[PYTHON] word2vec
Motivation ・ Word2vec kann einen Vektor angeben, der die Bedeutung eines Wortes auf gute Weise ausdrücken kann, indem nur eine große Textmenge angegeben wird. ・ Wenn Sie diesen guten Vektor als Merkmalsgröße verwenden, können Sie bei verschiedenen Aufgaben eine Verbesserung der Genauigkeit erwarten. ・ ・ Ich möchte die Genauigkeit der Informationsempfehlung verbessern ・ ・ Verwendung als Feature-Größe für FX-Vorhersageaufgaben zur Verbesserung der Genauigkeit usw. ·· Visualisierung
・ (Berühren Sie ein Ende des tiefen Lernens)
Haltung
・ Neben dem Verständnis von word2vec möchte ich damit interessante Dinge tun und die Genauigkeit von Aufgaben verbessern.
Agenda | Plan ・ Erleben Sie, wie gut der von word2vec erhaltene Vektor ist (dies ist heute) ・ Wenden Sie den von word2vec erhaltenen Vektor auf die Informationsempfehlungsaufgabe an und vergleichen Sie ihn mit dem Ergebnis eines normalen Vektors. ・ Wenden Sie den von word2vec erhaltenen Vektor auf die Austauschprognoseaufgabe an und vergleichen Sie ihn mit dem Ergebnis eines normalen Vektors. ・ Wenden Sie den von word2vec erhaltenen Vektor auf Visualisierungen wie die Charakteranalyse an, um den Geschmack zu visualisieren, ohne die menschliche Subjektivität zu übernehmen. ・ ・ Beispiel für die Visualisierung von Mimikwörtern
 http://techlife.cookpad.com/entry/2015/02/27/093000
http://techlife.cookpad.com/entry/2015/02/27/093000
Was ist word2vec?
・ Wenn Sie eine große Menge Text als Eingabe eingeben, wird so etwas wie eine Blackbox erstellt, die einen Vektor erstellt, der die Bedeutung jedes Wortes auf gute Weise ausdrücken kann
Probieren Sie verschiedene Dinge aus
Versuchen Sie zunächst, mit word2vec einen Vektor zu erstellen
Eingabe: 100 MB Englisch ↓ word2vec ↓ Ausgabe: Vektordarstellung (200 Dimensionen) für jedes Wort
Der Quellcode ist sehr einfach zu schreiben
genModel.py
import gensim
sentences = gensim.models.word2vec.Text8Corpus("/tmp/text8")
model = gensim.models.word2vec.Word2Vec(sentences, size=200, window=5, workers=4, min_count=5)
model.save("/tmp/text8.model")
print model["japan"]
(Beispiel) Vektor des Wortes "Japan"
aaa.txt
[-0.17399372 0.138354 0.18780831 -0.09954771 -0.05048304 0.140431
-0.08839419 0.0392667 0.267914 -0.05268065 -0.04712765 0.09693304
-0.03826345 -0.11237499 -0.12375604 0.15184014 0.09791548 -0.0411933
-0.26620147 -0.14839527 -0.07404629 0.14330374 -0.15179957 0.00764518
0.01670248 0.15400286 0.03410995 -0.32461527 0.50180262 0.29173616
0.17549005 -0.13509558 -0.20063001 0.50294453 0.11713456 -0.1423867
-0.17336504 0.09798998 -0.22718145 -0.18548743 -0.08841871 -0.10192692
0.15840843 -0.12143259 0.14727007 0.2040498 0.30346033 -0.05397578
0.17116804 0.09481478 -0.19946894 -0.10160322 0.0196885 0.11808696
-0.04913231 0.17468756 -0.14707023 0.02459025 0.11828485 -0.01075778
-0.13718656 0.05486668 0.25277957 -0.16104579 0.0396373 0.14481564
0.22176275 -0.17076172 -0.038408 0.29362577 -0.13069664 0.04339954
0.00451817 0.16272108 0.02541053 -0.14659256 0.16529948 0.13884881
-0.1113431 -0.09699004 0.07190027 -0.04339439 0.17680296 -0.21379708
0.1572576 0.03031984 -0.21495718 0.03347488 0.22941446 -0.13862187
0.21907888 -0.13375367 -0.13810037 0.09477621 0.13297808 0.25428322
-0.03635533 -0.1352797 -0.13009973 -0.01995344 0.05807789 0.34588996
0.10643663 -0.02748342 0.00877294 0.10331466 -0.02298069 0.26759195
-0.24946833 0.0619933 0.06216418 -0.20149906 0.0586744 0.16416067
0.34322274 0.25680053 -0.03443218 -0.07131385 -0.08819276 -0.02436011
0.01131095 -0.11262415 0.08383768 -0.17228018 -0.04570909 0.00717434
-0.04942331 0.01721579 0.19824736 -0.14876001 0.10319072 0.10815206
-0.24551305 0.02878521 0.17684355 0.13430905 0.03504089 0.14440946
-0.12238772 -0.09751064 0.22464643 -0.00364726 0.30931923 0.04332043
-0.00956943 0.40026045 -0.11306871 0.07663886 -0.21093726 -0.24558903
-0.11918587 -0.11373471 -0.04725014 0.16204022 0.06828773 -0.09220605
-0.04137927 0.06957231 0.29234451 -0.20949519 0.24574679 -0.14875519
0.24135616 0.13015954 0.03091074 -0.45729914 0.14642039 0.1330456
0.09597694 0.19738108 -0.08785061 0.15975344 0.11823107 0.10955801
0.43996817 0.22706555 -0.01743319 0.06030531 -0.08983251 0.43928599
0.07300217 -0.31112081 0.25329435 -0.02628026 -0.0781511 -0.03673798
0.01265055 -0.08048201 -0.0556048 0.25650752 0.02342006 -0.17268351
0.06641581 -0.04409864 0.02202901 -0.12416532 0.08068784 0.12611917
0.00144407 -0.24265616]
Ich bin mir nicht sicher, ob es gut oder schlecht ist, nur diesen Vektor zu betrachten, also werde ich diesen Vektor auf etwas anwenden
Versuchen Sie Anwendung 1: Suchen Sie nach ähnlichen Wörtern
Lassen Sie uns die Top 5 Wörter ähnlich wie "Japan" anzeigen. (Erhalten mit word2vec Vektor und cos Ähnlichkeit)
china 0.657877087593 india 0.605986833572 korea 0.598236978054 thailand 0.584705531597 singapore 0.552470624447
Länder mit engen Beziehungen liegen an der Spitze. Wenn Sie zum Vergleich die fünf besten Wörter auf die gleiche Weise mit einem gewöhnlichen Vektor finden (einem Vektor, der durch die Häufigkeit des Auftretens von Wörtern gebildet wird, die mit dem interessierenden Wort koexistieren), ohne word2vec zu verwenden,
in 0.617413123609 pensinula 0.604392809245 electification 0.602260135469 kii 0.5864838915 betrayers 0.575804870177
Und ein subtiles Ergebnis. Ich denke, es wird besser sein, wenn Sie tf-idf usw. kauen.
Versuchen Sie Anwendung 2: Visualisierung der Bedeutung
Visualisieren Sie den aus word2vec erhaltenen Vektor und bestätigen Sie, dass die Positionsbeziehung die Bedeutung ausdrückt. Im folgenden Beispiel sind beispielsweise zwei Wörter für einige Länder-Kapital-Paare dargestellt. Die Positionsbeziehung zwischen dem Land und der Hauptstadt wird in allen Fällen hergestellt → Das Konzept der Beziehung zwischen dem Land und der Hauptstadt kann verstanden werden.
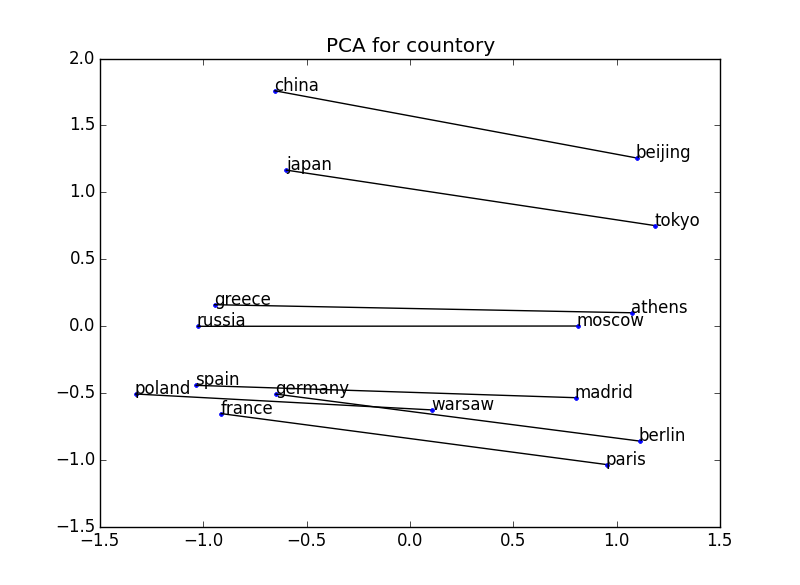 200 Dimensionen → 2 Dimensionen
200 Dimensionen → 2 Dimensionen
Zum Vergleich haben wir auf die gleiche Weise mit einem gewöhnlichen Vektor (einem Vektor, der durch die Häufigkeit des Auftretens von Wörtern gebildet wird, die mit dem interessierenden Wort koexistieren) ohne Verwendung von word2vec aufgetragen. Ich denke, es wird ein bisschen besser, wenn dies auch normalisiert wird.
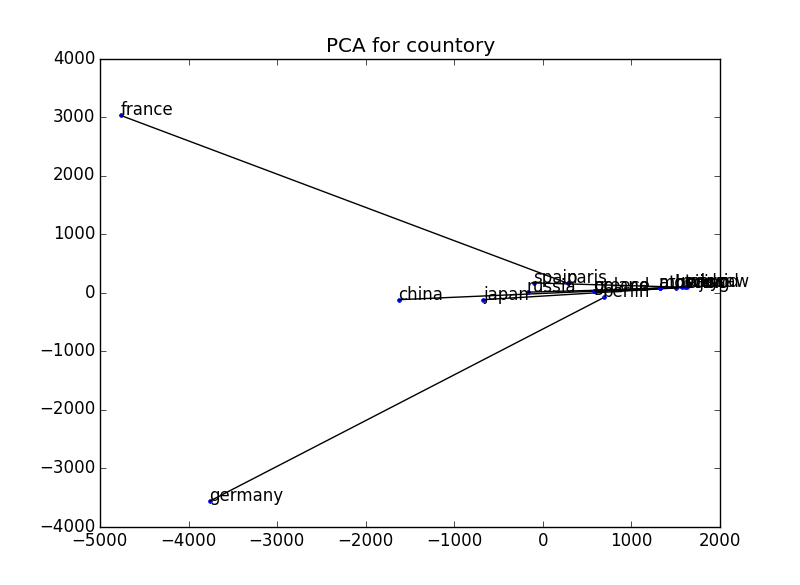 229 73 Abmessungen → 2 Abmessungen
229 73 Abmessungen → 2 Abmessungen
- Bei der Visualisierung wird die Dimension des Vektors mithilfe der Hauptkomponentenanalyse auf 2 Dimensionen reduziert. Referenz: http://breakbee.hatenablog.jp/entry/2014/07/13/191803
Beispiel in einem Buch:


Versuchen Sie Anwendung 3: Berechnung der Bedeutung
Wenn die Bedeutung richtig als Vektor ausgedrückt wird, sollten Sie in der Lage sein, die Bedeutung zu berechnen.
・ König - Mann + Frau = Königin (F: Was ist der König für Männer für Frauen? A: Königin) ・ Paris - Frankreich + Italien = Roma (F: Was ist Paris für Frankreich für Italien? A: Rom)
Wenn Sie den Vektor wie oben addieren oder subtrahieren, können Sie das Ergebnis dieser Berechnung tatsächlich erhalten.
Andere konventionelle Methoden vs word2vec richtige Informationen
Laut einer Studie von Mikolov et al. Zeigten Tests wie "Athene - Griechenland + Oslo ist korrekt, wenn es Norwegen wird", um die Fähigkeit dieser Addition und Subtraktion zu messen, dass die korrekte Antwortrate mit der herkömmlichen Methode 9% oder 23% betrug. Das in word2vec implementierte Skip-Gramm-Modell scheint jedoch die Genauigkeitsrate auf 55% erheblich verbessert zu haben. ”
Auszug :: Yasukazu Nishio. “Verarbeitung natürlicher Sprache durch word2vec”
Wie word2vec funktioniert
Abkürzung
Bild davon, wie word2vec funktioniert
Dieses Bild und diese Beschreibung haben mir sehr geholfen.
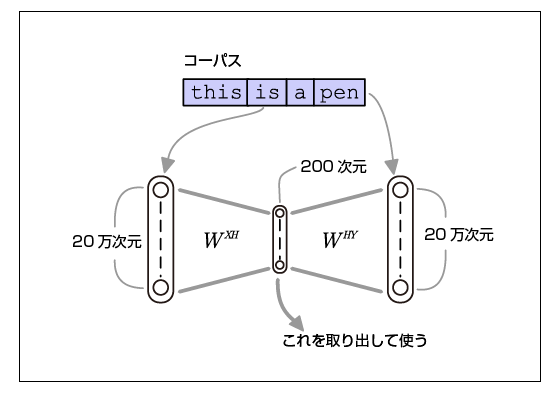
"Die Funktion besteht darin, die gleichen Daten sowohl in die Eingabe als auch in die Ausgabe einzufügen. Wenn Sie ein solches Lernen durchführen, denken Sie möglicherweise, dass ein langweiliges neuronales Netzwerk (einheitliche Zuordnung), das dasselbe ausgibt wie die Eingabe, wächst. Der Schlüssel zu dieser Methode besteht darin, dass die Größe der verborgenen Ebene so klein eingestellt ist, dass keine konstante Zuordnung erlernt werden kann. Daher lernt Autoencoder, so viele Informationen wie möglich in eine begrenzte verborgene Schicht zu packen, und als Ergebnis ist das Gewicht der Eingabeebene → verborgene Schicht eine niedrigdimensionale Vektordarstellung der Eigenschaften der Eingabedaten. Das Problem, das das neuronale Netzwerk lernt, ist nicht das Problem, das Sie lösen möchten, aber der verteilte Ausdruck, den das neuronale Netzwerk erzeugt, indem das neuronale Netzwerk das schwierige Problem lösen lässt, ist wertvoll. Unterlassung Wenn die Anzahl der Vokabeln 200.000 Dimensionen beträgt, hat die mittlere Ebene mit 200 Dimensionen nur 1/1000 Dimensionen. In dieser schwierigen Situation wird gelernt, um die Genauigkeitsrate des Vorhersageproblems "Errate die umgebenden Wörter" zu erhöhen. Auf diese Weise wird die Umwandlung so durchgeführt, dass Wörter mit einer ähnlichen "Häufigkeit des Auftretens der umgebenden Wörter" zu Vektoren mit geringem Abstand werden. ”
Auszug :: Yasukazu Nishio. “Verarbeitung natürlicher Sprache durch word2vec”
Implementierung
・ Um word2vec: gensim ・ Zum Zeitpunkt der Visualisierung wird die Dimension des Vektors mithilfe der Hauptkomponentenanalyse auf zwei Dimensionen reduziert. Referenz: http://breakbee.hatenablog.jp/entry/2014/07/13/191803