[PYTHON] Categorize cat images using ChainerCV
<!-Classify cat images with chainercv -->
Overview
About 2000 images of cats collected from the image posting site Pixabay are collected using the machine learning library ChainerCV. I tried to classify.
pixabay is a site that collects and publishes images and videos with a fairly loose license called ~~ CC0 (public domain) ~~ Pixabay License. Some images other than cats are actually mixed in the images collected by specifying "cat" as the search term. Ultimately, I think it will be necessary to classify manually, but the goal of this article is to first separate the files using an existing trained classification model for preprocessing.
ChainerCV
Trained models of VGGNet are widely distributed, and there are several methods that apply them. When I was looking for a toolkit for image classification using it, I arrived at ChainerCV: a Library for Computer Vision in Deep Learning. Supports object detection and semantic segmentation.
I wrote the code to classify the files using this. It is based on the contents of the sample.
code
#!/usr/nogpu/bin/python
# -*- coding: utf-8 -*-
import argparse
import chainer
from chainercv.datasets import voc_detection_label_names
from chainercv.links import SSD300
from chainercv import utils
import os
def main():
chainer.config.train = False
parser = argparse.ArgumentParser()
parser.add_argument('--gpu', type=int, default=-1)
parser.add_argument('--pretrained_model', default='voc0712')
parser.add_argument('src_dir')
parser.add_argument('dst_dir')
args = parser.parse_args()
model = SSD300(
n_fg_class=len(voc_detection_label_names),
pretrained_model=args.pretrained_model)
if args.gpu >= 0:
model.to_gpu(args.gpu)
chainer.cuda.get_device(args.gpu).use()
file_lists = []
for f in os.listdir(args.src_dir):
if not f.startswith("."):
file_lists.append(f)
if not os.path.exists(args.dst_dir):
os.mkdir(args.dst_dir)
cat_id = voc_detection_label_names.index('cat') #Obtaining an index equivalent to a cat
def has_cat(labels):
for l in labels:
if type(l) == int:
if l == cat_id:
return True
for ll in l: #labels may return an array of arrays
if ll == cat_id:
return True
return False
print("target file: %d files" % len(file_lists))
count = 0
for f in file_lists:
fname = os.path.join(args.src_dir, f)
img = utils.read_image(fname, color=True)
bboxes, labels, scores = model.predict([img])
if has_cat(labels):
dst_fname = os.path.join(args.dst_dir, f)
os.rename(fname, dst_fname)
count += 1
print("%d: move from %s to %s" % (count, fname, dst_fname))
print("%d files moved." % count)
if __name__ == '__main__':
main()
Commentary
There are various methods supported by ChainerCV, but when I tried it with Faster-RCNN and Single Shot Multibox Detector (Wei Liu, et al. "SSD: Single shot multibox detector" ECCV 2016.), SSD It was faster, so I used it to write the code.
It will automatically download the pre-learning model when you create an SSD300 class instance. This time, I chose "voc0712" which is the same as the demo default attached to Chainer CV. This download process is performed only the first time it is executed and is saved with the file name $ HOME / .chainer / dataset / pfnet / chainercv / models / ssd300_voc0712_2017_06_06.npz. This model supports 20 different categories. This model is compatible with The PASCAL Visual Object Classes Challenge 2012 (VOC2012).
$ python
>>> from chainercv.datasets import voc_detection_label_names
>>> voc_detection_label_names
('aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor')
accuracy
It doesn't look bad at first glance. The files to be processed include cats other than cats (lions, leopards, etc.), but since they are not subject to VOC2012, cats and dogs that seem to have relatively similar characteristics. It seems that it is often classified as.
From the results classified as cats, we selected those that are clearly not cats. The results are shown below.
| Image file | Classified as a cat | Classified as other than cats |
|---|---|---|
| The cat is in the picture | 1635 | 70 |
| The cat is not in the picture | 7 | 337 |
- Total number of images: 2049
- false-negative 7 sheets
- false-positive 70 sheets
- precision: 0.9957
- recall: 0.9589
The accuracy seems to be high enough, but compared to an environment where the classification accuracy would generally be evaluated given that the majority of the subjects are cat images (moderately comparable images for each label). It may not be a little fair to do.
Misjudgment case
Let's look at some failed cases.
Even though it looks like a cat, it is judged as a dog
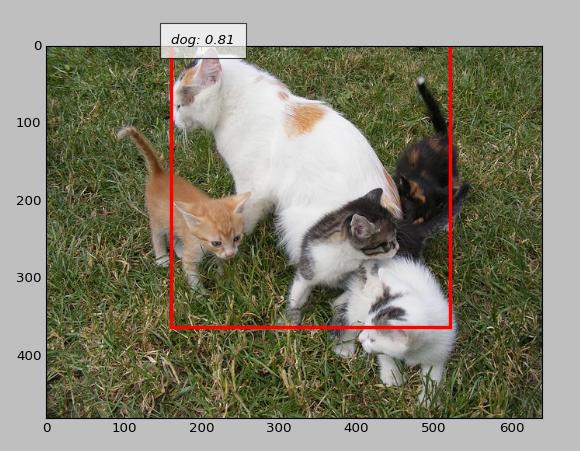
Is the object in the foreground in the way?


Are you dragged towards the background judgment?
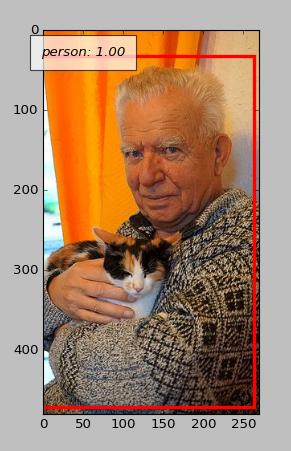
The contrast is not good
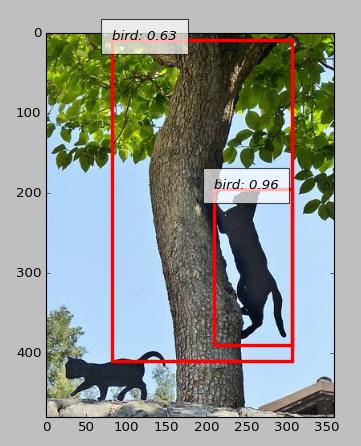
Just yarn

Statues and stuffed animals

The case where the classification is correct but I wanted you to play
The one in the picture is a cat (or something that can't be helped if it looks like that), and the following are examples of cases where cats are also classified as cats.
- Cat's forefoot up
- Face up
- Only around the eyes
- Only around the mouth
- Only the tail
- Plush Doll
- Processed photo image
- Photorealistic picture
- Moderately deformed image
- Through the screen door
- Out of focus image
- Monochrome image
There are some behaviors that are correct in a sense, so it seems that these things can only be classified by hand.
Repository for reproduction
The URL list I used to collect images is available on github. If you prepare image data based on this information, you can reproduce what you did in this article.
- https://github.com/knok/pixabay-cat-images
from now on
Since the recognized area can also be obtained, I think it would be nice to be able to perform processing such as playing images below a certain percentage. We plan to use this result for pix2pix (previous article).
Added about the license change of AIX
I don't know the exact date, but AIX has dropped the license on CC0 and added some restrictions. As far as I confirmed on Wayback Machine, I added a limit around July 2017 is. It's a fairly good license for machine learning training data, but keep in mind that it's no longer CC0.
Recommended Posts