[PYTHON] Implementierung der Gradientenmethode 1
Einführung
Es ist ungefähr einen Monat her, seit ich diesen Tag im Adventskalender gebucht habe, und es ist fast Weihnachten. Irgendwie habe ich das Gefühl, dass dieses Jahr schneller als gewöhnlich vergangen ist. Dieses Mal werde ich für diejenigen, die Python bis zu einem gewissen Grad schreiben können, aber nicht wissen, welche Art der Implementierung konkret durch maschinelles Lernen erfolgen wird, dies auf leicht verständliche Weise als Weihnachtsgeschenk von mir senden. Da der theoretische Teil und der praktische Teil gemischt sind, nehmen Sie bitte nur den Teil auf und essen Sie ihn, den Sie verstehen können. Vielleicht können Sie immer noch ein Gefühl dafür bekommen. Ein intuitives Bild des maschinellen Lernens im vorherigen Artikel finden Sie auch unter hier.
Was ist die Gradientenmethode?
Die Gradientenmethode ist eine der zur Optimierung verwendeten Methoden. Diese Gradientenmethode wird häufig verwendet, um das Gewicht $ W $ zu ermitteln, das die optimale Ausgabe liefert.
Insbesondere wird vorheriger quadratischer Summenfehler angezeigt
Eine der zu minimierenden Methoden ist die Gradientenmethode, bei der mithilfe der Differenzierung der Mindestwert ermittelt wird.
Implementierung der Differenzierung
Beginnen wir mit der Implementierung einer eindimensionalen Differenzierung.
Funktion von $ x $ Differenzierung von $ f (x) $ $ f ^ {\ prime} (x) $
numerical_differentiation.py
import numpy as np
import matplotlib.pylab as plt
def nu_dif(f, x):
h = 1e-4
return (f(x + h) - f(x))/(h)
def f(x):
return x ** 2
x = np.arange(0.0, 20.0, 0.1)
y = nu_dif(f, x)
plt.xlabel("x")
plt.ylabel("y")
plt.plot(x,y)
plt.show()
Der Graph unter $ y = f \ ^ {\ prime} (x) = 2x $ sollte nun gezeichnet werden. [3382ED86-34E1-4011-BE99-ADE6A8E1E530.jpeg](https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/535913/d1b7deeb-6e5f-6070-6bb3-b234e3b27432 .jpeg)
$ h $ ist ungefähr $ 10 \ ^ {-4} $, um Rundungsfehler zu vermeiden.
Bonus
In der obigen numerischen Berechnung ist $$ f ^ {\ prime} (x) = \ lim_ {h → 0} \ frac {f (x + h) - f (x - h)} {2h} \ tag {4} $ Berechnungen wie $ verbessern die Genauigkeit.
def nu_dif(f, x):
h = 1e-4
return (f(x + h) - f(x-h))/(2 * h)
Teilweise Differenzierung
Nachdem wir die eindimensionale Differenzierung implementiert haben, implementieren wir die mehrdimensionale Differenzierung. Hier werden wir der Einfachheit halber in zwei Dimensionen unterscheiden. Für eine Funktion mit zwei Variablen $ f (x, y) $ ist die Differenzierung zwischen $ x und y $, dh die partielle Differenzierung $ f_x, f_y 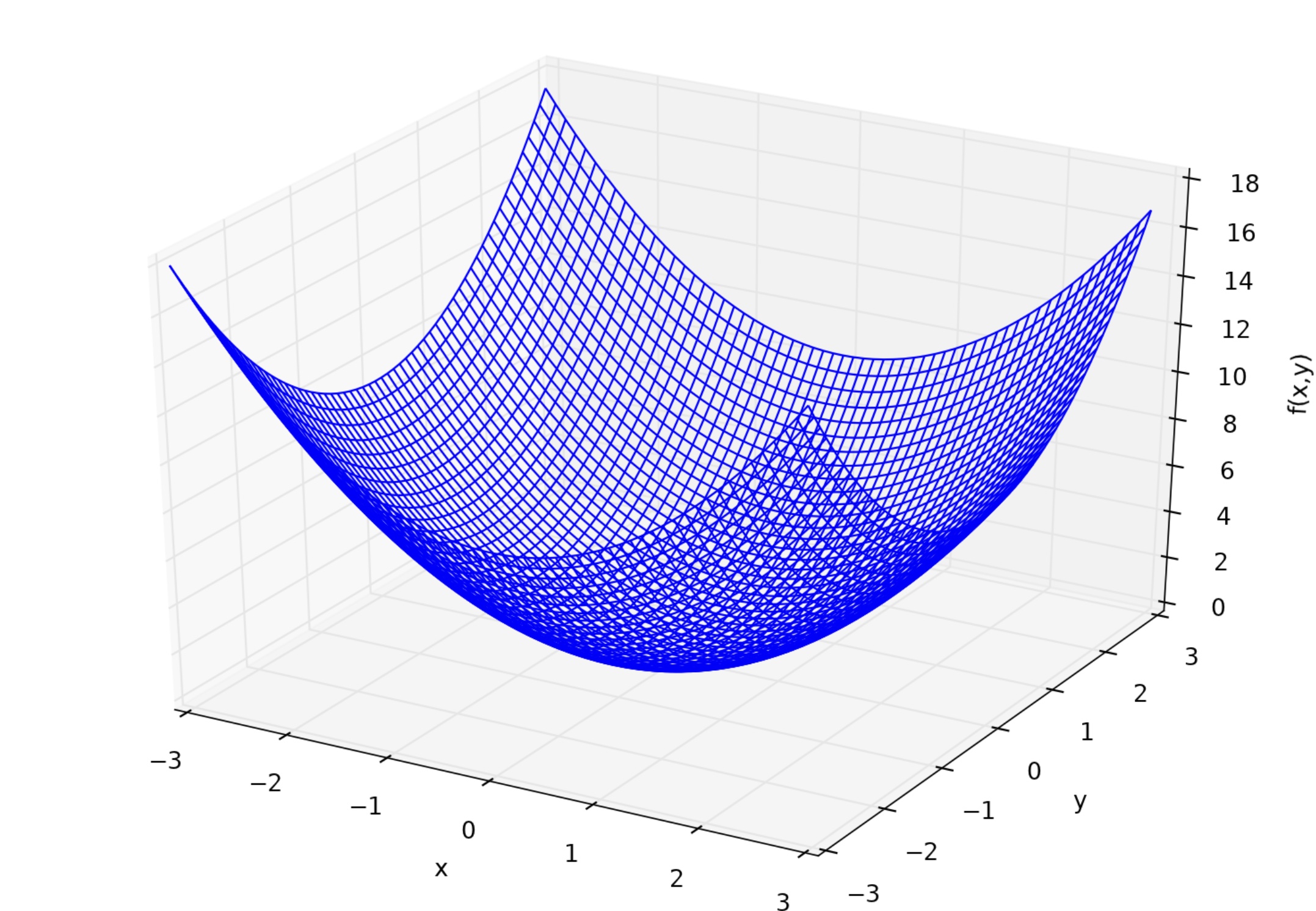
Lassen Sie uns nun auch eine teilweise Differenzierung implementieren. $ f_x = 2x, f_y = 2y $.
numerical_differentiation_2d.py
def f(x, y):
return x ** 2 + y ** 2
def nu_dif_x(f, x, y):
h = 1e-4
return (f(x + h, y) - f(x - h, y))/(2 * h)
def nu_dif_y(f, x, y):
h = 1e-4
return (f(x, y + h) - f(x, y - h))/(2 * h)
Gradient
Der Gradientenoperator (nabla) für die dreivariable Funktion $ f (x, y, z) $ in dreidimensionalen kartesischen Koordinaten ist
Implementierung der Gradientenmethode
Danke für deine harte Arbeit. Dies deckt alle mathematischen Grundlagen ab, die zur Implementierung einer einfachen Gradientenmethode erforderlich sind. Lassen Sie uns nun ein Programm implementieren, das automatisch den Mindestwert der Funktion ermittelt.
Beliebiger Punkt Ausgehend von $ \ boldsymbol {x} ^ {(0)} $ $$ \ boldsymbol {x} ^ {(k + 1)} = \ boldsymbol {x} ^ {(k)} - \ eta \ nabla Schieben Sie nach unten zu dem Punkt $ \ boldsymbol {x} ^ *
Implementieren Sie nun die Gradientenmethode, um den Punkt $ \ boldsymbol {x} ^ * = (x ^ *, y ^ *) $ zu finden, der den Mindestwert von $ f (x, y) = x ^ 2 + y ^ 2 $ ergibt. Machen wir das. Wie Sie bereits wissen, sind Sie erfolgreich, wenn Sie $ \ boldsymbol {x} ^ * = (0,0) $ erhalten.
numerical_gradient.py
#Gibt den Gradienten von f zurück
def numerical_gradient(f, x):
h = 1e-4
grad = np.zeros_like(x)
for i in range(x.size):
tmp = x[i]
x[i] = tmp + h
f1 = f(x)
x[i] = tmp - h
f2 = f(x)
grad[i] = (f1 - f2)/(2 * h)
x[i] = tmp
return grad
#Gradientenmethode
def gradient_descent(f, x, lr = 0.02, step_num = 200):
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x
#Definiere f
def f(x):
return x[0] ** 2 + x[1] ** 2
#Ausgabe x
print(gradient_descent(f, np.array([10.0, 3.0])))
Das Ergebnis der Einstellung von $ \ boldsymbol {x} ^ {(0)} = (10,3), \ eta = 0,02, k = 0,1, \ ldots, 199 $ [ 0.00284608 0.00085382] Sollte ausgegeben werden. Da sowohl $ x als auch y $ ungefähr $ 10 ^ {-3} $ sind, kann man sagen, dass sie fast $ 0 $ sind.
Gradientenmethode beim maschinellen Lernen
Der Umriss und die Nützlichkeit der Gradientenmethode wurden oben erläutert. Beim maschinellen Lernen ist der Schlüssel, wie das optimale Gewicht $ \ boldsymbol {W} $ gefunden wird. Das optimale Gewicht ist die Verlustfunktion $ \ boldsymbol {W} $, die $ L $ minimiert. Die Gradientenmethode kann als eine der Methoden verwendet werden, um dies zu erhalten. Das Gewicht $ \ boldsymbol {W} $ ist beispielsweise eine $ 2 \ times2 $ -Matrix
\boldsymbol{W}=\left(\begin{array}{cc}
w_{11} & w_{12} \\
w_{21} & w_{22}
\end{array}\right) \tag{9}
Für die Verlustfunktion $ L $ in
\nabla L \equiv \frac{\partial L}{\partial \boldsymbol {W}}\equiv\left(\begin{array}{cc}
\frac{\partial L}{\partial w_{11}} & \frac{\partial L}{\partial w_{12}} \\
\frac{\partial L}{\partial w_{21}} & \frac{\partial L}{\partial w_{22}}
\end{array}\right) \tag{10}
Berechnen Sie
Zusammenfassung
Vielen Dank, dass Sie so weit gelesen haben. Dieses Mal begann ich mit einer einfachen eindimensionalen Differentialimplementierung mit Python und erweiterte sie auf mehrere Dimensionen. Dann stellte ich den Gradientenoperator Nabla vor und lernte die Gradientenmethode, um den Minimalwert einer beliebigen Funktion damit zu ermitteln. Und schließlich habe ich Ihnen gesagt, dass die Verwendung der Gradientenmethode die Verlustfunktion reduzieren, dh die Genauigkeit des maschinellen Lernens verbessern kann. Obwohl die so erhaltenen Gewichte oft extrem sind, haben wir auch festgestellt, dass das Problem darin besteht, dass die Verlustfunktion nicht minimiert oder optimiert wird. Ab dem nächsten Mal werde ich einen anderen Ansatz für dieses Problem versuchen.
abschließend
Dieses Mal hatte ich die Gelegenheit, mich von einem Freund vorstellen zu lassen und in diesem Adventskalender 2019 der Chiba University zu posten. Es war ein wenig schwierig, weil ich es aus einem ziemlich rudimentären Teil zusammenfasste, aber ich konnte länger als gewöhnlich schreiben und fühlte ein Gefühl der Müdigkeit und Leistung. Zusätzlich zu meinen Posts veröffentlichen verschiedene Leute wundervolle Posts zu verschiedenen Themen auf verschiedenen Ebenen. Schauen Sie also bitte mal rein.
Recommended Posts