[PYTHON] [Lernen stärken] Umfrage zur Verwendung der Experience Replay-Bibliothek von DeepMind Reverb [Client Edition]
Japanischer Nachdruck von Blog-Artikel in englischer Sprache
1. Zuallererst
Fortsetzung von Letztes Mal über Reberb der Experience Replay-Bibliothek von DeepMind. Dieses Mal habe ich beim Lesen des Quellcodes den Teil untersucht, der nicht in der README auf der Clientseite geschrieben ist und den Dateneingabe- / Ausgabevorgang anweist.
2. "Client" und "TFClient"
Reverb verwendet ein Server-Client-Modell, es gibt jedoch zwei clientseitige Klassen, "reverb.Client" und "reverb.TFClient".
Es wird gesagt, dass "Client" für die frühen Entwicklungsstadien ist und "TFClient" im eigentlichen Lernprogramm verwendet wird. Der große Unterschied besteht darin, dass "TFClient", wie der Name schon sagt, im Berechnungsdiagramm von TensorFlow verwendet werden soll.
Eine der Beweggründe für das Schreiben dieses organisierten Artikels war, dass die APIs und die Verwendung beider inkonsistent und kompliziert waren.
Im folgenden Artikel wird davon ausgegangen, dass die Server- und Clientprogramme wie folgt initialisiert wurden:
import numpy as np
import tensorflow as tf
import reverb
table_name = "ReplayBuffer"
alpha = 0.8
buffer_size = 1000
batch_size = 32
server = reverb.Server(tables=[reverb.Table(name=table_name,
sampler=reverb.selectors.Prioritized(alpha),
remover=reverb.selectors.Fifo(),
max_size=buffer_size,
rate_limiter=reverb.rate_limiters.MinSize(1))])
client = reverb.Client(f"localhost:{server.port}")
tf_client = reverb.TFClient(f"localhost:{server.port}")
obs = np.zeros((4,))
act = np.ones((1,))
rew = np.ones((1,))
next_obs = np.zeros_like(obs)
done = np.zeros((1,))
priority = 1.0
dtypes = [tf.float64,tf.float64,tf.float64,tf.float64,tf.float64]
shapes = [4,1,1,4,1]
3. Erhaltung des Übergangs oder der Flugbahn
3.1 Client.insert
client.insert([obs,act,rew,next_obs,done],priorities={table_name: priority})
Das Argument "Prioritäten" lautet "diktieren", da dieselben Daten gleichzeitig in mehreren Tabellen (Wiedergabepuffern) mit unterschiedlichen Prioritäten registriert werden können. (Ich wusste nicht, dass es einen solchen Bedarf gibt)
Sie müssen die Priorität angeben, auch für reguläre nicht priorisierte Wiedergabepuffer.
Client.insert sendet bei jedem Aufruf Daten an den Server
3.2 Client.writer
with client.writer(max_sequence_length=3) as writer:
writer.append([obs,act,rew,next_obs,done])
writer.create_item(table_name,num_timesteps=1,priority=priority)
writer.append([obs,act,rew,next_obs,done])
writer.append([obs,act,rew,next_obs,done])
writer.append([obs,act,rew,next_obs,done])
writer.create_item(table_name,num_timesteps=3,priority=priority) #Registrieren Sie 3 Schritte als 1 Element.
#Beim Beenden mit Block an den Server senden
Durch Verwendung von "reverb.Writer", das von der "Client.writer" -Methode als Kontextmanager zurückgegeben wird, Sie können festlegen, dass der Inhalt flexibler gespeichert wird.
In der ersten Hälfte des obigen Beispielcodes wird beispielsweise derselbe Inhalt wie in 3.1 gespeichert, in der zweiten Hälfte werden die drei Schritte zusammen als ein Element gespeichert. Mit anderen Worten, wenn Sie eine Stichprobe erstellen, können Sie alle drei als eine Stichprobe abtasten. Beispielsweise kann davon ausgegangen werden, dass es verwendet wird, wenn Sie jede Episode abtasten möchten.
Daten werden an den Server gesendet, wenn "Writer.flush ()" oder "Writer.close ()" aufgerufen wird (sie werden auch automatisch aufgerufen, wenn der "with" -Block verlassen wird).
3.3 TFClient.insert
tf_client.inser([tf.constant(obs),
tf.constant(act),
tf.constant(rew),
tf.constant(next_obs),
tf.constant(done)],
tablea=tf.constant([table_name]),
priorities=tf.constant([priority],dtype=tf.float64))
Das Argument "Tabellen" ist der "str" Rang 1 "tf.Tensor", und die "Prioritäten" sind der "float64" (sofern nicht anders angegeben "float32") Rang 1 "tf.Tensor". Beide Formen müssen übereinstimmen.
Es ist wahrscheinlich notwendig, den "tf.Tensor" jeder Daten für eine spätere Abtastung auf Rang 1 oder höher zu halten.
3.4 Zusammenfassung
| An Server senden | Mehrere Schritte zu einem Element | Verwendung im TF-Berechnungsdiagramm | Daten | |
|---|---|---|---|---|
Client.insert |
Jedes Mal | X | X | Alles ist gut |
Client.writer |
Writer.close(), Writer.flush() (EinschließlichwithBeim Verlassen) |
O | X | Alles ist gut |
TFClient.insert |
Jedes Mal | X | O | tf.Tensor |
4. Lesen eines Übergangs oder einer Flugbahn
Keine der beiden Methoden entspricht dem β-Parameter der Gewichtskorrektur in Prioritized Experience Replay. (Das Gewicht der Prioritätsstichprobe wird überhaupt nicht berechnet.)
4.1 Client.sample
client.sample(table_name,num_samples=batch_size)
Der Rückgabewert ist generator von reverb.replay_sample.ReplaySample. "ReplaySample" ist ein benanntes Tupel mit "info" und "data". Die "Daten" enthalten die gespeicherten Daten, und die "Informationen" enthalten Informationen wie Schlüssel und Priorität.
4.2 TFClient.sample
tf_client.sample(tf.constant([table_name]),data_dtypes=dtypes)
Leider unterstützt diese Methode keine Batch-Probenahme. Der Rückgabewert ist "ReplaySample".
4.3 TFClient.dataset
tf_client.dataset(tf.constant([table_name]),dtypes=dtypes,shapes=shapes)
Es wird eine Methode angewendet, die sich von anderen Methoden völlig unterscheidet, und es scheint, dass es hauptsächlich beabsichtigt ist, diese Methode beim groß angelegten Produktionslernen anzuwenden.
Der Rückgabewert dieser Funktion ist "reverb.ReplayDataset", der "tf.data.Dataset" erbt. Dieses "ReplayDataset" kann ein "ReplaySample" wie einen "Generator" herausziehen und zum richtigen Zeitpunkt automatisch Daten vom Server abrufen. Mit anderen Worten, anstatt jedes Mal "sample" zu verwenden, werden nach dem Festlegen von "ReplayDataset" die automatisch gespeicherten Daten weiterhin ausgeworfen.
Da "Formen" einen Fehler auslöst, wenn "0" als Element angegeben wird, scheint es notwendig zu sein, die Daten auf Rang 1 oder höher zu speichern.
Weitere Parameter für die Leistungsanpassung finden Sie hier. Überprüfen Sie daher den Kommentar im Quellcode. Ich möchte, dass.
4.4 Zusammenfassung
| Stapelausgabe | Rückgabetyp | Typenspezifikation | Formbezeichnung | |
|---|---|---|---|---|
Client.sample |
O | replay_sample.ReplaySamplevongenerator |
Nicht notwendig | Nicht notwendig |
TFClient.sample |
X | replay_sample.ReplaySample |
notwendig | Nicht notwendig |
TFClient.dataset |
O (Intern automatisch implementiert) | ReplayDataset |
notwendig | notwendig |
5. Aktualisierung der Priorität
Im Gegensatz zu anderen Implementierungen von Wiedergabepuffern ist die ID, die das Element angibt, keine Seriennummer, die mit "0" beginnt, sondern ein scheinbar zufälliger Hash. Es kann mit ReplaySample.info.key zugegriffen werden.
(Da es schwierig zu schreiben ist, werde ich einen Teil des Beispielcodes weglassen. Es tut mir leid.)
5.1 Client.mutate_priorities
client.mutate_priorities(table_name,updates={key:new_priority},deletes=[...])
Dies kann sowohl gelöscht als auch aktualisiert werden.
5.2 TFClient.update_priorities
tf_client.update_priorities(tf.constant([table_name]),
keys=tf.constant([...]),
priorities=tf.constant([...],dtype=tf.float64))
6. Leistungsvergleich
Da es eine große Sache ist, habe ich einen Benchmark einschließlich meiner Arbeit cpprb erstellt.
** Hinweis: Das Reinforcement-Lernen wird nicht nur durch die Geschwindigkeit des Wiedergabepuffers bestimmt, da es andere schwere Prozesse gibt, wie das Erlernen von Deep Learning und das Aktualisieren der Umgebung. (Andererseits scheint es, abhängig von der Implementierung und den Bedingungen des Wiedergabepuffers, dass die Verarbeitungszeit des Wiedergabepuffers und die Verarbeitungszeit des tiefen Lernens ungefähr gleich sind.) **
Der Benchmark wurde in der Umgebung mit der folgenden Docker-Datei ausgeführt.
Dockerfile
FROM python:3.7
RUN apt update \
&& apt install -y --no-install-recommends libopenmpi-dev zlib1g-dev \
&& apt clean \
&& rm -rf /var/lib/apt/lists/* \
&& pip install tf-nightly==2.3.0.dev20200604 dm-reverb-nightly perfplot
# Reverb requires development version TensorFlow
CMD ["bash"]
(Da es auf dem CI des cpprb-Repositorys implementiert ist, wird auch cpprb installiert. Es ist fast gleichbedeutend mit "pip install cpprb".)
Dann habe ich das folgende Benchmark-Skript ausgeführt und ein Diagramm der Ausführungszeit gezeichnet.
benchmark.py
import gc
import itertools
import numpy as np
import perfplot
import tensorflow as tf
# DeepMind/Reverb: https://github.com/deepmind/reverb
import reverb
from cpprb import (ReplayBuffer as RB,
PrioritizedReplayBuffer as PRB)
# Configulation
buffer_size = 2**12
obs_shape = 15
act_shape = 3
alpha = 0.4
beta = 0.4
env_dict = {"obs": {"shape": obs_shape},
"act": {"shape": act_shape},
"next_obs": {"shape": obs_shape},
"rew": {},
"done": {}}
# Initialize Replay Buffer
rb = RB(buffer_size,env_dict)
# Initialize Prioritized Replay Buffer
prb = PRB(buffer_size,env_dict,alpha=alpha)
# Initalize Reverb Server
server = reverb.Server(tables =[
reverb.Table(name='ReplayBuffer',
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
max_size=buffer_size,
rate_limiter=reverb.rate_limiters.MinSize(1)),
reverb.Table(name='PrioritizedReplayBuffer',
sampler=reverb.selectors.Prioritized(alpha),
remover=reverb.selectors.Fifo(),
max_size=buffer_size,
rate_limiter=reverb.rate_limiters.MinSize(1))
])
client = reverb.Client(f"localhost:{server.port}")
tf_client = reverb.TFClient(f"localhost:{server.port}")
# Helper Function
def env(n):
e = {"obs": np.ones((n,obs_shape)),
"act": np.zeros((n,act_shape)),
"next_obs": np.ones((n,obs_shape)),
"rew": np.zeros(n),
"done": np.zeros(n)}
return e
def add_client(_rb,table):
""" Add for Reverb Client
"""
def add(e):
n = e["obs"].shape[0]
with _rb.writer(max_sequence_length=1) as _w:
for i in range(n):
_w.append([e["obs"][i],
e["act"][i],
e["rew"][i],
e["next_obs"][i],
e["done"][i]])
_w.create_item(table,1,1.0)
return add
def add_client_insert(_rb,table):
""" Add for Reverb Client
"""
def add(e):
n = e["obs"].shape[0]
for i in range(n):
_rb.insert([e["obs"][i],
e["act"][i],
e["rew"][i],
e["next_obs"][i],
e["done"][i]],priorities={table: 1.0})
return add
def add_tf_client(_rb,table):
""" Add for Reverb TFClient
"""
def add(e):
n = e["obs"].shape[0]
for i in range(n):
_rb.insert([tf.constant(e["obs"][i]),
tf.constant(e["act"][i]),
tf.constant(e["rew"][i]),
tf.constant(e["next_obs"][i]),
tf.constant(e["done"])],
tf.constant([table]),
tf.constant([1.0],dtype=tf.float64))
return add
def sample_client(_rb,table):
""" Sample from Reverb Client
"""
def sample(n):
return [i for i in _rb.sample(table,num_samples=n)]
return sample
def sample_tf_client(_rb,table):
""" Sample from Reverb TFClient
"""
def sample(n):
return [_rb.sample(table,
[tf.float64,tf.float64,tf.float64,tf.float64,tf.float64])
for _ in range(n)]
return sample
def sample_tf_client_dataset(_rb,table):
""" Sample from Reverb TFClient using dataset
"""
def sample(n):
dataset=_rb.dataset(table,
[tf.float64,tf.float64,tf.float64,tf.float64,tf.float64],
[4,1,1,4,1])
return itertools.islice(dataset,n)
return sample
# ReplayBuffer.add
perfplot.save(filename="ReplayBuffer_add2.png ",
setup = env,
time_unit="ms",
kernels = [add_client_insert(client,"ReplayBuffer"),
add_client(client,"ReplayBuffer"),
add_tf_client(tf_client,"ReplayBuffer"),
lambda e: rb.add(**e)],
labels = ["DeepMind/Reverb: Client.insert",
"DeepMind/Reverb: Client.writer",
"DeepMind/Reverb: TFClient.insert",
"cpprb"],
n_range = [n for n in range(1,102,10)],
xlabel = "Step size added at once",
title = "Replay Buffer Add Speed",
logx = False,
logy = False,
equality_check = None)
# Fill Buffers
for _ in range(buffer_size):
o = np.random.rand(obs_shape) # [0,1)
a = np.random.rand(act_shape)
r = np.random.rand(1)
d = np.random.randint(2) # [0,2) == 0 or 1
client.insert([o,a,r,o,d],priorities={"ReplayBuffer": 1.0})
rb.add(obs=o,act=a,rew=r,next_obs=o,done=d)
# ReplayBuffer.sample
perfplot.save(filename="ReplayBuffer_sample2.png ",
setup = lambda n: n,
time_unit="ms",
kernels = [sample_client(client,"ReplayBuffer"),
sample_tf_client(tf_client,"ReplayBuffer"),
sample_tf_client_dataset(tf_client,"ReplayBuffer"),
rb.sample],
labels = ["DeepMind/Reverb: Client.sample",
"DeepMind/Reverb: TFClient.sample",
"DeepMind/Reverb: TFClient.dataset",
"cpprb"],
n_range = [2**n for n in range(1,8)],
xlabel = "Batch size",
title = "Replay Buffer Sample Speed",
logx = False,
logy = False,
equality_check=None)
# PrioritizedReplayBuffer.add
perfplot.save(filename="PrioritizedReplayBuffer_add2.png ",
time_unit="ms",
setup = env,
kernels = [add_client_insert(client,"PrioritizedReplayBuffer"),
add_client(client,"PrioritizedReplayBuffer"),
add_tf_client(tf_client,"PrioritizedReplayBuffer"),
lambda e: prb.add(**e)],
labels = ["DeepMind/Reverb: Client.insert",
"DeepMind/Reverb: Client.writer",
"DeepMind/Reverb: TFClient.insert",
"cpprb"],
n_range = [n for n in range(1,102,10)],
xlabel = "Step size added at once",
title = "Prioritized Replay Buffer Add Speed",
logx = False,
logy = False,
equality_check=None)
# Fill Buffers
for _ in range(buffer_size):
o = np.random.rand(obs_shape) # [0,1)
a = np.random.rand(act_shape)
r = np.random.rand(1)
d = np.random.randint(2) # [0,2) == 0 or 1
p = np.random.rand(1)
client.insert([o,a,r,o,d],priorities={"PrioritizedReplayBuffer": p})
prb.add(obs=o,act=a,rew=r,next_obs=o,done=d,priority=p)
perfplot.save(filename="PrioritizedReplayBuffer_sample2.png ",
time_unit="ms",
setup = lambda n: n,
kernels = [sample_client(client,"PrioritizedReplayBuffer"),
sample_tf_client(tf_client,"PrioritizedReplayBuffer"),
sample_tf_client_dataset(tf_client,"PrioritizedReplayBuffer"),
lambda n: prb.sample(n,beta=beta)],
labels = ["DeepMind/Reverb: Client.sample",
"DeepMind/Reverb: TFClient.sample",
"DeepMind/Reverb: TFClient.dataset",
"cpprb"],
n_range = [2**n for n in range(1,9)],
xlabel = "Batch size",
title = "Prioritized Replay Buffer Sample Speed",
logx=False,
logy=False,
equality_check=None)
Das Ergebnis ist wie folgt. (Die neueste Version ist möglicherweise veraltet. Überprüfen Sie daher die cpprb-Projektsite.)
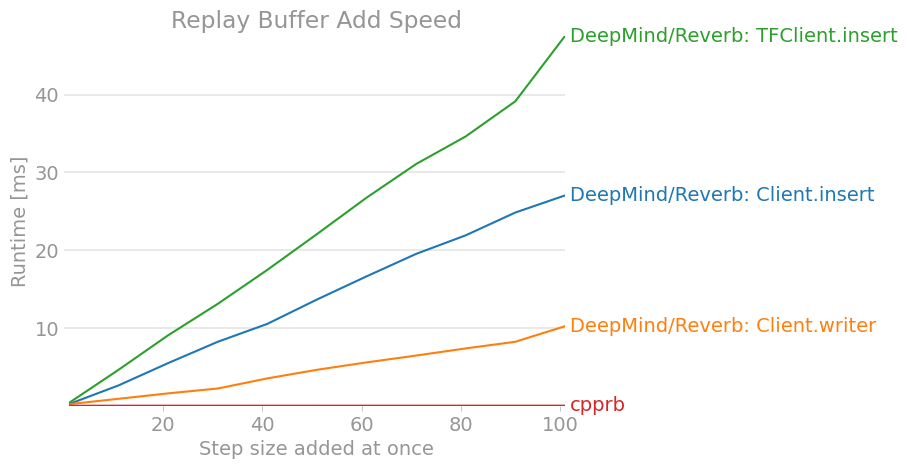
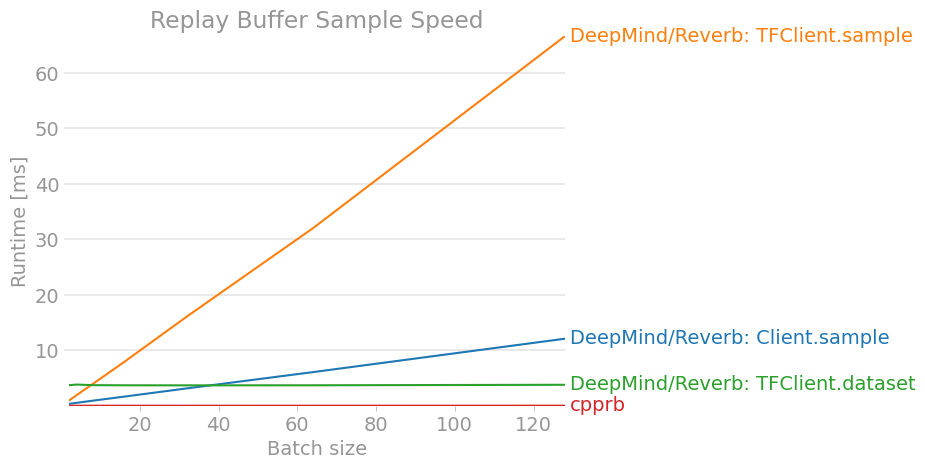
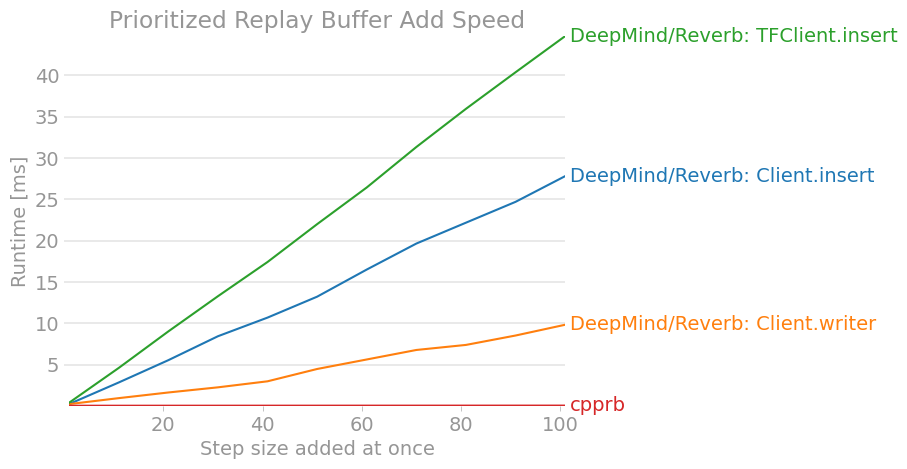
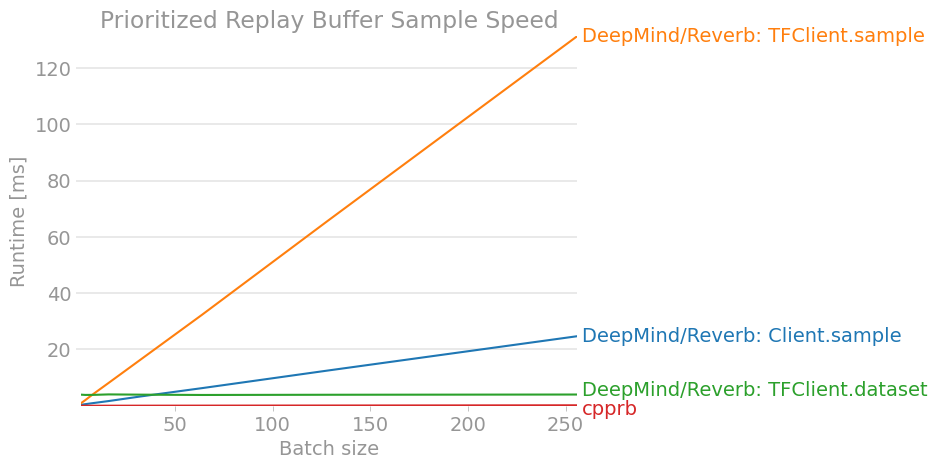
7. Schlussfolgerung
Wir haben untersucht und organisiert, wie der Reverb-Client des DeepMind Experience Replay-Frameworks verwendet wird. Im Vergleich zu anderen Wiederholungspufferimplementierungen wie OpenAI / Baselines war das Verständnis schwierig, da es viele Unterschiede in der API und Verwendung gibt. (Ich hoffe, es wird ein wenig einfacher zu verstehen sein, wenn die stabile Version veröffentlicht wird.)
Zumindest scheint es in Bezug auf die Leistung nicht überlegen zu sein, wenn wir nicht verteiltes Lernen in großem Maßstab durchgeführt und das gesamte Verstärkungslernen im TensorFlow-Berechnungsdiagramm abgeschlossen hätten.
Natürlich können verteiltes Lernen in großem Maßstab und verbessertes Lernen in Computergraphen die Leistung erheblich verbessern. Ich denke, wir müssen dies weiterhin berücksichtigen.
Recommended Posts