[PYTHON] Generierung von Charakterdialogen und Tonumwandlung durch CVAE
1. 1. Überblick
Guten Abend. Dieses Mal habe ich, wie der Titel schon sagt, versucht, den Dialog des Charakters mit CVAE (Conditional Variational Auto-Encoder) zu generieren. Ich versuche auch, den Ton des Charakters mit der gleichen Methode zu ändern.
- 170624: Es gab ein Problem mit dem Github-Code, daher wurde es behoben.
2. In Verbindung stehender Artikel (bestehende Forschung)
Es gibt viele Artikel, die im RNN-System einen Dialog erzeugen. [Evangelion] Versuchen Sie, mit Deep Learning automatisch Asuka-ähnliche Linien zu generieren
Diese Artikel hatten die folgenden Herausforderungen:
- Die Lerndaten des Charakters sind klein (höchstens 1000 Sätze. Wenn Sie außerdem den Dialog anderer Charaktere mit den Lerndaten mischen, funktioniert dies nicht.)
- Da nur die vom Zeichen bereits gesprochenen Zeilen für die Trainingsdaten verwendet werden, spricht das Zeichen keine Wörter aus, die nicht in den Zeilen erscheinen.
Ich möchte diese Probleme mit CVAE lösen. Da CVAE die Merkmale jeder Kategorie (in diesem Fall Zeichen) lernen kann, ist es möglich, die Genauigkeit der Dialoggenerierung für jedes Zeichen zu verbessern, selbst wenn der Dialog verschiedener Zeichen zu den Lerndaten hinzugefügt wird.
3. 3. Modell-
Nach dem Artikel, den ich das letzte Mal geschrieben habe: "Zeicheneinstellungen mit VAE vornehmen.", verwende ich auch LST MVAE als Modell. Die Modelle LSTM, VAE und Encoder-Decoder werden hier nicht ausführlich behandelt. Wenn Sie mit ihnen nicht vertraut sind, lesen Sie bitte die folgenden Artikel.
- Übersicht über das LSTM-Netzwerk
- Auto-Encoding Variational Bayes [arXiv:1312.6114]
- Chainer, RNN und maschinelle Übersetzung
VAE ist ein Modell, das DeepNeuralNet in ein Generierungsmodell verwandelt hat. Es gab jedoch das Problem, dass nicht gesteuert werden konnte, welche Art von Daten generiert wurden. CVAE hat dieses Problem gelöst.
CVAE ist ein Modell, das VAE mit einem Kategorievektor kombiniert (ein Vektor, der eine Kategorie ausdrückt, die auch ein Parameter ist).
Als Anwendungsbeispiel für VAE wird in diesem Artikel die Bilderzeugung von MNIST (Zeichenerkennung von Zahlen) vorgestellt.

In der normalen VAE werden Zahlen zufällig generiert, in der CVAE können Sie jedoch Zahlen von 0 bis 9 angeben, die generiert werden sollen.
Mit der gleichen Methode habe ich überprüft, ob es möglich ist, ein Zeichen anzugeben und einen Dialog zu generieren.
Die Konfiguration des CVAE-Modells entspricht im Wesentlichen der des LST MVAE in Zuvor geschriebener Artikel.
Fügen Sie einfach den Kategorievektor zu den Anfangswerten der verborgenen Schichten des Codierers und Decodierers hinzu.
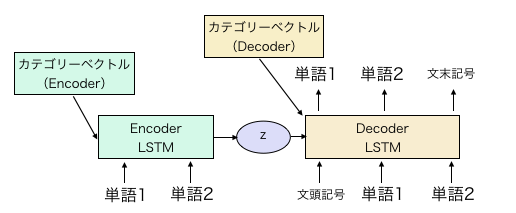
Eine einfache Abbildung zeigt das oben gezeigte Modell. Der Kategorievektor in der obigen Abbildung ist ein Parameter, der für jedes Zeichen geändert und gelernt werden muss. Zum Zeitpunkt des Lernens wird es sowohl in den Codierer als auch in den Decodierer eingegeben, aber zum Zeitpunkt der Generierung kann der Dialog des konfrontierten Zeichens durch Kombinieren der Verteilung des Zwischenausdrucks z und des Kategorievektors des Decodierers generiert werden.
Der Encoder ist bidirektionales LSTM und die Abmessung jeder verborgenen Schicht beträgt 300. Die Abmessung der Mittelschicht z beträgt 600. Die verborgene Schichtdimension des Decoders ist auf 600 eingestellt. Der Wortvektor ist 300 sowohl für den Codierer als auch für den Decodierer. Die morphologische Analyse wird nach Satzstücken durchgeführt, und die Anzahl der Wörter beträgt ungefähr 16000.
Später war ich mir über Folgendes nicht sicher, aber ich habe den Kategorievektor sowohl für die versteckten Schichten h als auch c von LSTM erstellt. Da der Encoder bidirektional ist, gibt es in 2x3 insgesamt 6 Arten von Kategorievektoren. Die Abmessungen entsprechen den Abmessungen der verborgenen Schicht (300 für Encoder, 600 für Decoder). Der Code ist wie gewohnt https://github.com/ashwatthaman/LSTMVAE Es wird in platziert. src/each_case/sampleCVAESerif.py Der Code zum Ausführen der bedingten VAE ist in geschrieben. Diesmal können die Daten jedoch nicht aus urheberrechtlicher Sicht freigegeben werden Es werden nur Dummy-Daten platziert.
4. Daten
Dies wurde von den folgenden Websites gecrawlt.
- Was du lieben solltest - Einführung von Anime-Zeilen-
- Anime Transcripts @ Anime in Englisch Insgesamt werden 218 Zeichen und etwa 120.000 Sätze gelernt. Die obigen 120.000 Sätze verwenden nur die Zeilen von Zeichen mit mehr als 100 Zeilen.
5. Ergebnis
5.1. Satzgenerierung für jedes Zeichen
Das Ergebnis. Das, was ich am besten gesagt habe (glaube ich), war Rei Ayanamis Linie, also werde ich es hier posten.
Es ist eine Lüge. Ich bin der einzige.
Ah, ich sollte die erste Maschine beschützen
Ich glaube ich habe mich gesucht.
Ikari hat sehr versagt.
Am Leben
Ich weiß es nicht. Ich mache den ersten Maschinenausfall.
Es hat ein Gesicht namens Rei Ayanami.
...Haus. Dann...Nur für Sie
Ich komme mit einem schlechten Gefühl?
Nein. Ich kann mich wirklich nicht bewegen.
Was sagst du Es gibt jedoch keinen Gefallen. Ich weiß nicht was ich getan habe.
Danke Danke. Ich bin in der Tür des Tages
Du bist fertig mit dem, was Rei Ayanami heißt.
Halt die Klappe und schlag jemanden.
Ja. Dieses Objekt ist einem dankbar und beabsichtigt dies zu tun.
Es ist beängstigend, sich im Laufe der Zeit darum zu kümmern.?
Weil das die Situation ist. Alle waren besorgt.
Glückwunsch!
Warum lebst du noch??
Also bin ich vor deinem Vater weggelaufen
Nein, ich bin ich. Ich habe mein Leben gelebt!
Nein, lauf nicht weg!
Es ist subjektiv, aber es scheint, dass eher Sätze erzeugt werden als nur RNN. "Lüge. Ich bin der einzige." </ B> "Also bin ich vor deinem Vater weggelaufen" </ b> Ich möchte, dass Ayanami etwas wie Rahen sagt, aber es ist in Ordnung, etwas zu sagen, das nicht gesagt wird.
Als nächstes kommt Misato.
Es ist in Ordnung, sich für die Genesung auszusondern?
Es tut mir Leid
Wie auch immer, schneiden Sie auf Nervs Standby-Stromversorgung!
Aber ich möchte glücklich sein.
Nach dem Bericht aus dem Hauptquartier werde ich ihn etwas früher am Morgen beenden
Befolgen Sie Shinjis Anweisungen.
Es tut mir leid, ich habe es. Dann muss ich früh gehen
Ich werde es öffnen, Japan.
Solch ein unvernünftiger Wunsch
...Asuka, eine Ersatzfestung
Ein Typ, der nicht wie gewohnt Witze machen kann.
Ist es auf der Wunde deiner Mutter??
Das Komitee unterbricht die Standby-Stromversorgung. Und drehen Sie die erste Maschine
Kamochi-kun, ich werde dich bombardieren?
Blöd...
Du hast eine Idee?
Unheimlich!Was für ein Gesicht hattest du, als du der Einsamkeit zugehört hast??
Ich habe ein Gesicht wie du. Du bist ein Vater
Apostel?
Das, Asuka, Ray?Einheit 0 ist?
ich hasse es!
...Evas Pilot hat ein Notsignal...Beeindruckend
Und nein, nein, nein, ich trage das nicht...
damit.
Was war das!?
Dass der Dara Saschi dich schlagen lässt...
Gut!
Veränderung?
Erste, zweite, zweite Qualifikation, welche Rettung.
Asuka
Ich hasse es, das weiß ich!
Ich kenne!Er hat es für mich gemacht, also leih mir das Mittagessen deiner Mutter.
Mama?
Er brachte mir ein Bad mit Mr. Kamochi?
Nervig!
...Es ist okay, ich hasse es wirklich!
Hass...
Warte eine Minute hier!
Mama, Idiot
Okay, Sheggy Ete Yoi!
Blöd!あんたなんかBlödにすんのよ!
Das?
Ich gehe, ich gehe.
Auf diese Weise bin ich gerade erwachsen.
ich hasse es!Blöd!
...Dieser Idiot...
Ich warte hier für einen Moment. Bitte geh!Herr Kamochi!
Erstens bin ich in der ersten Phase
Ich hasse es, ich hasse es, ich habe es so sehr gemacht, es ist kein anderes
Ersetzt, sichern Sie Einheit 2 selbst.
Erzählen Sie keine Geschichten von Menschen
Was ist das?
Evangelion Nr. 2 und Nr. 2!
Es ist ein seltsames Kind.
Hah...
Ich kenne.
...Kamochi ist laut...
Ruf dich auch nicht an!
Die Synchronisationsrate ist die vierte in ungefähr zwei Wochen.
Was für eine Lüge
Ich hasse es zuerst.
Nehmen Sie dies vorerst!
Sie sind schon lange gefahren, obwohl Sie noch nicht aufgewacht sind
Warte eine Minute hier!
Du blöder?Zuerst zuerst gekühlt!
Was, der Mund ist von jedem Mund, gut miteinander auskommen!
Okay, Shejoie Teyoi! </ B> Plötzliches Poptepipic.
Der Dialog anderer Charaktere https://github.com/ashwatthaman/LSTMVAE/tree/master/src/each_case/serif/test28_Public.txt Es ist in. Es gibt Gundam, Code Gears, Haruhi, Rakisuta, Everyday, Squid Girl und so weiter. Es scheint, dass die Generierungsgenauigkeit je nach Charakter sehr unterschiedlich ist.
5.2. Tonumwandlung
Was zu tun ist, habe ich bereits erwähnt, dass CVAE sowohl Codierern als auch Decodierern Kategorievektoren hinzufügt. Normalerweise wird derselbe Kategorievektor in den Codierer und Decodierer eingefügt. Ist es jedoch möglich, den Dialog des Codiererzeichens durch Einfügen verschiedener Vektoren in einen anderen Zeichenstil umzuwandeln? Das habe ich versucht. Lassen Sie uns Nao Yuris Zeile "Bitte sehen Sie alle" </ b> in ein Tintenfischmädchen umwandeln. Dann ..., "Jeder, mach es!" </ B>
Wurde ausgegeben. Es tut mir Leid ... Es wäre perfekt gewesen, wenn ich es gesehen hätte, anstatt es zu tun.
Als nächstes Asukas Dialog "Halo, Misato! Wie geht es dir?" </ B> Wird in den Shinji-Stil konvertiert.
"Wie Misato sagt. Wenden wir uns an Ayanami." </ B>
ist geworden. Nun, es ist subtil.
Noch einer Chars Dialog "Guney hat die Atomraketen des Feindes gestoppt. Das ist die Aufgabe eines gestärkten Menschen." </ B> Fragen.
"Ich werde dir vergeben, dass du mir erzählt hast, dass Guney die Atomraketen des Feindes gestoppt hat." </ B> Jetzt das. Ich bin der Meinung, dass dies relativ umgesetzt werden kann.
Aber relativ so? Es gibt niemanden von zehn, der funktioniert hat. In den meisten Fällen wurde es in Wörter mit völlig unterschiedlichen Bedeutungen umgewandelt. Es scheint, dass etwas mehr Einfallsreichtum erforderlich ist, um den Ton mit AutoEncoder umzuwandeln.
6. Rücksichtnahme oder Eindruck
6.1. Dialoggenerierung
Zunächst habe ich zwei Herausforderungen mit bestehenden Methoden aufgeworfen.
- Sie können aufgrund fehlender Trainingsdaten nicht gut lernen.
- Wenn Sie nur mit dem Dialog eines Charakters lernen, sagen Sie keine Wörter, die der Charakter zuvor noch nicht gesagt hat. Es sind zwei Punkte.
Wir haben 1. nicht quantitativ bewertet, aber ich denke, es wurde bestätigt, dass die Qualität von Sätzen verbessert werden kann, indem der Dialog anderer Zeichen in die Trainingsdaten aufgenommen wird. Im Vergleich zu bestehenden Methoden ist der Prozentsatz grammatikalisch gebrochener Sätze gering. Darüber hinaus gibt es nicht direkt aus, was im ursprünglichen Dialog enthalten ist.
Ungefähr 2. Im obigen Beispiel sagt Ray "Tür" und Misato sagt "Festung". Da diese Wörter nicht im ursprünglichen Dialogsatz enthalten sind, kann gesagt werden, dass es ihnen gelungen ist, neue Wörter herauszugeben. Das Verhältnis ist jedoch niedriger als erwartet.
6.2. Tonumwandlung
Durch Ändern des Kategorievektors mit Codierer und Decodierer haben wir die Möglichkeit gezeigt, den Ton und den Stil zu ändern. (Obwohl es noch nicht auf praktischem Niveau ist)
Die Ergebnisse der Addition / Subtraktion von Wörtern in word2vec und der Addition / Subtraktion von Bildern (Entfernen und Aufsetzen von Brillen) in GAN sind bekannt, aber es scheint keine Forschung zu geben, um die Bedeutung oder den Stil durch Hinzufügen oder Subtrahieren von Sätzen zu ändern. Ich werde. Natürlich können Sie den Stil selbst mithilfe des Encoder-Decoder-Modells ändern, aber es ist unter dem Gesichtspunkt nicht realistisch, dass Sie eine große Anzahl entsprechender Sätze sammeln müssen.
Die Genauigkeit der Konvertierung mit CVAE kann durch Erhöhen der Trainingsdaten in gewissem Maße verbessert werden, es ist jedoch zu diesem Zeitpunkt nicht bekannt, inwieweit dies erreicht werden kann. Es gibt etwas mehr Raum für Forschung.
7. Zukünftige Probleme
- Wenn Sie wirklich überprüfen möchten, ob Sie den Ton und den Stil konvertieren können, ist es besser, Daten mit mehr Sätzen in jeder Kategorie zu verwenden.
- Selbst wenn 120.000 Sätze vorhanden sind, können grammatikalisch falsche Sätze generiert werden. Ich denke, dies kann durch Erhöhen der Trainingsdaten gelöst werden.
- Dieses Mal wird anstelle von MeCab das Satzstück für die morphologische Unterteilung verwendet. Wenn die Bedingungen erfüllt sind, sollte MeCab zum Vergleich verwendet werden. Ich denke jedoch nicht, dass es sich je nach Methode der morphologischen Teilung so sehr ändern wird, also denke ich, dass CVAE funktioniert.
- Ich fand es schwierig, den Charakter dazu zu bringen, ein Wort zu sagen, das in den Trainingsdaten nicht gesprochen wurde. Benötigen Sie etwas, das vorverteilt ist?
8. Referenzseite (Vielen Dank für Ihre Hilfe)
Artikel
- [Evangelion] Versuchen Sie, mit Deep Learning automatisch Asuka-ähnliche Linien zu generieren
- Nehmen Sie mit VAE Zeicheneinstellungen vor.
- Übersicht über das LSTM-Netzwerk
- Auto-Encoding Variational Bayes [arXiv:1312.6114]
- Chainer, RNN und maschinelle Übersetzung
Papier-
Trainingsdaten