[PYTHON] [Translation] Spark Memory Management since 1.6.0
Translated the article here.
With the start of development of Apache Spark 1.6.0, the memory management model has changed. The old memory management model was the StaticMemoryManger class. Now it's called "legacy". "Legacy" mode is off by default. This will give different results if you run the same code on 1.5.x and 1.6.0. Please be careful about this. You can enable the spark.memory.useLegacyMode parameter for compatibility. This is off by default.
About a year ago, I wrote about memory management for the "legacy" model in an article called Spark Architecture. I also briefly wrote about memory management for the Spark Shuffle implementation.
This article is a new memory management model in ʻUnifiedMemoryManager` used in Apache Spark 1.6.0 This section explains.
To summarize briefly, the new memory management model looks like this.
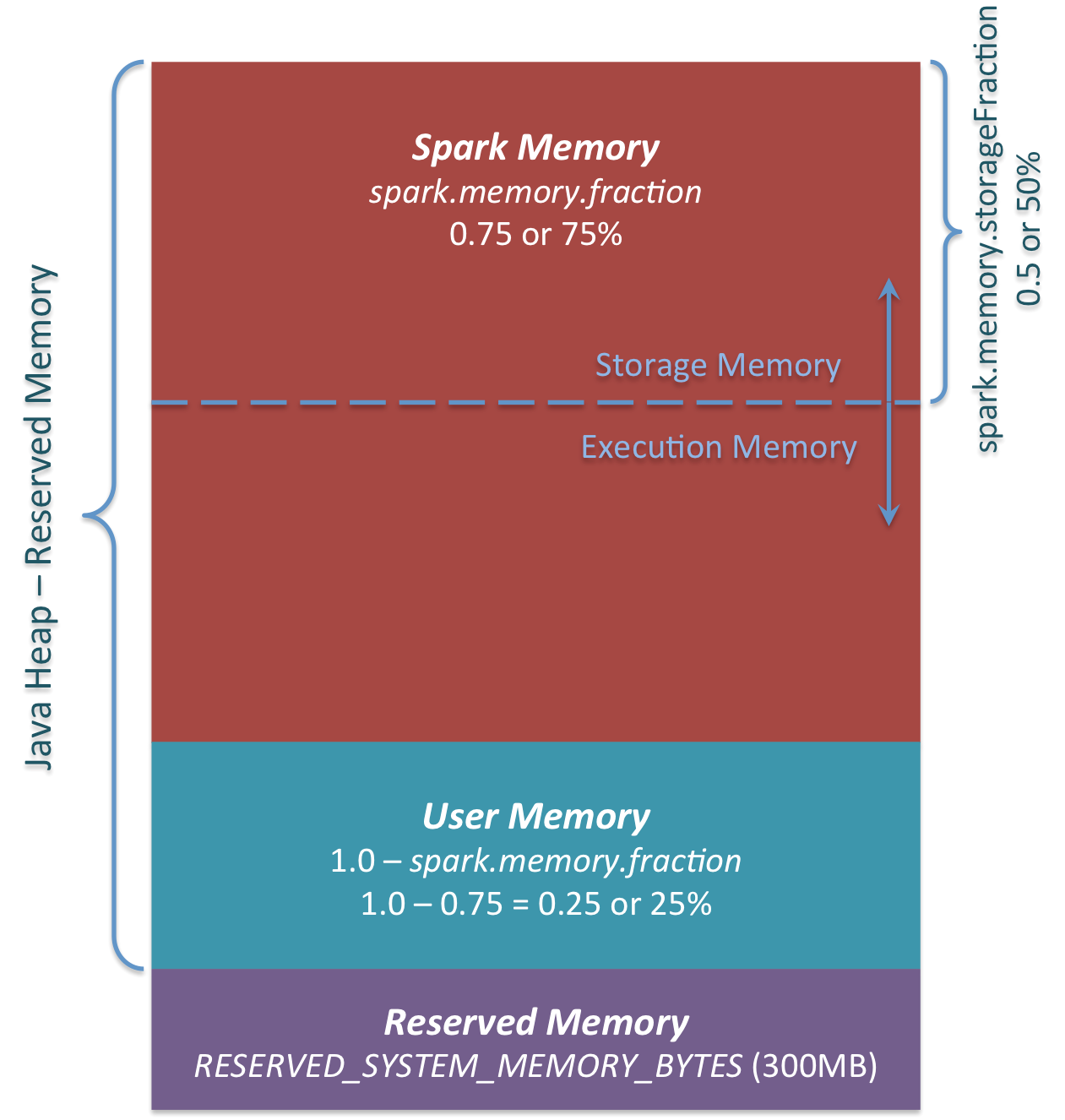
The three main memory areas can be seen in the figure.
Reserved Memory
Memory reserved by the system. This size is hard coded. In Spark 1.6.0 this value is 300MB. 300MB of RAM is not used for Spark calculations. This value cannot be changed without recompiling Spark or changing spark.testing.reservedMemory. This value is for testing purposes and it is not recommended to change it in production. This memory is called "reserved" and is never used by Spark. This value can set an upper limit on how much memory can be used by Spark usage information. Even if you want to use all Java Heaps for Spark's cache, this "reserved" area will not be used. (It's not really a spare. It's a place to store Spark's internal objects.) If you don't give the Spark executor a heap of at least 1.5 * Reserved Memory = 450MB, you'll get the error message "please use larger heap size". I will.
User Memeory This memory pool remains in memory even after Spark's memory is allocated. It is up to the user how to use this memory. You can save the data structure used in the transformation of RDD. For example, you can rewrite the operator of Spark's mapPartitions variant, which may have a Hash table and use UserMemory for aggregation. In Spark 1.6.0, the size of the memory pool is calculated as follows: "Java Heap"-"Reserved Memory" * (1.0 --spark.memory.fraction) By default, it is equivalent to: ("Java Heap"-300MB) * 0.25 As an example, a 4GB Heap can have 949MB of UserMemory. Again, it's up to the user what data to store for this UserMemory. Spark has nothing to do with what the user does and whether it crosses memory area boundaries. If you ignore this memory area, you may get an OOM error.
Spark Memory
This is a memory pool managed by Apache Spark. This size is calculated as follows: ("Java Heap"-"Reserved Memory") * spark.memory.fraction. In Spark 1.6.0, it is ("Java Heap"-300MB) * 0.75. For example, with a 4GB Heap, Spark Memory would be 2847MB. This memory pool is allocated to two areas. Storage Memory and Execution memory. This boundary can be changed with the spark.memory.storageFraction parameter. The default is 0.5. The advantage of this new memory area is that this boundary is not static. And if memory pressure occurs, the boundaries change. For example, one area can borrow space from the other to increase its size. Well, we'll talk about how this memory boundary changes later. Let's first discuss how this memory is used.
Storage Memory
This memory pool is used as a temporary space to "unroll" Spark cached data and serialized data. The "broadcast" data is also saved as a cache block. If you are interested in "unroll", take a look at this unroll code. As you can see, unroll does not need enough memory for the unrolled block. If there is not enough memory for the unrolled partition and the persistence level allows the drive to do data, then the data will be placed directly on the drive. For "broadcast", all broadcast data is cached according to the MEMORY_AND_DISK persistence level.
Execution Memory
This memory pool stores objects needed while performing Spark tasks. For example, it is used to store an intermediate state buffer for shuffles on the Map side, or to store a hash table used for hash aggregation. This memory pool will write data to disk if there is not enough memory. However, you cannot exclude blocks from this memory pool from other threads (tasks).
Now let's discuss how the boundary between Storage Memory and Execution Memory works. It is not possible to force a block from the memory pool as a characteristic of Execution Memory. Because these are used for intermediate computations, processes that require this memory will fail without this block of memory. This does not apply to Storage Memory (a simple cache in RAM). If you want to remove the block from the memory pool, you can update the block's metadata as if the block had been evacuated (or simply deleted) to the HDD. Spark will recalculate if it tries to read this block from the HDD or if the persistent level does not allow writing to the HDD.
You can force the block out of Storge Memory. On the other hand, Execution Memory cannot be used. When does Execution Memory write memory from Storage Memory? It happens in the following cases.
--If there is too much memory in Storage Memory. For example, if the cached block is not using all the memory. In this case, reduce the Storage Memory pool size and increase the Execution Memory pool.
--When the Storage Memory pool size exceeds the initial Storage Memory area size and all area is used. In this case, blocks in memory are forced out of the Storage Memory pool (written to drive) when the initial size is not reached.
Second, the Storage Memory pool can borrow space from Exection Memory if there is too much in the Execution Memory pool.
The size of the initial Strage Memory area is calculated as follows: “Spark Memory” * spark.memory.storageFraction = (“Java Heap” – “Reserved Memory”) * spark.memory.fraction * spark.memory.storageFraction. By default, it is equivalent to: (“Java Heap” – 300MB) * 0.75 * 0.5 = (“Java Heap” – 300MB) * 0.375. For example, a 4GB Heap uses 1423.5MB of RAM as the initial Storage Memory.
This means that if the sum of the amount of data in the Spark cache and the cache on the executor is the same as the initial Storage Memory size, then at least the size of the Storage area is the same as the initial data size. This is because it is not possible to move data out of memory while reducing its size. However, if the Execution Memory area exceeds the initial size before the Storage Memory is exhausted, you cannot force the Execution Memory to leave the entry. Finally, while the Execution Memory holds the memory, the processing is performed with the small Storage Memory Size (because the memory is dedicated to the Execution Memory).