[PYTHON] 7 Tipps, um Frustrationen im A3C nach Abschluss des DQN zu vermeiden
Einführung
Als ich versuchte, A3C selbst zu reproduzieren, während ich viele Codes im Internet betrachtete und die Literatur las, hatte ich das Gefühl, dass es zu viele Fallstricke gab und die Dunkelheit tief war, so dass ich der letzte sein werde, der in einer solchen Dunkelheit stecken bleibt. Deshalb habe ich versucht, die Orte, an denen ich süchtig war, in Form von Tipps zusammenzufassen Wenn Sie daran denken, Ihren eigenen Code zu schreiben und Ihr Bestes zu geben, hoffe ich, dass Sie auch ein wenig nicht in die Dunkelheit geraten, nachdem Sie dies gesehen haben.
Was ist A3C?
A3C ist eine Abkürzung für Asynchronous Advantage Actor-Critic, die von Deep Mind angekündigt wurde, der mit DQN im Jahr 2016 vertraut ist.
――Schnell: Das Lernen schreitet schnell voran, da das Lernen mit Asynchron und Advantage erfolgt! --Cheap: Deep Learning hebt die konventionelle Weisheit von GPUs auf und ermöglicht es Ihnen, mit nur einer kostengünstigen CPU zu rechnen!
- Gut: Bessere Leistung als DQN (und andere Vergleichsmethoden)!
Es ist eine tief stärkende Lernmethode wie eine Rindfleischschale mit allen drei Schlägen Kurz gesagt, DQN ist alt und A3C ist neu und besser (im Grunde genommen, wenn nicht absolut).
So ↓

Asynchronous Bei DQN wurde die Erfahrung, die von einem handelnden Agenten gesammelt wurde, zufällig ausgewählt (da die Erfahrung im Internet nicht iid wird) und als Trainingsdaten verwendet. Da nur die Erfahrung eines Agenten verwendet wird, ist die Geschwindigkeit, mit der Lernproben gesammelt werden, langsam. Da die Erfahrung einmal in Form von ReplayMemory gesammelt und dann gelernt wurde, ist es schwierig, aus Zeitreihendaten wie LSTM zu lernen. Dort war Daher werden im asynchronen A3C-Teil mehrere Agenten (maximal 16 im Papier) gleichzeitig verschoben, und einzelne Erfahrungen werden gesammelt und gelernt, sodass die Gesamterfahrung zufällig ausgewählt und online gelernt wird. Ich versuche zu sein Gleichzeitig habe ich viel Erfahrung gesammelt, so dass ich schneller lernen konnte.
Advantage Beim normalen TD-Lernen die Summe der Belohnung $ r $, die als Ergebnis der Aktion erhalten wurde, und des geschätzten Werts des nächsten Zustands $ V (s_ {t + 1}) $ (geteilt durch den Abzinsungssatz $ \ gamma $) Und unter Verwendung der Differenz des geschätzten Werts des aktuellen Status $ \ Delta $ aktualisieren wir den Wert des Status
Wenn umgekehrt die Schätzung für den nächsten Zustand falsch ist, wird die Schätzung für den aktuellen Zustand überhaupt nicht korrekt aktualisiert. Darüber hinaus muss der geschätzte Wert des nächsten Zustands für den nächsten geschätzten Wert korrekt sein, und der geschätzte Wert des nächsten Zustands befindet sich in einer Kette mit ..., sodass dies nur einen Schritt voraus ist. Es wird erwartet, dass die Aktualisierungsmethode einige Zeit benötigt, um auf den richtigen Wert zu konvergieren In A3C werden wir daher den geschätzten Wert unter Verwendung des nächsten Betrags, der als Vorteil bezeichnet wird, aktualisieren, indem wir die Möglichkeit nutzen, online zu lernen, dh Zeitreihendaten zu verwenden.
Hier ist $ k $ eine Konstante, die angibt, wie viel Vorausschau durchgeführt werden soll. Da die wahrscheinlichste Information bei der Wertschätzung des intensiven Lernens die tatsächlich erhaltene Belohnung $ r $ ist, ist die Höhe des Vorteils der wahrscheinlichere aktuelle Wert, wenn man bedenkt, dass die Belohnung k statt einen Schritt voraus ist. Es kann gesagt werden, dass es sich um einen Schätzfehler von handelt A3C verwendet diesen Betrag zum Lernen.
――Weil es ein wahrscheinlicherer Wert ist, schreitet das Lernen schneller voran ――Da wir bis zu mehreren Schritten vorausdenken, schreitet das Lernen schneller voran, als wenn Sie nur einen Schritt vorausschauen.
Es wird angenommen, dass dies eine Methode ist, die das Lernen in Erwartung dieser beiden Punkte effizienter macht.
Actor-Critic
In DQN haben wir eine Schätzung des Werts der Ausführung der Aktion $ a $ in einem bestimmten Zustand $ s $ trainiert, der als Q-Wert bezeichnet wird. Da der Wert einer Aktion in einem bestimmten Zustand geschätzt wird, gab es das Problem, dass die Anzahl der zu schätzenden Kombinationen bei kontinuierlicher Aktion enorm wurde (z. B. wenn Sie die Drehzahl eines Motors lernen wollten). Actor-Critic ist eine erweiterte Lernmethode, die lernt, während die Wahrscheinlichkeit des Auftretens der Aktion $ \ pi $ in einem bestimmten Zustand und der geschätzte Wert $ V $ des Zustands unabhängig geschätzt werden und die geschätzten Werte unabhängig sind. Es ist leicht zu lernen, auch wenn die Aktion kontinuierlich ist Ich weiß nicht, wie viel Actor-Critic zur Leistung von A3C selbst beiträgt, aber aufgrund der oben genannten Eigenschaften ist die Übernahme von Actor-Critic durch A3C entweder eine diskrete oder eine kontinuierliche Maßnahme. Es kann gesagt werden, dass es auch allgemeiner Zweck ist
7 Tipps, um Frustrationen zu vermeiden
Die Einführung ist länger geworden Da es viele A3C-Implementierungen gibt, auf die verwiesen werden kann, wie z. B. das GitHub-Repository unten.
Abgesehen von den Details zur Implementierung von A3C habe ich es von nun an für diejenigen implementiert, die Code in gewissem Umfang selbst schreiben, schreiben oder schreiben möchten, anstatt herumzustürmen. Wenn das Lernen jedoch nicht voranschreitet oder wenn das Lernen fortschreitet, das Ergebnis des Papiers jedoch völlig anders ist, werde ich die Punkte einführen, um vorsichtig zu sein und als Fallstricke und Tipps zu prüfen, denen ich verfallen bin.
Fallstricke / Tipps Teil 1 Hyperparameter ist ein Rätsel
Während Sie mit der Implementierung fortfahren, gibt es einige unklare Punkte wie die Parameter von RMSProp und wie Sie die Lernrate reduzieren können. Glücklicherweise haben die Vorfahren bereits [veröffentlicht], welche Parameter verwendet werden sollen (https://github.com/muupan/async-rl/wiki), sodass Sie selbst nach Hyperparametern suchen oder sich über seltsame Dinge Gedanken machen können. Lass uns anhalten
Fallstricke / Tipps Teil 2 Automatische Differenzierungsfalle
Die Beschreibung der im Papier beschriebenen A3C-Implementierung enthält zwei Zeilen:
Daran ist nichts auszusetzen, aber da das Atari-Reproduktionsnetzwerk in zwei Teile unterteilt ist und einige Parameter gemeinsam hat, $ \ theta ': d \ theta \ leftarrow d \ theta + \ nabla_ { \ theta '} \ log \ pi (a_i | s_i; \ theta') \ bigl (RV (s_i; \ theta_v ') \ bigr) $ ist $ V (s_i; \ theta_v'), wenn es so implementiert ist, wie es ist Da der $ -Teil ursprünglich keine Funktion von $ \ theta '$ ist, ist im Fall des Tensorflusses die Gradientenberechnung aufgrund der automatischen Differenzierung falsch, wenn $ V (s_i; \ theta_v') $ keinen skalaren Wert erhält. Masu
Fallstricke / Tipps Teil 3 OpenCV2 Drama Slow Problem
Wenn Sie OpenCV für die Grauskalierung von Bildern, die Bildanzeige usw. verwenden, sollten Sie bestätigen, dass Sie OpenCV3 verwenden. Wenn ich nicht bemerkte, dass OpenCV ein Engpass zu sein schien, verwendete ich OpenCV2, und als ich zu OpenCV3 wechselte, erhöhte sich die Ausführungsgeschwindigkeit um ein Vielfaches.
Fallstricke / Tipps # 4 Die Arcade-Lernumgebung unterstützt kein Multithreading
Wenn Sie es in mehreren Prozessen implementieren, spielt es keine Rolle, aber wenn Sie es in mehreren Threads implementieren, müssen Sie darüber nachdenken. Das bedeutet nicht, dass es überhaupt nicht funktioniert, weil ich keine Maßnahmen ergriffen habe, aber es gibt keine drastische Lösung, und soweit ich weiß, gibt es nur eine symptomatische Behandlung zur Entspannung, die wahrscheinlich in Ordnung ist. Es gibt auch miyosuda / async_deep_reinforce, aber ein Fix, der besagt, dass der Quellcode der Arcade-Lernumgebung ein wenig geändert werden sollte und statische Variablen nicht statisch sein sollten, ist wirksam. Scheint zu sein Allerdings scheint es in dem Bereich, den ich ausprobiert habe, von Zeit zu Zeit immer noch in einem seltsamen Zustand zu sein (weil ich ehrlich gesagt nicht weiß, ob mein Code fehlerhaft oder ALE fehlerhaft ist), und der Rest ist wie Glück. Außerdem hatte ich das Gefühl, dass der Code der Arcade-Lernumgebung in meiner Umgebung stabiler war, indem der Code von v0.5.1 geändert wurde als der neueste Master (möglicherweise aufgrund meiner Gedanken ... als Referenz). )
Fallstricke / Tipps # 5 Konvertieren Sie die Skalierung mit Bildvorverarbeitung in den Bereich 0-1
Das von Ale erhaltene Graustufenbild liegt im Bereich von 0 bis 255, aber aus meinen eigenen Experimenten scheint sich die Leistung zu verbessern, wenn Sie durch 255 dividieren und die Gesamtskala auf den Bereich von 0 bis 1 ändern ( Es ist schwer zu lernen, wenn man nicht durch 255 dividiert, nur um nach oben zu gehen.
Fallstricke / Tipps Teil 6 Implementieren Sie das Papier genau
Das ist natürlich! Es scheint, dass Sie wütend werden, aber ich werde hier mit Vorsicht schreiben, dass es dem Papier treu umgesetzt werden sollte. Was Sie besonders beachten sollten, ist die Anzahl der Vorteilsschritte, und wie ich oben geschrieben habe, ist der Vorteil vorgelesen. Theoretisch scheint das Ergebnis also besser zu sein, wenn Sie viel vorlesen können, sodass es in der Zeitung nicht 5 ist. Ist es nicht besser, eine größere Anzahl wie 10 oder 20 zu haben? Ist DeepMind dumm? Ich möchte wie ein Genie denken! Ich denke, dies ist ein Problem, das dadurch verursacht wird, wie die Belohnung für das Spiel, das Sie lernen möchten, und die Lernmethode namens Actor-Critic gegeben wird, aber in dem Breakout-Spiel, das ich ausprobiert habe, muss es unterwegs $ t_ {max} = 5 $ sein. Das Lernen ging schneller voran als die These, das Lernen ging schief, was ich für gut hielt (ungefähr 13 Schritte), das Netzwerk war kaputt und ich konnte mich nicht erholen. Andererseits scheint in Pong 20 zu funktionieren, daher sollte diese Anzahl von Schritten nicht einfach erhöht, sondern sorgfältig ausgewählt werden. Das heißt, und wenn Sie es reproduzieren möchten, sollten Sie es nach der Reproduktion ändern.
Fallstricke / Tipps # 7 Überprüfen Sie, ob Sie einen Gradientenaufstieg haben
Bei dieser Methode ist es erforderlich, den Gradienten des Richtliniennetzwerks in Richtung zunehmender Belohnung und zunehmender Entropie zu korrigieren. Daher ist die Berechnung seltsam, es sei denn, dem Verlust wird ein negatives Vorzeichen hinzugefügt, sodass er anstelle von Gradientenabstieg zum Aufstieg wird. Im Fall von Tensorflow sieht es wie folgt aus
policy_loss = - tf.reduce_sum(log_pi_a_s * advantage) - entropy * self.beta #Ich möchte den Wert in Richtung des Erhöhens ändern, also füge für beide ein Minus hinzu.
value_loss = tf.nn.l2_loss(self.reward_input - self.value) #Ich möchte den Fehler vom geschätzten Wert reduzieren, also lass ihn wie er ist
Fallstricke / Tipps Extra Edition Müssen Sie sich über Global Interpreter Lock Gedanken machen?
Sie sollten vorsichtig sein, aber es hängt davon ab, welche Bibliothek Sie verwenden und wie schnell sie ausgeführt werden soll. Zumindest scheint Tensorflow sich der GIL-Probleme relativ bewusst zu sein es scheint implementiert zu sein, und für mich ist es eine Ryzen7 1800X-Umgebung. Es war ungefähr 2 M Schritt / Stunde darunter Bei 2 Schritten / Stunde dauert es ungefähr 40 Stunden, bis 80 ms erreicht sind, was in der Zeitung angegeben ist. Fast Full-Python-Chainer ist GIL-bewusst und verarbeitet mehrere Prozesse Es ist nutzlos, wenn Sie es nicht implementieren
abschließend
Der Code, den ich geschrieben habe, um ihn zu reproduzieren, ist auf GitHub (LSTM-Version ist noch nicht verfügbar) veröffentlicht. Die Lernergebnisse werden später veröffentlicht ~~
Lernergebnis
Hier sind die Daten, als es mit Ryzen 1800X ungefähr 40 Stunden dauerte (ich wollte es wirklich mit 16Thread machen, aber es unterstützte den Kernel nicht, also 8)

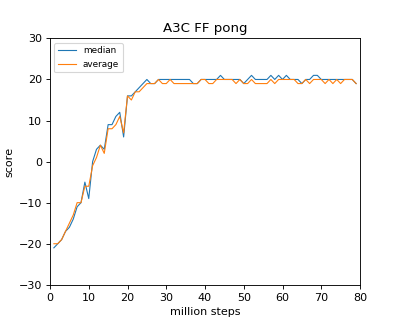
Soweit ich die Zeitung gelesen habe, scheint es, dass das gleiche Ergebnis für Breakout / Pong erzielt wird. Im Fall von Breakout / Pong scheint es in einem relativ frühen Stadium (20 Millionen Schritte) fast zu konvergieren.
Verweise
Asynchronous Methods for Deep Reinforcement Learning Reinforcement learning in continuous time: advantage updating
Recommended Posts