Schnelles Web-Scraping mit Python (unterstützt das Laden von JavaScript)
Einführung
Es ist häufig der Fall, dass Sie ein bestimmtes Element von einer Webseite extrahieren und ein Durcheinander verursachen möchten. (Ich möchte alle 5 Minuten den Bestand und den Preis eines bestimmten Produkts auf einer bestimmten EC-Site anzeigen. Ich möchte den Text für die Klassifizierung von Dokumenten usw. genau extrahieren.) Eine solche Elementextraktion wird als Web-Scraping bezeichnet, und Python ist in solchen Fällen ebenfalls nützlich.
Übrigens gibt es Crawler / Scraping Adventskalender 2014, der perfekt für diesen Zweck geeignet ist, und die folgenden Artikel sind gut organisiert. (Ich habe seine Existenz vor einiger Zeit bemerkt) http://orangain.hatenablog.com/entry/scraping-in-python
Lass es uns zuerst versuchen
Wie am Ende des vorherigen Artikels erwähnt, sind `Anfragen``` und` lxml``` beim Scraping in Python im Allgemeinen ausreichend.
pip install requests
pip install lxml
Lassen Sie uns nun den Textteil von der folgenden Seite der Tele-Asa-Nachrichten extrahieren. http://news.tv-asahi.co.jp/news_politics/articles/000041338.html
Lassen Sie uns zunächst sehen, wie die Seite organisiert ist. In Chrome gibt es standardmäßig Entwicklertools (siehe unten) (Firebug in Firefox). Wenn Sie es starten, klicken Sie auf das Lupensymbol und bewegen Sie den Mauszeiger auf den Teil, den Sie extrahieren möchten. Sie können das Zielelement problemlos treffen Sie können sehen, was für eine Seitenstruktur ist.
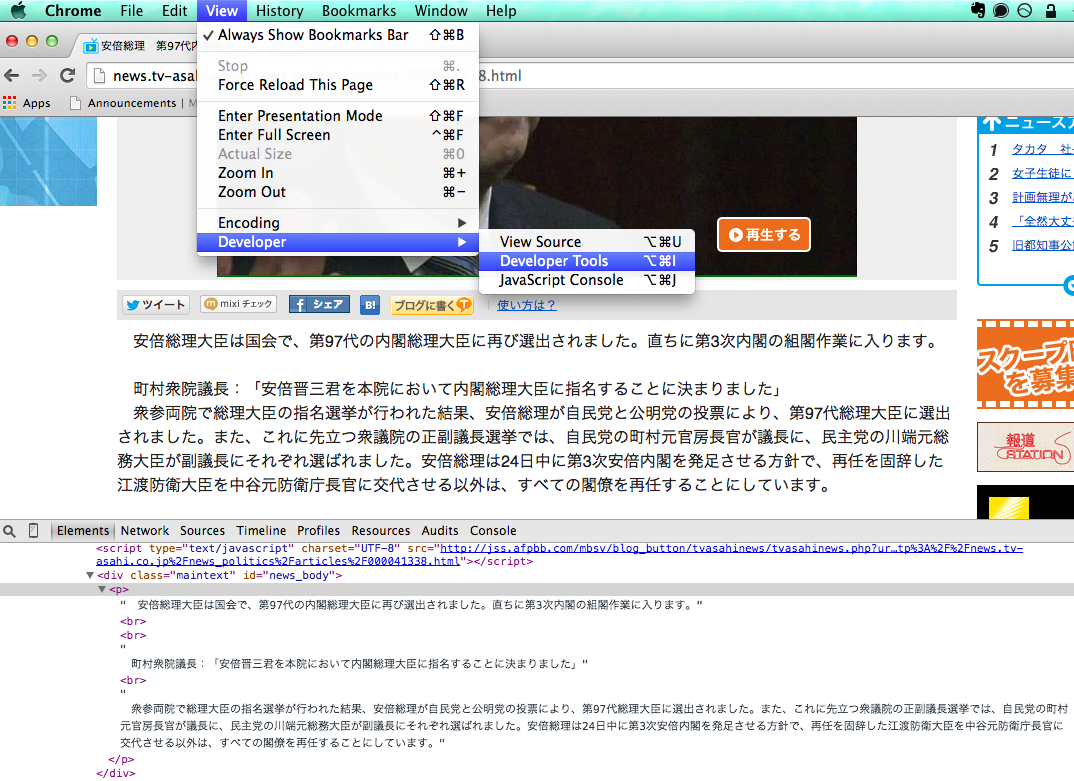
<div class="maintext" id="news_body">Unter dem Tag<p>Sie können sehen, dass der gewünschte Satz weiter unter dem Tag liegt.
Dieser Speicherort kann mithilfe des CSS-Selektors als `` `# news_body> p``` ausgedrückt werden, sodass der Scraping-Code, der diesen Teil des Textes schließlich extrahiert, wie folgt geschrieben werden kann:
vgl. Zusammenfassung der CSS-Selektoren http://weboook.blog22.fc2.com/blog-entry-268.html
import lxml.html
import requests
target_url = 'http://news.tv-asahi.co.jp/news_politics/articles/000041338.html'
target_html = requests.get(target_url).text
root = lxml.html.fromstring(target_html)
#text_content()Die Methode ruft den gesamten Text unter diesem Tag ab
root.cssselect('#news_body > p').text_content()
Wenn `ImportError: cssselect nicht installiert zu sein scheint. Wenn Sie wütend werden, können Sie ``pip install cssselect``` ausführen.
Wie Sie sehen können, ist es sehr einfach.
Laden Sie JavaScript
Der nächste schwierige Teil ist der Teil, der in JavaScript gerendert wird. Wenn ich es mit den Entwicklertools wie zuvor betrachte, denke ich, dass es auf die gleiche Weise verwendet werden kann, aber tatsächlich ist dies das Ergebnis des Ladens und Renderns von JavaScript.

Das HTML vor dem Laden von JavaScript ist einfach so.
<!--ähnliche Neuigkeiten-->
<div id="relatedNews"></div>
Selbst wenn Sie versuchen, das durch Anfragen erhaltene HTML so zu analysieren, wie es ist, funktioniert es nicht. Hier kommen Selen und PhantomJS ins Spiel.
Pip installieren Selen und PhantomJS[hier in der Gegend](http://tips.hecomi.com/entry/20121229/1356785834)Bitte installieren Sie es unter Bezugnahme auf.
Dann sieht die Version, die JavaScript lädt, so aus.
Wenn Sie HTML über Selen & PhantomJS erhalten, ist der Rest des Prozesses der gleiche.
```py
import lxml.html
from selenium import webdriver
target_url = 'http://news.tv-asahi.co.jp/news_politics/articles/000041338.html'
driver = webdriver.PhantomJS()
driver.get(target_url)
root = lxml.html.fromstring(driver.page_source)
links = root.cssselect('#relatedNews a')
for link in links:
print link.text
Ausführungsergebnis
Das 3. Abe-Kabinett wird in Kürze ins Leben gerufen. Nur der Verteidigungsminister wird ersetzt.
Shinzo Abe zum 97. Premierminister des Repräsentantenhauses ernannt
Einberufung eines Sonderparlaments heute: Das 3. Abe-Kabinett wurde nachts eingerichtet
Zur Errichtung des 3. Abe-Kabinetts lehnt Verteidigungsminister Eto die Wiederernennung ab
"Ein fruchtbares Jahr" Premierminister Abe blickt auf dieses Jahr zurück
Zusammenfassung
Wie oben erwähnt, konnte ich nicht nur normale HTML-Seiten, sondern auch Seiten mit JavaScript-Rendering schnell und einfach kratzen. Wenn Sie tatsächlich verschiedene Websites kratzen, haben Sie häufig Probleme mit Zeichencodeproblemen. Wenn Sie jedoch Web-Scraping durchführen können, können Sie verschiedene Aufgaben automatisieren, also in verschiedenen Situationen Es ist persönlich nützlich. Ich wünsche Ihnen ein schönes Weihnachts- und Web-Scraping-Leben.
Recommended Posts