[PYTHON] Lassen Sie uns die Daten der Fragebogenumfrage analysieren [4 .: Emotionsanalyse]
Dieses Mal möchte ich die Emotionsanalyse anhand der Antwortdaten des Fragebogens herausfordern. Durch die Durchführung einer emotionalen Analyse kann anhand der Wörter in der freien Antwort beurteilt werden, ob die Einstellung des Befragten positiv oder negativ ist.
Auch dieses Mal verwenden wir die kostenlosen Antwortdaten zu "Warum Sie die elektronische Version des Medikamentenhefts verwenden möchten" unter der folgenden URL.
Wir haben eine "Awareness Survey on Electronic Medicine Notebook" durchgeführt. https://www.nicho.co.jp/corporate/newsrelease/11633/
① Importieren Sie zunächst die Bibliothek. Dieses Mal werde ich Janome verwenden.
import csv
from janome.tokenizer import Tokenizer
② Laden Sie als Nächstes das "Japanese Evaluation Polarity Dictionary" herunter und lesen Sie es. Dies ist ein Wortwörterbuch, das zur Beurteilung von Wörtern verwendet wird. Beispielsweise ist "Ehrlichkeit" positiv, "bärisch" negativ und etwa 8.500 Ausdrücke sind mit positiv oder negativ verbunden (siehe unten). URL-Referenz).
http://www.cl.ecei.tohoku.ac.jp/index.php?Open%20Resources%2FJapanese%20Sentiment%20Polarity%20Dictionary
! curl http://www.cl.ecei.tohoku.ac.jp/resources/sent_lex/pn.csv.m3.120408.trim > pn.csv
np_dic = {}
fp = open("pn.csv", "rt", encoding="utf-8")
reader = csv.reader(fp, delimiter='\t')
for i, row in enumerate(reader):
name = row[0]
result = row[1]
np_dic[name] = result
if i % 500 == 0: print(i)
(3) Führen Sie eine morphologische Analyse der Zieldaten durch und vergleichen Sie jedes Wort mit dem obigen Wörterbuch. Im folgenden Code ist "p" positiv, "n" ist negativ und "e" ist eine neutrale Phrase, die keine ist, und jede wird gezählt, um den positiven oder negativen Grad zu bestimmen.
df = open("survey3.txt", "rt", encoding="utf-8")
text = df.read()
tok = Tokenizer()
res = {"p":0, "n":0, "e":0}
for t in tok.tokenize(text):
bf = t.base_form
if bf in np_dic:
r = np_dic[bf]
if r in res:
res[r] += 1
print(res)
cnt = res["p"] + res["n"] + res["e"]
print("Positive", res["p"] / cnt)
print("Negative", res["n"] / cnt)
Das Ergebnis ist wie folgt. Die Antwort lautete nur "warum Sie die elektronische Version des Medikamentenhefts verwenden möchten", und das Ergebnis ist immer noch sehr positiv.
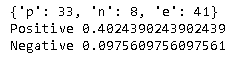
In dieser Umfrage wird übrigens auch untersucht, "warum Sie die elektronische Version des Medikamentenhefts nicht verwenden möchten". Was ist, wenn wir mit diesen Daten eine ähnliche Analyse durchführen?
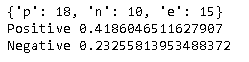
Das Ergebnis sieht so aus. Trotz des "Grundes, nicht verwenden zu wollen" übersteigt der positive Wert den negativen Wert. Bei Betrachtung der ursprünglichen Antwortdaten gab es einige Antworten wie "Papiernotizbuch ist besser", und es scheint, dass das obige Ergebnis erhalten wurde. Dieser Bereich bezieht sich auch auf das Fragebogendesign, und es scheint, dass Sie vorsichtig sein müssen, wenn Sie von der Implementierung von Text Mining ausgehen.
Referenzseite
Lassen Sie uns all-you-can-read Online-Romane mit negativem / positivem Urteilsvermögen bewerten https://news.mynavi.jp/article/zeropython-58/
Recommended Posts