[PYTHON] N-Kreuz-Methode
N-Kreuz-Methode
Als ich die blinde Schallquellentrennung (BASS) für die Stimme von ILRMA anwendete, wurde die Stimme zu einer unterdrückten Trennung anstelle einer vollständigen Trennung (Nullstellen der Stimme des Sprechers, der nicht das Ziel ist). Es ist eine Methode, die entwickelt wurde, damit auch solche Stimmen {VAD} sein können. Die Name-N-Kreuz-Methode ist ein Name, den ich entsprechend angegeben habe, daher glaube ich nicht, dass Sie durch Suchen Referenzen finden können.
Überblick
Es gibt eine Methode namens Nulldurchgangsmethode, die für die Sprachaktivitätserkennung (VAD) verwendet wird. Da diese jedoch einen geringen Rauschwiderstand aufweist, handelt es sich im Allgemeinen um einen Rahmen, der auf dem Gaußschen Mischungsmodell (GMM) basiert. Die Abschnittserkennung wird basierend auf der Sprach- / Nicht-Sprachidentifikation des Geräts durchgeführt. Da die Schallquelle diesmal durch ILRMA getrennt ist, kann der Schalldruckpegel für unbeabsichtigte Sprache zwar nicht unterdrückt werden, er kann jedoch nicht vollständig auf Null reduziert werden, sodass selbst die Stimme des Teils, der nach der GMM-Methode nicht erforderlich ist, als Sprachabschnitt behandelt wird Ich werde am Ende. Aus diesem Grund haben wir eine Methode implementiert, mit der die Zielstimme auch dann erkannt werden kann, wenn sich im Hintergrund eine Stimme befindet. Diese Methode wird diesmal als "N-Kreuz-Methode" bezeichnet. Ich denke, dass diese Methode nicht nur für diese Methode verwendet werden kann, sondern auch für Situationen wie Geschäftsverhandlungen in einem Café, in denen wahrscheinlich externes Audio eingemischt wird oder wenn Hintergrundmusik in der Tonquelle enthalten ist. 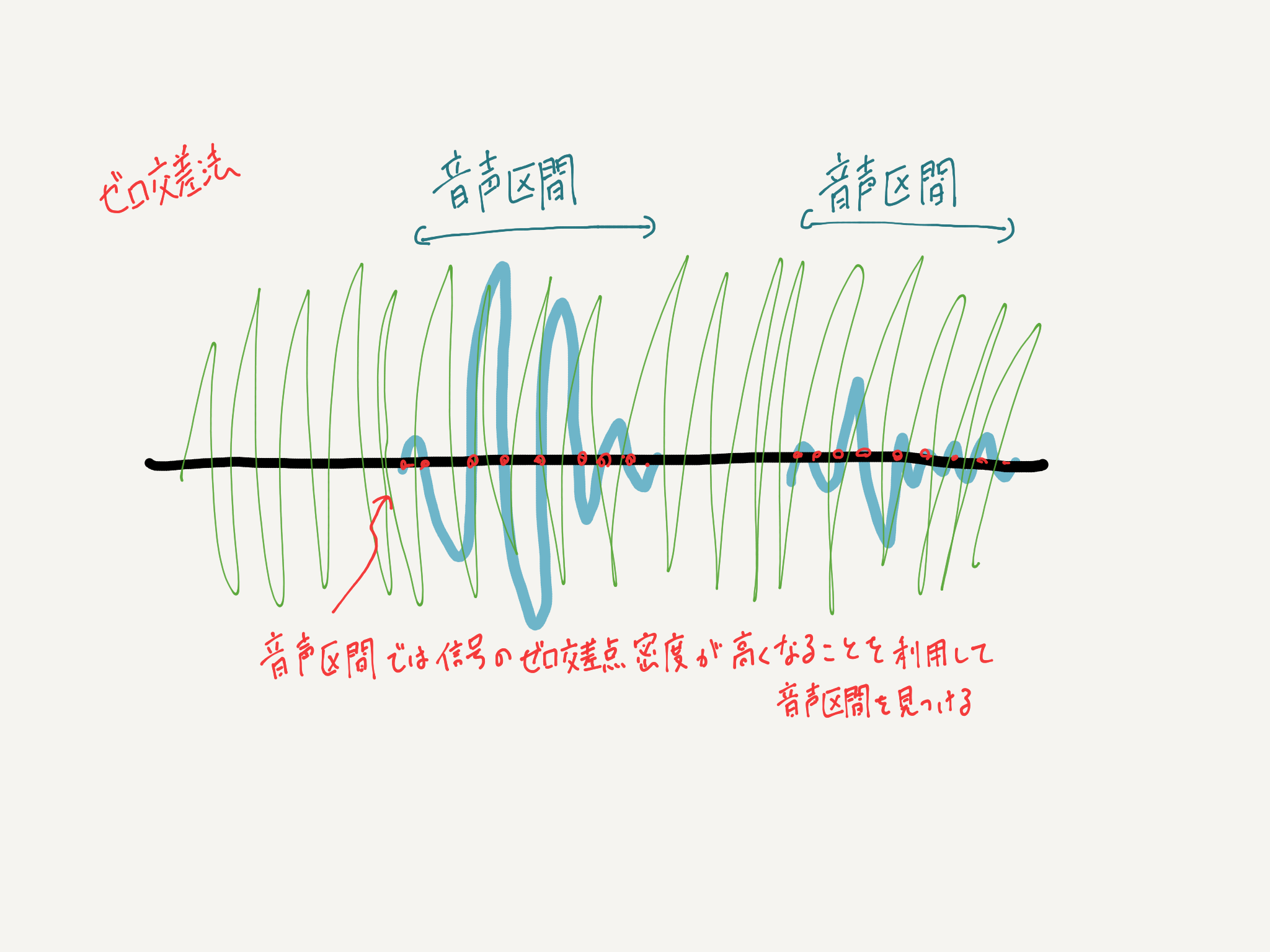
Theorie
Die Theorie ist einfach: Bei der Nullschnittmethode wird der Abschnitt, bei dem die Schnittfrequenz an der Linie von Y = 0 in Bezug auf die Sprachwellenform hoch ist, als Sprachabschnitt erfasst, aber bei dieser Methode wird sogar eine kleine Stimme erfasst, so dass N- Die Kreuzmethode verwendet einen Schnittpunkt mit einem beliebigen Wert von Y = N. Wir nennen diesen N-Wert * N-Kreuzlinie * oder * Empfindlichkeit *. 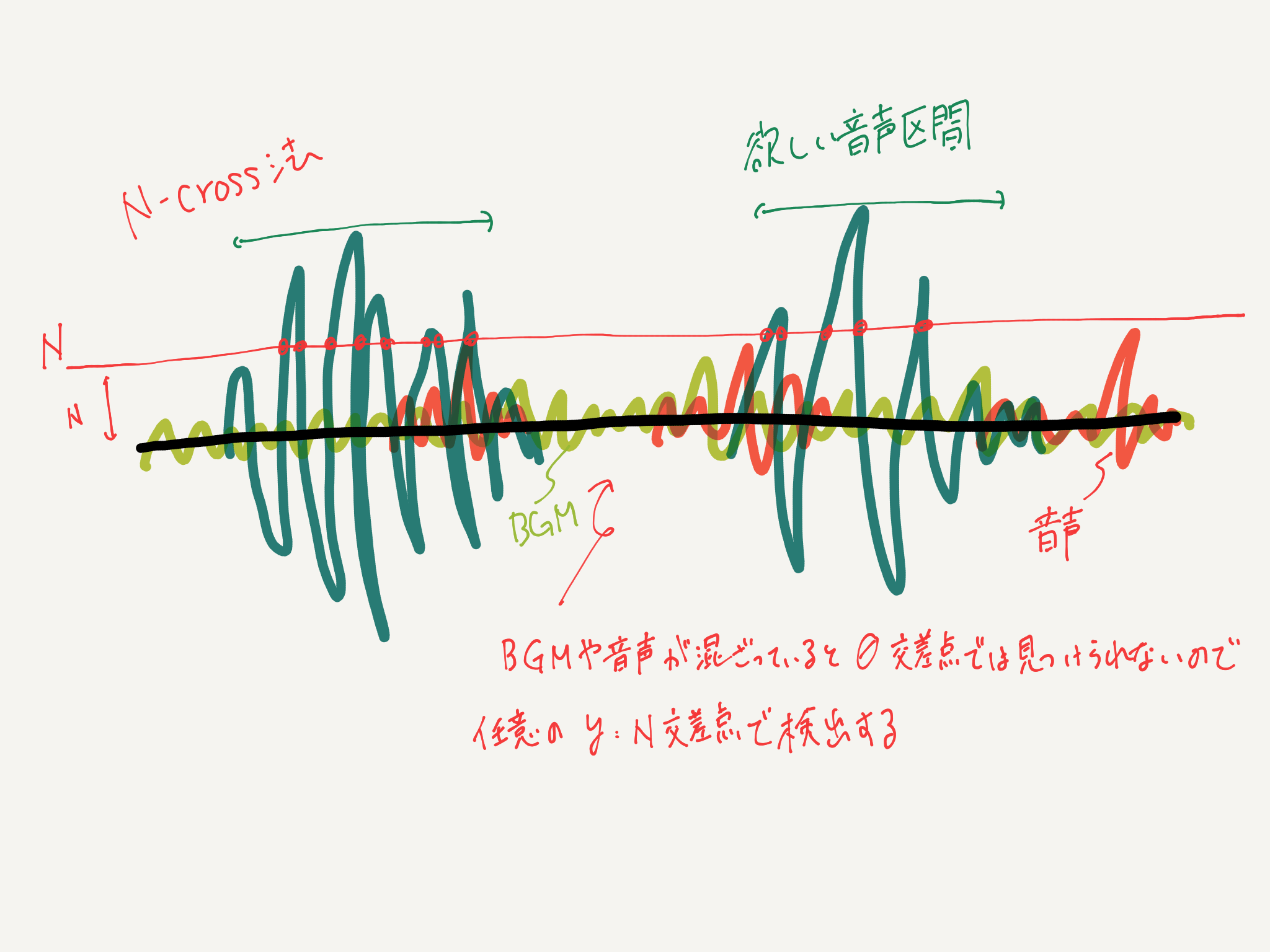
Implementierung
In Python implementiert. Bitte führen Sie es mit Colab oder Jupyter aus.
Wenn Sie im folgenden `Ncross ()` `eine monaurale Schallquelle` `data``` eingeben, ist diese kleiner oder gleich` `N``` (= 0 bis 1), wenn der maximale Schalldruck der Schallquelle 1 beträgt. Wenn die Stimme des Schalldrucks von nicht als VAD-Ziel betrachtet wird und die Sprachdaten in "hop_length" unterteilt und als Zielsprachabschnitt erkannt werden, wird sie auf "1" gesetzt, andernfalls wird sie auf "0" gesetzt. Gibt eine Zeitleistenliste zurück. Zusätzlich wird der Flächenwert, der den Zielabschnitt als Sprachabschnitt betrachtet, durch den Parameter `m``` angegeben. Je kleiner es ist, desto schwerer wird es und je größer es ist, desto mehr Geräusche nimmt es auf.
Und in dem unten geschriebenen `kukan ()` beginnen Sie mit der tatsächlichen Stimme zu sprechen, indem Sie die Zeitachsenliste `N_cross_list``` verwenden, die von` `Ncross ()` erhalten wird. Gibt eine Liste zurück, in der der Zeitindex und der Zeitindex des Endes der Story gespeichert sind. In Bezug auf die Parameter ist in `N_cross_list``` das Sprachintervall durch" 1 "und das Stilleintervall durch" 0 "gegeben. Wenn dieser Wert also durch" `num" gegeben ist, ist jedes Intervall gegeben Sie können den Zeitindex von erhalten. Als nächstes kommt `M```, aber im Gespräch denke ich, dass Sie auch beim Sprechen einen" Atemzug "nehmen können. In der Rede mit dieser Stille ist es ein Wert, der bestimmt, wie viele Sekunden die Stille als kontinuierliches Gespräch betrachtet wird. Da diesmal M = 200``` eingestellt ist, beträgt die Abtastfrequenz in der tatsächlichen Zeit 44000, also M * hop_length / SampleRate = 2.32 ... , was ungefähr 2 Sekunden entspricht. Wenn es ein gewisses Maß an Stille gibt, wird dies als Unterbrechung im Sprachabschnitt angesehen. Obwohl nicht in den Eingabeparametern enthalten, ist `` chousei ein Parameter, der dem erkannten Sprachintervall einen Spielraum gibt. Da hier `` `chousei = 30 eingestellt ist, wird`` chousei * hop_length / SampleRate = 0.348 ... ``Sekunden als Sprachabschnitt betrachtet. Der Grund, warum ich das mache, ist, dass das Reibungsgeräusch und das Burst-Geräusch zu Beginn des Gesprächs oft nicht als Stimme erkannt werden, also gebe ich es.
Ncross.py
#N-Kreuzmethode
#0 im stillen Bereich,Gibt eine Timeline-Liste von 1 im Sprachintervall zurück
def Ncross(data,N,m,hop_length):
"""
N-Kreuzmethode
1 im stillen Bereich,Gibt eine Timeline-Liste von 0 im Sprachintervall zurück
'''
data : Sound
N :Flächenwert(0~1)
m :Schwellenwert bei der Nulldurchgangsmethode
hop_length :Anzahl der Schnitte im Rahmen
"""
y=data/np.max(np.abs(data))
#Anzahl der Schnitte im Rahmen
nms = ((y.shape[0])//hop_length)+1
#Keine Polsterung, damit Anfang und Ende mit einem Rahmen ausgeschnitten werden können
y_bf = np.zeros(hop_length*2)
y_af = np.zeros(hop_length*2)
y_concat = np.concatenate([y_bf, y, y_af])
zero_cross_list = []
for j in range(nms):
zero_cross = 0
#Durch Rahmen ausgeschnitten
y_this = y_concat[j*512:j*512+2048]
for i in range(y_this.shape[0]-1):
#Bedingung, wenn sich positive oder negative Änderungen ergeben
if (np.sign(y_this[i]-N) - np.sign(y_this[i+1]-N))!=0:
zero_cross += 1
zero_cross_list.append(zero_cross)
#Normalisiert auf maximal 1
zero_cross_list = np.array(zero_cross_list)/max(zero_cross_list)
#Der Schwellenwert ist 0.Auf 4 setzen (Hulistisch, aber ...)
zero_cross_list = (zero_cross_list<m)*1
return zero_cross_list
hop_length = 2**9
cross_list = []
for i in range(N_person):
N_cross_list= Ncross(sep[:, -(i+1)],0.3,0.2,hop_length)
cross_list.append(N_cross_list)
N_cross_list1 = cross_list[0]
N_cross_list2 = cross_list[1]
for i in range(N_person):
plt.plot(sep[:, -(i+1)])
plt.show()
separation.py
num = 2
M = 200
chousei = 30
def kukan(N_cross_list,num,M):
A = N_cross_list
A_index = np.where(A == num)[0]
startlist = [A_index[0]]
endlist = []
for i in range(len(A_index)-1):
dif = A_index[i+1]-A_index[i]
if dif > M:
endlist.append(A_index[i])
startlist.append(A_index[i+1])
endlist.append(A_index[-1])
return startlist,endlist
for i in range(N_person):
startpoint,endpoint = kukan(cross_list[i],num=0,M=M)
print("start point",startpoint)
print("end point",endpoint)
for n in range(len(startpoint)):
target = sep[:, -(i+1)]
audio=target[hop_length*(startpoint[n]-chousei):hop_length*(endpoint[n]+chousei)]
display(Audio(audio, rate=RATE))