[PYTHON] Ein Überblick über DELG, eine neue Methode zum Extrahieren von Bildmerkmalen, die mit Kaggle Aufmerksamkeit erregt
Einführung
In diesem Artikel wird DELG vorgestellt, ein Algorithmus zur Extraktion von Bildmerkmalen, der in der Google Landmark Recognition Aufmerksamkeit erregt.
Dieser Algorithmus wurde im Januar 2020 angekündigt und es scheint, dass es fast keine japanische Literatur gibt.
Überblick
Die Extraktion von Bildmerkmalen ist grob in globale Merkmale unterteilt, die die Informationen des gesamten Bilds widerspiegeln, und in lokale Merkmale, die lokale Merkmale erfassen. Bisher wurden unterschiedliche Algorithmen für diese beiden Merkmalsextraktionen angewendet. In diesem Artikel werden diese zu einem Algorithmus kombiniert, um eine effiziente Merkmalsextraktion zu ermöglichen. Dies wird insbesondere durch die Verwendung der durchschnittlichen Pooling-Ebene für das globale Feature und der aufmerksamen Auswahl für das lokale Feature erreicht. Außerdem wird die Dimensionsreduzierung lokaler Features basierend auf dem Auto-Encoder eingeführt.
Infolgedessen hat dieses Modell in einer Reihe von Datensätzen (einschließlich des von Google veröffentlichten Landmark-Datensatzes) eine Leistung auf dem neuesten Stand der Technik erzielt.
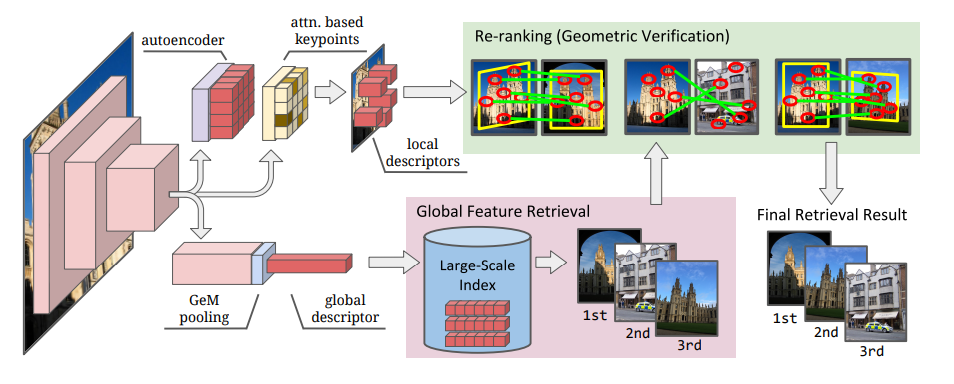
Was ist eine globale Funktion / eine lokale Funktion?
Globales Merkmal ist eine Merkmalsmenge, die aus dem gesamten Bild extrahiert wird. Ein lokales Feature ist eine Sammlung von Features, die aus einem Teil eines Bildes extrahiert wurden.
| Global feature (global descriptor, embedding) |
Local feature | |
|---|---|---|
| Bereich des Extraktionsziels | -Das ganze | -lokal |
| Abmessungen | - 画像につき1Abmessungen | - 画像につき複数Abmessungenになりうる |
| Extraktionsverfahren | -Berechnen Sie das Ganze auf einmal | 1.Wählen Sie das zu extrahierende Lokal aus(detector) 2.Merkmalsmenge extrahieren(descriptor) |
| Charakteristisch | -Leichte Berechnung, weil es ein Schritt ist -Da die Ausgabe pro Bild eindimensional ist, kann die Datenmenge unterdrückt werden -Hervorragender Rückruf |
-Relativ robust, auch wenn ein Teil des Bildes ausgeblendet ist -Hervorragende Präzision |
| Typische Methode | -Farbhistogramm - GeM pooling - ArcFace loss |
- SIFT - SURF - RANSAC - DELF |
Referenz
- Combining Local and Global Image Features for Object Class Recognition
- Großformatiges Bild basierend auf dem Hashing lokaler Funktionen
Sie können sehen, dass die Stärken und Schwächen der globalen und der lokalen Funktion unterschiedlich sind. Ähnliche Bildauswahlalgorithmen (Retrival) haben im Allgemeinen einen zweistufigen Ansatz, bei dem auf die Auswahl globaler Merkmale eine geometrische Überprüfung durch lokale Merkmale folgt.
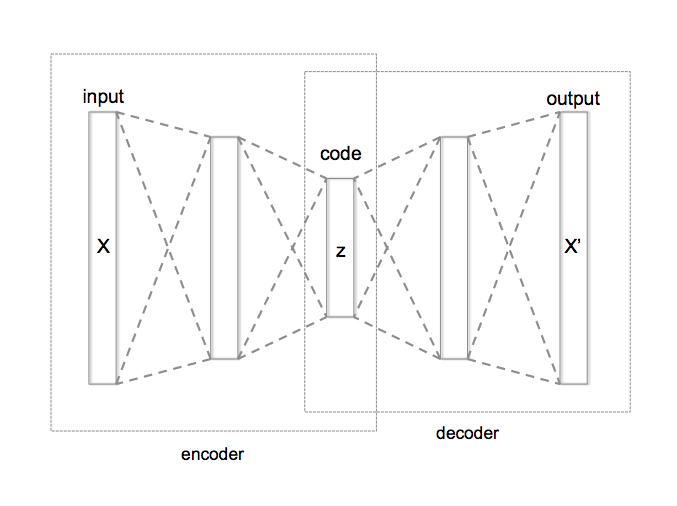
Was ist Autoencoder?
Es handelt sich um ein Dimensionsreduktionsverfahren unter Verwendung eines neuronalen Netzwerks, und die Dimension wird reduziert, indem eine Zwischenschicht mit einer geringeren Anzahl von Knoten als die Eingabeschicht angeordnet wird.
Da lokale Features im Allgemeinen eine große Dimension haben (100 bis 1.000), ist es üblich, eine Dimensionsreduzierung wie PCA separat durchzuführen. In diesem Artikel möchten wir jedoch die Abmessungen aus einer Hand reduzieren. Daher verwenden wir den Autoencoder, der in das neuronale Netzwerk integriert werden kann, um die Abmessungen zu reduzieren.
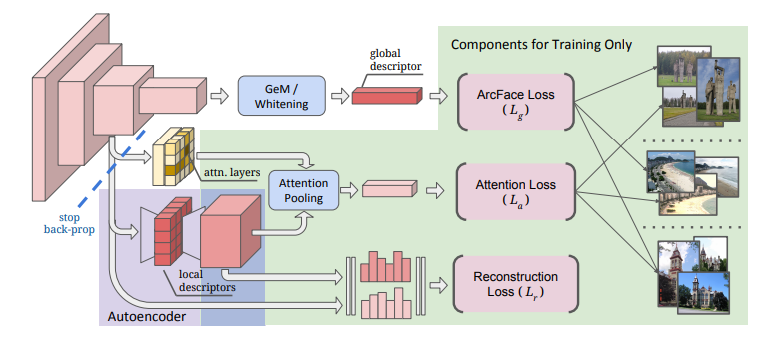
Vorgeschlagenes Modell
Die Merkmale des vorgeschlagenen Modells sind wie folgt.
- Basierend auf ResNet
- Global feature extraction
- Angepasste Ausgabe durch Generalized Mean Average (GeM) und Aufhellung der vollständig verbundenen Schicht
- Lernen mit ArcFace-Verlust
- Local feature
- Der Algorithmus, der charakteristische lokale Bereiche unterscheidet, ist wichtig. Aufmerksamkeitsmodul übernehmen
- Dimensionsreduzierung mit Autoencoder
- Lernen mit Aufmerksamkeitsverlust und Wiederaufbauverlust
Implementierung
Extrahieren Sie das globale und das lokale Merkmal des folgenden Bildes.

Global feature
import tensorflow as tf
#Laden Sie das trainierte DELG-Modell
SAVED_MODEL_DIR = '../input/delg-saved-models/local_and_global'
DELG_MODEL = tf.saved_model.load(SAVED_MODEL_DIR)
#Stellen Sie die Parameter ein
##Dimension des zu extrahierenden globalen Features
NUM_EMBEDDING_DIMENSIONS = 2048
##Stellen Sie die Bildauflösung ein(Image Pyramids)
DELG_IMAGE_SCALES_TENSOR = tf.convert_to_tensor([0.70710677, 1.0, 1.4142135])
##Schneiden Sie nur den Teil des DELG-Modells aus, der für die globale Merkmalsextraktion verwendet wird
DELG_INPUT_TENSOR_NAMES = ['input_image:0', 'input_scales:0']
GLOBAL_FEATURE_EXTRACTION_FN = DELG_MODEL.prune(DELG_INPUT_TENSOR_NAMES,
['global_descriptors:0'])
#Lesen Sie Bilddaten als Tensor aus dem Bildpfad
# image_Bitte stellen Sie den Pfad entsprechend ein
image_tensor = load_image_tensor(image_path)
#Extrahieren Sie die globale Funktion mit DELF
embedding_tensor_1 = GLOBAL_FEATURE_EXTRACTION_FN(image_tensor, DELG_IMAGE_SCALES_TENSOR)[0]
#Standardisieren
embedding_tensor_2 = tf.nn.l2_normalize(
embedding_tensor_1,
axis=1,
name='l2_normalization')
#Kombinieren Sie Ergebnisse unterschiedlicher Auflösungen
embedding_tensor_3 = tf.reduce_sum(
embedding_tensor_2, axis=0, name='sum_pooling')
#Standardisieren Sie dies weiter
embedding_res = tf.nn.l2_normalize(
embedding_tensor_3, axis=0, name='final_l2_normalization').numpy()
| Operation | Größe | |
|---|---|---|
| image_tensor | Bilddaten | 450, 800, 3 |
| embedding_tensor_1 | 2048-dimensionale globale Merkmalsextraktion für 3 Auflösungen | 3, 2048 |
| embedding_tensor_2 | Standardisierung | 3, 2048 |
| embedding_tensor_3 | Insgesamt in Richtung des Quetschens der Auflösungsachse | 2048, |
| embedding_res | Standardisierung | 2048, |
Local feature
#Stellen Sie die Parameter ein
##Maximale Anzahl der zu extrahierenden Features
LOCAL_FEATURE_NUM_TENSOR = tf.constant(1000)
#Schneiden Sie das Modell aus
LOCAL_FEATURE_EXTRACTION_FN = DELG_MODEL.prune(
DELG_INPUT_TENSOR_NAMES + ['input_max_feature_num:0', 'input_abs_thres:0'],
['boxes:0', 'features:0'])
#Laden Sie das Bild mit Tensor
image_tensor = load_image_tensor(image_path)
#Extraktion lokaler Merkmale durch DELF
#Geben Sie die Position und den Wert des Feature-Betrags aus
features = LOCAL_FEATURE_EXTRACTION_FN(image_tensor, DELG_IMAGE_SCALES_TENSOR,
LOCAL_FEATURE_NUM_TENSOR,
DELG_SCORE_THRESHOLD_TENSOR,
)
#Position des als Merkmalsgröße extrahierten Bildes
#Fügen Sie die 0. und 2. Spalte, die 1. und 3. Spalte der Ausgabe hinzu und dividieren Sie durch 2.
keypoints = tf.divide(
tf.add(
tf.gather(features[0], [0, 1], axis=1),
tf.gather(features[0], [2, 3], axis=1)), 2.0).numpy()
#Funktionswert
#Standardisieren
descriptors = tf.nn.l2_normalize(
features[1], axis=1, name='l2_normalization').numpy()
train_keypoints = keypoints
train_descriptors = descriptors
test_keypoints = keypoints_2 #Vergleich
test_descriptors = descriptors_2 #Vergleich
#Konvertieren Sie Deskriptoren in eine Baumstruktur und erhalten Sie Punkte, die nahe beieinander liegen.
#Referenz: https://myenigma.hatenablog.com/entry/2020/06/14/205753#kdtree%E3%81%A8%E3%81%AF
train_descriptor_tree = spatial.cKDTree(train_descriptors)
_, matches = train_descriptor_tree.query(
test_descriptors, distance_upper_bound=max_distance)
test_kp_count = test_keypoints.shape[0]
train_kp_count = train_keypoints.shape[0]
test_matching_keypoints = np.array([
test_keypoints[i,]
for i in range(test_kp_count)
#Der nächste Punkt ist max_Wenn der Abstand überschritten wird, wird der maximale Index +1 zurückgegeben.
if matches[i] != train_kp_count
])
train_matching_keypoints = np.array([
train_keypoints[matches[i],]
for i in range(test_kp_count)
if matches[i] != train_kp_count
])
Das Folgende zeigt das Ergebnis des Findens der lokalen Merkmale der beiden zu vergleichenden Bilder und des Visualisierens der übereinstimmenden Teile basierend auf den entsprechenden Deskriptoren. Es ist schade, dass die Positionen nicht genau richtig sind, aber Sie können sehen, dass die charakteristischen Teile grob zugeordnet sind.
| Das Originalbild | Datenerweiterung |
|---|---|
 |
 |
 |
 |
Entwicklungsbereich
Damit wurden die lokale Merkmalsmenge und ihre Entsprechung vorläufig erhalten, aber in der weiteren Entwicklung gibt es die folgenden Probleme.
- Ich möchte die Genauigkeit der entsprechenden Punkte verbessern
- Ich möchte die räumliche Beziehung verstehen (verstehen, wie unterschiedlich die Bilder aufgenommen wurden usw.)
Der RANSAC-Algorithmus wird üblicherweise für diese Probleme verwendet. Darüber hinaus wird Pydegensac in kaggle als schnellerer Algorithmus als RANSAC eingeführt. Die folgenden Artikel sind leicht zu verstehen, schauen Sie also bitte mal rein.
Referenz:
- Zuordnung von Merkmalspunkten durch Berechnung des "Bewegungsbetrags" und des "Verformungsbetrags" jedes Bildes
- RANSAC: Pydegensac vs Scikit
Am Ende
Siehe unten für weitere Details.
Recommended Posts