[PYTHON] Erhalten Sie Daten von Poloniex, einem virtuellen Geldwechsel, über die API und verwenden Sie Deep Learning, um den Preis des nächsten Tages vorherzusagen.
Einführung

Meine Damen und Herren, Hallo. Dies ist Yoshizaki (Twitter: @yoshizaki_kkgk), der repräsentative Direktor von Kikagaku Co., Ltd.
Lassen Sie uns nach langer Abwesenheit etwas Interessantes in unserem Urlaub machen! Dieser Artikel hatte die Idee. Wir hoffen, dass dieser Artikel den Lesern ein besseres Verständnis des Datenanalyseansatzes vermittelt.
Überraschenderweise die Antwort!
Letztes Mal habe ich einen Artikel für Anfänger geschrieben, um Daten von Liqui über den virtuellen Geldwechsel über die API zu erhalten. Vorheriger Artikel: Lassen Sie uns Informationen von der API des virtuellen Geldwechsels Liqui mit Python abrufen
Wie ich diesen Artikel geschrieben habe
Natürlich gab es eine Antwort aus dem vorherigen Artikel, aber wir veranstalten "** De-Black-Box-Seminar für künstliche Intelligenz / maschinelles Lernen ** Als nächsten Schritt erhielten wir viele Fragen von den Studenten, die an "/ seminars /)" teilnahmen, wie z. B. "Wie soll ich studieren?", Und übergaben sie als nächsten Schritt. Ich wollte einen technischen Artikel schreiben, den ich Ihnen geben könnte.
Ich dachte, welche Art von technischem Artikel sollte geschrieben werden, um auf die Stimmen der Studenten zu reagieren, und ich suchte nach etwas, das Folgendes befriedigen könnte.
- Vollständige Daten können leicht abgerufen werden → ** Virtuelle Währung **
- Genießen Sie die Visualisierung und Verarbeitung von Daten → ** Zeitreihendaten ** ――Sie können modernste Techniken üben → ** Deep Learning **
Und
** Hoffentlich gibt es Vorteile **
Vor diesem Hintergrund habe ich beschlossen, die fortschrittlichste Zeitreihenanalysemethode unter Verwendung der virtuellen Währung als Thema einzuführen.
Dieses Ziel
Ich sehe oft Artikel über das Erstellen einer Umgebung oder das Abrufen von Daten, aber ich möchte immer die Artikel lesen, die von Anfang bis Ende erklären **, also für mich Ich werde einen Artikel schreiben, den ich auch für andere interessant finde.
- ** Erstellen Sie eine Umgebung, um die Poloniex-API mit Python zu verwenden **
- Holen Sie sich ** Poloniex ** Daten über die API -Laden Sie Daten in ** Pandas ** und berechnen Sie den gleitenden Durchschnitt
- ** Visualisieren Sie Ihre Daten mit Matplotlib **
- ** Multiple Regressionsanalyse ** sagt den Preis für den nächsten Tag voraus -Vorgeben Sie den Preis für den nächsten Tag mit ** RNN (LSTM) ** unter Verwendung von ** Chainer **
Zusammenfassend lässt sich sagen, dass die Vorhersagen mithilfe von Deep Learning noch verbessert werden können! Ich werde in diesem Artikel jedoch so weit schreiben, dass er in die Diskussion über Versuch und Irrtum einbezogen werden kann. Es besteht ein großer Bedarf an Preis- / Nachfrageprognosen für virtuelle Währungen, aber ich hoffe, Sie werden feststellen, dass dies immer noch schwierig ist.
Außerdem habe ich diese Methode verbessert und relativ gute Ergebnisse erzielt! Wenn ja, lassen Sie es mich bitte wissen! → Yoshizaki (Twitter: @yoshizaki_kkgk)
Erstellen einer Umgebung zur Verwendung der Poloniex-API mit Python
Aufbau einer Python-Umgebung
Wenn Sie Python nicht auf Ihrem PC installiert haben, befolgen Sie zunächst die Schritte im folgenden Artikel. Bisher haben Hunderte von Menschen an dem von unserem Unternehmen veranstalteten Seminar teilgenommen, aber es handelt sich um ein fast fehlerfreies Einstellungsverfahren.
Bitte beachten Sie, dass das Einstellungsverfahren zwischen Windows und Mac unterschiedlich ist.
· Für Windows [Definitive Edition] Erstellen einer Umgebung zum Lernen von "maschinellem Lernen" mit Python unter Windows
Installieren Sie das Poloniex-Modul
Öffnen wir zuerst das ** Jupyter-Notizbuch **.
Wenn Sie den folgenden Befehl im Terminal ausführen (Eingabeaufforderung / Windows Powershell), wird die Umgebung gestartet, die über den Browser ausgeführt werden kann.
jupyter notebook
Tatsächlich kann Jupyter Notebook per Pip installiert werden, was praktisch ist, da Sie das Terminal nicht jedes Mal öffnen müssen.
Verwenden Sie "pip" für Windows und "pip3" für Mac.
- Ich benutze
pip3, weil ich auf einem Mac arbeite.
Bitte beachten Sie, dass bei Verwendung von pip in Jupyter Notebook Folgendes hinzugefügt werden muss!
# python-Poloniex installieren
!pip3 install https://github.com/s4w3d0ff/python-poloniex/archive/v0.4.6.zip
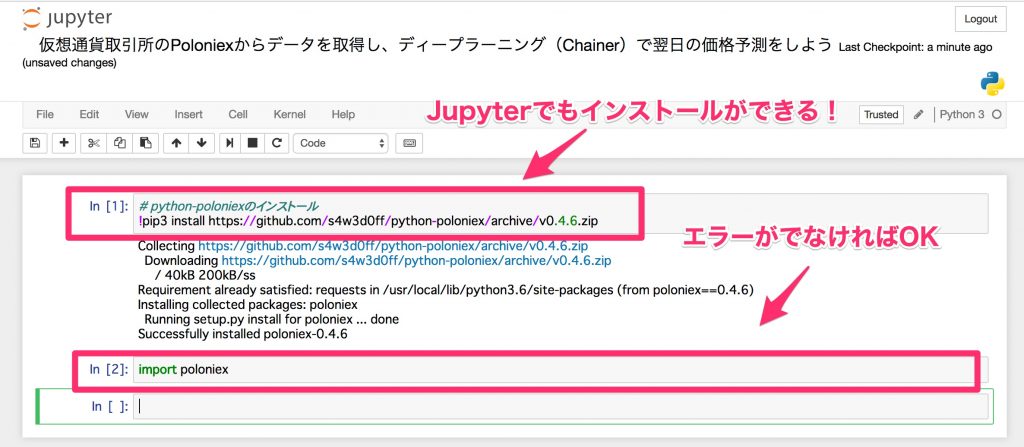
Importieren Sie es nach der Installation und überprüfen Sie, ob es korrekt installiert ist.
import poloniex
Jetzt können Sie die Daten von Poloniex über die API abrufen.
Mit der API von Poloniex können Sie Daten abrufen, indem Sie auf die URL klicken. Die Schnittstelle für Python, die die Verwendung noch einfacher macht, ist diesmal "Python-Poloniex" installiert. Diese Dinge, die die gleichen Funktionen haben, aber für den Menschen einfach zu bedienen sind (Wrap), werden Wrapper genannt, und in der Programmierindustrie werden diese Dinge häufig hergestellt und veröffentlicht.
Holen Sie sich Poloniex-Daten über die API
Daten bekommen
Lassen Sie uns nun die Daten von Poloniex abrufen, die das Hauptthema sind. Mit Poloniex können Sie Daten im Wert von mehreren Jahren gleichzeitig abrufen, sodass Sie auf frühere Daten zugreifen können, ohne sie selbst speichern zu müssen. Dies ist eine sehr willkommene Umgebung für Analysen auf Prototypenebene.
Dank des Poloniex-Wrappers können Sie die Daten mit einer einzigen Befehlszeile wie folgt abrufen: Passen Sie das Abtastintervall und die Anzahl der Tage nach Bedarf an.
import time
#Vorbereiten der Poloniex-API
polo = poloniex.Poloniex()
#Lesen Sie 100 Tage in 5-Minuten-Intervallen ab (Abtastintervall 300 Sekunden).
chart_data = polo.returnChartData('BTC_ETH', period=300, start=time.time()-polo.DAY*100, end=time.time())
Leider besteht die einzige Möglichkeit, das Abtastintervall und die Anzahl der Tage (insbesondere das Abtastintervall) festzulegen, darin, den auf GitHub geschriebenen Quellcode zu lesen.
Wenn Sie den Quellcode darin lesen, finden Sie die folgenden Kommentare.
def returnChartData(self, currencyPair, period=False, start=False, end=False):
""" Returns candlestick chart data. Parameters are "currencyPair",
"period" (candlestick period in seconds; valid values are 300, 900,
1800, 7200, 14400, and 86400), "start", and "end". "Start" and "end"
are given in UNIX timestamp format and used to specify the date range
for the data returned (default date range is start='1 day ago' to
end='now') """
Das heißt, der Zeitraum umfasst "300" (5 Minuten), "900" (15 Minuten), "1800" (1 Stunde), "7200" (4 Stunden), "14400" (8 Stunden), "86400" (12). Zeit) kann angegeben werden. Auch wenn dies nicht in diesem Kommentar enthalten ist, können Sie "polo.DAY" verwenden, wenn Sie den Zeitraum auf ein Tagesintervall festlegen möchten.
Als ich die diesmal erfassten Daten überprüfte, wurden die Daten im folgenden Format gespeichert.
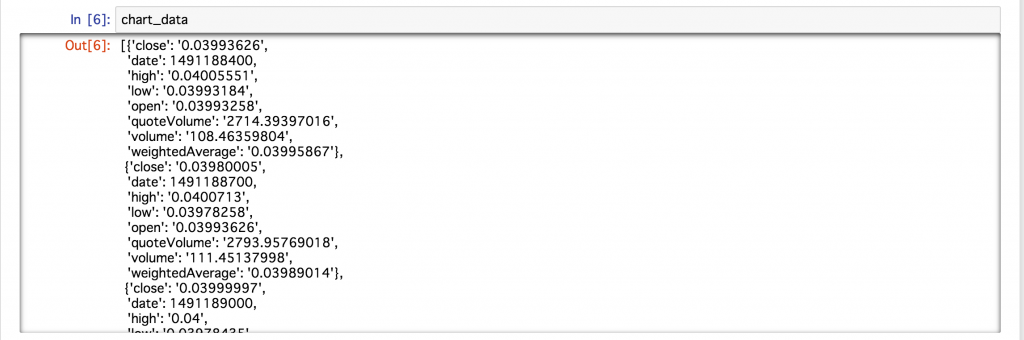
Es scheint, dass die obigen Daten für jede Abtastzeit im Wörterbuchtyp gespeichert sind. Da es so ist, ist es schwierig, es als Daten zu behandeln. Lassen Sie uns die Daten daher effizient mit Pandas extrahieren, was für Datenbankoperationen praktisch ist.
Laden Sie Daten in Pandas und berechnen Sie den gleitenden Durchschnitt
Laden Sie Daten in Pandas
Pandas ist definitiv nützlich, wenn Sie Daten in Python bearbeiten (Bedienbarkeit + viele Referenzartikel). Sie können auch das Jupyter-Notizbuch verwenden, um Ihre Tabelle einfach und übersichtlich zu visualisieren.
Das Laden von Daten in Pandas ist einfach. Insbesondere wenn das Datenetikett und der Wert für jede Abtastzeit enthalten sind, wie in diesem Fall, können sie einfach unter Verwendung des "DataFrame" von Pandas gelesen werden.
#Pandas importieren
import pandas as pd
#Daten in Pandas importieren
df = pd.DataFrame(chart_data)
Wie viele von Ihnen vielleicht bereits wissen,
ModuleNotFoundError: No module named 'pandas'
Wenn Sie eine Fehlermeldung erhalten, dass es kein Modul namens pandas like gibt
!pip3 install pandas # !Kann in Jupyter Notebook mit installiert werden
Wenn Sie es so installieren, können Sie es sofort (oder pip) verwenden.
Lassen Sie uns nun die ersten 10 Zeilen anzeigen.
df.head(10)

** Ausgezeichnet! ** ** **
Sie können es einfach mit nur einem Befehl lesen und die Daten in einem sehr schönen Format überprüfen, sodass die Arbeit der Datenanalyse beschleunigt wird! Danke Pandas!
Übrigens, wenn Sie beispielsweise Daten nur für die geschlossene Spalte extrahieren möchten, können Sie sie extrahieren, indem Sie die Spalte einfach als df ['close'] benennen, was sehr einfach ist.

Berechnen wir den gleitenden Durchschnitt
Pandas macht es auch einfach, ** gleitende Durchschnitte ** zu berechnen.
Dieses Mal wurde die Fensterbreite zur Berechnung des Durchschnitts als Kurzzeitlinie auf 1 Tag und die Fensterbreite zur Berechnung des Durchschnitts für die Langzeitlinie auf 5 Tage festgelegt. Der Quellcode zur Berechnung des gleitenden Durchschnitts lautet wie folgt.
#Kurzzeitlinie: Fensterbreite 1 Tag (5 Minuten x 12 x 24)
data_s = pd.rolling_mean(df['close'], 12 * 24)
#Langzeitlinie: Fensterbreite 5 Tage (5 Minuten x 12 x 24 x 5)
data_l = pd.rolling_mean(df['close'], 12 * 24 * 5)
Damit ist die Berechnung abgeschlossen (einfach!). In diesem Fall können Sie versuchen, die Fensterbreite auf verschiedene Arten zu ändern!
Zeichnen wir nun den diesmal berechneten gleitenden Durchschnitt, da es schwierig ist, die Änderung nur anhand des numerischen Werts zu verstehen.
Visualisieren Sie Ihre Daten mit Matplotlib
Lass es uns zuerst benutzen
Matplotlib ist auch ein bekanntes Modul (Bibliothek) zur Visualisierung von Python. Sehen heißt glauben! Zeichnen wir es, einschließlich des gleitenden Durchschnitts!
#Laden Sie matplotlib (installieren Sie mit pip oder pip3, wenn ein Fehler auftritt)
import matplotlib.pyplot as plt
#Die einfachste Handlung
plt.plot(df['close'])
plt.show()

Oh! Ein solches Zeitreihendiagramm wurde angezeigt.
Räumen Sie Ihr Grundstück mit Seaborn auf
Wir werden Seaborn verwenden, eine Hülle für Matplotlib, die die Parzellen in Matplotlib noch sauberer machen kann. Wenn Sie die Breite so einstellen, dass der Bildschirm ausgefüllt wird, ist die Anzeige einfacher. Wenn Sie diese Einstellung beim Kopieren und Einfügen ein wenig ändern, ist die Analyse einfacher.
#Zeigen Sie die Zeichnung ordentlich an
from matplotlib.pylab import rcParams
import seaborn as sns
rcParams['figure.figsize'] = 15, 6
Zeichnen wir hier die vorherigen Daten.

Die Breite ist voll, Gitterlinien sind enthalten und der Hintergrund ist farbig, wodurch es sich schön anfühlt. Wenn man sich das Jupyter-Notizbuch ansieht, ist der Unterschied so offensichtlich.
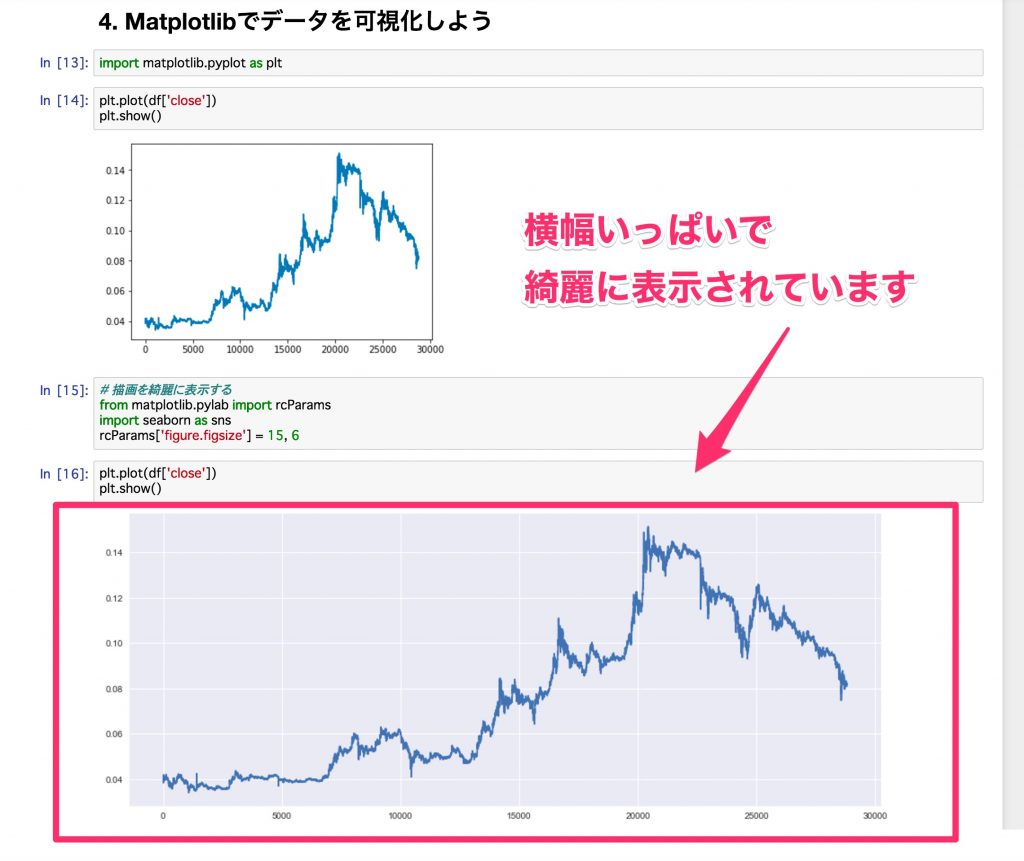
Die Hintergrundfarbe usw. kann auf der Seaborn-Seite geändert werden. Wenn Sie interessiert sind, lesen Sie bitte den folgenden Artikel.
Referenz: Einführung in Seaborn, eine Python-Bibliothek, die das Zeichnen schöner Grafiken erleichtert
Lassen Sie uns die Farbe des Diagramms ändern
Mit Matplotlib ist es auch sehr einfach, die Farben zu ändern. Sie können den Namen der Farbe (z. B. Blau oder Rot) in der Farboption verwenden. Wenn Sie sich besonders für schöne Farben interessieren, sollten Sie ihn im Format hexadezimal # ..... angeben.
#Geben wir die Farbe des Diagramms an (Farbe)
plt.plot(df['close'], color='#7f8c8d')
plt.show()

Auf diese Weise hat sich die Farbe geändert. Die Farbe dieses Mal wird aus diesen flachen UI-Farben ausgewählt.
Referenz: flache UI-Farben
Zeichnen wir die kurzfristige Linie und die langfristige Linie
Mit Matplotlib ist es auch sehr einfach, mehrere Zeilen zu zeichnen, zu deklarieren, was angezeigt werden soll, und schließlich "plt.show ()" und fertig. Zeichnen wir nun die Kurzzeitlinie und die Langzeitlinie, die auf der Pandas-Seite zusammen berechnet wurden.
#Es werden auch kurzfristige und langfristige Linien aufgezeichnet
plt.plot(df['close'], color='#7f8c8d')
plt.plot(data_s, color='#f1c40f') #Kurzfristige Leitung
plt.plot(data_l, color='#2980b9') #Langzeitlinie
plt.show()

Ich kann es gut zeichnen! Jetzt können Sie nicht nur den numerischen Wert visuell beurteilen, sondern auch, wie breit die Fensterbreite für die Kurzzeitlinie und die Langzeitlinie sein sollte!
Mit Pandas und Matplotlib ist es wirklich erstaunlich, dies in nur wenigen Zeilen analysieren zu können, und es ist ein Verlust, wenn Sie es nicht wissen.
Bisher haben wir die Daten, ** einfache Aggregation ** und ** Visualisierung ** erfasst. Von hier aus werden wir eine Datenanalysemethode vorstellen, die das fortgeschrittene maschinelle Lernen (Haupttechnologie der künstlichen Intelligenz) voll ausnutzt.
Dieser Bereich wird in unserem ** Systemautomatisierungsseminar ** ausführlicher behandelt. Wenn Sie also interessiert sind, tun Sie dies bitte!

Prognostizieren Sie den Preis des nächsten Tages mit einer multiplen Regressionsanalyse
Voraussetzungen für die Arbeit mit Zeitreihendaten
Dann denke ich, dass es viele Leute gibt, die sich fragen, ob es möglich ist, den Preis durch maschinelle Lerntechnologie vorherzusagen. Lassen Sie es uns also in einem praktischen Format sehen.
In ** Zeitreihendaten (Daten, die zu jedem Zeitpunkt schwanken) ** gibt es viele Tests, z. B. welche Art von Merkmalen als Voraussetzung für die Analyse vorliegen, und es ist nutzlos, wenn dieses Merkmal überhaupt nicht gelöscht wird. Es gibt viele Diskussionen über solche Theorien.
Natürlich denke ich, dass Sie es einzeln überprüfen sollten, aber es ist nicht das Wesentliche dieser Zeit, diese kleinen Eigenschaften zu sehen, aber können Sie den Preis wirklich durch maschinelles Lernen vorhersagen? ?? Zunächst möchte ich die Schlussfolgerung wissen, also lassen Sie uns diesmal eine kleine Diskussion über die Art dieser Daten hinterlassen.
Für diejenigen, die tiefer in diese Eigenschaft eintauchen möchten, werden die folgenden Artikel empfohlen, da sie detaillierte Informationen zu verschiedenen Merkmalen enthalten. Referenz: [Wichtige Punkte, die Anfänger der Zeitreihendatenanalyse wissen sollten - Regressionsanalyse - Was ist zu tun, bevor eine Korrelationsanalyse durchgeführt wird (Überprüfen und Transformieren der Datenform)](http://qiita.com / HirofumiYashima / items / b6dabe412c868d271410)
Lassen Sie uns den Preis unmittelbar danach vorhersagen
Dann werden wir beim maschinellen Lernen zunächst die Beziehung zwischen der Eingangsvariablen X und der Ausgangsvariablen y zuordnen.
- Im Programm sind die Lehrerdaten der Ausgabevariablen "t" und der vorhergesagte Wert der Ausgabevariablen ist "y".
Bei Vorhersagen anhand von Zeitreihendaten muss zunächst berücksichtigt werden, von welchen Eingabe- und Ausgabevariablen die aktuellen Daten getrennt werden sollen. Diesmal ist der Preis, den wir vorhersagen möchten (Ausgabevariable y), der Preis nach 5 Minuten, und der für die Vorhersage verwendete Faktor (Eingabevariable X) sind die letzten 30 Stichproben (5 Minuten x 30 Daten).
In vielen Fällen wird es auf diese Weise geteilt, aber in Wirklichkeit handelt es sich nicht um einfache Zeitreihendaten, sondern es wird häufig die Differenz oder der Logarithmus der Differenz genommen, aber Versuch und Irrtum um dies herum ist der nächste Schritt. Machen wir das.
#Lesen von numpy, das häufig in linearen Algebraoperationen verwendet wird
import numpy as np
#Da es als Zeichenfolge (String-Typ) über die API empfangen wird, konvertieren Sie es in einen Float-Typ.
#Außerdem empfiehlt Chainer float32, also passen Sie es hier an.
data = df['close'].astype(np.float32)
#Teilen Sie die Daten in Eingangsvariable x und Ausgangsvariable t
x, t = [], []
N = len(data)
M = 30 #Anzahl der Eingangsvariablen: Verwenden Sie die letzten 30 Samples
for n in range(M, N):
#Trennung von Eingangs- und Ausgangsvariablen
_x = data[n-M: n] #Eingangsvariablen
_t = data[n] #Ausgabevariablen
#Liste zur Berechnung(x, t)Wird hinzufügen
x.append(_x)
t.append(_t)
Wenn Sie es für spätere Analysen verwenden, ist es außerdem praktisch, die Daten im Numpy-Format zu speichern, z. B. um die Größe zu überprüfen und die Daten zu konvertieren.
#In das Numpy-Format konvertieren (zur Vereinfachung)
x = np.array(x)
t = np.array(t).reshape(len(t), 1) #Umformen ist eine Maßnahme, die später keinen Fehler in Chainer verursacht
Teilen Sie in Trainingsdaten (Zug) und Verifizierungsdaten (Test)
Machen Sie beim maschinellen Lernen ein Modell und beenden Sie es! Stattdessen wird es in zwei Daten unterteilt, um zu bestätigen, wie genau das erstellte Modell ist.
- ** Trainingsdaten (Zug) **: Daten zum Training des Modells
- ** Verifizierungsdaten (Test) **: Daten zur Überprüfung der Genauigkeit durch Abgleich der Antworten
- Als Weiterentwicklung gibt es auch einen Fall, in dem die Daten zur manuellen Bestimmung der Parameter, die innerhalb der als Hyperparameter bezeichneten Methode bestimmt werden sollen, in drei Teile unterteilt sind.
Lassen Sie uns zunächst das erstellte Modell fest verifizieren, indem Sie diese Trainingsdaten und Verifizierungsdaten in zwei Teile teilen. Dieses Mal machen die Trainingsdaten 70% der Gesamtzahl und die Verifizierungsdaten 30% der Gesamtzahl aus.
# 70%Für das Training 30%Zur Überprüfung
N_train = int(N * 0.7)
x_train, x_test = x[:N_train], x[N_train:]
t_train, t_test = t[:N_train], t[N_train:]
Wenn Sie die Listenschnitzfunktion von Python nutzen, können Sie Ihren Datensatz wie oben beschrieben problemlos aufteilen.
Lernen Sie ein Modell für die multiple Regressionsanalyse
In Python ist ** Scikit-learn ** der Standard für maschinelles Lernen. Wenn Sie sich nicht besonders mit der Schneide auskennen, werden hier fast alle Methoden implementiert, und vor allem ist die Schnittstelle für den Betrieb sehr gut, daher wird dies empfohlen.
Lassen Sie uns nun ein Modelltraining mit Scikit-learn (sklearn im Programm) implementieren.
# scikit-linear lernen_Lastmodell
from sklearn import linear_model
#Deklaration des multiplen Regressionsanalysemodells
reg = linear_model.LinearRegression()
#Lernen eines Modells anhand von Trainingsdaten
reg.fit(x_train, t_train)
Ja. Das ist es! Alles was Sie tun müssen, ist das Modell zu deklarieren, die Trainingsdaten an das Modell zu übergeben und "fit" zu machen. Es ist so einfach wie es sich anhört, aber ich bin sehr dankbar, dass dieser einfache Code Fehler von Menschen reduziert.
Wenn die Datenanalyse nicht funktioniert, ist es oft schwierig zu erkennen, ob die Daten schlecht oder das Programm schlecht sind. Wenn Sie diese Bibliotheken verwenden, können Sie Ihre eigene Verantwortung (Programmfehler) reduzieren Kann reibungslos ablaufen.
Überprüfen Sie das Modell
Lassen Sie uns die Genauigkeit anhand der obigen Überprüfungsdaten überprüfen. Als Genauigkeitsindex verwenden wir einen Index, der als Entscheidungskoeffizient bezeichnet wird und zwischen 0 und 1 berechnet wird (genau genommen ist auch ein Minus erforderlich). Grob gesagt ist 1 das Beste, 0 kommt nicht in Frage (obwohl der Ausdruck zu extrem ist).
Betrachten wir bei der Überprüfung auch den Wert des Bestimmungskoeffizienten nicht nur für die Überprüfungsdaten, sondern auch für die Trainingsdaten. Idealerweise ist ein gutes Modell gut, wenn die beiden Werte vergleichbar und genau sind.
Sie können score verwenden, um den Entscheidungskoeffizienten zu berechnen.
#Trainingsdaten
reg.score(x_train, t_train)
#Trainingsdaten
reg.score(x_train, t_train)

Wie oben erwähnt, liegt der Wert ** sehr nahe bei ** 1, und ich stelle mir die folgende Story-Entwicklung vor.
Willkommen bei Rich
"Oh! Ich denke, das kann mit wahnsinnig guter Genauigkeit vorhergesagt werden! Sie können von morgen an sehr reich sein." "Ich muss über Steuersparmaßnahmen nachdenken, weil ich mit Investitionen Geld verdienen kann." "Fangen wir hier mit Wohnungen an. Okay, kaufen wir 100 Millionen Dollar."
Ergebnisse visualisieren
Zeichnen wir nun den gemessenen Wert und den vorhergesagten Wert mit der Erwartung, dass der Entscheidungskoeffizient ein sehr guter Wert war.
Zeichnen Sie zunächst den gemessenen Wert (blau) und den vorhergesagten Wert (orange) für die Trainingsdaten.
#Trainingsdaten
plt.plot(t_train, color='#2980b9') #Der gemessene Wert ist blau
plt.plot(reg.predict(x_train), color='#f39c12') #Der vorhergesagte Wert ist orange
plt.show()

Sie sehen, dass sich die beiden Daten sehr gut überschneiden und fast übereinstimmen (weiterer Anstieg der Erwartungen). Da dies jedoch die Daten sind, die für das Training verwendet werden, ist es natürlich, dass es gut funktioniert. Das Hauptthema ist das Ergebnis für die Verifizierungsdaten.
Für die Verifizierungsdaten wird nun ein Diagramm des gemessenen Werts (blau) und des vorhergesagten Werts (orange) erstellt.
#Validierungsdaten
plt.plot(t_test, color='#2980b9') #Der gemessene Wert ist blau
plt.plot(reg.predict(x_test), color='#f39c12') #Der vorhergesagte Wert ist orange
plt.show()

Oh! Dies ist auch genau überlappend! Toll! Zu wunderbar! Dies mag den reichen Mann bestätigt haben.
Bis zum nächsten Mal in Dubai.
Fallen Sie von einem reichen Mann, der zu früh war
Eigentlich scheint das sehr gut zu funktionieren, aber es funktioniert überhaupt nicht wirklich. Leider dürfte Dubai etwas weiter entfernt sein. Ah, eine Million Dollar ... lol
Um zu erklären, was das bedeutet, schauen wir uns einen Teil der Validierungsdaten an, nicht das Ganze.
Wenn Sie ein Teil extrahieren, ist es in Ordnung, wenn Sie den Bereich mit plt.xlim () angeben.
#Schauen wir uns einen Teil zur Überprüfung an
plt.plot(t_test, color='#2980b9') #Der gemessene Wert ist blau
plt.plot(reg.predict(x_test), color='#f39c12') #Der vorhergesagte Wert ist orange
plt.xlim(200, 300) #Einige der Funktionen sind leicht zu verstehen
plt.show()

Eigentlich scheint die Vorhersage auf den ersten Blick gut zu sein, aber Sie können sehen, dass der vorhergesagte Wert (orange) einfach um eine Stichprobe vom gemessenen Wert (blau) abweicht. ..
Kurz gesagt, ich dachte, dass ein plausibler Wert durch Vorhersage nach dem Lernen durch maschinelles Lernen erhalten wurde, aber ich gab nur den Wert eine Stichprobe zuvor als vorhergesagten Wert aus, und es war überhaupt keine Methode, die meinen Kopf benutzte. Wenn der Wert vor 5 Minuten als vorhergesagter Wert verwendet wird, wird sicherlich ein plausibler Wert herauskommen und der Entscheidungskoeffizient wird hoch berechnet.
Wenn ich dies nach 1 Tag auf die Vorhersage anstatt auf die Vorhersage nach 5 Minuten änderte, wurde ein solches Ergebnis erhalten.
- Jeder, bitte versuchen Sie dieses Programm.

Dies ist eine Vorhersage für Trainingsdaten, aber das Ergebnis ist insbesondere, dass der vorhergesagte Wert die Daten nur um einen Tag verschiebt (1 Probe x 12 x 24 = 288 Proben in 5 Minuten).
Dies könnte der Grund sein, warum gesagt wird, dass die Nachfrageprognose durch Datenanalyse sehr schwer zu erreichen ist.
Warum passiert das?
Viele Techniken des maschinellen Lernens ermöglichen eine bessere Anpassung, indem Werte, die als Parameter bezeichnet werden, im Modell angepasst werden, um den Fehler durchgehend zu reduzieren. Und in Zeitreihendaten wie dieser Zeit tritt ein Phänomen namens ** Random Walk ** auf, das die Schwierigkeit der Parametereinstellung erhöht.
Dies bedeutet, dass die Wahrscheinlichkeit, dass der Preis in der nächsten Stichprobe steigt oder fällt, 5: 5 im Vergleich zur vorherigen Stichprobe beträgt. Bei einem durchschnittlichen Durchschnitt von 5: 5 (erwarteter Wert) lautet die Antwort auf die Frage, ob der nächste Preis weder steigen noch fallen wird. Infolgedessen ist es die Theorie, dass es am besten ist, den Wert des vorherigen Tages so wiederzugeben, wie er im Wert des nächsten Tages ist.
Beim maschinellen Lernen wird diese Argumentation ausschließlich aus den Daten abgeleitet und im vorhergesagten Wert wiedergegeben.
Als Test sieht das Histogramm wie folgt aus, wenn man den Preisunterschied zum Vortag betrachtet.
#Nehmen Sie den Unterschied zur vorherigen Probe
t_diff = t[:-1] - t[1:]
#Seaborn Distroplot ist bequem
sns.distplot(t_diff)
plt.show()

Die Breite des Behälters ist etwas breit, schauen wir uns das genauer an. Außerdem werden die gezeichneten Linien (Ergebnisse der Schätzung des Kerneldichteverhältnisses) nicht benötigt. Löschen Sie sie daher.
#Erhöhen Sie die Anzahl der Fächer, kde(Schätzung des Gaußschen Kerndichteverhältnisses)Planen Sie ab
sns.distplot(t_diff, bins=3000, kde=False)
plt.xlim(-0.00075, 0.00075)
plt.ylim(0, 750)
plt.show()

Die rechte Hälfte von 0 gibt an, wie oft der Preis gegenüber dem Vortag gestiegen ist, und die linke Hälfte von 0 gibt an, wie oft der Preis gegenüber dem Vortag gefallen ist. Wie Sie sehen können, ist es symmetrisch um 0 verteilt. Daher ist es ein 5: 5 ** zufälliger Spaziergang **, egal ob er hoch oder runter geht. Hinweis: Es gibt verschiedene statistische Testmethoden zur Bestimmung der zufälligen Gehfähigkeit, nicht visuell. Wenn Sie also interessiert sind, lesen Sie diese bitte durch.
Was soll ich machen?
Bei Methoden des maschinellen Lernens wie der multiplen Regressionsanalyse wird angenommen, dass ** Daten zu jedem Zeitpunkt unabhängig von der tatsächlichen Verteilung generiert werden **. Mit anderen Worten, es wird angenommen, dass ** die Daten zum vorherigen Zeitpunkt die Daten zum nächsten Mal nicht beeinflussen ** (sie sollten zufällig aus der wahren Verteilung generiert werden).
Wenn es beispielsweise um die Schätzung der Miete geht, enthält die erste Stichprobe die Bedingungen für das Haus von Herrn A (Entfernung vom Bahnhof, Größe des Zimmers) und die zweite Stichprobe die Bedingungen für das Haus von Herrn B. Insbesondere hat das Haus von Herrn A jedoch keine Beziehung zum Haus von Herrn B (es wird unabhängig generiert).
Daher sind bei der Zeitreihenanalyse, bei der die Daten der vorherigen Zeit einen großen Einfluss haben, die Annahmen in erster Linie unterschiedlich, sodass sie natürlich nicht funktionieren sollten.
Das Hidden Markov-Modell war dasjenige, das diese Eigenschaft modellieren wollte. Die ausführliche Erklärung wird weggelassen, da der folgende Artikel sie auf wunderbare und leicht verständliche Weise erklärt. Kurz gesagt, ** Ich habe einen Mechanismus erstellt, der vorhersagen kann, selbst wenn die vorherigen Daten die nächsten Daten beeinflussen **. ..
Referenz: Zeitreihendaten: Grundlagen des Hidden-Markov-Modells und der Plattform des wiederkehrenden Netzes
Und es wird auch im Deep Learning implementiert, das in den letzten Jahren boomte, ** Recurrent Neural Network **, sogenanntes ** RNN **.
Am Ende dieses Artikels möchte ich abschließend die Modellierung mit diesem ** RNN ** vorstellen.
Prognostizieren Sie die Preise für den nächsten Tag mit RNN (LSTM) mithilfe von Chainer
Was ist Chainer?

** Chainer ** ist ein Framework, das mit ** Python ** verwendet werden kann und auf ** Deep Learning (neuronales Netzwerk) ** spezialisiert ist, das von der japanischen Firma ** Preferred Networks ** entwickelt wurde. Es gibt auch TensorFlow, das von Google und seinem Wrapper Keras bereitgestellt wird, und ich persönlich bin der Meinung, dass viele Menschen in Japan beide verwenden.
** Chainer wurde ursprünglich mit einer leicht zu erlernenden Oberfläche erstellt ** und ist im Vergleich zu anderen Frameworks sehr flexibel, wenn Sie die Deep-Learning-Entwicklung auf Papierebene anpassen ** Ich finde es attraktiv, dass du es schaffst **.
Der Mechanismus mit dem Namen ** Define by Run ** unterscheidet sich erheblich von anderen Frameworks wie TensorFlow von Google. Für Anfänger ** können Sie den numerischen Wert und die Größe während des Lernens überprüfen **. Der Vorteil ist das einfache Debuggen ** (ich habe direkt vom Chainer-Entwickler gehört). Natürlich ist es für Entwickler sehr wichtig, wie es sich während des Lernens verhält und wo der Fehler auftritt, daher ist die Übernahme dieser Struktur ein großer Vorteil. Ich fühle es ist *.
Unser Unternehmen ist das einzige offizielle Schulungsunternehmen in Japan (Stand: 27. Juli 2017), das die Chainer-Technologie von Preferred Networks in der Gesellschaft verbreitet. Machen. Darüber hinaus arbeiten wir mit Microsoft zusammen, um ein praktisches Deep-Learning-Seminar abzuhalten, in dem Sie lernen, wie Sie die Implementierung von Deep Learning durch Chainer auf einem GPU-Computer unter Microsoft Azure beschleunigen können. Wenn Sie also ** hier möchten ** Bitte werfen Sie einen Blick darauf.

Lassen Sie uns mit LSTM vorhersagen
Lassen Sie uns nun eine Methode namens ** LSTM (Long Short-Term Memory) ** implementieren, die häufig in RNN implementiert wird. Es gibt verschiedene Gründe, aber da LSTM oft als RNN eingeführt wird, denke ich, dass es gut ist, sich am Anfang an RNN ≒ LSTM zu erinnern.
Laden Sie das gewünschte Modul
Chainer muss verschiedene Module laden, und Sie werden sich daran gewöhnen, wenn Sie es verwenden, damit Sie es zuerst kopieren und einfügen können. Die unten verwendeten sind auf das erforderliche Minimum beschränkt, daher ist es eine gute Idee, sich nur den Namen zu merken.
import chainer
import chainer.links as L
import chainer.functions as F
from chainer import Chain, Variable, datasets, optimizers
from chainer import report, training
from chainer.training import extensions
Definieren wir das Modell von LSTM
Ganz zu schweigen von Chainer. Wenn Sie nicht mit der Verwendung von Python vertraut sind, fällt es Ihnen möglicherweise zunächst schwer, aber vorerst haben wir den Abschnitt "L.LSTM" eingefügt, sodass es in Ordnung ist, genügend Intervalle für die Implementierung von LSTM zu haben.
class LSTM(Chain):
#Geben Sie die Struktur des Modells an
def __init__(self, n_units, n_output):
super().__init__()
with self.init_scope():
self.l1 = L.LSTM(None, n_units) #LSTM-Schicht hinzugefügt
self.l2 = L.Linear(None, n_output)
#Setzen Sie den in LSTM gespeicherten Wert zurück
def reset_state(self):
self.l1.reset_state()
#Berechnung der Verlustfunktion
def __call__(self, x, t, train=True):
y = self.predict(x, train)
loss = F.mean_squared_error(y, t)
if train:
report({'loss': loss}, self)
return loss
#Vorwärtsausbreitungsberechnung
def predict(self, x, train=False):
l1 = self.l1(x)
h2 = self.l2(h1)
return h2
Der Rest ist für diejenigen, die an Chainer gewöhnt sind. Da LSTM jedoch eine Struktur hat, die den Status intern enthält, verwenden Sie "reset_state ()", um ihn jedes Mal im internen Status zu halten, wenn Sie lernen. Sie müssen den Wert zurücksetzen, den Sie haben. Es ist in Ordnung, diesen Bereich zu nutzen, also lasst uns nach und nach lernen.
Passen Sie den Updater für LSTM an
Dies ist der Stolperpunkt, und es ist sehr schwierig, es selbst zu machen.
Chainer wurde eine neue Funktion namens "Trainer" hinzugefügt. Wenn Sie die erforderlichen Informationen wie das Modell im Voraus festlegen und dann "Trainer.run ()" verwenden, wird das Lernen automatisch gestartet und der Lernstatus. Eine benutzerfreundliche Funktion wurde hinzugefügt, z. B. die Überprüfung des Fortschritts von. Da das Innere jedoch auf gute Weise zu einer Blackbox verarbeitet wurde, wurde es schwierig, es selbst anzupassen.
Bei Verwendung von LSTM muss das erste geschriebene "reset_state ()" ausgeführt werden, um den Statuswert für jede Lernschleife zu initialisieren, aber das im offiziellen Tutorial usw. beschriebene "Training". Wenn .StandardUpdater verwendet wird, wird "reset_state ()" für jede Lernschleife (offensichtlich) nicht ausgeführt, und das Lernen des LSTM-Systems kann nicht gut durchgeführt werden. Als ich den Entwickler von Chainer fragte, sagte er mir, dass dies mit den folgenden zwei Methoden gelöst werden kann.
- Passen Sie sich an, indem Sie die Funktion des Update-Teils von
training.StandardUpdaterüberschreiben - Schreiben in zustandslosem LSTM
Die letztere Methode ist schwierig, da die intern gehaltenen Variablen selbst geschrieben und übergeben werden und die erstere Methode zur Lösung des Problems verwendet wird.
Erstellen Sie Ihren eigenen LSTMupdater, der training.StandardUpdater erbt.
Es wurde gesagt, dass der Update-Teil in update_core beschrieben ist, also werde ich diese Funktion überschreiben.
class LSTMUpdater(training.StandardUpdater):
def __init__(self, data_iter, optimizer, device=None):
super(LSTMUpdater, self).__init__(data_iter, optimizer, device=None)
self.device = device
def update_core(self):
data_iter = self.get_iterator("main")
optimizer = self.get_optimizer("main")
batch = data_iter.__next__()
x_batch, y_batch = chainer.dataset.concat_examples(batch, self.device)
#↓ hier zurücksetzen_state()Ermöglicht das Laufen
optimizer.target.reset_state()
#Andere entsprechen dem Zeitreihen-Update
optimizer.target.cleargrads()
loss = optimizer.target(x_batch, y_batch)
loss.backward()
#Kette in Zeitreihen lösen_backward()Es scheint, dass die Berechnungseffizienz zunehmen wird
loss.unchain_backward()
optimizer.update()
Bereiten Sie Trainings- und Validierungsdaten für Chainer vor
Für den von Chainer verwendeten Datensatz ist es erforderlich, Daten in Form einer Liste oder eines Numpy vorzubereiten, und für jede Stichprobe ist es erforderlich, sie in einem Taple mit Eingabe und Ausgabe zusammenzufassen und aufzulisten. Es wird schwierig sein, in Sätzen zu schreiben, aber es ist in Ordnung, wenn Sie es als "Liste (zip (..., ...))" angeben. Es ist schwierig, eine Referenz zu finden, daher fragen Sie sich möglicherweise, wie Sie Ihr eigenes Dataset für die Verwendung mit Chainer erstellen können. Dies ist jedoch die von Chainer-Entwicklern empfohlene Methode.
#Wenn der Datensatz für Chainer ausreicht, um in den Speicher zu passen, listen Sie ihn auf(zip(...))Empfohlen
#↑ Vom PFN-Entwickler empfohlene Methode
train = list(zip(x_train, t_train))
test = list(zip(x_test, t_test))
In Fällen, in denen das Dataset nicht in den Speicher passt (z. B. Zehntausende von Bilddaten), kann das TupleDataset von Chainer verwendet werden, um die Daten nur dann effizient in den Speicher zu laden, wenn sie stapelweise verwendet werden. Es scheint implementiert zu sein. Wenn Sie also der Meinung sind, dass die Datengröße groß und langsam ist, verwenden Sie diese Option.
Informationen zu TupleDataset: https://docs.chainer.org/en/stable/reference/datasets.html
Vorbereitung zum Trainer
Zu diesem Zeitpunkt ist die Vorbereitung abgeschlossen. Stellen Sie sie im folgenden Ablauf auf "Trainer" ein.
- Modelldeklaration: Verwenden Sie das erstellte Modell --Definition des Optimierers: Wählen Sie die Optimierungsmethode aus und ordnen Sie sie dem Modell zu
- Definition von Iteratoren: Isolieren Sie Datensätze nach Batch --Definition des Updaters: Aktualisieren Sie die Update-Regeln usw.
- Trainerdefinition: Fassen Sie die Einstellungen für die Trainingsausführung zusammen
Korrigieren Sie den Startwert zu Beginn mit dem folgenden Befehl und vergessen Sie nicht, ** die Reproduzierbarkeit sicherzustellen **. Wenn Sie dies vergessen, ändern sich die Ergebnisse zwischen heute und morgen und Sie werden verletzt, wenn Sie versuchen, sich morgen bei Ihrem Chef zu melden.
#Sicherstellung der Reproduzierbarkeit
np.random.seed(1)
Lassen Sie uns den obigen Ablauf sofort durchgehen.
#Modelldeklaration
model = LSTM(30, 1)
#Definition des Optimierers
optimizer = optimizers.Adam() #Der Optimierungsalgorithmus verwendet Adam
optimizer.setup(model)
#Definition des Iterators
batchsize = 20
train_iter = chainer.iterators.SerialIterator(train, batchsize)
test_iter = chainer.iterators.SerialIterator(test, batchsize, repeat=False, shuffle=False)
#Definition des Updaters
updater = LSTMUpdater(train_iter, optimizer)
#Definition des Trainers
epoch = 30
trainer = training.Trainer(updater, (epoch, 'epoch'), out='result')
#Trainererweiterung
trainer.extend(extensions.Evaluator(test_iter, model)) #Auswertung mit Auswertungsdaten
trainer.extend(extensions.LogReport(trigger=(1, 'epoch'))) #Zeigen Sie die Mitte des Lernergebnisses an
#Ausgabeverlust für Zugdaten und Verlust für Testdaten für jede Epoche
trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'validation/main/loss', 'elapsed_time']), trigger=(1, 'epoch'))
Ausführung des Lernens
Die Ausführung des Lernens beginnt mit dem folgenden Befehl.
trainer.run()

Wie oben erwähnt, wird es in ** interaktiv ** angezeigt, sodass es sehr praktisch ist, den Lernprozess auf einen Blick zu sehen.
Dieses Mal werden die obigen Lernergebnisse erhalten, aber der "Verlust" für die Trainingsdaten nimmt ab, aber der "Verlust" für die Verifizierungsdaten nimmt eher zu als ab. Bitte versuchen Sie es mit verschiedenen Versuchen und Fehlern, z. B. mit ** Dropout **.
Bonus: Modell mit zusätzlichem Ausfall
Übrigens ist es bei der Übernahme von Dropout in Ordnung, ein solches Modell zu erstellen.
class LSTM(Chain):
def __init__(self, n_units, n_output):
super().__init__()
with self.init_scope():
self.l1 = L.LSTM(None, n_units)
self.l2 = L.Linear(None, n_output)
def reset_state(self):
self.l1.reset_state()
def __call__(self, x, t, train=True):
y = self.predict(x, train)
loss = F.mean_squared_error(y, t)
if train:
report({'loss': loss}, self)
return loss
def predict(self, x, train=False):
#Dropout hinzufügen (nur während des Trainings verwenden)
if train:
h1 = F.dropout(self.l1(x), ratio=0.05)
else:
h1 = self.l1(x)
h2 = self.l2(h1)
return h2
Als dieser Ausfall hinzugefügt wurde, nahm auch der Validierungsverlust stetig ab, so dass für solche Daten Maßnahmen zur Überanpassung (Überlernen) erforderlich zu sein scheinen.
Zeichnen Sie die Ergebnisse
Schauen wir uns zunächst die Trainingsdaten an.
#Berechnung des vorhergesagten Wertes
model.reset_state()
y_train = model.predict(Variable(x_train)).data
#Handlung
plt.plot(t_train, color='#2980b9') #Der gemessene Wert ist blau
plt.plot(y_train, color='#f39c12') #Der vorhergesagte Wert ist orange
plt.show()

Es scheint, dass Sie es bis zu einem gewissen Grad vorhersagen können.
Schauen wir uns als nächstes die Verifizierungsdaten an.
#Berechnung des vorhergesagten Wertes
model.reset_state()
y_test = model.predict(Variable(x_test)).data
#Handlung
plt.plot(t_test, color='#2980b9') #Der gemessene Wert ist blau
plt.plot(y_test, color='#f39c12') #Der vorhergesagte Wert ist orange
plt.show()
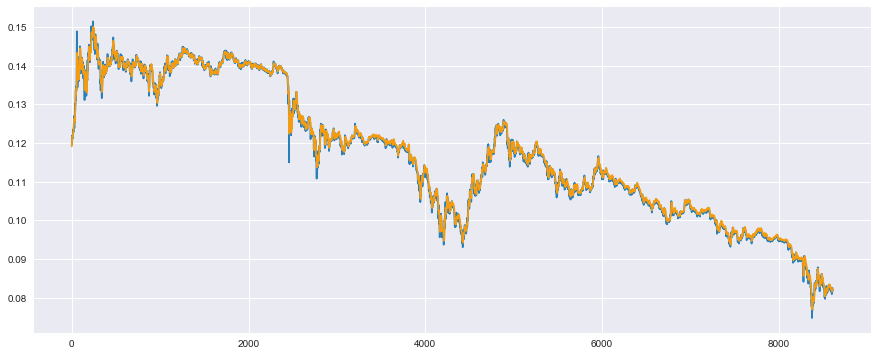
Es scheint, dass die Verifizierungsdaten bis zu einem gewissen Grad vorhergesagt werden können. Ich würde dies gerne quantitativ bewerten, aber der zuvor erwähnte Entscheidungsfaktor liefert recht gute Ergebnisse, selbst wenn es eine Zeitverzögerung gibt. Daher ist er nicht zuverlässig. Schauen wir uns das an.
Nun schauen wir uns an, was rein aus war.
#Schauen wir uns einen Teil zur Überprüfung an
plt.plot(t_test, color='#2980b9') #Der gemessene Wert ist blau
plt.plot(y_test, color='#f39c12') #Der vorhergesagte Wert ist orange
plt.xlim(200, 300) #Einige der Funktionen sind leicht zu verstehen
plt.show()

Irgendwie scheint das Problem einer einfacheren Abweichung als bei der vorherigen multiplen Regressionsanalyse gelöst worden zu sein. Es gibt jedoch immer noch eine leichte Zeitverzögerung, so dass es nicht perfekt ist.
Zukunftsaussichten
Dieses Mal war das Ziel, es grob zu verwenden, also plane ich, von nun an Versuch und Irrtum zu machen. Wir planen, den folgenden Versuch und Irrtum einzuführen, wenn wir eine andere Chance haben.
- Berücksichtigen Sie andere Preise als die virtuelle Währung, die den Eingabevariablen entsprechen
- Berücksichtigen Sie andere Indikatoren wie Differenz und Protokoll der Differenz
Ursprünglich wird gesagt, dass Merkmale wie das letztere automatisch als Merkmale im neuronalen Netzwerk erstellt werden, aber es scheint nicht so ideal zu sein, und es wird als menschliches Know-how verstanden. Es wird gesagt, dass es besser ist, es gehorsam hinzuzufügen, wenn es sich um eine Feature-Menge handelt, die so gut ist wie sie ist, also denke ich, ich sollte diesen Bereich auch ausprobieren.
abschließend
Mir ist aufgefallen, dass es ein sehr langer Artikel war, aber es gibt nicht viele technische Blogs, die ich von Anfang bis Ende durchgesehen habe, und ich bin glücklich, viele Dinge zu schreiben, die ich schreiben möchte, und dies ist für Leser. Ich hoffe, es hilft.
Der Begriff Datenanalyse klingt hübsch, erfordert aber auch technisches Know-how wie das Erfassen und Formen solcher Daten sowie mathematische Überlegungen beim Erstellen von Chainers LSTM. Es ist eine schwierige und unterhaltsame Aufgabe, schnell ein breites Spektrum an Wissen aufzunehmen. Probieren Sie es also aus.
Wir freuen uns auf Ihr Follow-up
Wir bieten Informationen zu maschinellem Lernen und künstlicher Intelligenz aus geschäftlicher Sicht sowie empfohlene Nachschlagewerke.
Kikagaku Co., Ltd. (Offizielle HP) Präsident und CEO Ryosuke Yoshizaki
- Twitter:@yoshizaki_kkgk
- Facebook:@ryosuke.yoshizaki --Blog: Blog des Kikagaku-Vertreters
Bis zum Ende Danke fürs Lesen.