[PYTHON] Ich habe versucht, Faster R-CNN mit Pytorch auszuführen
Einführung
Beachten Sie, dass ich große Probleme hatte, da es nur wenige Artikel gab, in denen Faster R-CNN mit einem geeigneten Datensatz ausgeführt wurde.
Da dies mein erster Beitrag ist, denke ich, dass einige Dinge nicht erreicht werden können, aber wenn Sie Fehler haben, weisen Sie bitte darauf hin.
Anmerkungen
- Dieser Artikel ist für ** Datensätze im PSCAL-VOC-Format **. Ich habe den Datensatz mit dem Namen BDD100K in das Pascal VOC-Format konvertiert und trainiert, sodass die Klassenbezeichnung die von BDD100K ist.
Code
Der gesamte Code geht an github. (Wenn Sie den gesamten folgenden Code kopieren und einfügen und den Klassennamen mit dem Datensatz abgleichen, sollte dies funktionieren.)
importieren
Knusprig
import numpy as np
import pandas as pd
from PIL import Image
from glob import glob
import xml.etree.ElementTree as ET
import torch
import torchvision
from torchvision import transforms
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
dataloader.py
#Datenort
xml_paths_train=glob("##########/*.xml")
xml_paths_val=glob("###########/*.xml")
image_dir_train="#############"
image_dir_val="##############"
Die beiden oberen Zeilen geben den Speicherort der XML-Datei an Die beiden Linien sind die Position des Bildes
Daten lesen
dataloader.py
class xml2list(object):
def __init__(self, classes):
self.classes = classes
def __call__(self, xml_path):
ret = []
xml = ET.parse(xml_path).getroot()
for size in xml.iter("size"):
width = float(size.find("width").text)
height = float(size.find("height").text)
for obj in xml.iter("object"):
difficult = int(obj.find("difficult").text)
if difficult == 1:
continue
bndbox = [width, height]
name = obj.find("name").text.lower().strip()
bbox = obj.find("bndbox")
pts = ["xmin", "ymin", "xmax", "ymax"]
for pt in pts:
cur_pixel = float(bbox.find(pt).text)
bndbox.append(cur_pixel)
label_idx = self.classes.index(name)
bndbox.append(label_idx)
ret += [bndbox]
return np.array(ret) # [width, height, xmin, ymin, xamx, ymax, label_idx]
Anmerkungen werden geladen
Geben Sie für Klassen ** die verwendete Datenklasse ** ein.
dataloader.py
#Laden einer Anotation des Zuges
xml_paths=xml_paths_train
classes = [###################################]
transform_anno = xml2list(classes)
df = pd.DataFrame(columns=["image_id", "width", "height", "xmin", "ymin", "xmax", "ymax", "class"])
for path in xml_paths:
#image_id = path.split("/")[-1].split(".")[0]
image_id = path.split("\\")[-1].split(".")[0]
bboxs = transform_anno(path)
for bbox in bboxs:
tmp = pd.Series(bbox, index=["width", "height", "xmin", "ymin", "xmax", "ymax", "class"])
tmp["image_id"] = image_id
df = df.append(tmp, ignore_index=True)
df = df.sort_values(by="image_id", ascending=True)
#Val Anotation lesen
xml_paths=xml_paths_val
classes = [#######################]
transform_anno = xml2list(classes)
df_val = pd.DataFrame(columns=["image_id", "width", "height", "xmin", "ymin", "xmax", "ymax", "class"])
for path in xml_paths:
#image_id = path.split("/")[-1].split(".")[0]
image_id = path.split("\\")[-1].split(".")[0]
bboxs = transform_anno(path)
for bbox in bboxs:
tmp = pd.Series(bbox, index=["width", "height", "xmin", "ymin", "xmax", "ymax", "class"])
tmp["image_id"] = image_id
df_val = df_val.append(tmp, ignore_index=True)
df_val = df_val.sort_values(by="image_id", ascending=True)
Bilder laden
dataloader.py
#Bilder laden
#Da die Hintergrundklasse (0) erforderlich ist, Hund,1 Startetikett für Katze
df["class"] = df["class"] + 1
class MyDataset(torch.utils.data.Dataset):
def __init__(self, df, image_dir):
super().__init__()
self.image_ids = df["image_id"].unique()
self.df = df
self.image_dir = image_dir
def __getitem__(self, index):
transform = transforms.Compose([
transforms.ToTensor()
])
#Eingabebild laden
image_id = self.image_ids[index]
image = Image.open(f"{self.image_dir}/{image_id}.jpg ")
image = transform(image)
#Anmerkungsdaten lesen
records = self.df[self.df["image_id"] == image_id]
boxes = torch.tensor(records[["xmin", "ymin", "xmax", "ymax"]].values, dtype=torch.float32)
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
area = torch.as_tensor(area, dtype=torch.float32)
labels = torch.tensor(records["class"].values, dtype=torch.int64)
iscrowd = torch.zeros((records.shape[0], ), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"]= labels
target["image_id"] = torch.tensor([index])
target["area"] = area
target["iscrowd"] = iscrowd
return image, target, image_id
def __len__(self):
return self.image_ids.shape[0]
image_dir1=image_dir_train
dataset = MyDataset(df, image_dir1)
image_dir2=image_dir_val
dataset_val = MyDataset(df_val, image_dir2)
Erstellen eines DataLoader
dataloader.py
#Lade Daten
torch.manual_seed(2020)
train=dataset
val=dataset_val
def collate_fn(batch):
return tuple(zip(*batch))
train_dataloader = torch.utils.data.DataLoader(train, batch_size=1, shuffle=True, collate_fn=collate_fn)
val_dataloader = torch.utils.data.DataLoader(val, batch_size=2, shuffle=False, collate_fn=collate_fn)
Die batch_size ist klein, da der GPU-Speicher sofort überlief, als ich ihn drehte.
Modelldefinition
Wenn Sie die Genauigkeit auch bei geringem Lernaufwand verbessern möchten, empfehlen wir ** model1.py **. Ich möchte nur ein bisschen mit dem Modell spielen! Bitte benutzen Sie ** model2.py **. (Model2 hat fast keinen Kommentarartikel, und ich war für immer besorgt, weil der Quellcode des Torchvision-Tutorials falsch war.)
*** Achtung num_classes funktioniert nur, wenn die Anzahl der zu klassifizierenden Klassen +1 beträgt. (+1 ist, weil der Hintergrund ebenfalls klassifiziert werden muss) **
model1 verwendet normalerweise ein trainiertes Modell mit resnet50 als Backbone
model1.py
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=False)####True
##Hinweis: Anzahl der Klassen + 1
num_classes = (len(classes)) + 1
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
model2 sieht so aus (es gibt einen Fehler im Tutorial ...)
model2.py
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
backbone = torchvision.models.mobilenet_v2(pretrained=True).features
backbone.out_channels = 1280
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
#Wenn das Tutorial gepackt ist, wird hier ein Fehler ausgegeben.([0]Zu['0']Wenn Sie es einstellen)
'''
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=[0],
output_size=7,
sampling_ratio=2)
'''
#Standardmäßig
roi_pooler =torchvision.ops.MultiScaleRoIAlign(
featmap_names=['0','1','2','3'],
output_size=7,
sampling_ratio=2)
# put the pieces together inside a FasterRCNN model
model = FasterRCNN(backbone,
num_classes=(len(classes)) + 1,###Hinweis
rpn_anchor_generator=anchor_generator)
#box_roi_pool=roi_pooler)
Die FasterRCNN-Funktion hat verschiedene Argumente und Sie können ziemlich viel mit dem Modell spielen. Weitere Informationen hier
Lernen
Die automatische Differenzierung ist wunderbar
train.py
##Lernen
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005)
num_epochs = 5
#GPU-Cache löschen
import torch
torch.cuda.empty_cache()
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
##model.cuda()
model.train()#Wechseln Sie in den Lernmodus
for epoch in range(num_epochs):
for i, batch in enumerate(train_dataloader):
images, targets, image_ids = batch#####Batch ist das Bild und die Ziele des Mini-Batches,image_Enthält IDs
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
##Bild und Ziel (Boden) im Lernmodus-Wahrheit)
##Der Rückgabewert ist diktiert[tensor]Es ist ein Verlust darin. (Verlust von RPN und RCNN)
loss_dict= model(images, targets)
losses = sum(loss for loss in loss_dict.values())
loss_value = losses.item()
optimizer.zero_grad()
losses.backward()
optimizer.step()
if (i+1) % 20 == 0:
print(f"epoch #{epoch+1} Iteration #{i+1} loss: {loss_value}")
Ergebnisse anzeigen
Hinweis: Geben Sie hier das Nutzungsdatenetikett gemäß dem Eingabebeispiel für die Kategorie ein.
test.py
#Ergebnisse anzeigen
def show(val_dataloader):
import matplotlib.pyplot as plt
from PIL import ImageDraw, ImageFont
from PIL import Image
#GPU-Cache löschen
import torch
torch.cuda.empty_cache()
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
#device = torch.device('cpu')
model.to(device)
model.eval()#Zum Inferenzmodus
images, targets, image_ids = next(iter(val_dataloader))
images = list(img.to(device) for img in images)
#Gibt beim Ableiten eine Vorhersage zurück
'''
- boxes (FloatTensor[N, 4]): the predicted boxes in [x1, y1, x2, y2] format, with values of x
between 0 and W and values of y between 0 and H
- labels (Int64Tensor[N]): the predicted labels for each image
- scores (Tensor[N]): the scores or each prediction
'''
outputs = model(images)
for i, image in enumerate(images):
image = image.permute(1, 2, 0).cpu().numpy()
image = Image.fromarray((image * 255).astype(np.uint8))
boxes = outputs[i]["boxes"].data.cpu().numpy()
scores = outputs[i]["scores"].data.cpu().numpy()
labels = outputs[i]["labels"].data.cpu().numpy()
category={0: 'background',##################}
#Beispiel für einen Kategorieeintrag
#category={0: 'background',1:'person', 2:'traffic light',3: 'train',4: 'traffic sign', 5:'rider', 6:'car', 7:'bike',8: 'motor', 9:'truck', 10:'bus'}
boxes = boxes[scores >= 0.5].astype(np.int32)
scores = scores[scores >= 0.5]
image_id = image_ids[i]
for i, box in enumerate(boxes):
draw = ImageDraw.Draw(image)
label = category[labels[i]]
draw.rectangle([(box[0], box[1]), (box[2], box[3])], outline="red", width=3)
#Anzeige des Etiketts
from PIL import Image, ImageDraw, ImageFont
#fnt = ImageFont.truetype('/content/mplus-1c-black.ttf', 20)
fnt = ImageFont.truetype("arial.ttf", 10)#40
text_w, text_h = fnt.getsize(label)
draw.rectangle([box[0], box[1], box[0]+text_w, box[1]+text_h], fill="red")
draw.text((box[0], box[1]), label, font=fnt, fill='white')
#Für den Fall, dass Sie ein Bild speichern möchten
#image.save(f"resample_test{str(i)}.png ")
fig, ax = plt.subplots(1, 1)
ax.imshow(np.array(image))
plt.show()
show(val_dataloader)
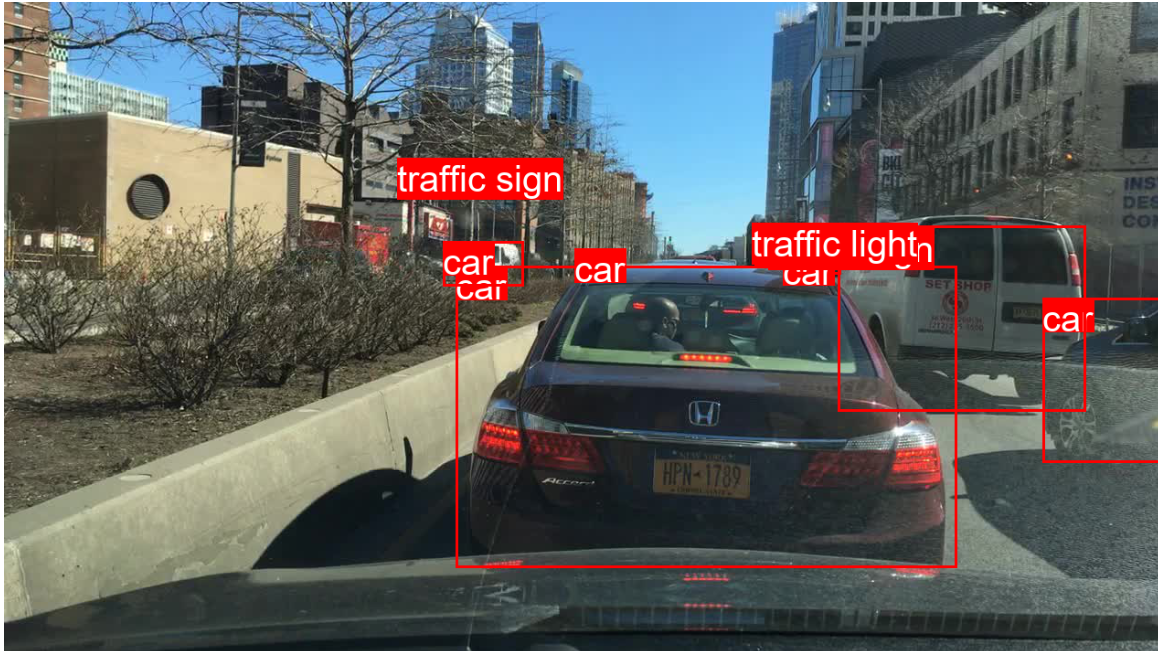
Es sollte so angezeigt werden
Schließlich
――Ich habe zum ersten Mal einen Artikel geschrieben. Es ist fast so, als würde man nur den Quellcode einfügen, aber ich hoffe, Sie können darauf verweisen. ――Ich möchte einen Papierkommentar ausprobieren
Verweise
-
http://maruo51.com/2020/06/06/faster-rcnn_dogcat/
-
Klicken Sie hier, um das Torchvision-Tutorial aufzurufen
Recommended Posts