[PYTHON] 7 tips to avoid frustration in A3C after graduating from DQN
Introduction
When I tried to reproduce A3C by myself while looking at many codes on the net and reading the literature, I felt that there were too many pitfalls and the darkness was deep, so I will be the last to get stuck in such darkness. Therefore, I tried to summarize the places I was addicted to in the form of Tips If you are thinking of writing your own code and trying your best, I hope that you will not get into the darkness even a little after seeing this.
What is A3C
A3C stands for Asynchronous Advantage Actor-Critic, announced by DeepMind, which is familiar with DQN in 2016.
――Fast: Learning progresses quickly because learning is done using Asynchronous and Advantage! ――Cheap: Deep Learning overturns the common sense of GPU, and you can calculate with only an inexpensive CPU! --Good: Better performance than DQN (and other comparison methods)!
It is a deep reinforcement learning method like a beef bowl with all three beats. In a nutshell, DQN is old and A3C is new and better (basically, if not absolutely).
Like this ↓

Asynchronous At DQN, the experience gained by one agent acting was randomly sampled (because the experience does not become iid online) and used as training data. Since the experience of only one agent is used, the speed at which learning samples are collected is slow, and since the experience was once accumulated in the form of ReplayMemory and then learned, it is difficult to learn from time-series data such as LSTM. There was Therefore, in the A3C Asynchronous part, multiple agents (Max 16 in the paper) are moved at the same time, and individual experiences are collected and learned so that the overall experience is randomly sampled and learned online. I am trying to be Also, since I can gain a lot of experience at the same time, I can learn faster by that much.
Advantage In normal TD learning, the sum of the reward $ r $ obtained as a result of the action and the estimated value $ V (s_ {t + 1}) $ (discounted by the discount rate $ \ gamma $) of the value of the next state. And, using the difference of the estimated value of the current state $ \ Delta $, we will update the value of the state.
Conversely, if the estimate for the next state is incorrect, the estimate for the current state will not be updated correctly in the first place. Furthermore, the estimate of the next state must be correct for the next estimate, and the estimate of the next state is chained with ..., so this is only one step ahead. The update method is expected to take some time to converge to the correct value Therefore, in A3C, taking advantage of being able to learn online, that is, using time series data, we will update the estimated value using the next amount called Advantage.
Here, $ k $ is a constant that indicates how much look-ahead is to be performed. Since the most probable information in the value estimation of reinforcement learning is the reward $ r $ actually obtained, the amount of Advantage is the more probable current value considering the reward k steps ahead instead of one step ahead. It can be said that the estimation error of A3C uses this amount for learning,
――Because it is a more probable value, learning progresses faster ――Since we consider up to several steps ahead, learning progresses faster than if you only look one step ahead.
It is thought that it is a method that made learning more efficient by expecting these two points.
Actor-Critic
In DQN, we trained an estimate of the value of performing an action $ a $ in a certain state $ s $, which is called the Q value. Since we estimate the value of an action in a certain state, there was a problem that the number of combinations that had to be estimated became enormous when the action was continuous (for example, when we wanted to learn the rotation speed of the motor). Actor-Critic is a reinforcement learning method that learns while independently estimating the probability of action $ \ pi $ to occur in a certain state and the estimated value $ V $ of the state, and the estimated values are independent. , It has the feature that it is easy to learn even if the action is continuous. I do not know how much Actor-Critic contributes to the performance of A3C itself, but due to the above characteristics, A3C adopting Actor-Critic is either a discrete or continuous measure. Can be learned, and it can be said that it has become versatile.
7 Tips to avoid frustration
The introduction has become longer Since there are many A3C implementations that can be referred to, such as the GitHub repository below.
From here on, aside from the details of how to implement A3C, I implemented it for those who want to write, write, or want to write code to some extent, rather than slamming it all around. However, when learning does not progress, or when learning progresses but the result of the dissertation is completely different, I will introduce the points to be careful and check as pitfalls and tips that I am addicted to.
Pit / Tips Part 1 Hyperparameter is a mystery
As you proceed with the implementation, there will be some unclear points such as the parameters of RMSProp and how to attenuate the learning rate. Fortunately, the ancestors have already [published] what parameters should be used (https://github.com/muupan/async-rl/wiki), so you can search for hyperparameters yourself or worry about strange things. Let's stop
Pit / Tips Part 2 Automatic Differentiation Trap
The description of the A3C implementation in the paper has the following two lines:
There is nothing wrong with it, but since the Atari reproduction network is divided into two parts and shares some parameters, $ \ theta': d \ theta \ leftarrow d \ theta + \ nabla_ { \ theta'} \ log \ pi (a_i | s_i; \ theta') \ bigl (RV (s_i; \ theta_v') \ bigr) $ is $ V (s_i; \ theta_v') if implemented as it is Since the $ part is not originally a function of $ \ theta'$, in the case of tensorflow, if $ V (s_i; \ theta_v') $ is not given a scalar value, the gradient calculation will be incorrect as a result of automatic differentiation. Masu
Pit / Tips Part 3 OpenCV2 Drama Slow Problem
If you are using OpenCV for grayscale or image display etc., you should make sure that you are using OpenCV3. If I didn't notice it and thought that OpenCV seemed to be a bottleneck, I used OpenCV2, and when I switched to OpenCV3, the execution speed increased several times.
Pit / Tips # 4 Arcade Learning Environment does not support multithreading
If you implement it in multiple processes, it doesn't matter, but if you implement it in multiple threads, you have to think about it. It doesn't mean that it doesn't work at all because I didn't take any measures, but there is no radical solution, and as far as I know, there is only a symptomatic treatment for relaxation that is probably okay. There is also miyosuda / async_deep_reinforce, but it is effective to modify the source code of the arcade learning environment a little and say that static variables are not static. Seems to be However, it still seems to be in a weird state from time to time in the range I tried (because I honestly don't know if my code is buggy or ALE is buggy), and the rest is like luck. Also, I felt that the code of the arcade learning environment was more stable in my environment by modifying the code of v0.5.1 than the latest master (maybe because of my mind ... for reference). )
Pit / Tips # 5 Convert scale to range 0-1 with image Preprocessing
The grayscale image obtained from ale is in the range of 0-255, but in my own experimentation, it seems that the performance will improve if you divide by 255 and change the overall scale to the range of 0-1 ( It's difficult to learn if you don't divide by 255 just to go up)
Pit / Tips # 6 Implement faithfully to your dissertation
That's natural! I'm going to get angry, but I'll write it here with caution that it should be implemented faithfully to the paper. What you should pay particular attention to is the number of steps of advantage, and as I wrote above, advantage is pre-read, so in theory it seems that the result is better if you can pre-read a lot, so it is not 5 in the paper. Isn't it better to have a larger number such as 10 or 20? Is DeepMind stupid? I want to think like a genius! I think this is a problem caused by the way the game is rewarded and the learning method called Actor-Critic, but in the Breakout game I tried, it must be $ t_ {max} = 5 $ on the way. Learning progressed faster than the dissertation, learning went wrong around what I thought was good (around 13Mstep), the network was broken, and then I could not recover. On the other hand, in Pong, 20 seems to work, so this number of steps should not be simply increased, it must be selected carefully. That means, and if you want to reproduce it, you should change it after reproduction.
Pit / Tips # 7 Check if you're Gradient Ascent
In this method, the gradient of the policy network must be corrected in the direction of increasing reward and entropy, so the calculation will be incorrect unless a negative sign is added to Loss so that it becomes Ascent instead of Gradient Descent. In the case of tensorflow, it looks like the following
policy_loss = - tf.reduce_sum(log_pi_a_s * advantage) - entropy * self.beta #I want to change the value in the direction of increasing, so add a minus to both.
value_loss = tf.nn.l2_loss(self.reward_input - self.value) #I want to reduce the error from the estimated value, so leave it as it is
Pit / Tips Extra Edition Do you have to worry about Global Interpreter Lock?
You should be careful, but it depends on which library you use and how fast you want it to run. At least, Tensorflow seems to be relatively aware of GIL issues it seems to be implemented, and I'm in the Ryzen7 1800X environment. It was about 2M step / hour below At 2Mstep / hour, it takes about 40 hours to reach 80MStep, which is written in the paper. Almost full-python Chainer is GIL conscious and multiprocessing It seems to be useless if you do not implement it
in conclusion
The code I wrote to reproduce it is posted on GitHub (LSTM version is not yet), so please refer to it. The learning results will be posted later ~~
Learning results
Here is the data when it took about 40 hours with Ryzen 1800X (I really wanted to do it with 16Thread, but it did not support Kernel, so 8)

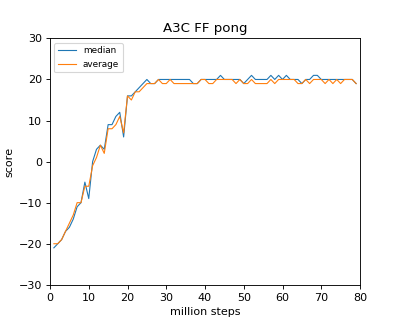
As far as I read the paper, it seems that the same result is obtained for Breakout / Pong. In the case of Breakout / Pong, it seems that it almost converges at a relatively early stage (20 million steps).
References
Asynchronous Methods for Deep Reinforcement Learning Reinforcement learning in continuous time: advantage updating