Binäre Klassifizierung nach Entscheidungsbaum nach Python ([Informationen zur Informationsabteilung der High School II] Unterrichtsmaterialien für die Lehrerausbildung)
Einführung
Ein Entscheidungsbaum ist ein Diagramm der Baumstruktur für Entscheidungen im Bereich der Entscheidungstheorie. Es gibt Regression (Regressionsbaum) und Klassifizierung (Klassifizierungsbaum) als Szenen, in denen der Entscheidungsbaum verwendet wird, aber ich möchte bestätigen, wie der Entscheidungsbaum für die Klassifizierung verwendet wird. Insbesondere möchte ich den Mechanismus bei der Implementierung in Python bestätigen, was in "Vorhersage durch Klassifizierung" in den auf der Seite des Ministeriums für Bildung, Kultur, Sport, Wissenschaft und Technologie veröffentlichten Materialien zur Lehrerausbildung von Information II aufgegriffen wird. Ich werde.
Lehrmaterial
[Informationsabteilung der High School "Information II" Lehrmaterialien für Lehrer (Hauptband): Ministerium für Bildung, Kultur, Sport, Wissenschaft und Technologie](https://www.mext.go.jp/a_menu/shotou/zyouhou/detail/mext_00742.html "Informationsabteilung der High School Unterrichtsmaterialien "Information II" für die Lehrerausbildung (Hauptteil): Ministerium für Bildung, Kultur, Sport, Wissenschaft und Technologie ") Kapitel 3 Informations- und Datenwissenschaft, zweite Hälfte (PDF: 7,6 MB)
Umgebung
- ipython
- Colaboratory - Google Colab
Teile, die in den Unterrichtsmaterialien aufgenommen werden sollen
Lernen 15 Vorhersage nach Klassifizierung: "2. Binäre Klassifizierung nach Entscheidungsbaum"
Ich würde gerne sehen, wie es funktioniert, wenn der in R in Python geschriebene Quellcode implementiert wird.
Diesmal werden Daten verarbeitet
Laden Sie Titandaten von kaggle auf die gleiche Weise wie die Lehrmaterialien herunter. Dieses Mal werde ich titans "train.csv" verwenden.
https://www.kaggle.com/c/titanic/data
Dies sind die Daten, die das "Überleben / Tod", "Zimmergrad", "Geschlecht", "Alter" usw. einiger Passagiere in Bezug auf den Titanic-Unfall beschreiben. Zunächst möchte ich mein Verständnis des Entscheidungsbaums vertiefen, indem ich ein Implementierungsbeispiel gebe, in dem die im Lehrmaterial beschriebene Implementierung in R hier durch Python ersetzt wird.
Implementierungsbeispiel und Ergebnis in Python
Laden und Vorverarbeiten von Daten (Python)
Von train.csv benötigen wir nur die Informationen zu Klasse (Raumnote), Geschlecht (Geschlecht), Alter (Alter) und Überleben (Überleben 1, Tod 0), sodass wir nur die erforderlichen Teile extrahieren. Fehlende Werte werden als "NaN" behandelt, und wir werden mit der Richtlinie zum Entfernen fehlender Werte fortfahren.
Originaldaten lesen, Daten extrahieren, fehlende Werte verarbeiten (Quellcode)
import numpy as np
import pandas as pd
from IPython.display import display
from numpy import nan as NaN
titanic_train = pd.read_csv('/content/train.csv')
#Originaldatenanzeige
display(titanic_train)
# Pclass(Zimmerqualität)、Sex(Sex)、Age(Alter)、Survived(Überleben 1,Tod 0)
titanic_data = titanic_train[['Pclass', 'Sex', 'Age', 'Survived']]
display(titanic_data)
#Fehlender Wert'NaN'Beseitigen, abschütteln
titanic_data = titanic_data.dropna()
display(titanic_data)
#Überprüfen Sie die Daten, um festzustellen, ob fehlende Werte entfernt wurden
titanic_data.isnull().sum()
Originaldaten lesen, Daten extrahieren, fehlende Werte verarbeiten (Ausgabeergebnis)
Lesen der Originaldaten

Datenextraktion

Ergebnis der Datenverarbeitung für fehlende Werte

Überprüfen Sie die Daten, um festzustellen, ob fehlende Werte entfernt wurden

Ausführung der Visualisierung des Entscheidungsbaums (Quellcode)
Ich werde dtreeviz verwenden, um den Entscheidungsbaum mit Python zu visualisieren, da er leicht zu sehen ist.
dtreeviz Installation
!pip install dtreeviz pydotplus
Visualisierung von Entscheidungsbäumen durchführen
import sklearn.tree as tree
from dtreeviz.trees import dtreeviz
##Konvertieren Sie männlich in 0 und weiblich in 1
titanic_data["Sex"] = titanic_data["Sex"].map({"male":0,"female":1})
# 'Survived'Charakteristische Matrix mit Daten, die durch Spalten schauen
# 'Survived'Zielvariable für Spalten
X_train = titanic_data.drop('Survived', axis=1)
Y_train = titanic_data['Survived']
#Erstellen Sie einen Entscheidungsbaum (die maximale Tiefe des Baums wird mit 3 angegeben)
clf = tree.DecisionTreeClassifier(random_state=0, max_depth = 3)
model = clf.fit(X_train, Y_train)
viz = dtreeviz(
model,
X_train,
Y_train,
target_name = 'alive',
feature_names = X_train.columns,
class_names = ['Dead','Sruvived']
)
#Entscheidungsbaumanzeige
display(viz)
Ausführung der Visualisierung des Entscheidungsbaums (Ausgabe)

Bei der Analyse des Entscheidungsbaums muss berücksichtigt werden, wie tief der Baum analysiert werden soll. Wenn der Entscheidungsbaum nicht in einer geeigneten Tiefe gestoppt wird, kann es zu einer Überanpassung kommen, die zu den für die Analyse verwendeten Trainingsdaten passt, und die Generalisierungsleistung kann sich verschlechtern. Aufgrund der diesmaligen Anzeige wird die maximale Tiefe mit 3 angegeben, sodass sie nicht zu tief eingestellt ist. Im Lehrmaterial wird jedoch ein Parameter mit mäßiger Komplexität angegeben und der Baum wird beschnitten. Ich mache (beschneiden), also möchte ich genauso vorgehen.
Beschneidung
Wenn man sich ansieht, wie gut die bedingte Verzweigung jedes Knotens des Entscheidungsbaums erfolgt, wird häufig ein Parameter namens Verunreinigung verwendet. Je kleiner dieser Parameter ist, desto einfacher ist der Standard. Zeigt an, dass die Klassifizierung abgeschlossen wurde. Ein weiterer wichtiger Faktor ist der Komplexitätsparameter, der angibt, wie komplex der gesamte Baum ist. In diesem Quellcode wird die Unreinheit zum Zeitpunkt der Erzeugung des Entscheidungsbaums als Gini-Unreinheit bezeichnet. (DecisionTreeClassifier () Argumentkriterien {"gini", "entropy"}, default = "gini") Als Methode zum Generieren des Entscheidungsbaums verwenden wir einen Algorithmus namens Minimale Kosten-Komplexitäts-Bereinigung. Dies ist ein Algorithmus, der einen Entscheidungsbaum generiert, der die Kosten für die Baumgenerierung (Anzahl der Knoten am Ende des Baums x Baumkomplexität + Baumverunreinigung) minimiert, da er als Bereinigung der Komplexität bei minimalen Kosten bezeichnet wird. Wenn die Komplexität hoch ist, hat die Anzahl der Abschlussknoten einen starken Einfluss auf die Baumerzeugungskosten, und wenn der bestimmte Baum durch das Beschneiden der Komplexität mit minimalen Kosten erzeugt wird, wird ein kleinerer Baum (geringere Tiefe und Anzahl von Knoten) erzeugt. Ich kann es schaffen Wenn andererseits die Komplexität gering ist, ist der Effekt der Baumerzeugungskosten aufgrund der Anzahl der Endknoten gering, und wenn ein Entscheidungsbaum erzeugt wird, kann ein großer und komplexer Baum (kleine Tiefe und Anzahl von Knoten) erzeugt werden.
Ich habe über ein grobes Bild gesprochen, ohne mathematische Formeln zu verwenden, aber es gibt viele offizielle Dokumente und andere Websites, die ausführlich erklärt werden. Daher ist es möglicherweise eine gute Idee, genauer hinzuschauen. [Referenz] https://scikit-learn.org/stable/modules/tree.html#minimal-cost-complexity-pruning
Beschneiden (Quellcode)
Beziehung zwischen Parametern in Bezug auf Komplexität und Parametern in Bezug auf Unreinheit
import matplotlib.pyplot as plt
#Erstellen Sie einen Entscheidungsbaum (keine maximale Baumtiefe angegeben)
clf = tree.DecisionTreeClassifier(random_state=0)
model = clf.fit(X_train, Y_train)
path = clf.cost_complexity_pruning_path(X_train, Y_train)
# ccp_alphas:Parameter in Bezug auf die Komplexität
# impurities:Parameter in Bezug auf Unreinheit
ccp_alphas, impurities = path.ccp_alphas, path.impurities
fig, ax = plt.subplots()
ax.plot(ccp_alphas[:-1], impurities[:-1], marker='o', drawstyle="steps-post")
ax.set_xlabel("effective alpha")
ax.set_ylabel("total impurity of leaves")
ax.set_title("Total Impurity vs effective alpha for training set")
Beziehung zwischen Komplexitätsparametern und der Anzahl der generierten Knoten und der Tiefe des Baums
clfs = []
for ccp_alpha in ccp_alphas:
clf = tree.DecisionTreeClassifier(random_state=0, ccp_alpha=ccp_alpha)
clf.fit(X_train, Y_train)
clfs.append(clf)
print("Number of nodes in the last tree is: {} with ccp_alpha: {}".format(
clfs[-1].tree_.node_count, ccp_alphas[-1]))
clfs = clfs[:-1]
ccp_alphas = ccp_alphas[:-1]
node_counts = [clf.tree_.node_count for clf in clfs]
depth = [clf.tree_.max_depth for clf in clfs]
fig, ax = plt.subplots(2, 1)
ax[0].plot(ccp_alphas, node_counts, marker='o', drawstyle="steps-post")
ax[0].set_xlabel("alpha")
ax[0].set_ylabel("number of nodes")
ax[0].set_title("Number of nodes vs alpha")
ax[1].plot(ccp_alphas, depth, marker='o', drawstyle="steps-post")
ax[1].set_xlabel("alpha")
ax[1].set_ylabel("depth of tree")
ax[1].set_title("Depth vs alpha")
fig.tight_layout()
Beschneiden (Ausgabeergebnis)
Beziehung zwischen Parametern in Bezug auf Komplexität und Parametern in Bezug auf Unreinheit

Beziehung zwischen Komplexitätsparametern und der Anzahl der generierten Knoten und der Tiefe des Baums

Im Lehrmaterial wird der Baum auf eine Tiefe von etwa 1 bis 2 beschnitten. Wenn also der Komplexitätsparameter ccp_alpha etwa 0,041 beträgt, die Tiefe 1 beträgt, die Anzahl der Knoten etwa 1 beträgt und wenn ccp_alpha etwa 0,0151 beträgt, ist er tief. Sie können sehen, dass es sich wahrscheinlich um 2 und 3 Knoten handelt.
Bestimmen des Baums nach dem Beschneiden (Quellcode)
ccp_alpha=0.041
clf = tree.DecisionTreeClassifier(ccp_alpha = 0.041)
model = clf.fit(X_train, Y_train)
viz = dtreeviz(
model,
X_train,
Y_train,
target_name = 'alive',
feature_names = X_train.columns,
class_names = ['Dead','Sruvived']
)
display(viz)
ccp_alpha=0.0151
clf = tree.DecisionTreeClassifier(ccp_alpha = 0.0151)
model = clf.fit(X_train, Y_train)
viz = dtreeviz(
model,
X_train,
Y_train,
target_name = 'alive',
feature_names = X_train.columns,
class_names = ['Dead','Sruvived']
)
display(viz)
Entscheidungsbaum nach dem Beschneiden (Ausgabeergebnis)
ccp_alpha=0.041

ccp_alpha=0.0151

Wenn wir uns diese ansehen, können wir sehen, dass der größte Faktor, der Leben und Tod trennt, das Geschlecht ist und Frauen eher gerettet werden. Selbst für Männer ist die Überlebensrate umso höher, je jünger sie sind (= Kinder). Bei Frauen ist die Überlebensrate umso höher, je höher die Note des Raums ist.
Kommentar
Die Unterrichtsmaterialien haben die folgende Beschreibung.
Leben oder Tod dieses Unfalls Der größte Faktor, der das Leben oder den Tod dieses Unfalls bestimmt, war das Geschlecht. Es kann auch gelesen werden, dass die Besatzung Frauen und Kinder aktiv rettete. Darüber hinaus scheint die Überlegenheit oder Unterlegenheit der Kabine kein Faktor für die Bestimmung von Leben oder Tod zu sein.
Als Ergebnis der Implementierung und Ausgabe durch mich schien es, dass *** die Überlegenheit oder Unterlegenheit der Kabine auch ein Faktor bei der Bestimmung von Leben oder Tod *** war. Die Zusammensetzung des Entscheidungsbaums war unabhängig davon, ob es sich um Python oder R handelte, gleich. Daher ist es wichtig, nicht nur die Ergebnisse der Unterrichtsmaterialien zu betrachten, sondern sie auch tatsächlich auszuführen und auf Ihre eigene Weise zu analysieren. Ich dachte.
[Referenz] Implementierungsbeispiel und Ergebnisse in R (aus Unterrichtsmaterialien)
Daten lesen und vorverarbeiten (R)
Lesen der Originaldaten (Quellcode)
titanic.train<-read.csv("/content/train.csv") #Geben Sie den Datenspeicherort an str(titanic.train)
### Lesen der Originaldaten (Ausgabeergebnis)
> ```console
'data.frame': 891 obs. of 12 variables:
$ PassengerId: int 1 2 3 4 5 6 7 8 9 10 ...
$ Survived : int 0 1 1 1 0 0 0 0 1 1 ...
$ Pclass : int 3 1 3 1 3 3 1 3 3 2 ...
$ Name : Factor w/ 891 levels "Abbing, Mr. Anthony",..: 109 191 358 277 16 559 520 629 417 581 ...
$ Sex : Factor w/ 2 levels "female","male": 2 1 1 1 2 2 2 2 1 1 ...
$ Age : num 22 38 26 35 35 NA 54 2 27 14 ...
$ SibSp : int 1 1 0 1 0 0 0 3 0 1 ...
$ Parch : int 0 0 0 0 0 0 0 1 2 0 ...
$ Ticket : Factor w/ 681 levels "110152","110413",..: 524 597 670 50 473 276 86 396 345 133 ...
$ Fare : num 7.25 71.28 7.92 53.1 8.05 ...
$ Cabin : Factor w/ 148 levels "","A10","A14",..: 1 83 1 57 1 1 131 1 1 1 ...
$ Embarked : Factor w/ 4 levels "","C","Q","S": 4 2 4 4 4 3 4 4 4 2 ...
Datenextraktion (Quellcode)
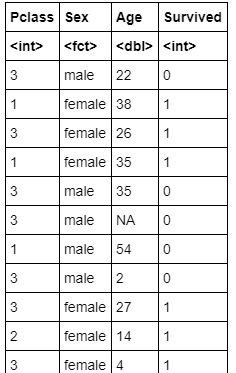
titanic.data<-titanic.train[,c("Pclass","Sex","Age","Survived")] titanic.data
### Datenextraktion (Ausgabeergebnis)
> 
### Fehlender Wert (NA) (Quellcode)
> ```R
titanic.data<-na.omit(titanic.data)
Ausführung der Visualisierung des Entscheidungsbaums (Quellcode)
install.packages("partykit") library(rpart) library(partykit) titanic.ct<-rpart(Survived~.,data=titanic.data, method="class") plot(as.party(titanic.ct),tp_arg=T)
### Ausführung der Visualisierung des Entscheidungsbaums (Ausgabeergebnis)
> <img width = "480" alt = "Download (12) .png " src = "https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/677025/4c8bf0fc-369b -137d-21b4-4c41e77c0741.png ">
### Klassifikationsbaum CP (Quellcode)
> ```R
printcp(titanic.ct)
Klassifikationsbaum CP (Ausgabeergebnis)
Classification tree: rpart(formula = Survived ~ ., data = titanic.data, method = "class")
Variables actually used in tree construction: [1] Age Pclass Sex
Root node error: 290/714 = 0.40616
n= 714
CP nsplit rel error xerror xstd
1 0.458621 0 1.00000 1.00000 0.045252 2 0.027586 1 0.54138 0.54138 0.038162 3 0.012069 3 0.48621 0.53793 0.038074 4 0.010345 5 0.46207 0.53448 0.037986 5 0.010000 6 0.45172 0.53793 0.038074
### Klassifizierungsbaum (Quellcode), wenn CP auf 0,028 eingestellt ist
> ```R
titanic.ct2<-rpart(Survived~.,data=titanic.data, method="class", cp=0.028)
plot(as.party(titanic.ct2))
Ausführung der Visualisierung des Entscheidungsbaums (Ausgabeergebnis)

Klassifizierungsbaum (Quellcode), wenn CP 0,027 ist
titanic.ct3<-rpart(Survived~.,data=titanic.data, method="class", cp=0.027) plot(as.party(titanic.ct3))
### Ausführung der Visualisierung des Entscheidungsbaums (Ausgabeergebnis)
> <img width = "480" alt = "Download (14) .png " src = "https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/677025/74101e1b-623e -94c1-40a5-8a700a5e7ec2.png ">
# Quellcode
Python-Version
https://gist.github.com/ereyester/dfb4fd6fb3e58c5d0539866f7e2622b4
R-Version
https://gist.github.com/ereyester/182d5d49ea04be579da2ffc82412a82a
Recommended Posts