[PYTHON] [Übersetzung] Spark Memory Management seit 1.6.0
Übersetzte den Artikel hier.
Apache Spark 1.6.0 hat mit der Entwicklung begonnen und das Speicherverwaltungsmodell wurde geändert. Das alte Speicherverwaltungsmodell war die StaticMemoryManger-Klasse. Jetzt heißt es "Vermächtnis". Der "Legacy" -Modus ist standardmäßig deaktiviert. Dies führt zu unterschiedlichen Ergebnissen, wenn Sie denselben Code unter 1.5.x und 1.6.0 ausführen. Bitte seien Sie vorsichtig damit. Sie können den Parameter "spark.memory.useLegacyMode" aus Kompatibilitätsgründen aktivieren. Dies ist standardmäßig deaktiviert.
Vor ungefähr einem Jahr schrieb ich in einem Artikel namens Spark Architecture über die Speicherverwaltung für das "Legacy" -Modell. Ich habe auch kurz über die Speicherverwaltung für die Spark Shuffle-Implementierung geschrieben.
Dieser Artikel ist ein neues Speicherverwaltungsmodell mit "UnifiedMemoryManager", das in Apache Spark 1.6.0 verwendet wird Dieser Abschnitt erklärt.
Kurz zusammengefasst sieht das neue Speicherverwaltungsmodell folgendermaßen aus.
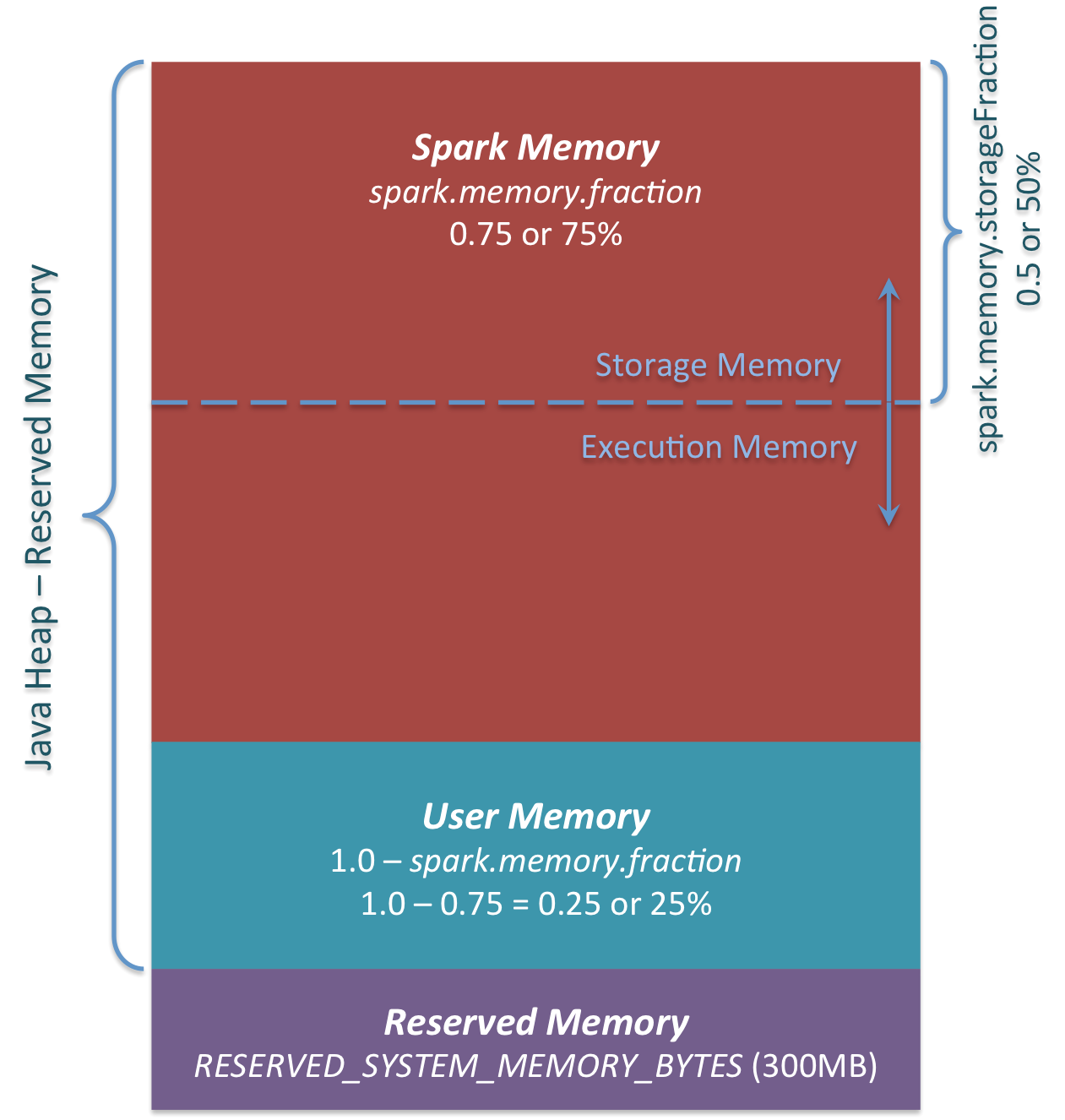
Die drei Hauptspeicherbereiche sind in der Abbildung zu sehen.
Reserved Memory
Vom System reservierter Speicher. Diese Größe ist fest codiert. In Spark 1.6.0 beträgt dieser Wert 300 MB. 300 MB RAM werden nicht für Spark-Berechnungen verwendet. Dieser Wert kann nicht geändert werden, ohne Spark neu zu kompilieren oder spark.testing.reservedMemory zu ändern. Dieser Wert dient zu Testzwecken und es wird nicht empfohlen, ihn in der Produktion zu ändern. Dieser Speicher heißt "reserviert" und wird von Spark niemals verwendet. Dieser Wert kann eine Obergrenze dafür festlegen, wie viel Speicher von Spark-Nutzungsinformationen verwendet werden kann. Selbst wenn Sie den gesamten Java-Heap für den Spark-Cache verwenden möchten, wird dieser "reservierte" Bereich nicht verwendet. (Tatsächlich handelt es sich nicht um ein Ersatzobjekt. Hier können Sie das interne Objekt von Spark speichern.) Wenn Sie Spark Executor keinen Heap von mindestens 1,5 * Reserved Memory = 450 MB zuweisen, wird die Fehlermeldung "Bitte verwenden Sie einen größeren Heap" angezeigt. Ich werde.
User Memeory Dieser Speicherpool bleibt auch nach der Zuweisung des Spark-Speichers im Speicher. Es ist Sache des Benutzers, diesen Speicher zu verwenden. Sie können die Datenstruktur speichern, die bei der Transformation von RDD verwendet wird. Sie können beispielsweise den Operator der mapPartitions-Variante von Spark neu schreiben, die möglicherweise eine Hash-Tabelle enthält, und UserMemory für die Aggregation verwenden. In Spark 1.6.0 wird die Größe des Speicherpools wie folgt berechnet: "Java Heap" - "Reserved Memory" * (1.0 --spark.memory.fraction) Standardmäßig entspricht dies: ("Java-Heap" - 300 MB) * 0,25 Ein 4-GB-Heap kann beispielsweise 949 MB UserMemory enthalten. Auch hier ist es Sache des Benutzers, welche Daten für diesen UserMemory gespeichert werden sollen. Spark hat nichts damit zu tun, was der Benutzer tut und ob er die Grenzen des Speicherbereichs überschreitet. Wenn Sie diesen Speicherbereich ignorieren, wird möglicherweise ein OOM-Fehler angezeigt.
Spark Memory Dies ist ein von Apache Spark verwalteter Speicherpool. Diese Größe wird wie folgt berechnet: ("Java Heap" - "Reserved Memory") * spark.memory.fraction. In Spark 1.6.0 ist es ("Java Heap" -300 MB) * 0,75. Bei einem 4-GB-Heap beträgt der Spark-Speicher beispielsweise 2847 MB. Dieser Speicherpool ist zwei Bereichen zugeordnet. Speicher und Ausführungsspeicher. Diese Grenze kann mit dem Parameter "spark.memory.storageFraction" geändert werden. Der Standardwert ist 0,5. Der Vorteil dieses neuen Speicherbereichs besteht darin, dass diese Grenze nicht statisch ist. Und wenn Speicherdruck auftritt, ändern sich die Grenzen. Beispielsweise kann ein Bereich Platz vom anderen ausleihen, um seine Größe zu erhöhen. Nun, wir werden später darüber sprechen, wie sich diese Speichergrenze ändert. Lassen Sie uns zunächst diskutieren, wie dieser Speicher verwendet wird.
Storage Memory
Dieser Speicherpool wird als temporärer Speicherplatz zum "Abrollen" von zwischengespeicherten Spark-Daten und serialisierten Daten verwendet. Die "Broadcast" -Daten werden auch als Cache-Block gespeichert. Wenn Sie an "Abrollen" interessiert sind, sehen Sie sich diesen Abrollcode an. Wie Sie sehen können, benötigt das Abrollen nicht genügend Speicher für den abgewickelten Block. Wenn nicht genügend Speicher für die nicht abgewickelte Partition vorhanden ist und die Persistenzstufe es dem Laufwerk ermöglicht, Daten zu verarbeiten, werden die Daten direkt auf dem Laufwerk abgelegt. Bei "Broadcast" werden alle Broadcast-Daten gemäß der Persistenzstufe "MEMORY_AND_DISK" zwischengespeichert.
Execution Memory
Dieser Speicherpool speichert die Objekte, die Sie beim Ausführen von Spark-Aufgaben benötigen. Beispielsweise wird es verwendet, um den Zwischenzustandspuffer von shuffle auf der Kartenseite zu speichern, oder um die für die Hash-Aggregation verwendete Hash-Tabelle zu speichern. Dieser Speicherpool schreibt Daten auf die Festplatte, wenn nicht genügend Speicher vorhanden ist. Sie können jedoch keine Blöcke aus diesem Speicherpool von anderen Threads (Tasks) ausschließen.
Lassen Sie uns nun diskutieren, wie die Grenze zwischen Speicher und Ausführungsspeicher funktioniert. Es ist nicht möglich, einen Block aus dem Speicherpool als Merkmal des Ausführungsspeichers zu erzwingen. Da diese für Zwischenberechnungen verwendet werden, schlagen Prozesse, die diesen Speicher benötigen, ohne diesen Speicherblock fehl. Dies gilt nicht für den Speicher (ein einfacher Cache im RAM). Wenn Sie den Block aus dem Speicherpool entfernen möchten, können Sie die Metadaten des Blocks so aktualisieren, als ob der Block auf die Festplatte evakuiert (oder einfach gelöscht) worden wäre. Spark berechnet neu, wenn versucht wird, diesen Block von der Festplatte zu lesen, oder wenn die persistente Ebene das Schreiben auf die Festplatte nicht zulässt.
Sie können den Block aus dem Storge Memory zwingen. Andererseits kann der Ausführungsspeicher nicht verwendet werden. Wann schreibt der Ausführungsspeicher Speicher aus dem Speicher? Dies geschieht in den folgenden Fällen.
--Wenn sich zu viel Speicher im Speicher befindet. Zum Beispiel, wenn der zwischengespeicherte Block nicht den gesamten Speicher belegt. Reduzieren Sie in diesem Fall die Größe des Speicherpools und erhöhen Sie den Ausführungsspeicherpool.
--Wenn die Größe des Speicherpools die anfängliche Größe des Speicherbereichs überschreitet und der gesamte Bereich verwendet wird. In diesem Fall werden Speicherblöcke aus dem Speicherpool (auf Laufwerk geschrieben) gezwungen, wenn die anfängliche Größe nicht erreicht wird.
Die Größe des anfänglichen Strage-Speicherbereichs wird wie folgt berechnet: "Spark Memory" * spark.memory.storageFraction = ("Java Heap" - "Reserved Memory") * spark.memory.fraction * spark.memory.storageFraction. Standardmäßig entspricht dies: ("Java-Heap" - 300 MB) * 0,75 * 0,5 = ("Java-Heap" - 300 MB) * 0,375. Beispielsweise verwendet ein 4-GB-Heap 1423,5 MB RAM als anfänglichen Speicher.
Dies bedeutet, dass, wenn die Summe der Datenmenge im Spark-Cache und des Cache auf dem Executor der anfänglichen Speichergröße entspricht, mindestens die Größe des Speicherbereichs der anfänglichen Datengröße entspricht. Dies liegt daran, dass es nicht möglich ist, Daten aus dem Speicher zu verschieben, während die Größe verringert wird. Wenn der Ausführungsspeicherbereich jedoch die ursprüngliche Größe überschreitet, bevor der Speicher erschöpft ist, können Sie den Ausführungsspeicher nicht zwingen, Einträge zu entfernen. Während der Ausführungsspeicher den Speicher enthält, wird er schließlich mit einer kleinen Speichergröße verarbeitet (da der Speicher dem Ausführungsspeicher zugeordnet ist).