Using Azure ML Python SDK 5: Pipeline Basics
Contents of this time
This time, I will introduce the function to execute multiple tasks (such as data preparation and model training) as one pipeline. The completed pipeline can now be published as an endpoint and can be a part of automation. You can schedule it yourself, or you can pass parameters at the time of the call, but this time I'll explain it with the most basic sample.
Scenario here
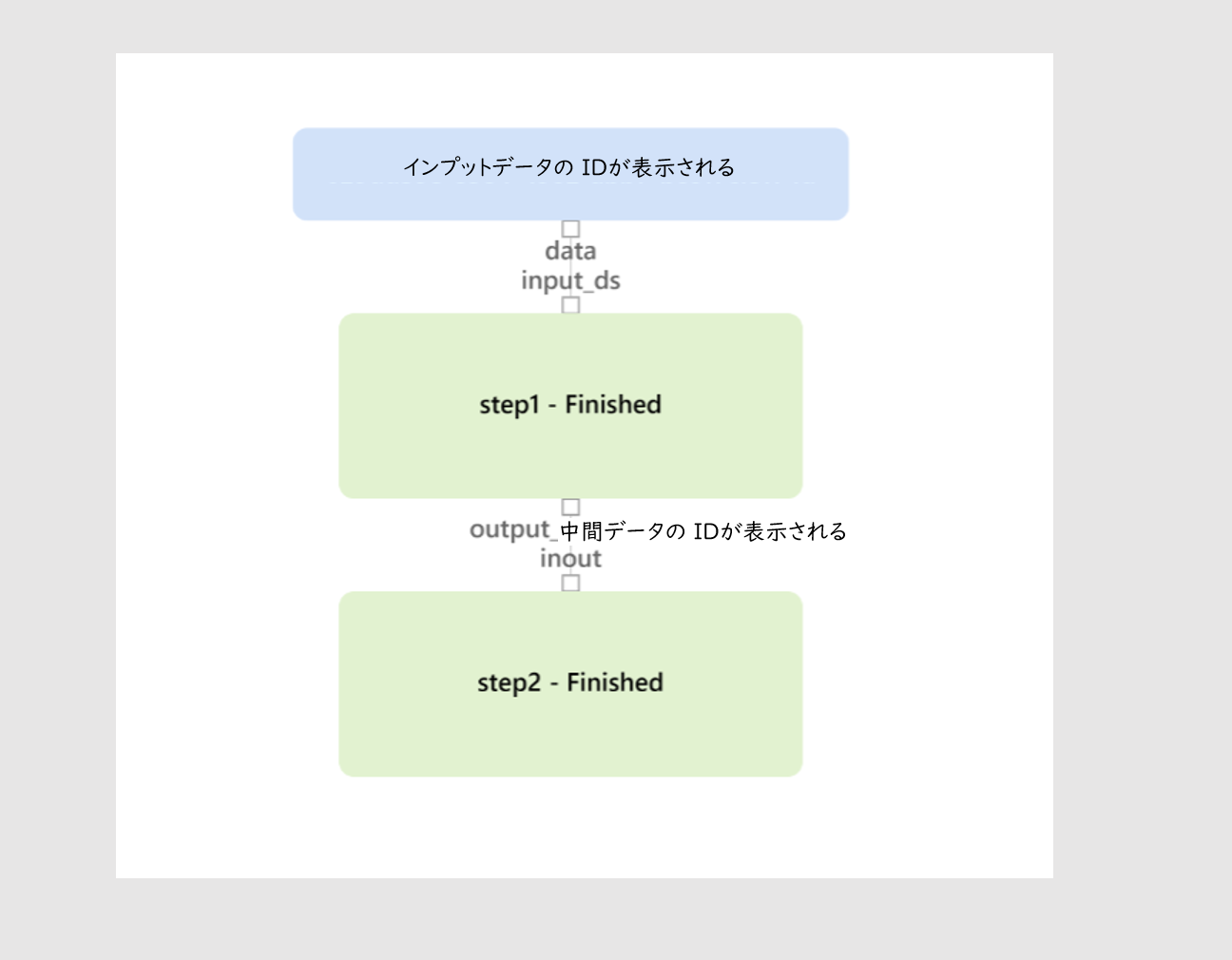
Now consider a pipeline that sequentially executes the two tasks STEP1 and STEP2. ("Pipeline configuration" in the figure below)
--STEP1 receives the file "HelloWorld.txt" from input_data1 and stores the intermediate file "output.csv" in inout --STEP2 retrieves the inout file and stores it in output2 as it is
Since input_data1, inout, and output2 are object names in the script, the blog storage folders registered under the name demostore, work, work_out, and work_out2 are actually referenced. ("Storage configuration" in the figure below)
It is assumed that the script_pipeline folder is prepared locally in Nootebook, and the processing contents of STEP1 and STEP2 are implemented in script2.py and script2-1.py. .. ("Script folder structure" in the figure below)

procedure
We will continue to follow the steps as before.
-
Load the package
Load the package.from azureml.core import Workspace, Experiment, Dataset, Datastore from azureml.core.compute import ComputeTarget from azureml.core.compute_target import ComputeTargetException from azureml.core.runconfig import RunConfiguration from azureml.core.conda_dependencies import CondaDependencies from azureml.data import OutputFileDatasetConfig from azureml.pipeline.core import Pipeline from azureml.pipeline.steps import PythonScriptStep from azureml.widgets import RunDetails workspace = Workspace.from_config() -
Specifying a computing cluster
Specify the compute cluster.aml_compute_target = "demo-cpucluster1" # <== The name of the cluster being used try: aml_compute = ComputeTarget(workspace, aml_compute_target) print("found existing compute target.") except ComputeTargetException: print("no compute target with the specified name found") -
Specify input and output folders
demostore is the datastore name registered in Azure ML Workspace. I'm passing the file path in her blob container for the datastore to the dataset class.ds = Datastore(workspace, 'demostore') input_data1 = Dataset.File.from_files(ds.path('work/HelloWorld.txt')).as_named_input('input_ds').as_mount() inout = OutputFileDatasetConfig(destination=(ds, 'work_out')) output2 = OutputFileDatasetConfig(destination=(ds, 'work_out2')) # can not share output folder between steps
This is similar to the input/output pair shown in Using Azure ML Python SDK 3: Exporting Output to Blob Storage--Part 1, but here the output defined by OutputFileDatasetConfig. The difference is that there are two. Also, at this point inout is not associated with intermediate file storage, but it will be associated with subsequent cells.
-
Specifying the container environment
The PythonScriptStep used in the next cell should use RunConfiguration () used in 1 and 2 using the Azure ML Python SDK instead of Environment () used in 3 and 4 using the Azure ML Python SDK. ..run_config = RunConfiguration() run_config.target = aml_compute run_config.environment.python.conda_dependencies = CondaDependencies.create(pip_packages=[ 'azureml-defaults' ], pin_sdk_version=False) -
Specifying the executable file name
In the previous sample, the executable file name and environment were configured by ScriptRunConfig, but in the pipeline, PythonScriptStep is used. (It is not limited to this depending on the contents of the pipeline.)
The argument configuration is almost the same as ScriptRunConfig.
The pipeline throws multiple tasks together into a compute cluster, but here we prepare STEP1 and STEP2.step1 = PythonScriptStep(name="step1", script_name="script2.py", source_directory='script_pipeline', arguments =['--datadir', input_data1, '--output', inout], compute_target=aml_compute, runconfig=run_config, allow_reuse=True) step2 = PythonScriptStep(name="step2", script_name="script2-1.py", source_directory='script_pipeline', arguments =['--datadir', inout.as_input(name='inout'), '--output', output2], compute_target=aml_compute, runconfig=run_config, allow_reuse=True)
The inout defined as the output of STEP1 has been redefined as .as_input () in the input of STEP2. This indirectly associates STEP1 and STEP2, and at the same time specifies that inout is the intermediate file storage.
Without this association, STEP1 and STEP2 would be executed in parallel. (However, when executing in parallel, the output folder name of STEP1 and the input folder name of STEP2 must be different.)
-
Definition of pipeline
Define a pipeline.pipeline1 = Pipeline(workspace=workspace, steps=[step1, step2])
The configuration of the pipeline can be verified in advance.
```python
pipeline1.validate()
print("Pipeline validation complete")
```
-
Executing a pipe run
Run the pipeline.pipeline_run = Experiment(workspace, 'pipeline-test').submit(pipeline1, regenerate_outputs=False)
Not just for pipelines, you can use RunDetails to monitor execution. I haven't introduced it so far, so I'll use it here.
```python
RunDetails(pipeline_run).show()
```
The following execution status is displayed in this widget.
This execution graph can also be viewed in Azure ML Studio.
-
Waiting for the end of the pipeline
Wait for the end of the pipeline%%time pipeline_run.wait_for_completion(show_output=True) -
Contents of STEP1 and STEP2
The contents of the script are illustrated for reference. It is made almost the same as the sample used so far. script2.pyimport argparse import os print("*********************************************************") print("************* Hello World! *************") print("*********************************************************") parser = argparse.ArgumentParser() parser.add_argument('--datadir', type=str, help="data directory") parser.add_argument('--output', type=str, help="output") args = parser.parse_args() print("Argument 1: %s" % args.datadir) print("Argument 2: %s" % args.output) with open(args.datadir, 'r') as f: content = f.read() with open(os.path.join(args.output, 'output.csv'), 'w') as fw: fw.write(content)
script2-1.py
```python
import argparse
import os
print("*********************************************************")
print("************* Hello World! *************")
print("*********************************************************")
parser = argparse.ArgumentParser()
parser.add_argument('--datadir', type=str, help="data directory")
parser.add_argument('--output', type=str, help="output")
args = parser.parse_args()
print("Argument 1: %s" % args.datadir)
print("Argument 2: %s" % args.output)
for fname in next(os.walk(args.datadir))[2]:
print('processing', fname)
with open(os.path.join(args.datadir, fname),'r') as f:
content = f.read()
with open(os.path.join(args.output, fname), 'w') as fw:
fw.write(content)
```
The HelloWorld.txt used here is a very simple file.
```python
0,Hello World
1,Hello World
2,Hello World
```
in conclusion
What do you think. Creating a pipeline allows you to automate Machine Learning tasks. Next time, I will write about hyperparameter tuning.
Reference material
Azure Machine Learning Pipelines: Getting Started PythonScriptStep Class Use Azure ML Python SDK 1: Use dataset as input-Part 1 [Using Azure ML Python SDK 2: Using dataset as input-Part 2] (https://qiita.com/notanaha/items/30d57590c92b03bc953c) [Using Azure ML Python SDK 3: Using dataset as input-Part 1] (https://qiita.com/notanaha/items/d22ba02b9cc903d281b6) [Using Azure ML Python SDK 4: Using dataset as input-Part 2] (https://qiita.com/notanaha/items/655290670a83f2a00fdc) Azure/MachineLearningNotebooks What is Azure Machine Learning SDK for Python? (https://docs.microsoft.com/ja-jp/python/api/overview/azure/ml/?view=azure-ml-py)
Recommended Posts