[PYTHON] Übersetzte die Erklärung des oberen Modells des Kaggle-Wettbewerbs zur Erkennung von Gehirnwellen
Vor nicht allzu langer Zeit wollte ich Gehirnwellen mithilfe von Techniken des maschinellen Lernens und der Datenanalyse klassifizieren. "Grasp-and-Lift-EEG-Erkennung", die Handbewegungen im Kaggle-Wettbewerb erkennt (https://www.kaggle.com/c/grasp-and-lift-eeg-detection) Also habe ich versucht, es für das Studium zu übersetzen. Die Frist für diesen Wettbewerb endet im August 2015 und reicht von "Signal Processing & Classification Pipeline" bis "Code" im Github-Repository von Herrn Alexandre Barachant vom Top-Team "Cat & Dog" ab dem 25. Februar 2017. Ich wollte den Abschnitt bis und die Gliederung des Modells übersetzen.
Es tut mir leid, dass ich wenig über mein Gehirn und meine Signalverarbeitung weiß, und ich habe "(* ~ *)" als Notiz eingefügt, um das Lesen zu erschweren. Bitte weisen Sie auf Fehler hin.
Original: alexandrebarachant/Grasp-and-lift-EEG-challenge https://github.com/alexandrebarachant/Grasp-and-lift-EEG-challenge
Signalverarbeitungs- und Klassifizierungspipeline
Überblick:
Das Ziel dieser Herausforderung ist es, sechs verschiedene Ereignisse (* = Ereignisse ) zu erfassen, die sich auf Handbewegungen beim Greifen, Heben von Objekten usw. beziehen. Verwenden Sie nur Gehirnwellen ( = EEG (nicht invasiv) *). Es ist notwendig, die Wahrscheinlichkeit von 6 Ereignissen in allen Zeitabtastungen auszugeben. Die Auswertungsmethode ist AUC (AreaUnderROCcurve), die 6 Ereignisse umfasst.
In Bezug auf Gehirnwellen werden Muster im Gehirn während Handbewegungen als Änderungen der räumlichen Frequenz von Gehirnwellensignalen charakterisiert. Insbesondere sollte die Signalstärke im 12-Hz-Frequenzband des kontralateralen Motorkortex MU abnehmen. Wenn die Signalintensität des ipsilateralen motorischen Kortex zunimmt. Diese Änderungen treten auf, nachdem die Bewegung ausgeführt wurde, und einige Ereignisse sind zu Beginn der Bewegung gekennzeichnet (z. B. Beginn der Bewegung). Es ist schwierig, alle sechs Ereignisse mit einem einzigen Modell zu bewerten, da einige andere am Ende gekennzeichnet sind (z. B. das Ersetzen von Objekten). Mit anderen Worten, ob es sich um eine Vorhersage oder eine Erkennung handelt, hängt davon ab, was klassifiziert wird.
Die sechs Ereignisse repräsentieren verschiedene Phasen einer Reihe von Handbewegungen (Beginn der Bewegung, Beginn des Hebens usw.). Eine Herausforderung bestand darin, die temporäre Struktur der Serie zu berücksichtigen. Das heißt, die kontinuierliche Beziehung zwischen Ereignissen. Darüber hinaus überschneiden sich einige Ereignisse, andere schließen sich gegenseitig aus. Infolgedessen ist es schwierig, Mehrklassenmethoden oder Finite-State-Maschinen (* Automat? *) Zum Decodieren von Sequenzen zu verwenden.
Schließlich wird das True-Label aus dem EMG-Signal (* = Elektromyogramm ) extrahiert und erhält einen Rahmen von + -150 ms (zentriert auf das Auftreten des Ereignisses). Diese 300ms haben keine psychologische (?) Bedeutung. (Ähnlich wie bei einer einfachen Stichprobe von 150 + 151 Frames ( 301 Frames *) mit unterschiedlichen Beschriftungen für 150 und 151) Daher bestand eine weitere Schwierigkeit darin, die Vorhersage FalsePositive (= falsch positiv) zu schärfen. Zu minimieren (an den Rändern des Rahmens).
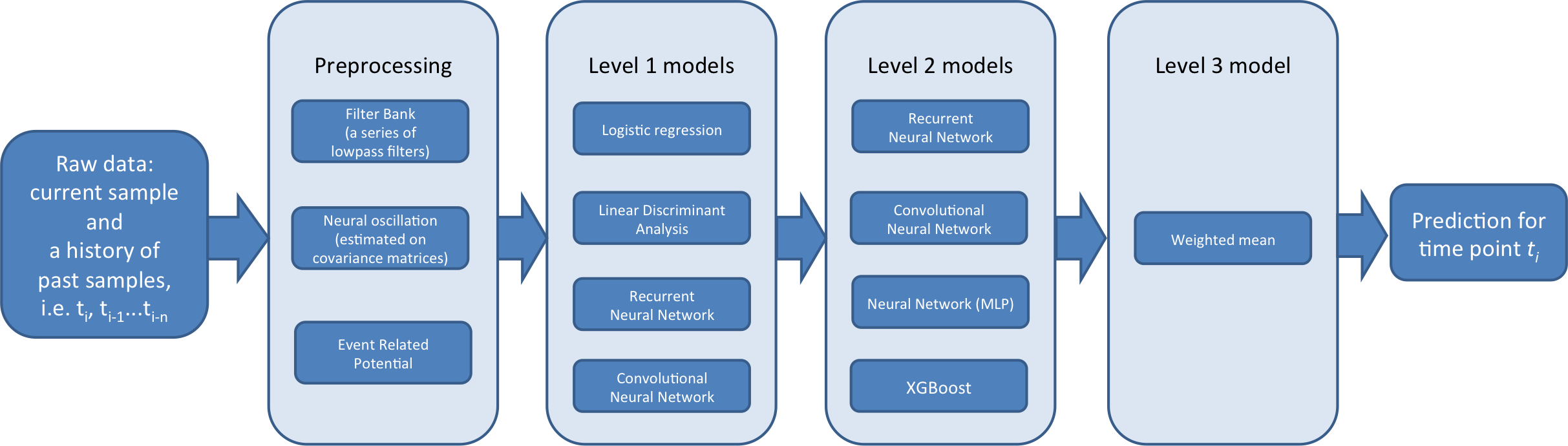
Erstellen Sie in einem solchen Kontext eine dreistufige Klassifikator-Pipeline:
--Lvl1 ist fachspezifisch. Das heißt, jedes Fach wird individuell trainiert. Viele von ihnen sind auch ereignisspezifisch (* das heißt, es scheint, dass viele Themen nur eine Bewegung haben ). Das Hauptziel von Lvl1 ist die Unterstützung und Vielseitigkeit des Lvl2-Moduls. Durch Einbetten von Themen und Ereignissen mit verschiedenen Arten von Funktionen. ( Level 1 gibt ein neues Feature aus dem Feature aus und sendet es in der folgenden Stufe an den Level 2-Klassifikator *)
--Lvl2 ist ein globales Modell (nicht patientenspezifisch). Trainiert auf den Ergebnissen von Level 1-Vorhersagen (Meta-Features). Ihr Hauptziel ist es, die temporäre Struktur zwischen Ereignissen zu berücksichtigen. Auch die Tatsache, dass sie dazu beitragen, Vorhersagen zwischen Probanden signifikant global zu korrigieren (* ist *).
--Lvl3 ist ein Vorhersage-Ensemble von Lvl2. Es wird ein Algorithmus durchlaufen, der das Gewicht von 2 optimiert, um die AUC zu maximieren. Dieser Schritt verbessert die Schärfe der Vorhersagen und vermeidet Überlernen.
Keine zukünftigen Datenregeln
Wir haben den Kausalzusammenhang genau beobachtet. Es wird immer ein temporärer Filter angewendet, aber die lFilter-Funktion (Scipy) wurde verwendet. Es ist eine Funktion, die "direkte Form-II-Kausalfilterung" implementiert. Es wird jedes Mal ein Schiebefenster verwendet, aber wir haben das Signal links mit Nullen aufgefüllt. Die gleiche Idee gilt, wenn die Historie vergangener Prognosen verwendet wird. (Dieselbe Idee wurde angewendet, wenn eine Vorgeschichte vergangener Vorhersagen verwendet wurde.) Schließlich kann, da das Signal oder die Vorhersage über die unverarbeitete Zeitreihe hinweg verkettet war, die letzte Stichprobe der vorherigen Reihe "lecken". Dies ist kein Regelverstoß. Weil die Regeln nur innerhalb einer bestimmten Zeitachse gelten.
Modellbeschreibung
Hier ist eine Übersicht über die 3-Ebenen-Pipeline
Lvl1 Das Modell wird wie folgt beschrieben. Training mit Rohdaten im Validierungsmodus und Testmodus (?). Das vorherige Modell wurde in Serie 1-6 mit Vorhersagen 7-8 trainiert (diese Vorhersagen sind Trainingsdaten der Stufe 2 (Metafunktionen). Spätere Modi werden in den Serien 1-8 trainiert und in den Testreihen 9-10 vorhergesagt. (* 9-10 ist das zu übermittelnde Vorhersageziel, lernt 1-6 dafür und gibt die Vorhersage von 7-8 aus. Danach bedeutet dies, dass die Vorhersage als Eingabe ausgegeben wird und die Vorhersage von 9-10 von Lvl2 ausgegeben wird. ? *)
Cov Die Kovarianzmatrix ist ein Auswahlmerkmal zur Erfassung von Handbewegungen aus Gehirnwellen. Sie enthalten räumliche Informationen (durch Kanalverteilung pro Kanal) und Frequenzinformationen (durch Signalverteilung). Die Kovarianzmatrix wird in einem Schiebefenster vorhergesagt (normalerweise 500 Proben). Nach Verwendung des Bandpassfilters zum Signal. Es gibt zwei Arten von Kovarianz:
-
1.AlexCov: Das Ereignislabel wird zuerst neu beschriftet. Zu einer Reihe von 7 Zuständen. Für jeden Zustand des Gehirns wird der geometrische Durchschnitt (* später beschrieben *) entsprechend jeder Kovarianzmatrix geschätzt. (Durch Berechnung der euklidischen LOG-Metrik) Danach wird beim Erstellen eines Merkmalsvektors der Größe 7 der Lehman-Abstand zu jedem Schwerpunkt berechnet. Dieses Verfahren kann als überwachte Mannigfaltigkeitseinbettung mit einer Riemannschen Metrik angesehen werden. (?)
-
2.RafalCov: Gleiche Idee wie oben, jedoch für jede Veranstaltung separat angewendet. Beim Erstellen eines Feature-Vektors aus 12 Elementen (Es gibt 2 Klassen, 1 und 0, für jede Veranstaltung)
ERP (* Eventbezogenes Potenzial, ERP) ) Dieser Datensatz enthält visuell ausgelöste Potentiale (bezogen auf das experimentelle Paradigma). Die Funktionen für die asynchrone ERP-Erkennung basieren im Wesentlichen auf den Vorgängen der vorherigen BCI-Herausforderung ( der Autor hat zuvor an der ERP-Erkennungs-Herausforderung gearbeitet *). Während des Trainings wird das Signal 1 Sekunde vor Beginn jedes Ereignisses epochiert. ERP wurde gemittelt und unter Verwendung des Xdawn-Algorithmus reduziert (bevor es mit einem etablierten Signal kombiniert wurde). Dann wurde die Kovarianzmatrix abgeleitet und verarbeitet. Ähnlich wie bei der Co-Dispersionsfunktion.
FBL Es wurde festgestellt, dass das Signal viele prädiktive Informationen enthält. Bei niedrigen Frequenzen. Daher werden wir die Filterbankmethode einführen. Es besteht aus der Kombination der Ergebnisse der Anwendung einiger Butterworth-Tiefpassfilter 5. Ordnung. (Grenzfrequenzen sind 0,5, 1, 2, 3, 4, 5, 7, 9, 15, 30 Hz)
FBL_DELAY Die FBL hat jedoch eine einzelne Rohdaten / Beobachtung von 2 Sekunden zusammen mit 5 vergangenen Proben (1000 Proben in der Vergangenheit, von denen jede nur die 200. Probe nimmt?). Es wird erweitert, indem es in ein Intervall überspannt wird. Mit diesen zusätzlichen Funktionen kann das Modell die temporäre Struktur des Ereignisses erfassen.
FBCL In der Filterbank werden die Merkmale der Kovarianzmatrix zu einem Merkmalssatz zusammengefasst.
Algorithmus
** LogisticRegression **, ** LDA (Linear Discrimination Analysis) ** Für Test und Pre-Training werden unterschiedliche Standardisierungen angewendet.) Unter den oben genannten Merkmalen eine ereignisspezifische Perspektive? Ist auf den Daten angegeben?
Es gibt auch zwei LVL1NN-Methoden, von denen keine ereignisspezifisch ist. (Alle Ereignisse werden gleichzeitig gelernt) (* folgende *)
Convolutional Neural Network Dies ist eine Modellfamilie (basierend auf Tim Hochvergs Skript und Bluefools Tweaks. [Tim Hochbergs Skript mit Bluefools Tweaks](https://www.kaggle.com/bitsofbits/grasp-and- Lift-Eeg-Detection / naive-nnet): Tiefpassfilter und Option 2dCONV (Er umfasst alle Elektroden, sodass jeder Filter die Abhängigkeiten zwischen allen Elektroden gleichzeitig erfasst.) Zusammenfassend ist dies eine kleine 1D / 2D-Faltung NN (Eingabe → Dropout → 1d / 2dConv → dicht → Dropout → dicht → Dropout → Ausgabe) Als würde man mit einigen der aktuellen und vergangenen Proben lernen. Jedes CNN wird 100 Mal markiert, um die relativ hohe Varianz (* Variation ) zwischen den einzelnen Läufen zu verringern ( Bagging ?, Siehe unten *). Wird dieser eine Lauf veranlasst, eine effiziente Epochenstrategie zu nutzen, die das Netzwerk mit einem zufälligen Teil der Trainingsdaten trainiert? Etwas wie.
Recurrent Neural Network Kleine RNN, die nach dem Passieren des Tiefpassfilters auf Signal trainiert wurde (Eingang-> Dropout-> GRU-> Dichte-> Dropout-> Ausgang) (Filterbank des Tiefpassfilters und Grenzfrequenz von 1, 5, 10, 30 Hz) Trainiert mit einem kurzen, spärlichen Zeitreihenwechsel von 8 Sekunden (nehmen Sie jede 100. Probe bis zu den letzten 4000 Proben). RNN scheint perfekt auf diese Aufgabe anwendbar zu sein (eine genau definierte temporäre Struktur von Ereignissen und ihre Zwischenabhängigkeiten (* Interdependenzen? *)), Aber in der Praxis werden gute Vorhersagen getroffen. War hart. Daher waren die Berechnungskosten hoch, so dass ich sie nicht so weit verfolgte, wie ich erwartet hatte.
Level2 Diese Modelle werden mit der Ausgabe von Level 1-Modellen trainiert. Sie trainieren im Validierungs- und Testmodus. Die Validierung ist eine Kreuzvalidierungsmethode, die durchgeführt wird und in Reihen unterteilt ist (2-fach (* Gruppe *)). Die Vorhersagen aus jeder Falte werden dann für das Lvl3-Modell mit Meta-Merkmalen versehen (dies nennen wir die neuen Merkmale, die mithilfe des Modells transformiert wurden). Dieses Testmodusmodell wird in den Serien 7 und 8 trainiert, und Vorhersagen werden für die Testreihen 9 und 10 ausgegeben.
Algorithmus
XGBoost Gradientenverstärkungsmaschinen bieten eine einzigartige Perspektive auf die Daten, erzielen sehr gute Ergebnisse und bieten Vielseitigkeit für die nächste Stufe des Modells. Nur Lvl2 wird für jedes Ereignis einzeln trainiert, und die Betreff-ID wird als Feature hinzugefügt. Es hilft bei der Korrektur von Vorhersagen zwischen Subjekten (das Hinzufügen einer One-Hot-Codierung von Subjekt-IDs verbessert die Leistung in NN-basierten Modellen nicht). XGBoost sagt ein bestimmtes Ereignis korrekt voraus. Diese Genauigkeit ist sehr gut, wenn mit einigen Sekunden Zeitreihensignalen trainiert wird, mit Metafunktionen aller Ereignisse, nicht nur des entsprechenden Ereignisses. Weil sie prädiktive Informationen extrahieren, die in Zwischenabhängigkeiten zwischen Ereignissen und verwandten transienten Strukturen enthalten sind. Wenn Sie im Eingabe-Teilbeispiel Ihr Bestes geben, können Sie es außerdem standardisieren und Überlernen verhindern.
Recurrent Neural Network Eine sehr hohe AUC kann mit einer genau definierten temporären Struktur von Ereignissen und einer Vielzahl von Level 2-Metafunktionen erreicht werden. Das Training mit Adam ist mit geringen Rechenkosten verbunden (in vielen Fällen dauert die Konvergenz nur eine Epoche). Die große Anzahl von Level 2-Modellen ist eine einfache RNN-Architektur mit geringfügigen Änderungen (Eingabe-> Dropout-> GRU-> Dichte-> Dropout-> Ausgabe), bei der es sich um einen unterabgetasteten kurzen Zeitverlauf von 8 Sekunden (* Zeitverlauf) handelt. , Zeitreihenänderung, Eingangsdatenlänge? *).
Neural Network Trainiert in einer kleinen mehrschichtigen (nur eine verborgene Schicht) unterabgetasteten 3-Sekunden-Verlaufszeitleiste. Dies war schlimmer als RNNs und XGBoost. Das Lvl3-Modell war jedoch vielseitig einsetzbar.
Convolutional Neural Network Kleine Lvl2-CNNs (eine Faltungsschicht, kein Pooling, dann eine dichte Schicht) werden in einem 3-Sekunden-Zeitverlauf mit unterabgetasteter Geschichte trainiert. Zwischen den Zeitabtastwerten wird ein Filter erstellt, der alle Vorhersagen und Schritte für eine einzelne Zeitstichprobe umfasst. Für mehrschichtige NNs besteht der Hauptzweck dieser CNNs darin, Vielseitigkeit für das Lvl3-Modell bereitzustellen.
Die Vielseitigkeit des Lvl2-Modells wird durch Ausführen des obigen Algorithmus mit den folgenden Modifikationen erweitert:
--Mache Meta-Features in verschiedene Teilmengen --Ändern Sie die Länge des Zeitverlaufs
- Protokollverlauf protokollieren (* Zeitreihen-Stichprobenprotokoll erstellen? *) (Aktuelle Zeitpunkte werden dichter abgetastet als sogar Intervall-Stichproben)
- Beuteln (siehe unten)
Für NNs, CNNs, RNNs:
- Verwenden Sie parametrisches ReLu anstelle von Relu für die Aktivierungsfunktion für dichte Schichten
- Mehrschicht
- Ändern Sie den Optimierer (SGD oder ADAM)
Zitiert aus Toki no Mori Wiki http://ibisforest.org/index.php?%E3%83%90%E3%82%AE%E3%83%B3%E3%82%B0
Absacken †
Ein Verfahren zum Synthetisieren von Diskriminatoren, die durch Wiederholen der Bootstrap-Abtastung erzeugt werden, um Diskriminatoren mit höherer Unterscheidungsgenauigkeit zu erzeugen. Der Name stammt von Bootstrap AGGregatING
Im Bereich der neuronalen Netze wird es auch als Komiteemaschine bezeichnet.
Bootstrap-Sampling †
So erstellen Sie einen neuen Probensatz X'aus dem Probensatz X = {xi} N, indem Sie Duplizieren und Abtasten zulassen
Bagging Einige Modelle sind zusätzlich gekennzeichnet. Um seine Robustheit zu erhöhen. Es werden zwei Arten des Absackens verwendet:
--Wählen Sie eine zufällige Teilmenge aus den Trainingszielen. Für jede Tasche (Modell enthält mehrere Taschen in seinem Namen) (* Dateiname im Repository des Autors *)
- Aus den Meta-Funktionen der Auswahl einer zufälligen Teilmenge für jede Tasche (mit dem Namen bags_model) (* Dateiname im Repository des Autors *)
In allen Fällen 15 Taschen gefunden (* run? *) Um zufriedenstellende Ergebnisse zu erzielen. Die AUC steigt nicht viel an, selbst wenn sie weiter erhöht wird.
Level3 Lvl2-Vorhersagen werden zusammengestellt. Durch einen Algorithmus, der die Ensemblegewichte optimiert, um die AUC zu maximieren. Dieser Schritt erhöht die Schärfe (Genauigkeit?) Der Vorhersage und die Verwendung einer sehr einfachen Ensemble-Methode verhindert ein Überlernen. (Es war eine Bedrohung für das (* = Überlernen ) wirklich fortgeschrittene ( hohe Lvr, = viele Stufen? *) Ensemble.) Um die AUC weiter zu erhöhen und die Robustheit zu erhöhen. Wir haben drei gewichtete Durchschnittswerte verwendet für:
--Arithmetischer Durchschnitt (* gewöhnlicher Durchschnitt *)
- Geometrischer Durchschnitt (* Multiplizieren Sie jeden und ziehen Sie die Wurzel *)
- Indexdurchschnitt:
f
\bar x_p = S(\sum x_i^{w_i}) , wherew_i=[0..3] andS is a logistic function that is used to force output into [0..1]
Das Lvl3-Modell ist der Durchschnitt der oben genannten drei gewichteten Durchschnittswerte.
Einreichung
| Submission name | CV AUC | SD | Public LB | Private LB |
|---|---|---|---|---|
| "Safe1" | 0.97831 | 0.000014 | 0.98108 | 0.98095 |
| "Safe2" | 0.97846 | 0.000011 | 0.98117 | 0.98111 |
| "YOLO" | 0.97881 | 0.000143 | 0.98128 | 0.98109 |
Safe1 Eine Kreuzvalidierung mit einer relativ hohen AUC und Stabilität wurde als endgültiges Einreichungsmodell (lvl3) verwendet. Robuste Metafunktionen von lvl2 (7/8 der lvl2-Modelle sind Baged)? (7 out of 8 level2 models were bagged.)
Safe2 Eine weitere Einreichung, die eine sehr stabile CV (* Kreuzvalidierung? *) AUC ist. Diese Lvl2-Meta-Funktion (nur 6/16 Tasche)? (nur 6 von 16 Level2-Modellen wurden verpackt) wurde als weniger sichere Wahl für Lvl2 angesehen als safe1 (falsch (?)) und wurde in der endgültigen Einreichung nicht ausgewählt. Ich bin nur hier interessiert.
YOLO (* YOLO, was bedeutet "Leben ist nur einmal"? *) Die zweite endgültige Einreichung ist der Durchschnitt von 18 Lvl3-Modellen. Das heißt, sie zusammen führen zu einer erhöhten Robustheit. Von CV- und öffentlichen LB-Scores bei der Kreuzvalidierung. Diese Übermittlung ist etwas überlernt und Sie können die hohen Rechenkosten vermeiden, indem Sie entweder Safe1 oder Safe2 ausführen. Beide geben ähnliche AUCs in privaten Bestenlisten aus.
Diskussion
Entschlüsseln Sie tatsächlich die Aktivität des Gehirns?
Aufgrund einer Vielzahl von Merkmalen ist unklar, ob diese Modelle tatsächlich die mit Handbewegungen verbundene Gehirnaktivität entschlüsseln. Durch die Verwendung einer komplexen Vorverarbeitung (aufgrund gemeinsam verteilter Funktionen) oder des Black-Box-Algorithmus (CNN) ergeben sich zusätzliche Schwierigkeiten. Bei der Analyse der Ergebnisse. (* Ist es die Geschichte des Problems, dass das Ergebnis von NN nicht erklärt werden kann, warum es passiert ist? *)
Die gute Leistung von Modellen, die auf seltenen Merkmalen basieren, lässt weitere Zweifel aufkommen. Es ist nicht bekannt, dass diese Merkmale beim Decodieren von Handbewegungen besonders nützlich sind. Insbesondere ist es sehr schwierig, gute Ergebnisse zu erzielen, indem ein Ereignis mit einer Frequenz von 1 Hz oder weniger und 300 ms erfasst wird. Die Erklärung ändert sich, wenn sich die Grundlinie (* grundlegende Wellenformdaten? ) Aufgrund der Bewegung des Körpers ändert oder wenn das Subjekt ein Objekt berührt und den Boden berührt. ( Ich verstehe, dass es bedeutet, dass es in solchen Fällen erkannt werden kann *)
Auch mit einem Co-Dispersionsmodell, das im 70-150-Hz-Frequenzband vorhersagt, wo eine relativ gute Leistung beobachtet werden kann. Dieses Frequenzband enthält viel EEG (* = Gehirnwelle *), und die Aktivität der EMG im Zusammenhang mit der Aufgabe ist latent.
- Kindenzu (Elektromyographie --EMG) *
Der Datensatz ist jedoch sehr sauber und enthält starke Muster im Zusammenhang mit dem Ereignis. Dies ist dieses Skript. Sie können es in räumlichem Muster mit mne sehen). Andere Aktivitäten (VEP *, EMG * usw.) können zur Gesamtleistung beitragen, indem sie Vorhersagen in schwierigeren Fällen erzwingen (Vorhersagen für schwierigere Fälle verstärken), aber tatsächlich wir Entschlüsselt zweifellos die Gehirnaktivität im Zusammenhang mit Handbewegungen.
- Visuell evozierte Potentiale (VEP) sind Potentiale, die im visuellen Bereich der Großhirnrinde durch visuelle Reize (aus Wikipedia) erzeugt werden. *
Benötigen Sie all diese Modelle?
Bei dieser Herausforderung habe ich das Ensemble sehr gut genutzt. Das Problem mit dieser Methode (Vorhersage aller Proben) war dieser Art von Lösung gewidmet. (?) (Die Art und Weise, wie das Problem definiert wurde (Vorhersage jeder Stichprobe), hat sich für diese Art von Lösung ausgesprochen.) In einer solchen Situation verbessert eine Erhöhung der Anzahl der Modelle immer die Leistung und die Vorhersagegenauigkeit.
In einer realen Anwendung ist es nicht erforderlich, alle Zeitabtastungen zu klassifizieren, und es wird eine Zeitrahmenmethode verwendet, die beispielsweise alle 250 ms ausgegeben wird. Ich glaube, es ist möglich, mit einer optimaleren Lösung die gleiche Dekodierungsleistung zu erzielen, indem das Ensemble auf Stufe 2 gestoppt und nur eine Teilmenge einiger Level 1-Modelle verwendet wird. (Eine für jede Art von Funktion).
Recommended Posts