[Python / Chrome] Grundeinstellungen und Operationen zum Scraping
Einführung
Früher habe ich mit VBA gekratzt, aber ich weiß nicht, wie lange Internet Explorer verwendet werden kann. Also fing ich an, ** Chrome ** mit ** Python ** zu kratzen. Die Umgebung ist ** Windows **.
Es ist jetzt mehr Inhalt, aber ich werde die Grundlagen, die Sie beachten sollten (wahrscheinlich den Inhalt, den Sie in ein paar Monaten vergessen werden), als persönliche Erinnerung aufschreiben.
**
1. Installieren Sie Selen
Installieren Sie zunächst ein Browser-Steuerungspaket namens selenium in Python.
Sie können es installieren, indem Sie den Befehl py -m pip install selenium an der Eingabeaufforderung wie folgt eingeben:
Eingabeaufforderung
>py -m pip install selenium
Collecting selenium
Downloading selenium-3.141.0-py2.py3-none-any.whl (904 kB)
|████████████████████████████████| 904 kB 1.1 MB/s
Collecting urllib3
Downloading urllib3-1.25.11-py2.py3-none-any.whl (127 kB)
|████████████████████████████████| 127 kB 939 kB/s
Installing collected packages: urllib3, selenium
Successfully installed selenium-3.141.0 urllib3-1.25.11
Einzelheiten, einschließlich der Installation von Python selbst, finden Sie unter hier.
2. Laden Sie WebDriver herunter
Als nächstes benötigen Sie ** WebDriver ** für Ihren Browsertyp.
● Nachschlagewerke [Hidekatsu Nakajima "Buch, das Excel, E-Mail und das Web mit Python automatisiert" SB Creative](https://www.amazon.co.jp/Python%E3%81%A7Excel%E3%80%81%E3%83% A1% E3% 83% BC% E3% 83% AB% E3% 80% 81Web% E3% 82% 92% E8% 87% AA% E5% 8B% 95% E5% 8C% 96% E3% 81% 99% E3% 82% 8B% E6% 9C% AC-% E4% B8% AD% E5% B6% 8B% E8% 8B% B1% E5% 8B% 9D / dp / 4815606390)
2-1. Website herunterladen
Öffnen Sie die Seite zum Herunterladen von Chrome-Treibern (https://sites.google.com/a/chromium.org/chromedriver/downloads) wie unten gezeigt.
 Im roten Rahmen oben befinden sich drei Versionen (87, 86, 85) des Chrome-Treibers.
Von diesen laden Sie die Version herunter, die der aktuell verwendeten Chrome-Version entspricht (siehe nächster Abschnitt).
Im roten Rahmen oben befinden sich drei Versionen (87, 86, 85) des Chrome-Treibers.
Von diesen laden Sie die Version herunter, die der aktuell verwendeten Chrome-Version entspricht (siehe nächster Abschnitt).
Sie können den WebDriver-Link für jeden Browser im Abschnitt "Treiber" von "PyPI / Selenium" überprüfen.
2-2. Überprüfung der Chrome-Version
Sie können die Version überprüfen, indem Sie "Über Google Chrome (G)" unter "Hilfe (H)" im Chrome-Browsermenü öffnen.
 In meiner Umgebung ist die Version von Chrome "86". Klicken Sie daher auf der zuvor erwähnten Download-Site auf den entsprechenden "Chrome-Treiber 86.0.4240.22".
In meiner Umgebung ist die Version von Chrome "86". Klicken Sie daher auf der zuvor erwähnten Download-Site auf den entsprechenden "Chrome-Treiber 86.0.4240.22".
2-3. Erwerb von WebDriver
Wenn Sie einen Bildschirm wie den folgenden sehen, klicken Sie auf den Chrome-Treiber für Windows, um ihn zu installieren.
 Wenn Sie die heruntergeladene Datei entpacken, erhalten Sie einen WebDriver mit dem Namen "chromedriver.exe" wie folgt.
Wenn Sie die heruntergeladene Datei entpacken, erhalten Sie einen WebDriver mit dem Namen "chromedriver.exe" wie folgt.
 Sie verwenden diesen Treiber im selben Ordner wie die Python-Quellcodedatei (Sie können ihn in einem anderen Ordner ablegen und den Pfad im Quellcode angeben).
Sie verwenden diesen Treiber im selben Ordner wie die Python-Quellcodedatei (Sie können ihn in einem anderen Ordner ablegen und den Pfad im Quellcode angeben).
3. Beschreibung des Quellcodes
Hier ist der Code, der die Yahoo-Site öffnet und eine Suche durchführt:
Test01.py
import time
from selenium import webdriver
driver = webdriver.Chrome() #Erstellen Sie eine Instanz von WebDriver
driver.get('https://www.yahoo.co.jp/') #Öffnen Sie den Browser, indem Sie die URL angeben
time.sleep(2) #Warten Sie 2 Sekunden
search_box = driver.find_element_by_name('p') #Identifizieren Sie das Suchfeld anhand des Namensattributs
search_box.send_keys('Schaben') #Geben Sie Text in das Suchfeld ein
search_box.submit() #Suchbegriff senden (wie beim Drücken der Suchtaste)
time.sleep(2) #Warten Sie 2 Sekunden
driver.quit() #Browser schließen
Dies ist eine geringfügige Änderung des Codes auf der ChromeDriver-Site (http://chromedriver.chromium.org/getting-started). Bei der Ausführung wird der Browser (Chrome) gestartet und das Wort "Scraping" wird von der Yahoo-Site gesucht.
Im Folgenden werde ich eine kurze Erklärung hinterlassen.
3-1. Importieren der Bibliothek
Sample.py
import time
from selenium import webdriver
Grundsätzlich wird es durch die Entsprechung von "import [Bibliotheksname]" beschrieben.
Die erste Zeile importiert die Standardbibliothek time.
Die zweite Zeile importiert eine Bibliothek namens "Webdriver" aus dem soeben installierten Paket "Selen".
3-2. Erstellen einer Instanz von WebDriver
3-2-1. Wenn der Treiber im selben Ordner wie der Quellcode gespeichert ist
Wenn ChromeDriver im selben Ordner wie der Quellcode gespeichert ist, können Sie eine Instanz von WebDriver erstellen, indem Sie wie folgt schreiben.
Sample.py
driver = webdriver.Chrome()
3-2-2. Wenn der Treiber in einem anderen Ordner als dem Quellcode gespeichert wird
Wenn der Treiber eine Ebene tiefer im Verzeichnis (Ordner) gespeichert ist, schreiben Sie wie folgt.
Sample.py
driver = webdriver.Chrome('Driver/chromedriver')
Der obige "Treiber" ist der Verzeichnisname (Ordnername).
3-2-3 Informationen zu Instanzvariablennamen
Beachten Sie, dass die Variable "Treiber" (natürlich) alles sein kann. Es ist in Ordnung, die Variable wie folgt auf "d" zu setzen:
Sample.py
d = webdriver.Chrome()
3-3 Öffnen Sie den Browser, indem Sie die URL angeben
Sie können die angegebene Site öffnen, indem Sie "[Instanzname] .get ([URL-Name])" wie folgt schreiben.
Sample.py
driver.get('https://www.yahoo.co.jp/')
3-4 Holen Sie sich den Knoten
3-4-1. HTML überprüfen
Um die Suche durchzuführen, müssen Sie die Position des Textfelds lesen, um den Suchbegriff einzugeben, z. B.:
 Dies wird durch Betrachten des HTML-Codes der WEB-Seite erreicht.
Um den HTML-Code im Textfeld anzuzeigen, klicken Sie mit der rechten Maustaste darauf und wählen Sie Validieren.
Dies wird durch Betrachten des HTML-Codes der WEB-Seite erreicht.
Um den HTML-Code im Textfeld anzuzeigen, klicken Sie mit der rechten Maustaste darauf und wählen Sie Validieren.
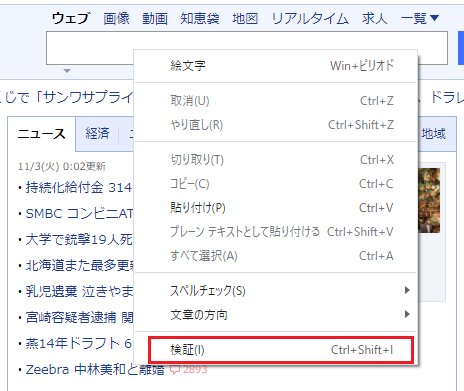 Dann wird der HTML-Code der Site auf der rechten Seite angezeigt.
Der Teil, der blau ist, ist der HTML-Code des relevanten Teils.
Dann wird der HTML-Code der Site auf der rechten Seite angezeigt.
Der Teil, der blau ist, ist der HTML-Code des relevanten Teils.
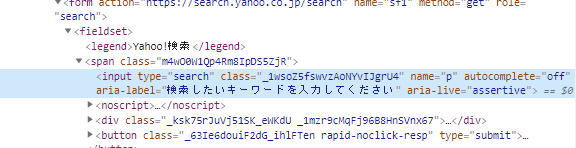 In diesem HTML werden Attributwerte wie "Typ", "Klasse" und "Name" im Tag "Eingabe" angegeben.
Anhand dieser Tag-Namen und Attributwerte als Hinweise geben Sie die erforderlichen Teile (Knoten) an.
In diesem HTML werden Attributwerte wie "Typ", "Klasse" und "Name" im Tag "Eingabe" angegeben.
Anhand dieser Tag-Namen und Attributwerte als Hinweise geben Sie die erforderlichen Teile (Knoten) an.
Der gleiche Tag-Name und Attributwert können dupliziert werden. Suchen Sie daher zuerst den eindeutigen (es gibt nur einen auf der Seite). Bei der Überprüfung stellte ich fest, dass es auf der Seite nur eine der folgenden "Klassen" und "Namen" gibt.
class="_1wsoZ5fswvzAoNYvIJgrU4"
name="p"
3-4-2. Quellcode zum Abrufen des Knotens
Hier erhalten Sie unter Verwendung des einfacheren Attributwerts von "Name" den erforderlichen Teil (Knoten) mit dem folgenden Code.
Da search_box eine Variable ist, kann es sich um einen Alias handeln.
Sample.py
search_box = driver.find_element_by_name('p')
Wenn Sie einen Knoten mit dem Attributwert "Name" erhalten möchten, beschreiben Sie ihn mit der Anordnung "[Instanzname] .find_element_by_name ([Attributwert])".
Um es mit dem Attributwert "class" zu erhalten, schreiben Sie wie folgt.
Sample.py
search_box = driver.find_element_by_class_name('_1wsoZ5fswvzAoNYvIJgrU4')
3-4-3. Methode zum Abrufen von Knoten
Es gibt verschiedene Methoden, um den Knoten neben "Name" und "Klasse" abzurufen (diese Site). Referenz).
3-4-3-1. Beim Erwerb eines einzelnen Knotens
| Methode | Akquisitionsziel |
|---|---|
| find_element_by_id | ID-Name (Attributwert) |
| find_element_by_name | Name Name (Attributwert) |
| find_element_by_xpath | Holen Sie sich mit XPath |
| find_element_by_link_text | Holen Sie sich mit Link-Text |
| find_element_by_partial_link_text | Holen Sie sich als Teil des Link-Textes |
| find_element_by_tag_name | Tag-Name (Element) |
| find_element_by_class_name | Klassenname (Attributwert) |
| find_element_by_css_selector | Holen Sie sich mit Selektor |
Beim Abrufen einer einzelnen Nummer wird nur der erste gefundene Knoten abgerufen, auch wenn es einen mit demselben Namen gibt.
Wenn Sie mit XPath wie mir nicht vertraut sind, lesen Sie bitte diesen Artikel "Erforderlich zum Erstellen eines Crawlers! Zusammenfassung der XPATH-Notation". .. Ich denke, es wird sehr praktisch sein, wenn Sie es meistern können.
3-4-3-2. Beim Erwerb mehrerer Knoten (Liste)
| Methode | Akquisitionsziel |
|---|---|
| find_elements_by_name | ID-Name (Attributwert) |
| find_elements_by_xpath | Name Name (Attributwert) |
| find_elements_by_link_text | Holen Sie sich mit Link-Text |
| find_elements_by_partial_link_text | Holen Sie sich als Teil des Link-Textes |
| find_elements_by_tag_name | Tag-Name (Element) |
| find_elements_by_class_name | Klassenname (Attributwert) |
| find_elements_by_css_selector | Holen Sie sich mit Selektor |
Beim Abrufen einer einzelnen Nummer werden alle Knoten mit demselben Namen im Listenformat abgerufen.
In der ursprünglichen HTML-Beschreibung gibt es Regeln wie einen "ID-Namen" auf einer Seite und mehrere "Klassennamen" und "Namensnamen". Einige Websites haben jedoch mehrere ID-Namen. Daher gibt es mehrere (Listen-) Erfassungsmethoden wie "find_elements_by_name".
Bei der Mehrfacherfassung ist es erforderlich, bis zur Elementnummer wie folgt anzugeben, da die Knoten im Listenformat erfasst werden.
Sample.py
search_box = driver.find_elements_by_name('p')[0]
3-4-4. [Referenz] Ruft den Knoten (unter dem untergeordneten Element) des Knotens ab
Es ist einfach, Code zu schreiben, wenn Sie einen eindeutigen ID-Namen haben, wenn Sie einen Knoten erhalten, aber manchmal ist es nicht so praktisch. In einem solchen Fall ist es häufig der Fall, dass ein großer Bereich von Knoten einmal angegeben wird und die Knoten seiner untergeordneten Elemente (Enkelelemente) angegeben werden, beispielsweise durch Ausführen einer verfeinerten Suche.
Das Verfahren zum Abrufen des Knotens des Knotens kann durch einfaches Verketten der Verfahren wie folgt realisiert werden.
Sample.py
search_box = driver.find_element_by_tag_name('fieldset').find_element_by_tag_name('input')
Es ist auch möglich, die Variablen separat zu schreiben (siehe unten).
Sample.py
search_box1 = driver.find_element_by_tag_name('fieldset')
search_box = search_box1.find_element_by_tag_name('input')
In der zweiten Verfeinerung werden die Knoten unter dem untergeordneten Element als Ziel ausgewählt.
3-5 Geben Sie Text in das Suchfeld ein
Um Text in das Suchfeld einzugeben, verwenden Sie die Methode "send_keys" und schreiben Sie: Hier wird das Wort "Scraping" in das Textfeld eingegeben.
Sample.py
search_box.send_keys('Schaben')
3-6 Suche durchführen
Sie können die Methode "submit" wie folgt verwenden, um den im Suchformular eingegebenen Text an den Website-Server zu senden (dh die Suche durchzuführen).
Sample.py
search_box.submit()
Dies bedeutet, dass Sie HTML-Formulardaten an den Server senden.
Sie können das gleiche Ergebnis erzielen, indem Sie einfach den unten gezeigten Befehl "Klicken Sie auf die Suchschaltfläche" ausführen.
Sample.py
search_box = driver.find_element_by_class_name('PHOgFibMkQJ6zcDBLbga8').click()
Dies bedeutet, dass der Knoten durch den Klassennamen für die Suchschaltfläche erfasst wird und die Suchschaltfläche durch die Klickmethode angeklickt wird.
3-7. Schließen Sie den Browser
Sie können den geöffneten Browser mit dem folgenden Code schließen.
Sample.py
driver.quit()
Sind die oben genannten "grundlegenden Grundlagen"?
Während ich dies schrieb, fragte ich mich, wie man "innerText" und "OuterHTML" bekommt, aber auch in diesem Bereich wurden normalerweise Methoden vorbereitet.
Python-Scraping wird von vielen Leuten verwendet, daher scheint es ziemlich einfach zu sein.
Recommended Posts