[PYTHON] Speichern Sie Pandas-Daten mit Cloud Pak for Data (Watson Studio) im Excel-Format in Datenbeständen.
Speichern von Dateien in Datenbeständen eines Analyseprojekts mithilfe von project_lib [Ein weiterer Artikel](https://qiita.com/ttsuzuku/items/eac3e4bedc020da93bc1#%E3%83%87%E3%83%BC%E3% 82% BF% E8% B3% 87% E7% 94% A3% E3% 81% B8% E3% 81% AE% E3% 83% 87% E3% 83% BC% E3% 82% BF% E3% 81% AE% E4% BF% 9D% E5% AD% 98-% E5% 88% 86% E6% 9E% 90% E3% 83% 97% E3% 83% AD% E3% 82% B8% E3% 82% A7 Ich habe es in% E3% 82% AF% E3% 83% 88) geschrieben, aber es waren einige Tricks erforderlich, um es im Excel-Format zu speichern. Nachdem Sie verschiedene Dinge untersucht haben, dieser Artikel von stackoverflow Es war gültig.
Hier ist ein Beispiel, das ich tatsächlich ausprobiert habe.
Pandas Datenrahmen verwendet
#Beispieldaten Iris
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['iris_type'] = iris.target_names[iris.target]
df.head()
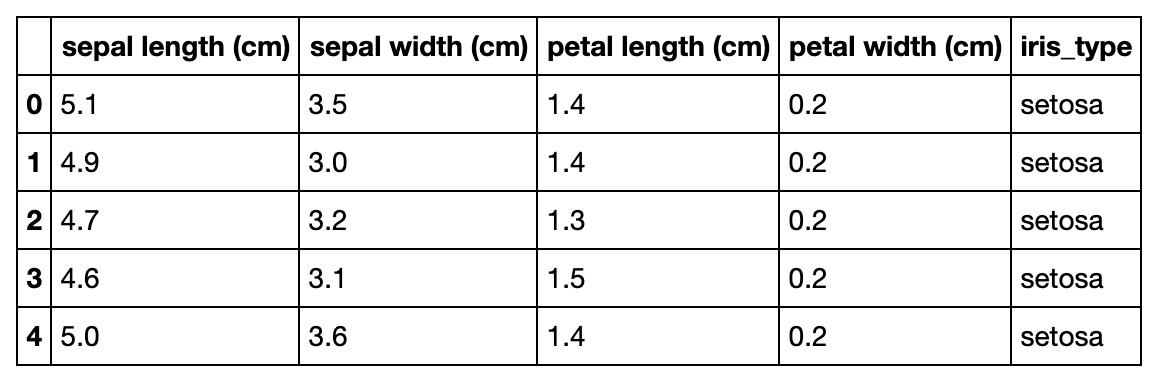
Speichern wir diese Daten im Excel-Format. Der Flow wird einmal als Excel-Datei in der Umgebung mit pandas.to_excel gespeichert.
#Einmal als Excel-Datei in die Umgebung ausgeben
filename = 'iris.xlsx'
df.to_excel(filename, index=False)
!pwd
!ls -l
# -output-
# /home/wsuser/work
# total 12
# -rw-r-----. 1 wsuser watsonstudio 8737 May 28 06:53 iris.xlsx
Lesen Sie als Io-Byte-Stream und speichern Sie ihn mit project_lib in Ihrem Analyseprojekt.
from project_lib import Project
project = Project.access()
import io
with open(filename, 'rb') as z:
data = io.BytesIO(z.read())
project.save_data(filename, data, set_project_asset=True, overwrite=True)
Stellen Sie sicher, dass es im Analyseprojekt gespeichert wurde.

Für alle Fälle werde ich es herunterladen und mir den Inhalt ansehen.
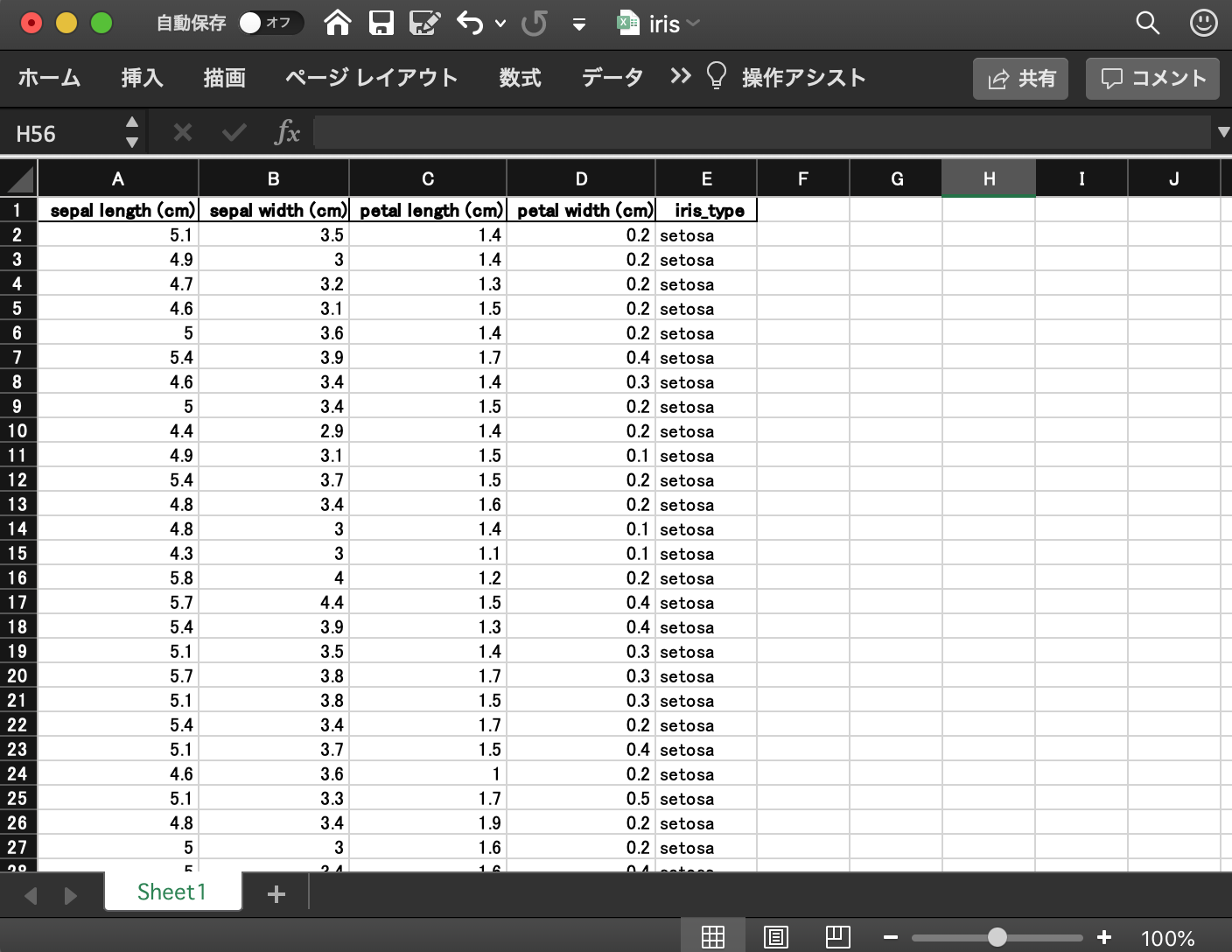 Sie haben 150 Zeilen Iris-Daten erfolgreich im Excel-Format gespeichert.
Sie haben 150 Zeilen Iris-Daten erfolgreich im Excel-Format gespeichert.