[PYTHON] Sentence vector creation using fastText (also visualization)
I tried to create a Japanese sentence vector using this model by referring to "I have released a trained model of fastText". .. It's hard to make models such as BERT and fastText, so those who publish these things will be disappointed. So, I would like to share as much know-how as possible about what can be done with such things.
Following the previous article "Creating sentence vectors using BERT (Keras BERT)", Google Colaboratory I'd like to use .com /) in an easy way to do it without having to put it in my machine.
How to make a sentence vector with fastText
If you want to try making a sentence vector regardless of the method, skip this section and go to the next section. fastText is the logic to get the representation of a vector of words. Since the correlation between words appears in the vector relationship, similar vectors can be obtained for words with similar usage. It seems that various methods have been devised to obtain a sentence vector using this word vector, but this time, simply, ** find the vector of all the words contained in the sentence and use the average as the preparative vector. ** I took the method. This method is not suitable for complicated sentences where the word order information disappears and the dependency and context affect the meaning of the sentence, but it is like a conversational sentence or a short question sentence with a disordered word order. It seems that it is fully available and the calculation is fast.
Prepare a model for fastText
First, prepare a trained model of fastText. You can get it from here introduced at the beginning.
-Trained model of fastText has been released
There is a ** Download Word Vectors ** link on this page, so download the file from there. From here, you can download a model created by dividing the original sentence into words in a normal Mecab dictionary. A model of word division using NEologd has also been released, but in this sample we will use the normal one.
Extract the downloaded vector.zip and extract ** model.vec **. Create a ** bert ** folder under ** My Drive ** on your Google Drive, create a ** fasttext ** folder, ** vector ** folder in it, and ** model. Upload vec **. It is okay if it looks like the following. This time bert is not relevant, but it is a folder name for the convenience of the sample, so if you feel uncomfortable, please rename it.
Run a program that creates sentence vectors
From here Download the following ipynb file, which is the main body of the program, and upload it to any location on Google Drive.
- fasttext_sentencevector.ipynb
Also, in this sample, at the end, I added a part to vectorize and visualize each sentence in the sentence list, so if you want to try it so far, download the following list and * Please store it directly under the * bert ** folder.
- sample_corpus1.csv
Set up Google Drive to use Google Colaboratory and open ** fasttext_sentencevector.ipynb ** in Google Colaboratory. Once open, run it with Run all ([Ctrl] + [F9]).
The code runs in order, and in one place on the way, "Mount Google Drive in path / content / drive" is displayed as follows. Since you need to authenticate to see the file in Google Drive, click the link displayed, give permission according to the instructions on the screen, and enter the code displayed at the end of "Enter your authorization code:" If you put it in the place, it will proceed.
Go to this URL in a browser: https://accounts.google.com/o/oauth2/auth?client_id=...
Enter your authorization code:
In the code cell below, the sentence set in the sentence_vector function is the sentence for which the sentence vector is created.
print(sentence_vector('I'd like to make a restaurant reservation'))
The created sentence vector has 300 dimensions and looks like this.
[[ 0.1202 -0.01985181 -0.03682778 0.09241433 0.06526966 -0.03810288
0.002114 0.031315 -0.07302511 0.05999633 0.12339155 0.036735
-0.01310033 0.00162244 -0.1747051 0.0203813 -0.07293266 -0.16425289
...
-0.113902 0.07032856 0.00790416 -0.05663266 -0.00517633 0.0051248
-0.04521288 -0.13712189 -0.17047666 -0.01394678 0.03347553 0.09704111
-0.04956407 -0.10511766 -0.06996578 -0.016097 -0.07823177 -0.06531233]]
Did it move successfully? If you rewrite the argument and execute this code cell again, the sentence vector will be recalculated and output.
Visualize the text vector of the question text list
As a bonus, find the vector for each sentence in the list of question sentences, plot it on a graph, and visualize it. This question text list is categorized by question type, and the question type number is set in category.
category,input
1,Can you deliver the lunch box?
1,Can you deliver the lunch box?
1,Do you have lunch
1,I want you to deliver your lunch to the company
1,Do you have a lunch box
1,Is there a delivery service for lunch?
1,Can you deliver it to me
1,Can you deliver the meal?
1,Do you offer home delivery service
2,Can I bring my pet with me?
2,Can I bring my pet
2,Put pets together
2,Do you want to bring a dog
2,Can i put a dog
2,Can it be used with dogs
..
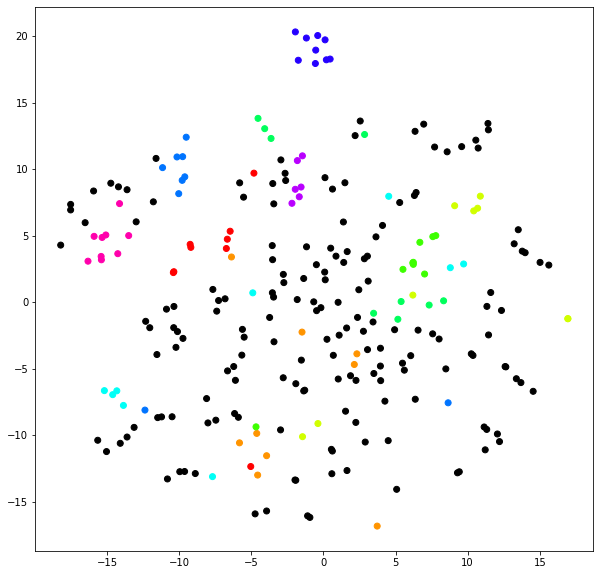
After finding the vector of each interrogative sentence, color-code it with category and plot it. Since the vector of the question sentence has 300 dimensions, it looks like this when compressed to 2 dimensions using t-SNE and plotted. There are about 30 categories in the question list, but if you color all of them, it will be difficult to see, so I colored only 10 of them and made the rest black. You can see that the same question types are relatively solid. In other words, it can be said that question sentences with similar meanings become close sentence vectors.
Where I got stuck
One day, I suddenly got an error when loading mecab. I didn't know the reason at all, but thanks to the references, I found the cause and it was due to an upgrade on the mecab side. Therefore, in the sample, I try to use a specific version of mecab.
error message: [ifs] no such file or directory: /usr/local/etc/mecabrc
References
I referred to this document.
-Trained model of fastText has been released -Use mecab ipadic-NEologd with Google Colaboratory -[Error not found mecabrc](https://medium.com/@jiraffestaff/mecabrc-%E3%81%8C%E8%A6%8B%E3%81%A4%E3%81%8B%E3% 82% 89% E3% 81% AA% E3% 81% 84% E3% 81% A8% E3% 81% 84% E3% 81% 86% E3% 82% A8% E3% 83% A9% E3% 83% BC-b3e278e9ed07)
in conclusion
I introduced how to create a sentence vector in the shortest possible procedure as easily as possible, but if something goes wrong, please comment. If the sentences can be made into vectors, the usage will be expanded in various ways. BERT is good, but fastText is very nice because the model size is small and light.
I usually develop products related to natural language and AI here. We also use technologies other than fastText, so please feel free to contact us if you have any questions about AI or machine learning. → Ifocus Network Co., Ltd.