[PYTHON] Beurteilung der emotionalen Polarität von Sätzen mit dem Textklassifikator fastText
Einführung
Ich habe ein Skript erstellt, das automatisch die emotionale Polarität (positiv, negativ) für jeden Satz bestimmt, daher möchte ich es zusammenfassen.
Im Bereich der Beurteilung der emotionalen Polarität anhand von Sätzen (Dokumenten) wird dies auch als Stimmungsanalyse oder Reputationsanalyse bezeichnet. In der Vergangenheit bestand die orthodoxe Methode darin, Polaritätswerte (positive und negative Werte) für jedes Wort im Wortpolaritätswörterbuch zu registrieren und diese zur Bestimmung der Polarität zu verwenden. Bei dieser Methode besteht jedoch das Problem, dass nicht berechnet werden kann, wann ein Wort erscheint, das nicht im Polaritätswörterbuch enthalten ist, und dass die Polarität des Wortes überhaupt eindeutig bestimmt werden kann. Es gibt ein Problem. (z. B. ist auch nur ein Wort "billig" billig und günstig! Wenn Sie sagen, billig ist positiv, aber wenn Sie sagen, dass Sie billig sind, erhalten Sie einen negativen Eindruck.)
Daher werden wir in diesem Artikel ein Skript vorstellen, das die emotionale Polarität eines Satzes mithilfe eines Textklassifikators automatisch berechnet und Daten von einer EC-Site überprüft. Indem Sie aus den Überprüfungsdaten lernen, ** den Punkt, an dem Sie sich die Mühe beim Erstellen eines Polaritätswörterbuchs ersparen können, und den Punkt, an dem Sie die emotionale Polarität anhand syntaktischer Informationen beurteilen können (der Polaritätswert des Wortes kann flexibel geändert werden) ** Vielleicht schmeckt es gut! Ich habe es mit der Erwartung geschafft.
fastText fastText [^ 1] ist ein maschinelles Lernen, das die von Facebook entwickelte Wortvektorisierung und Textklassifizierung unterstützt.
Die Struktur selbst ist die Struktur eines dreischichtigen neuronalen Netzwerks, wie in der folgenden Abbildung gezeigt, und weist eine Struktur auf, die dem von Mikolov et al. Vorgeschlagenen CBoW-Modell sehr ähnlich ist.
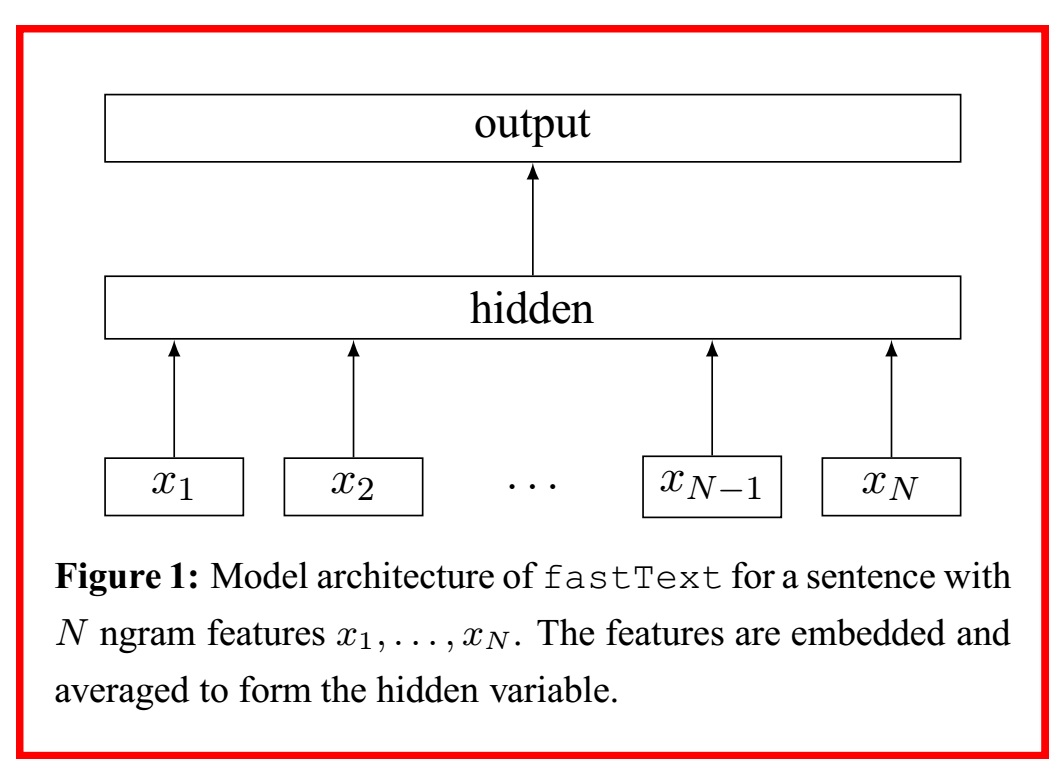
In der Eingabeebene wird der One-Hot-Vektor der im $ i $ -ten Dokument enthaltenen Wörter angegeben, und in der Ausgabeschicht wird die Wahrscheinlichkeitsverteilung, dass jedes Dokument zu jeder Klasse gehört, durch softmax $ {\ bf p} = (p_1, p_2, .. ., p_n) Holen Sie sich $. Die exklusive Klassifizierungsmethode (Ausgabe einer Klasse) gibt die Klasse mit dem höchsten Wahrscheinlichkeitswert von $ {\ bf p} $ aus.
Trainingsdaten
Dieses Mal haben wir ein Modell zur Beurteilung der Satzpolarität unter Verwendung der Überprüfungsdaten von EC-Sites (Amazon und Rakuten) erstellt. Bereiten Sie von den Bewertungen für Produkte die Anzahl der Sterne als korrektes Antwortetikett und den Bewertungstext als Lerndaten vor. Wenn Sie möchten, dass fastText trainiert, können Sie eine Liste wie die folgende erstellen. Das richtige Antwortetikett lautet \ ___ label \ ___ **, und der Lernhintergrund ist eine geteilte Version des unter dem Etikett beschriebenen Dokuments.
train.lst
__label__1,Ich war nicht am Lesen interessiert, also schauen Sie bitte. Es ist schwarz und weiß und die Illustrationen sind nicht süß, also habe ich es einmal geöffnet ... Ich kann es nicht laut vorlesen.
tat.
__label__1,Es scheint, dass es in 3 Minuten nach dem Start ausverkauft war. Ich konnte es nicht kaufen.
FastText lernen
FastText zu lernen ist sehr einfach. Wenn die Trainingsdaten (train.lst) input_file sind und das Speicherziel des trainierten Modells ausgegeben wird, können Sie nur mit dem folgenden Code trainieren.
learning.py
argvs = sys.argv
input_file = argvs[1]
output = argvs[2]
classifier = ft.supervised(input_file, output)
Beurteilung der emotionalen Polarität von Sätzen
Finden Sie die emotionale Polarität des als Eingabe angegebenen Satzes gemäß der folgenden Formel.
- $ e_i $: Bewertungswert für $ i $ ($ e = \ {e_1 = 1, e_2 = 2, ..., e_5 = 5 \} $)
- $ p_i $: Wahrscheinlichkeit, dass die Eingabeanweisung als Bewertung $ e_i $ beurteilt wird
In der obigen Formel gibt $ p_i $ den Wert der Ausgabeebene von fastText an, und $ e_i $ gibt die Anzahl der Sterne an. Der emotionale Polaritätswert $ score $ eines Satzes wird als positiv beurteilt, wenn er sich 5 nähert, und negativ, wenn er sich 1 nähert. ** Wenn der von Ihnen eingegebene Text der Natur einer mit Sternen übersäten Bewertung nahe kommt, ist $ score $ höher. ** ** **
estimation.py
# -*- coding: utf-8 -*-
import sys
import commands as cmd
import fasttext as ft
def text2bow(obj, mod):
# input:Mod für Dateien="file", input:Mod für Strings="str"
if mod == "file":
morp = cmd.getstatusoutput("cat " + obj + " | mecab -Owakati")
elif mod == "str":
morp = cmd.getstatusoutput("echo " + obj.encode('utf-8') + " | mecab -Owakati")
else:
print "error!!"
sys.exit(0)
words = morp[1].decode('utf-8')
words = words.replace('\n','')
return words
def Scoring(prob):
score = 0.0
for e in prob.keys():
score += e*prob[e]
return score
def SentimentEstimation(input, clf):
prob = {}
bow = text2bow(input, mod="str")
estimate = clf.predict_proba(texts=[bow], k=5)[0]
for e in estimate:
index = int(e[0][9:-1])
prob[index] = e[1]
score = Scoring(prob)
return score
def output(score):
print "Evaluation Score = " + str(score)
if score < 1.8:
print "Result: negative--"
elif score >= 1.8 and score < 2.6:
print "Result: negative-"
elif score >= 2.6 and score < 3.4:
print "Result: neutral"
elif score >= 3.4 and score < 4.2:
print "Result: positive+"
elif score >= 4.2:
print "Result: positive++"
else:
print "error"
sys.exit(0)
def main(model):
print "This program is able to estimate to sentiment in sentence."
print "Estimation Level:"
print " negative-- < negative- < neutral < positive+ < positive++"
print " bad <----------------------------------------> good"
print "Input:"
while True:
input = raw_input().decode('utf-8')
if input == "exit":
print "bye!!"
sys.exit(0)
score = SentimentEstimation(input, model)
output(score)
if __name__ == "__main__":
argvs = sys.argv
_usage = """--
Usage:
python estimation.py [model]
Args:
[model]: The argument is a model for sentiment estimation that is trained by fastText.
""".rstrip()
if len(argvs) < 2:
print _usage
sys.exit(0)
model = ft.load_model(argvs[1])
main(model)
Ausführungsmethode
Führen Sie dies wie folgt über die Befehlszeile aus.
estimatin.py
$ python estimation.py [model]
- [Modell]: FastText-Modell gelernt (**. Bin-Datei)
Ausführungsergebnis
Hier ist das Ergebnis der tatsächlichen Ausführung und Beurteilung der emotionalen Polarität des Satzes. Übrigens wird es nach seiner Ausführung interaktiv. Geben Sie also "exit" ein, wenn Sie das Programm beenden möchten.
This program is able to estimate to sentiment in sentence. Estimation Level: negative-- < negative- < neutral < positive+ < positive++ bad <----------------------------------------> good Input: Der Ramen-Laden, in den ich gestern gegangen bin, war wirklich gut! Evaluation Score = 4.41015725 Result: positive++ Der Ramen-Laden, in den ich gestern gegangen bin, war etwas schmutzig, aber sehr lecker! Evaluation Score = 4.27148227 Result: positive++ Der Ramen-Laden, in den ich gestern gegangen bin, war ein modischer Laden, aber der Geschmack war nicht gut Evaluation Score = 2.0507823 Result: negative- Der Ramen-Laden, in den ich gestern gegangen bin, war schmutzig und unangenehm Evaluation Score = 1.12695298578 Result: negative-- exit bye!!
Irgendwie ist das Ergebnis so! Es vermittelt das Gefühl, dass die Polarität anhand des Satzendes und nicht anhand der syntaktischen Informationen beurteilt werden kann.
Zusammenfassung
Dieses Mal habe ich ein Skript erstellt, das die emotionale Polarität eines Satzes mithilfe des Textklassifikators fastText und der Überprüfungsdaten der EC-Site automatisch beurteilt. Es gibt kein Problem, wenn es einen Überprüfungstext und einen Bewertungswert für die EC-Site gibt. Ich denke, dass dies auch mit Amazon- oder Pompare Mall-Daten möglich ist.
Recommended Posts