[PYTHON] Daten-Wrangling der Excel-Datei mit dem Status meiner Kartenausstellung (September)
Einführung
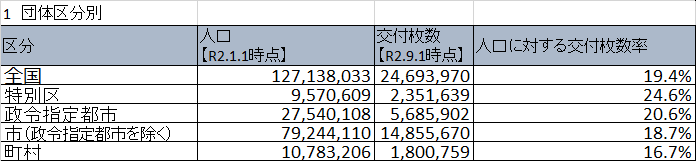
Ministerium für innere Angelegenheiten und Kommunikation Mein Nummernsystem und meine Nummernkarte
- Excel-Format meines Ausstellungsstatus für Nummernkarten (Stand: 1. September, 2. Jahr von Reiwa)
Konvertieren Sie in das CSV-Format von My Number Card Spread Status Dashboard.
-
- August, 2. Jahr von Rewa und 1. September, 2. Jahr von Rewa Da das Format der Excel-Dateien unterschiedlich ist, wird nur der 1. September, 2. Jahr von Rewa unterstützt.
- Das Basisdatum ist August am Ende jeder Tabelle und September steht im Spaltennamen (wie PDF).
- Trennung jeder Tabelle
Klicken Sie hier, um den Status der Ausstellung meiner Nummernkarte anzuzeigen (Stand: 1. August, 2. Jahr von Reiwa). https://qiita.com/barobaro/items/05efbb6aa2c759c80ff0
- Im September steht das Basisdatum im Spaltennamen und jedes wird extrahiert
- Jede Tabelle hat einen Zeitpunkt in der 2. und 3. Spalte des Spaltennamens. Extrahieren Sie also darauf basierend
Daten-Wrangling
import csv
import datetime
import re
import pandas as pd
def wareki2date(s):
m = re.search("(H|R|Heisei|Reiwa)([0-9 Yuan]{1,2})[.Jahr]([0-9]{1,2})[.Mond]([0-9]{1,2})Tag?",s)
year, month, day = [1 if i == "Ehemalige" else int(i) for i in m.group(2, 3, 4)]
if m.group(1) in ["Heisei", "H"]:
year += 1988
elif m.group(1) in ["Reiwa", "R"]:
year += 2018
return datetime.date(year, month, day).strftime("%Y/%m/%d")
def df_conv(df, col_name, population_date, delivery_date):
df.set_axis(col_name, axis=1, inplace=True)
df["Basisdatum der Bevölkerungsberechnung"] = population_date
df["Basisdatum für die Berechnung der Anzahl der Lieferungen"] = delivery_date
df.insert(0, "Basisdatum der Berechnung", delivery_date)
return df
def my_round(s):
return int(s * 1000 + 0.5) / 10
df = pd.read_excel(
"https://www.soumu.go.jp/main_content/000707709.xlsx", sheet_name=1, header=None
)
df.dropna(thresh=3, inplace=True)
dfg = df.groupby(
(df[1].str.contains("Zeitpunkt", na=False) | df[2].str.contains("Zeitpunkt", na=False)).cumsum()
)
dfs = [g.dropna(how="all", axis=1).reset_index(drop=True) for _, g in dfg]
print(len(dfs))
#Nach Gruppenklassifikation
population_date = wareki2date(dfs[0].iat[0, 1])
delivery_date = wareki2date(dfs[0].iat[0, 2])
df0 = df_conv(
dfs[0].iloc[1:].reset_index(drop=True),
["Einstufung", "Population", "Anzahl der Lieferungen", "Populationに対するAnzahl der Lieferungen率"],
population_date,
delivery_date,
)
df0["Anzahl der Zuschüsse an die Bevölkerung"] = df0["Anzahl der Zuschüsse an die Bevölkerung"].apply(my_round)
df0.to_csv(
"summary_by_types.csv",
index=False,
quoting=csv.QUOTE_NONNUMERIC,
encoding="utf_8_sig",
)
df0
#Liste der Präfekturen
population_date = wareki2date(dfs[3].iat[0, 1])
delivery_date = wareki2date(dfs[3].iat[0, 2])
df3 = df_conv(
dfs[3].iloc[1:].reset_index(drop=True),
["Name der Präfekturen", "Gesamtzahl (Bevölkerung)", "Anzahl der Lieferungen", "人口に対するAnzahl der Lieferungen率"],
population_date,
delivery_date,
)
df3["Anzahl der Zuschüsse an die Bevölkerung"] = df3["Anzahl der Zuschüsse an die Bevölkerung"].apply(my_round)
df3.to_csv(
"all_prefectures.csv",
index=False,
quoting=csv.QUOTE_NONNUMERIC,
encoding="utf_8_sig",
)
df3
#Nach Geschlecht und Alter
population_date = wareki2date(dfs[4].iat[0, 1])
delivery_date = wareki2date(dfs[4].iat[0, 4])
df4 = df_conv(
dfs[4].iloc[2:].reset_index(drop=True),
[
"Alter",
"Population(Mann)",
"Population(Frau)",
"Population(Gesamt)",
"Anzahl der Lieferungen(Mann)",
"Anzahl der Lieferungen(Frau)",
"Anzahl der Lieferungen(Gesamt)",
"Zuschussrate(Mann)",
"Zuschussrate(Frau)",
"Zuschussrate(Gesamt)",
"Verhältnis der Anzahl der Zuschüsse zum Ganzen(Mann)",
"Verhältnis der Anzahl der Zuschüsse zum Ganzen(Frau)",
"Verhältnis der Anzahl der Zuschüsse zum Ganzen(Gesamt)",
],
population_date,
delivery_date,
)
df4["Zuschussrate(Mann)"] = df4["Zuschussrate(Mann)"].apply(my_round)
df4["Zuschussrate(Frau)"] = df4["Zuschussrate(Frau)"].apply(my_round)
df4["Zuschussrate(Gesamt)"] = df4["Zuschussrate(Gesamt)"].apply(my_round)
df4["Verhältnis der Anzahl der Zuschüsse zum Ganzen(Mann)"] = df4["Verhältnis der Anzahl der Zuschüsse zum Ganzen(Mann)"].apply(my_round)
df4["Verhältnis der Anzahl der Zuschüsse zum Ganzen(Frau)"] = df4["Verhältnis der Anzahl der Zuschüsse zum Ganzen(Frau)"].apply(my_round)
df4["Verhältnis der Anzahl der Zuschüsse zum Ganzen(Gesamt)"] = df4["Verhältnis der Anzahl der Zuschüsse zum Ganzen(Gesamt)"].apply(my_round)
df4.to_csv(
"demographics.csv", index=False, quoting=csv.QUOTE_NONNUMERIC, encoding="utf_8_sig",
)
df4
#Nach Stadt
population_date = wareki2date(dfs[5].iat[0, 2])
delivery_date = wareki2date(dfs[5].iat[0, 3])
df5 = df_conv(
dfs[5].iloc[2:].reset_index(drop=True),
["Name der Präfekturen", "Stadtname", "Gesamtzahl (Bevölkerung)", "Anzahl der Lieferungen", "人口に対するAnzahl der Lieferungen率"],
population_date,
delivery_date,
)
df5["Anzahl der Zuschüsse an die Bevölkerung"] = df5["Anzahl der Zuschüsse an die Bevölkerung"].apply(my_round)
df5["Stadtname"] = df5["Stadtname"].replace(r"\s", "", regex=True)
df5["Stadtname"] = df5["Stadtname"].mask(df5["Name der Präfekturen"] + df5["Stadtname"] == "Shinoyama City, Präfektur Hyogo", "Tamba Shinoyama Stadt")
df5["Stadtname"] = df5["Stadtname"].mask(df5["Name der Präfekturen"] + df5["Stadtname"] == "Stadt Kajiwara, Landkreis Takaoka, Präfektur Kochi", "Hibara-cho, Takaoka-gun")
df5["Stadtname"] = df5["Stadtname"].mask(df5["Name der Präfekturen"] + df5["Stadtname"] == "Sue Town, Kasuya County, Präfektur Fukuoka", "Sue-cho, Kasuya-gun")
if pd.Timestamp(df5.iloc[0]["Basisdatum der Berechnung"]) < datetime.date(2018, 10, 1):
df5["Stadtname"] = df5["Stadtname"].mask(
df5["Name der Präfekturen"] + df5["Stadtname"] == "Stadt Nakagawa, Präfektur Fukuoka", "Nakagawa-cho, Chikushi-Pistole"
)
else:
df5["Stadtname"] = df5["Stadtname"].mask(
df5["Name der Präfekturen"] + df5["Stadtname"] == "Stadt Nakagawa, Landkreis Chikushi, Präfektur Fukuoka", "Nakagawa City"
)
df_code = pd.read_csv(
"https://docs.google.com/spreadsheets/d/e/2PACX-1vSseDxB5f3nS-YQ1NOkuFKZ7rTNfPLHqTKaSag-qaK25EWLcSL0klbFBZm1b6JDKGtHTk6iMUxsXpxt/pub?gid=0&single=true&output=csv",
dtype={"Gruppencode": int, "Name der Präfekturen": str, "Name des Landkreises": str, "Stadtname": str},
)
df_code["Stadtname"] = df_code["Name des Landkreises"].fillna("") + df_code["Stadtname"]
df_code.drop("Name des Landkreises", axis=1, inplace=True)
df5 = pd.merge(df5, df_code, on=["Name der Präfekturen", "Stadtname"], how="left")
df5["Gruppencode"] = df5["Gruppencode"].astype("Int64")
df5.to_csv(
"all_localgovs.csv",
index=False,
quoting=csv.QUOTE_NONNUMERIC,
encoding="utf_8_sig",
)
df5