[PYTHON] Datensatz zur Auswertung des Spam-Reviewer-Erkennungsalgorithmus
Überblick
 Zur Bewertung des Erkennungsalgorithmus für Spam-Prüfer
Artikel [Ein zweigliedriges Diagrammmodell und eine sich gegenseitig verstärkende Analyse für Überprüfungsseiten](http://www.anrdoezrs.net/links/8186671/type/dlg/http://link.springer.com/chapter/10.1007%2F978-3 -642-23088-2_25)
Künstliche Daten wurden veröffentlicht. Dieser Artikel fasst die Verwendung zusammen.
Außerdem wird die parallele Auswertung mithilfe der Google Cloud Platform zusammengefasst.
Zur Bewertung des Erkennungsalgorithmus für Spam-Prüfer
Artikel [Ein zweigliedriges Diagrammmodell und eine sich gegenseitig verstärkende Analyse für Überprüfungsseiten](http://www.anrdoezrs.net/links/8186671/type/dlg/http://link.springer.com/chapter/10.1007%2F978-3 -642-23088-2_25)
Künstliche Daten wurden veröffentlicht. Dieser Artikel fasst die Verwendung zusammen.
Außerdem wird die parallele Auswertung mithilfe der Google Cloud Platform zusammengefasst.
Installation
Das Paket ist in PyPI registriert, sodass Sie es mit dem Befehl pip installieren können.
$ pip install --upgrade rgmining-synthetic-dataset
Künstliche Graphendaten lesen
Der rgmining-synthetische-Datensatz enthält das synthetische Paket.
Exportieren Sie die Funktion synthetisch.Laden und die Konstante synthetisch.ANOMALOUS_REVIEWER_SIZE.
Die Funktion "synthetisch laden" lädt künstliche Überprüfungsdiagrammdaten und
Die Konstante synthetisch.ANOMALOUS_REVIEWER_SIZE ist in diesem Datensatz enthalten
Es gibt die Anzahl der eigentümlichen Spam-Prüfer an (57).
Anomale Spam-Rezensenten haben eine "Anomalie" in ihrem Namen.
Daher wird bei der Auswertung anhand dieses Datensatzes
Wie genau und reproduzierbar können Sie 57 Spam-Rezensenten finden? Herausfinden.
Ich werde die Erklärung weglassen, wie die künstlichen Daten erstellt wurden. Wenn Sie interessiert sind, [Originalarbeit](http://www.anrdoezrs.net/links/8186671/type/dlg/http://link.springer.com/chapter/10.1007%2F978-3-642-23088- Bitte beziehen Sie sich auf 2_25). (Ich kann es eines Tages in einem anderen Artikel zusammenfassen)
Die Funktion synthet.load verwendet ein Diagrammobjekt als Argument.
Dieses Grafikobjekt ist
--new_reviewer (name) : Erstellt ein Reviewer-Objekt mit dem Namen name und gibt es zurück.
--new_product (name) : Erstellt ein Produktobjekt mit dem Namen name und gibt es zurück.
--add_review (Rezensent, Produkt, Bewertung) : Fügen Sie eine Bewertung hinzu, deren Punktzahl zu Produkt von Rezensent Bewertung ist. Beachten Sie, dass. Es wird angenommen, dass "Bewertung" auf 0 oder mehr und 1 oder weniger normalisiert ist.
Sie müssen drei Methoden haben.
Der neulich eingeführte Fraud Eagle erfüllt diese Bedingung. Deshalb,
import fraud_eagle as feagle
import synthetic
graph = feagle.ReviewGraph(0.10)
synthetic.load(graph)
In diesem Fall kann der Fraud Eagle-Algorithmus verwendet werden, um diese künstlichen Daten zu analysieren.
Aktuelle Analyse
Fraud Eagle war ein Algorithmus, der einen Parameter verwendet Lassen Sie uns herausfinden, welche Parameter für diesen künstlichen Datensatz geeignet sind. Diesmal von den Top 57 Personen mit einem hohen "anomalous_score", Bewerten Sie anhand des Prozentsatzes, der tatsächlich ein besonderer Spam-Prüfer war. (Je höher dieses Verhältnis, desto korrekter und eigenartiger sind Spam-Prüfer.)
analyze.py
#!/usr/bin/env python
import click
import fraud_eagle as feagle
import synthetic
@click.command()
@click.argument("epsilon", type=float)
def analyze(epsilon):
graph = feagle.ReviewGraph(epsilon)
synthetic.load(graph)
for _ in range(100):
diff = graph.update()
print("Iteration end: {0}".format(diff))
if diff < 10**-4:
break
reviewers = sorted(
graph.reviewers,
key=lambda r: -r.anomalous_score)[:synthetic.ANOMALOUS_REVIEWER_SIZE]
print(len([r for r in reviewers if "anomaly" in r.name]) / len(reviewers))
if __name__ == "__main__":
analyze()
Ich habe click für den Befehlszeilenparser verwendet.
$ chmod u+x analyze.py
$ ./analyze.py 0.1
Dann können Sie mit dem Parameter "0.1" experimentieren. Die Ausgabe ist
$ ./analyze.py 0.10
Iteration end: 0.388863491546
Iteration end: 0.486597792445
Iteration end: 0.679722652169
Iteration end: 0.546349261422
Iteration end: 0.333657951459
Iteration end: 0.143313076183
Iteration end: 0.0596751050403
Iteration end: 0.0265415183341
Iteration end: 0.0109979501706
Iteration end: 0.00584731865022
Iteration end: 0.00256288275348
Iteration end: 0.00102187920468
Iteration end: 0.000365458293609
Iteration end: 0.000151984909839
Iteration end: 4.14654814812e-05
0.543859649123
Es scheint, dass etwa 54% der Top-57-Personen eigenartige Spam-Rezensenten waren.
Untersuchung optimaler Parameter in der Cloud
Ich habe den Parameter früher auf 0,1 gesetzt, aber ändert sich das Ergebnis mit anderen Werten? Lassen Sie uns nach mehreren Werten suchen. Grundsätzlich können Sie das obige Skript einzeln mit unterschiedlichen Parametern ausführen. Da es einige Zeit zu dauern scheint, werden wir es parallel über die Google Cloud ausführen.
Verwenden Sie zur Verwendung der Google Cloud das in [Einfachere Verwenden der Google Cloud Platform] eingeführte Tool Roadie (http://qiita.com/jkawamoto/items/751558536a597a33ae2a). Informationen zur Installation und Grundeinstellung finden Sie im obigen Artikel.
Listen Sie zunächst die Bibliotheken auf, die zum Ausführen der zuvor in require.txt erstellten analyse.py erforderlich sind.
requirements.txt
click==6.6
rgmining-fraud-eagle==0.9.0
rgmining-synthetic-dataset==0.9.0
Erstellen Sie dann eine Skriptdatei zum Ausführen von "Roadie".
analyze.yml
run:
- python analyze.py {{epsilon}}
Dieses Mal benötigen wir keine externe Datendatei oder ein passendes Paket Schreiben Sie einfach nur den Befehl run. Der Teil {{epsilon}} ist ein Platzhalter. Übergeben Sie es als Argument beim Erstellen einer Instanz. Da wir dieses Mal viele Instanzen erstellen möchten, werden wir auch Warteschlangen verwenden. Führen Sie zunächst die erste Aufgabe aus, die auch zum Hochladen des Quellcodes dient.
$ roadie run --local . --name feagle0.01 --queue feagle -e epsilon=0.01 analyze.yml
Der erste besteht darin, den Parameter auf 0,01 zu setzen.
Mit -e epsilon = 0.05 wird der Wert in analyse.yml auf {{epsilon}} gesetzt.
Führen Sie dann die Aufgabe für die verbleibenden Parameter aus.
$ for i in `seq -w 2 25`; do
roadie run --source "feagle0.01.tar.gz" --name "feagle0.${i}" \
--queue feagle -e "epsilon=0.$i" analyze.yml
done
—Quelle feagle0.01.tar.gz gibt die Verwendung des zuerst hochgeladenen Quellcodes an.
Wenn Sie —queue <name> wie folgt an den Befehl roadie run übergeben,
Fügen Sie der Warteschlange "
$ roadie queue instance add --instances 7 feagle
Der Ausführungsstatus jeder Instanz ist
$ roadie status
Sie können mit überprüfen. Der Name der Warteschlange + eine Zufallszahl ist der Name der Instanz, die die Warteschlange verarbeitet. Wenn der Status verschwindet, ist der Vorgang abgeschlossen.
Da das Ausführungsergebnis in Google Cloud Storage gespeichert ist, Holen Sie es sich mit dem folgenden Befehl und schreiben Sie es in eine CSV-Datei.
$ for i in `seq -w 1 25`; do
echo "0.${i}, `roadie result show feagle0.${i} | tail -1`" >> result.csv
done
Sie können die Ausgabe jeder Aufgabe mit dem Roadie-Ergebnis show
plot.py
#!/usr/bin/env python
import click
from matplotlib import pyplot
import pandas as pd
@click.command()
@click.argument("infile")
def plot(infile):
data = pd.read_csv(infile, header=None)
pyplot.plot(data[0], data[1])
pyplot.show()
if __name__ == "__main__":
plot()
Es ist ziemlich einfach, aber es ist ein guter Prototyp.
$ chmod u+x plot.py
$ ./plot.py result.csv
Das vorliegende Ergebnis ist wie folgt.

Da 0,01 bis 0,13 flach sind, überprüfen wir noch einen etwas kleineren Wert. Stellen Sie die Aufgabe wie zuvor in die Warteschlange und führen Sie sie in 8 Parallelen aus.
$ for i in `seq -w 1 9`; do
roadie run --source "feagle0.01.tar.gz" --name "feagle0.00${i}" \
--queue feagle -e "epsilon=0.00$i" analyze.yml
done
$ roadie queue instance add --instances 7 feagle
Wenn die Ausführung abgeschlossen ist, erstellen Sie eine CSV und zeichnen Sie sie wie unten gezeigt.
$ for i in `seq -w 1 9`; do
echo “0.00${i}, `roadie result show feagle0.00${i} | tail -1`" >> result2.csv
done
$ for i in `seq -w 1 25`; do
echo "0.${i}, `roadie result show feagle0.${i} | tail -1`" >> result2.csv
done
$ ./plot.py result2.csv
Das Ergebnis ist wie folgt. Etwa 54% scheinen die besten in Fraud Eagle zu sein.
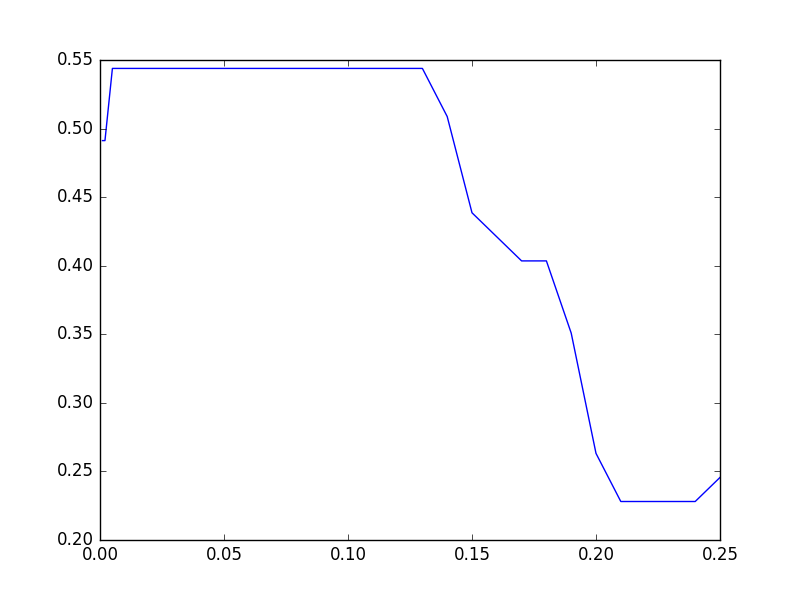
Übrigens, wenn der Parameter bei "0,01" liegt, konvergiert der Algorithmus nicht und vibriert nicht. Zum Beispiel ist im Fall von 0,01 die Ausgabe
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Es sieht aus wie das. Dieses Mal wird es in 100 Schleifen abgeschnitten. Ich bin der Meinung, dass das Originalpapier nicht über Konvergenzbedingungen gesprochen hat Es scheint, dass wir etwas mehr untersuchen müssen.