Possible |
| N-best solution | Possible | 不Possible | 不Possible | 不Possible |
Dictionary data
--IPA dictionary
IPA dictionary, a dictionary whose parameters are estimated by CRF based on the IPA corpus.
--Juman dictionary
Juamn dictionary, a dictionary whose parameters are estimated by CRF based on the Kyoto corpus.
--Unidic dictionary
Unidic dictionary, BCCWJ A dictionary estimated by CRF based on the corpus.
--mecab-ipadic-NEologd dictionary
mecab-ipadic-NEologd is a system dictionary for MeCab customized by adding new words obtained from many language resources on the Web.
--Advantages
--Approximately 3.12 million pairs (including duplicate entries) of word surface (notation) and frigana pairs of words such as named entities that cannot be correctly divided by MeCab's standard system dictionary are recorded.
--This dictionary is updated automatically on the development server, and will be updated at least twice a week.
--Because it utilizes language resources on the Web, new named entities can be recorded at the time of update. The resources currently used are as follows.
--Dump data of Hatena keyword
--Postal code data download
--A corner of the list of station names nationwide
--Personal name (last name / first name) entry data
--Data that is an entry of adverbs that are not recorded in the IPA dictionary
--Data that is an entry of adjectives that are not recorded in the IPA dictionary
--Data that is an entry of adjective verbs that are not recorded in the IPA dictionary
--Data that is an entry of an interjection entry that is not recorded in the IPA dictionary
--Data that is an entry of a list of notational fluctuation character strings of general nouns / proper nouns and their prototype pairs.
--Data that is an entry of a list of notational fluctuation character strings and their prototype sets
--Data that is an entry of words that have the same pattern as the collapsed notation words that tend to appear on SNS.
--Data with hand-reading kana added to pictograms under Unicode 9.0
--Data with hand-reading kana added to emoticons that can be entered on the initial iOS device or Android device
--A list of Japanese mountain names
--Patch to fix obvious errors (typographical errors, omissions, etc.) related to the reading kana of entries contained in the IPA dictionary
--Patch to fix morpheme occurrence cost of entries in IPA dictionary
--Data created as entries by generating time expressions and numerical expressions using predefined patterns
--Data that is an entry of new words and unknown words extracted from news articles
--Data containing entries of popular words, idioms, and hashtags on the Internet
--Large amount of document data crawled from the Web
- Disadvantage --Insufficient classification of named entities --Words that are not named entities are also registered as named entities. --The association between named entity notation and frigana may be incorrect. --All the part of speech information of the added adverb is'adverb, general ,,,,' --The only supported character code is UTF-8.
neologd
$ echo "Instagram" | mecab -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd/
Instagram noun,Proper noun,General,*,*,*,Instagram,Insta fly,Insta fly
EOS
$ echo "Instagram" | mecab
Instagram noun,General,*,*,*,*,*
Shine noun,General,*,*,*,*,Shine,Flies,Flies
EOS
$ echo "Seriously" | mecab -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd/
Serious noun,Proper noun,General,*,*,*,Seriously,Seriously,Seriously
EOS
$ echo "Seriously" | mecab
Serious noun,Adjectival noun stem,*,*,*,*,seriously,Really,Really
Swastika noun,General,*,*,*,*,Swastika,Manji,Manji
EOS
$ echo "Tapiru" | mecab -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd/
Tapi noun,Proper noun,General,*,*,*,Tapi,Tapi,Tapi
Auxiliary verb,*,*,*,Literary language,Word connection,Ri,Le,Le
EOS
$ echo "Tapiru" | mecab
Tapi noun,General,*,*,*,*,*
Auxiliary verb,*,*,*,Literary language,Uninflected word,Ru,Le,Le
EOS
$ echo "Agemizawa" | mecab -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd/
Agemizawa noun,Proper noun,General,*,*,*,Agemizawa,Agemizawa,Agemizawa
EOS
$ echo "Agemizawa" | mecab
Raise verb,Independence,*,*,One step,Continuous form,Give,Age,Age
Only verb,Non-independent,*,*,One step,Continuous form,View,Mi,Mi
Zawa noun,Proper noun,Organization,*,*,*,*
EOS
$ echo "Bruise fisheries" | mecab -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd/
Bruise fishery noun,Proper noun,General,*,*,*,Bruise fisheries,Azamaru Suisan,Azamaru Suisan
EOS
$ echo "Bruise fisheries" | mecab
Bruise noun,General,*,*,*,*,Bruise,Bruise,Bruise
Maru prefix,Several connections,*,*,*,*,Maru,Maru,Maru
Fisheries noun,General,*,*,*,*,Fisheries,Suisan,Suisan
EOS
$ echo "Instagram" | mecab -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd/
Instagram noun,Proper noun,General,*,*,*,Instagram,Instagram,Instagram
EOS
$ echo "Instagram" | mecab
Instagram noun,Proper noun,Organization,*,*,*,*
EOS
$ echo "Kemio" | mecab
Particles,Final particle,*,*,*,*,Ke,Ke,Ke
Only verb,Independence,*,*,One step,Continuous form,View,Mi,Mi
Verb,Non-independent,*,*,Five steps, La line,Word connection special 2,Oru,Oh,Oh
EOS
$ echo "Kemio" | mecab -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd/
Kemio noun,Proper noun,Personal name,General,*,*,Kemio,Kemio,Kemio
EOS
How to use in code (UNIX & python3)
mecab.py
import MeCab
t = MeCab.Tagger ('-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')#mecab-ipadic-NEologd
t = MeCab.Tagger ("-Ochasen")#Standard guy
text = 'Text you want to parse'
t.parse('')#Prevent strings from being GC
m = t.parseToNode(text)
while m:
if m.feature.split(',')[0] == 'noun':
print(m.surface)
result
AWS noun,Proper noun,General,*,*,*,AWS,Amazon web services,Amazon web services
Famous noun,Adjectival noun stem,*,*,*,*,Famous,Yuumei,Yumei
Service noun,Change connection,*,*,*,*,service,service,service
Amazon noun,Proper noun,General,*,*,*,Amazon,Amazon,Amazon
Elastic noun,Proper noun,General,*,*,*,Elastic,Elastic,Elastic
Compute noun,General,*,*,*,*,*
Cloud noun,General,*,*,*,*,*
the term
--Conditional Random Fields
It is one of the probabilistic graphical models represented by undirected graphs and is a discriminative model. Series labeling aims to take a data string (eg a word string) as input and label individual data as output. For example, there is a problem of giving part of speech information to a word string (input: "I / ha / run" ⇒ output: "noun / particle / verb"). Is done.
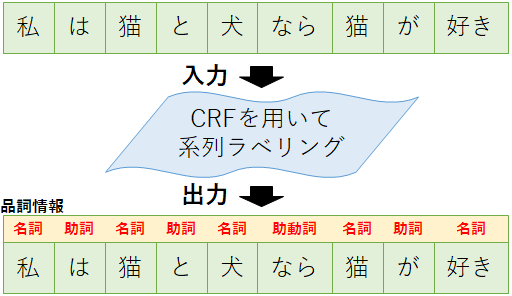
The CRF for solving sequence labeling is called the Linear-chain CRF.
Reference site: [Technical explanation] CRF (Conditional Random Fields)
Recommended Posts