[PYTHON] Pepper Tutorial (7): Image Recognition
Contents of this tutorial
In this tutorial, we will explain the specifications and behavior of image recognition by Pepper through samples.
- Image-related specifications
- How to check the image with Choregraphe
- Basic facial treatment
- Face learning and discrimination
- Image learning and discrimination
** For image recognition, there is no operation confirmation method for virtual robots, and an actual Pepper machine is required. ** I would like you to experiment with the actual Pepper machine at Aldebaran Atelier Akihabara. (Reservation URL: http://pepper.doorkeeper.jp/events)
Various sensor specifications
The specifications related to Pepper's image processing are as follows.
- 2D camera x 2 (forehead ** [A] **, mouth ** [B] **) ... Output 1920 x 1080, 15fps
- 3D camera (infrared irradiation: ** [C] **, infrared detection: ** [D] **) ... ASUS Xtion 3D sensor, output 320 × 240, 20fps

Pepper uses these cameras to recognize people and objects.
How to check images with Choregraphe
You can check the information of the image taken by Pepper's camera in Choregraphe.
Confirmation by video monitor panel
Use the video monitor panel for operations related to Pepper images. The Video Monitor panel is usually located in the same area as the Pause Library and can be viewed by selecting the Video Monitor tab. If you cannot find it, select [Video Monitor] from the [View] menu.

The video monitor panel provides the ability to view images from Pepper's camera, as well as manage the visual recognition database described below.
- Camera image ... You can check the contents of Pepper's camera
- Play / Pause button ... Play back to see the current camera image in real time. You can stop this with a pause
- Learning mode button ... Switch to image learning mode. How to use it will be explained in the image learning tutorial.
- Import button ... Import the visual recognition database from a local file into Choregraphe
- Export button ... Export the visual recognition database from Choregraphe to a local file
- Erase button ... Erase the current visual recognition database
- Submit button ... Submits the visual recognition database held in the current Choregraphe to Pepper
Confirmation by Monitor
You can also use the Monitor application that is installed with Choregraphe. Start the Monitor application as follows.
-
Launch the ** Monitor ** application that is installed with Choregraphe.
-
Click ** Camera ** in the Monitor application launch menu
-
A dialog will open asking you to connect to Pepper, so select the Pepper you are using.

-
The Monitor window will open. Click the ** Play button **.

-
You can check the image taken by Pepper's camera
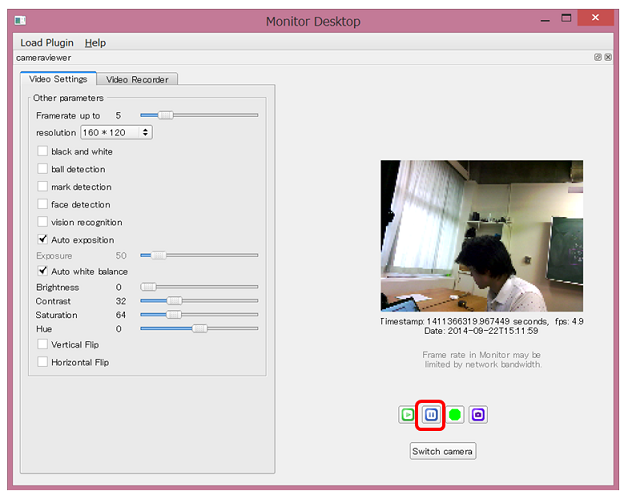 You can stop playback with the ** Pause button **
You can stop playback with the ** Pause button ** -
In addition to images, you can check information related to image recognition. By checking ** face detection [A] **, you can check the status of ** face recognition in Pepper [B] **.

-
If you want to check the contents of the 3D camera, ** Select [3d sensor monitor] from the [Load Plugin] menu **

-
You can check the depth map by clicking the ** play button ** in the same way as a 2D camera.
 You can stop playback with the ** Pause button **
You can stop playback with the ** Pause button **
With this Monitor application, you can check the contents of the image recognized by Pepper in detail.
Basic face recognition
Face recognition
By using the Face Detection box provided as a standard box, you can get the number of faces currently recognized by Pepper. Here, I'll try to combine the Say Text boxes I've used several times to make ** talk the number of faces that Pepper recognizes **.
Try to make
- Preparation of the box to use
- standard box library
- Vision> Face Detection ... Performs face detection and outputs the number of detected faces.
- advanced box library ... Select the advanced tab of the box library
- Audio> Voice> Say Text ... Speak the entered string
- Connect the boxes

By connecting numberOfFaces (orange, type: number) in the Face Detection box and onStart (blue, type: string) in the Say Text box, you can make Pepper speak the value of numberOfFaces output by the Face Detection box. I will.

The application is now complete. When a face is recognized, the Face Detection box outputs numberOfFaces, and Pepper speaks in response to this output.
Operation check
Connect to Pepper and try playing. When you show your face to Pepper, Pepper talks about the number of faces in sight, like "Ichi" and "Ni".
In Robot View, you can also know the position of the face recognized by Pepper.

For example, as shown above, when Pepper recognizes a face, a face mark will appear in the robot view. This shows the position of the face that Pepper is aware of.
(Supplement) Customization of Say Text box
This sample is as simple as saying numbers such as "ichi" and "ni". It's enough to see the movement of the Face Detection box, but it's an application that's hard to tell what you're doing.
Here, as an example, if the number of detected faces is 1, let's change it so that it says "There is one person in front of me" **.
The Say Text box is a Python box that uses the talking API ** ALTextToSpeech API **. If you can manipulate the string passed from the Say Text box to ALTextToSpeech, you can change what you say.
This time, I will try to operate the character string in the Say Text box. Double-clicking on the Say Text box will open the Python code, looking for the ʻonInput_onStart (self, p) `function in this code. You can see that there is a line like this:
sentence = "\RSPD="+ str( self.getParameter("Speed (%)") ) + "\ "
sentence += "\VCT="+ str( self.getParameter("Voice shaping (%)") ) + "\ "
sentence += str(p)
sentence += "\RST\ "
id = self.tts.post.say(str(sentence))
self.ids.append(id)
self.tts.wait(id, 0)
p contains the value entered in the Say Text box and constructs the string to give to the ALTextToSpeech API at sentence + = str (p).
Therefore, if you change this part to sentence + =" there is a person in front of me "+ str (p) +" there are people " etc., instead of "one", "there is one person before me" "(" One person "speaks" one person ").
Face tracking
Similar to voice allows Pepper to track the direction of the face. In the audio example, we were moving only the angle of the neck, but here we will use the Face Tracker box to ** move in the direction of the face **.
Try to make
- Preparation of boxes to use (standard box library)
- Trackers> Face Tracker ... Track your face
- Connect the boxes

You can track your face just by starting the Face Tracker box.
- Set the parameters
Set the Mode variable of the Face Tracker parameter to ** Move **.

The application is now complete. The Face Tracker box has a big feature that "identifies the face and moves in that direction", so the flow can be as simple as this.
Operation check
Connect to Pepper and try playing. When a human is nearby, it tries to track the recognized face by bending its neck, but as it gradually moves away with the face facing, Pepper moves toward the face. If you are connected to Pepper by wire, be careful not to move it in an unexpected direction.
Before I get used to it, I'm a little scared to be chased while staring at Pepper, but eventually I may think that my eyes are cute ...!
Face learning and discrimination
In the previous example, I simply counted and chased "faces". Here, let's take a look at learning to remember who the face is.
Face learning
You can let Pepper learn with faces by using the Learn Face box. Here, we will try ** to memorize the face that Pepper saw with the name "Taro" 5 seconds after playback **.
Try to make
- Preparation of boxes to use (standard box library)
- Data Edit> Text Edit ... Output any character string
- Vision> Learn Face ... Memorize the correspondence between faces and names
-
Connect the boxes
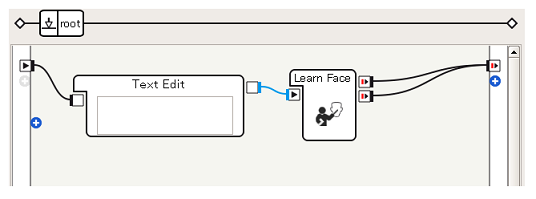
-
Set the character string

Now, Learn Face enables applications where Pepper's face is learned as a "taro".
Operation check
After connecting to Pepper and playing, make sure your face is within the range of Pepper's camera. Five seconds after playback, Pepper's eyes will turn green ** if the face can be learned normally, and ** red ** if it fails.
You can delete the learned face data by executing ** Unlearn All Faces Box **.
####
[Reference] Learn Face contents You can see how "Wait for 5 seconds" and "Eyes turn green" in the Learn Face box are realized by double-clicking the Learn Face box.
You can see that the Learn Face box is a flow diagram box and is represented as a collection of simpler boxes such as Wait. By looking inside the box in this way, you can use it as a reference when thinking about how to use the box.
Face discrimination
After learning a face, based on the learning data, ** determine who the face Pepper is currently recognizing is and let him speak its name **.
Try to make
- Preparation of the box to use
- standard box library
- Vision> Face Reco. ... Face identification
- advanced box library
- Audio> Voice> Say Text ... Speak the character string entered from the previous Box
- Connect the boxes
 It's very simple, it just gives the output (blue, string) of the Face Reco. Box to the Say Text box.
It's very simple, it just gives the output (blue, string) of the Face Reco. Box to the Say Text box.
Operation check
Connect to Pepper and play. If you show your face to Pepper and say the name you learned, such as "Taro", you will be successful. Learn Face multiple faces to see if Pepper can be identified properly.
Image learning and discrimination
Choregraphe has a function to operate the visual recognition database, which can be used to make Pepper learn something other than the human face.
Image learning
To learn the images, use Choregraphe's video monitor panel. Here, let's learn ** NAO ** in the atelier.
-
Connect to Pepper, with the object on the video monitor, click the ** Learn button **
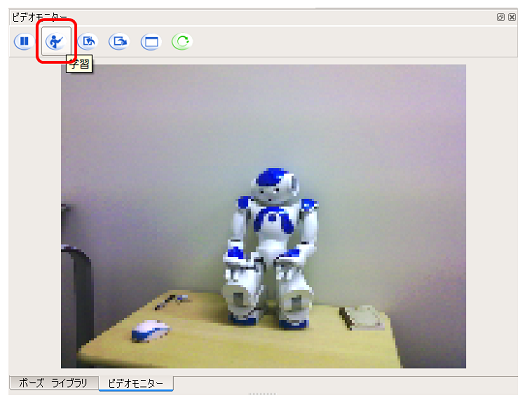
-
Click the left mouse button on ** Boundary of Object **

-
Create a vertex by clicking the left button as if drawing a straight line.

-
Set the vertices to surround the object, and finally left-click on the starting point.

-
The area of the object will be identified and a dialog will open asking you to enter information. Enter the appropriate information.

Enter NAO here.

- Click the ** Send current visual recognition database to robot button ** to send the information registered in Choregraphe's visual recognition database to Pepper.

You have now associated Pepper with the string "NAO" to the image features of NAO.
Image discrimination
As with face discrimination, we will try to ** talk about what you are looking at based on the contents of the trained visual recognition database **.
Try to make
The Vision Reco. Box allows you to match what Pepper is currently looking at with the visual recognition database to get the name of the object.
- Preparation of the box to use
- standard box library
- Vision> Vision Reco. ... Match the visual recognition database
- advanced box library
- Audio> Voice> Say Text ... Speak the character string entered from the previous Box
-
Connect the boxes (1)
 First, give the onPictureLabel output (blue, string) of the Vision Reco. Box to the Say Text box, similar to face discrimination.
First, give the onPictureLabel output (blue, string) of the Vision Reco. Box to the Say Text box, similar to face discrimination. -
Connect the boxes (2) In this sample, the ** onPictureLabel output ** and ** onStop input ** of the Vision Reco. Box are connected in order to stop the operation of the Vision Reco. Box while talking after recognition (the reason will be described later).
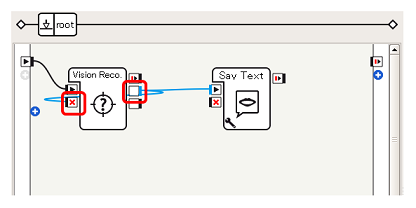 After talking, connect the ** onStopped output ** of the Say Text box to the ** onStart input ** of the Vision Reco. Box to resume operation of the Vision Reco. Box.
After talking, connect the ** onStopped output ** of the Say Text box to the ** onStart input ** of the Vision Reco. Box to resume operation of the Vision Reco. Box.

####
Therefore, if you only connect in 2., not only will you continue to talk "NAO", "NAO", "NAO" while showing NAO, but this will continue for a while even if you remove NAO from Pepper's field of view. It will be. To prevent such problems, after the Vision Reco. Box outputs the recognition result, the Vision Reco. Box is temporarily stopped, and after the Say Text box is finished, the Vision Reco. Operation is restarted. ..
Operation check
Please connect to Pepper and play the created application. Speaking of "NAO" when showing NAO is a success.
As you can see, Pepper has various functions for image recognition. By controlling Pepper with the information obtained from the eyes, the range of control can be expanded. Please give it a try.
Recommended Posts