[PYTHON] [Hands-on für Anfänger] Lesen Sie zaggles "Predicting Home Prices" Zeile für Zeile (Teil 2: Bestätigung fehlender Werte)
Thema
Klicken Sie hier für den ersten Inhalt Der zweite Teil des Projekts, um den Inhalt des Hands-On zu notieren, dass jeder das berühmte Thema "Hauspreis" -Problem von Kaggle herausfordern wird. Es ist eher ein Memo als ein Kommentar, aber ich hoffe, es hilft jemandem irgendwo.
- Ursprüngliches Thema: https://www.kaggle.com/c/house-prices-advanced-regression-techniques
- Referenzierter Artikel: https://yolo-kiyoshi.com/2018/12/17/post-1003/
Die heutige Arbeit
Bestätigung fehlender Werte (kann nicht abgeschlossen werden)
Zusammenfassend scheint es einige fehlende Werte zu geben.
Fehlender Status der Trainingsdaten (fehlender Wert)
train.isnull().sum()[train.isnull().sum()>0].sort_values(ascending=False)
Fehlender Wert
- Was ist überhaupt ein "fehlender Wert": https://www.weblio.jp/content/%E6%AC%A0%E6%90%8D%E5%80%A4
Wenn Sie eine Datendatei vorbereiten, müssen Sie einen numerischen Wert eingeben, auch wenn die Daten fehlen. Der eingegebene numerische Wert zeigt jedoch an, dass tatsächlich keine Daten vorhanden waren. Daher müssen diese vom Analyseziel ausgeschlossen werden. Geben Sie daher einen Wert (fehlender Wert) ein, der sich deutlich von anderen gültigen Daten unterscheiden lässt.
.isnull()
- .isnull (): Überprüft, ob der Wert für jedes Element als wahr oder falsch eingegeben wird.
- Referenz: https://note.nkmk.me/python-pandas-nan-judge-count/
- Wenn das Ergebnis nur von train.isnull () ausgegeben wird
.sum()
-
.sum (): Vertrauter Zusatz. Es addiert sich sowohl vertikal als auch horizontal durch Angabe eines Arguments.
-
Referenz: https://deepage.net/features/pandas-sum.html
-
Wenn das Ergebnis nur von train.isnull () ausgegeben wird. Sum ()
-
[train.isnull (). Sum ()> 0]: Das Gefühl, dass nur Spalten mit fehlenden Elementen als Schlüssel angegeben und angeordnet werden.
-
Wenn das Ergebnis nur mit train.isnull () ausgegeben wird. Sum () [train.isnull (). Sum ()> 0]

.sort_values()
- .sort_values (aufsteigend = False): Datensortierung. Hier werden nur die Argumente angegeben, die in absteigender Reihenfolge vorliegen sollen. Es scheint jedoch, dass Sie die Elemente auswählen können, um den Algorithmus zu sortieren oder zu ändern. Praktisch.
- Referenz: https://deepage.net/features/pandas-sort-values.html
- Nur mit train.isnull () anzeigen. Sum () [train.isnull (). Sum ()> 0] .sort_values (aufsteigend = False)

Fehlende Testdaten
Die Erklärung ist die gleiche wie die Trainingsdaten, daher werde ich sie weglassen.
test.isnull().sum()[test.isnull().sum()>0].sort_values(ascending=False)
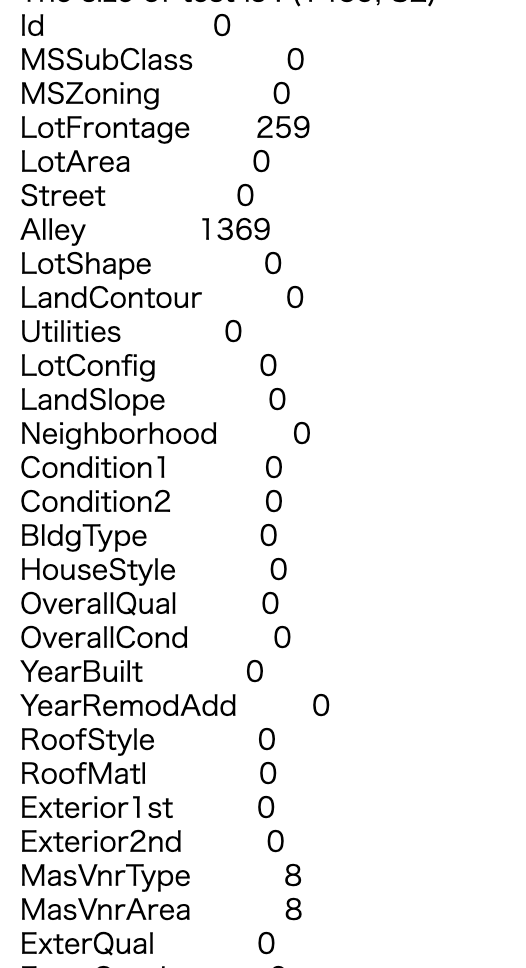
Status des Trainingsdatenverlusts (Datentyp)
.index.tolist()
#Überprüfen Sie den Datentyp der Spalte, die den Fehler enthält
na_col_list = alldata.isnull().sum()[alldata.isnull().sum()>0].index.tolist() #Listen Sie Spalten mit Fehlern auf
alldata[na_col_list].dtypes.sort_values() #Datentyp
- Der Inhalt bis zu "alldata.isnull (). Sum () [alldata.isnull (). Sum ()> 0]" wird weggelassen, da er bis zu dem Punkt erstellt wurde, an dem fehlende Werte in einer Reihe stehen.
- .index: Unterscheidet sich das von
index ()? Ich dachte, aber es scheint anders. - .tolist (): Ich habe dies erneut verwendet, um nur Spalten aufzulisten. (Etwas mehrdeutig)
- Referenz: https://note.nkmk.me/python-pandas-list/
- Ausgabeergebnis von
na_col_list = alldata.isnull (). Sum () [alldata.isnull (). Sum ()> 0] .index.tolist ()
.dtypes
- .dtypes: Wenn Sie dies auf ein Array anwenden, wird jeder Datentyp überprüft. Praktisch. Es gibt auch einen ähnlichen dtype.
- Referenz: https://www.sejuku.net/blog/62023
- Ausgabeergebnis von
alldata [na_col_list] .dtypes(* Der Inhalt von sort_values () wird in aufsteigender Reihenfolge weggelassen)

Mangelsituationen verstehen und damit umgehen
Dies ist eine Beschreibung der Meinungen zum statistischen Umgang mit Daten. Wir empfehlen, dass Sie es normal lesen und verstehen. Eine Geschichte, die sich vom Programmierverständnis unterscheidet.
Sowohl Trainingsdaten als auch Testdaten fehlen erheblich. In diesem Fall möchten Sie die Spalte mit vielen Fehlern löschen. Zuvor verfügt Kaggle jedoch über ein Dokument mit detaillierten Angaben zu Variablen. Schauen wir uns das also zuerst an. Wenn Sie die Daten von Kaggle herunterladen, werden Sie feststellen, dass sie auch eine Datei mit dem Namen "data_description.txt" enthalten. Diese Datei beschreibt, welche Daten in den Variablen gespeichert sind. Dann können Sie sehen, dass die Mehrzahl der Mängel nicht bedeutet, dass keine Informationen vorhanden sind, sondern dass die Mängel selbst Informationen sind. Schauen wir uns zum Beispiel PoolQC (Poolqualität) an, das die meisten Mängel aufweist. Der Verlust dieser Variablen bedeutet, dass der Pool im Haus nicht vorhanden ist und der Datenverlust selbst eine Information ist. Bei anderen Variablen (kategorialen Variablen) bedeutet der Mangel lediglich, dass die Einrichtung oder Ausrüstung nicht vorhanden ist. Bei numerischen Variablen bedeutet der Mangel nur, dass der belegte Bereich Null ist und nicht ohne Informationen. Daher wird die folgende Vervollständigung für den Verlust von kategorialen Variablen und numerischen Variablen durchgeführt.
Das ist es.
Hmmm. Ich habe mir nur die Daten angesehen.
Recommended Posts