[PYTHON] Ergänzung der fehlenden titanischen Werte von kaggle und Erstellung von Features
Einführung
Beim letzten Mal habe ich mir die Zugdaten der Titanic angesehen, um festzustellen, welche Merkmale mit der Überlebensrate zusammenhängen. Letztes Mal: Datenanalyse vor der Generierung von Titanic-Features von Kaggle (Ich hoffe, Sie können diesen Artikel auch lesen)
Basierend auf dem Ergebnis erstellen wir dieses Mal ** einen Datenrahmen, der die fehlenden Werte ergänzt und dem Vorhersagemodell die erforderlichen Funktionen hinzufügt **.
Dieses Mal werden wir als Vorhersagemodell "** GBDT (Gradient Boosting Tree) xg Boost **" verwenden, das häufig in Kaggle-Wettbewerben verwendet wird, damit wir die Daten dafür geeignet machen.
1. Datenerfassung und Bestätigung fehlender Werte
import pandas as pd
import numpy as np
train = pd.read_csv('/kaggle/input/titanic/train.csv')
test = pd.read_csv('/kaggle/input/titanic/test.csv')
#Kombinieren Sie Zugdaten und Testdaten zu einem
data = pd.concat([train,test]).reset_index(drop=True)
#Überprüfen Sie die Anzahl der Zeilen, die fehlende Werte enthalten
train.isnull().sum()
test.isnull().sum()
Die Nummer jedes fehlenden Werts ist wie folgt.
| Zugdaten | Testdaten | |
|---|---|---|
| PassengerId | 0 | 0 |
| Survived | 0 | |
| Pclass | 0 | 0 |
| Name | 0 | 0 |
| Sex | 0 | 0 |
| Age | 177 | 86 |
| SibSp | 0 | 0 |
| Parch | 0 | 0 |
| Ticket | 0 | 0 |
| Fare | 0 | 1 |
| Cabin | 687 | 327 |
| Embarked | 2 | 0 |
2. Ergänzung von Einschiffung und Tarif
Wenn Sie sich zunächst die beiden Reihen ansehen, in denen die Einschiffung fehlt, ist sowohl ** Klasse 1 ** als auch ** Tarif 80 **.
 Unter denen mit einer 'P-Klasse von 1' und einem 'Tarif von 70-90' hatte ** Embarked den höchsten Anteil an S **, daher werden diese beiden durch S ergänzt.
Unter denen mit einer 'P-Klasse von 1' und einem 'Tarif von 70-90' hatte ** Embarked den höchsten Anteil an S **, daher werden diese beiden durch S ergänzt.
data['Embarked'] = data['Embarked'].fillna('S')
In Bezug auf den Fahrpreis betrug die ** P-Klasse der fehlenden Linie 3 ** und ** die Einschiffung war S **.
 Daher wird es durch den Medianwert unter denjenigen ergänzt, die diese beiden Bedingungen erfüllen.
Daher wird es durch den Medianwert unter denjenigen ergänzt, die diese beiden Bedingungen erfüllen.
data['Fare'] = data['Fare'].fillna(data.query('Pclass==3 & Embarked=="S"')['Fare'].median())
In Bezug auf den fehlenden Wert von Alter möchte ich das Alter anhand einer zufälligen Gesamtstruktur vorhersagen, nachdem ich andere Feature-Mengen erstellt habe. Daher werde ich es später beschreiben.
3. Klassifizierung von Merkmalen
** Familiengröße, Tarif, Kabine, Ticket **, die Sibsp und Parch kombinieren, werden ** nach dem Unterschied in der Überlebensrate ** klassifiziert. Informationen zum Unterschied in der Überlebensrate für die einzelnen Funktionen finden Sie im Artikel Zurück.
** Klassifizierung der Merkmalsmenge 'Family_size', die die Anzahl der Familienmitglieder darstellt **
data['Family_size'] = data['SibSp']+data['Parch']+1
data['Family_size_bin'] = 0
data.loc[(data['Family_size']>=2) & (data['Family_size']<=4),'Family_size_bin'] = 1
data.loc[(data['Family_size']>=5) & (data['Family_size']<=7),'Family_size_bin'] = 2
data.loc[(data['Family_size']>=8),'Family_size_bin'] = 3
** Tarifklassifizierung **
data['Fare_bin'] = 0
data.loc[(data['Fare']>=10) & (data['Fare']<50), 'Fare_bin'] = 1
data.loc[(data['Fare']>=50) & (data['Fare']<100), 'Fare_bin'] = 2
data.loc[(data['Fare']>=100), 'Fare_bin'] = 3
** Kabinenklassifizierung **
#Merkmalsmenge, die das erste Alphabet darstellt'Cabin_label'Erstellen(Fehlender Wert'n')
data['Cabin_label'] = data['Cabin'].map(lambda x:str(x)[0])
data['Cabin_label_bin'] = 0
data.loc[(data['Cabin_label']=='A')|(data['Cabin_label']=='G'), 'Cabin_label_bin'] = 1
data.loc[(data['Cabin_label']=='C')|(data['Cabin_label']=='F'), 'Cabin_label_bin'] = 2
data.loc[(data['Cabin_label']=='T'), 'Cabin_label_bin'] = 3
data.loc[(data['Cabin_label']=='n'), 'Cabin_label_bin'] = 4
** Klassifizierung nach der Anzahl der doppelten Ticketnummern 'Ticket_count' **
data['Ticket_count'] = data.groupby('Ticket')['PassengerId'].transform('count')
data['Ticket_count_bin'] = 0
data.loc[(data['Ticket_count']>=2) & (data['Ticket_count']<=4), 'Ticket_count_bin'] = 1
data.loc[(data['Ticket_count']>=5), 'Ticket_count_bin'] = 2
** Klassifizierung nach Ticketnummer **
#Teilen Sie in Tickets mit nur Zahlen und Tickets mit Zahlen und Alphabeten
#Holen Sie sich ein Ticket nur für Nummern
num_ticket = data[data['Ticket'].str.match('[0-9]+')].copy()
num_ticket_index = num_ticket.index.values.tolist()
#Tickets, bei denen nur Nummern aus den Originaldaten entfernt wurden und der Rest Alphabete enthält
num_alpha_ticket = data.drop(num_ticket_index).copy()
#Klassifizierung von Tickets nur mit Nummern
#Da die Ticketnummer eine Zeichenfolge ist, wird sie in einen numerischen Wert konvertiert
num_ticket['Ticket'] = num_ticket['Ticket'].apply(lambda x:int(x))
num_ticket['Ticket_bin'] = 0
num_ticket.loc[(num_ticket['Ticket']>=100000) & (num_ticket['Ticket']<200000),
'Ticket_bin'] = 1
num_ticket.loc[(num_ticket['Ticket']>=200000) & (num_ticket['Ticket']<300000),
'Ticket_bin'] = 2
num_ticket.loc[(num_ticket['Ticket']>=300000),'Ticket_bin'] = 3
#Klassifizierung von Tickets einschließlich Nummern und Alphabeten
num_alpha_ticket['Ticket_bin'] = 4
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('A.+'),'Ticket_bin'] = 5
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('C.+'),'Ticket_bin'] = 6
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('C\.*A\.*.+'),'Ticket_bin'] = 7
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('F\.C.+'),'Ticket_bin'] = 8
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('PC.+'),'Ticket_bin'] = 9
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('S\.+.+'),'Ticket_bin'] = 10
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('SC.+'),'Ticket_bin'] = 11
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('SOTON.+'),'Ticket_bin'] = 12
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('STON.+'),'Ticket_bin'] = 13
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('W\.*/C.+'),'Ticket_bin'] = 14
data = pd.concat([num_ticket,num_alpha_ticket]).sort_values('PassengerId')
4. Altersergänzung
Für den fehlenden Wert von Alter gibt es eine Methode zum ** Median ** oder ** Ermitteln und Ergänzen des Durchschnittsalters für jeden Titel des Namens **, aber als ich ihn nachgeschlagen habe, fehlte er ** unter Verwendung einer zufälligen Gesamtstruktur. Es gab eine Methode **, um das Alter des Teils vorherzusagen, in dem es sich befindet, also werde ich diesmal dieses verwenden.
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestRegressor
#Beschriften Sie nicht numerische Merkmale numerisch
#Beschriften Sie auch Funktionen, die nicht zur Vorhersage des Alters verwendet werden
le = LabelEncoder()
data['Sex'] = le.fit_transform(data['Sex'])
data['Embarked'] = le.fit_transform(data['Embarked'])
data['Cabin_label'] = le.fit_transform(data['Cabin_label'])
#Die Feature-Menge, die zur Vorhersage des Alters verwendet wird'age_data'Einstellen
age_data = data[['Age','Pclass','Family_size',
'Fare_bin','Cabin_label','Ticket_count']].copy()
#Teilen Sie in fehlende und nicht fehlende Zeilen
known_age = age_data[age_data['Age'].notnull()].values
unknown_age = age_data[age_data['Age'].isnull()].values
x = known_age[:, 1:]
y = known_age[:, 0]
#Lerne in einem zufälligen Wald
rfr = RandomForestRegressor(random_state=0, n_estimators=100, n_jobs=-1)
rfr.fit(x, y)
#Sagen Sie den Wert voraus und weisen Sie ihn der fehlenden Zeile zu
age_predict = rfr.predict(unknown_age[:, 1:])
data.loc[(data['Age'].isnull()), 'Age'] = np.round(age_predict,1)
Sie haben jetzt den fehlenden Wert für Alter vervollständigt.
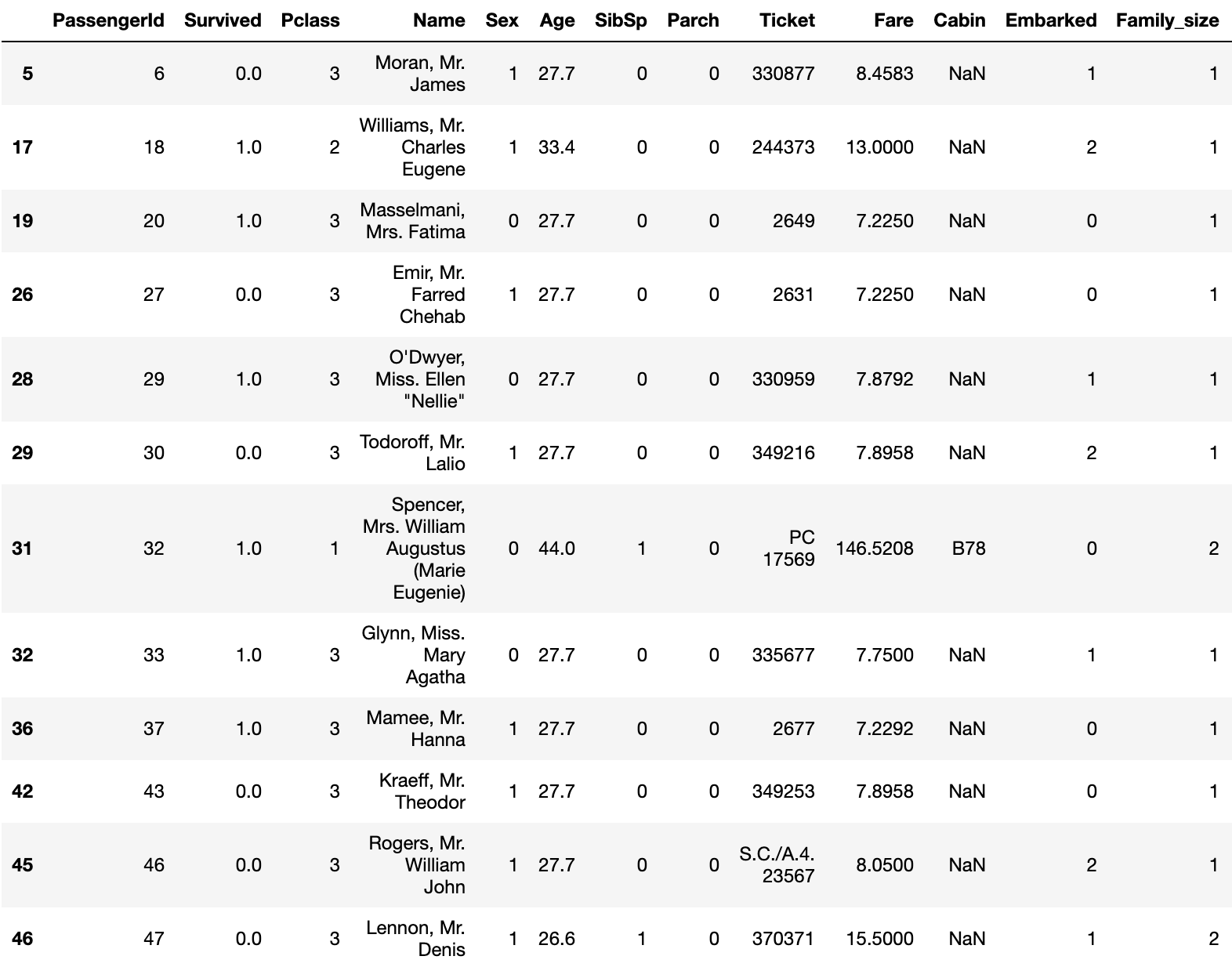 Und das Alter wird ebenfalls klassifiziert.
Und das Alter wird ebenfalls klassifiziert.
data['Age_bin'] = 0
data.loc[(data['Age']>10) & (data['Age']<=30),'Age_bin'] = 1
data.loc[(data['Age']>30) & (data['Age']<=50),'Age_bin'] = 2
data.loc[(data['Age']>50) & (data['Age']<=70),'Age_bin'] = 3
data.loc[(data['Age']>70),'Age_bin'] = 4
Lassen Sie zum Schluss den unnötigen Feature-Betrag fallen und die Erstellung des Feature-Betrags ist abgeschlossen.
#Löschen Sie unnötige Funktionen.
data = data.drop(['PassengerId','Name','Age','Fare','SibSp','Parch','Ticket','Cabin',
'Family_size','Cabin_label','Ticket_count'], axis=1)
Am Ende sieht der Datenrahmen so aus.
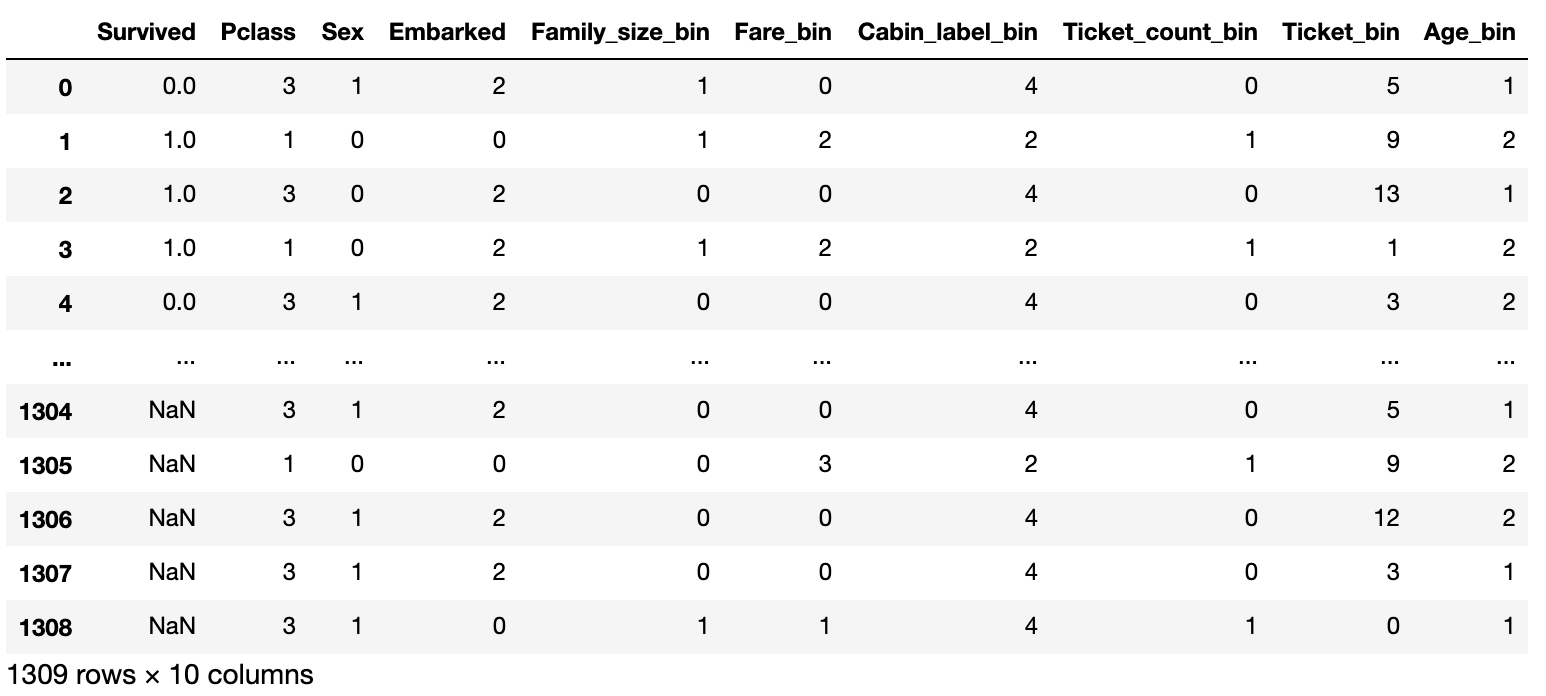
5. Vorhersage mit xg Boost
Teilen Sie die Daten zunächst erneut in Zugdaten und Testdaten auf und teilen Sie sie nur für Merkmalsmengen in "X" und nur für "Überleben" in "Y".
#Teilen Sie erneut in Zugdaten und Testdaten
model_train = data[:891]
model_test = data[891:]
X = model_train.drop('Survived', axis=1)
Y = pd.DataFrame(model_train['Survived'])
x_test = model_test.drop('Survived', axis=1)
Schauen wir uns die Leistung des Modells an, indem wir zwei suchen: ** logloss ** und ** Genauigkeit **.
from sklearn.metrics import log_loss
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
import xgboost as xgb
#Parameter einstellen
params = {'objective':'binary:logistic',
'max_depth':5,
'eta': 0.1,
'min_child_weight':1.0,
'gamma':0.0,
'colsample_bytree':0.8,
'subsample':0.8}
num_round = 1000
logloss = []
accuracy = []
kf = KFold(n_splits=4, shuffle=True, random_state=0)
for train_index, valid_index in kf.split(X):
x_train, x_valid = X.iloc[train_index], X.iloc[valid_index]
y_train, y_valid = Y.iloc[train_index], Y.iloc[valid_index]
#Konvertieren Sie den Datenrahmen in eine Form, die für xg boost geeignet ist
dtrain = xgb.DMatrix(x_train, label=y_train)
dvalid = xgb.DMatrix(x_valid, label=y_valid)
dtest = xgb.DMatrix(x_test)
#Lerne mit xgboost
model = xgb.train(params, dtrain, num_round,evals=[(dtrain,'train'),(dvalid,'eval')],
early_stopping_rounds=50)
valid_pred_proba = model.predict(dvalid)
#Fragen Sie nach Protokollverlust
score = log_loss(y_valid, valid_pred_proba)
logloss.append(score)
#Finden Sie Genauigkeit
#valid_pred_Da proba ein Wahrscheinlichkeitswert ist, wird er in 0 und 1 konvertiert.
valid_pred = np.where(valid_pred_proba >0.5,1,0)
acc = accuracy_score(y_valid, valid_pred)
accuracy.append(acc)
print(f'log_loss:{np.mean(logloss)}')
print(f'accuracy:{np.mean(accuracy)}')
Mit diesem Code log_loss : 0.4234131996311837 accuracy : 0.8114369975356523 Das Ergebnis war das.
Nachdem das Modell vollständig ist, erstellen Sie die Prognosedaten, die an kaggle gesendet werden sollen.
y_pred_proba = model.predict(dtest)
y_pred= np.where(y_pred_proba > 0.5,1,0)
submission = pd.DataFrame({'PassengerId':test['PassengerId'], 'Survived':y_pred})
submission.to_csv('titanic_xgboost.csv', index=False)
Das Ergebnis sieht so aus.
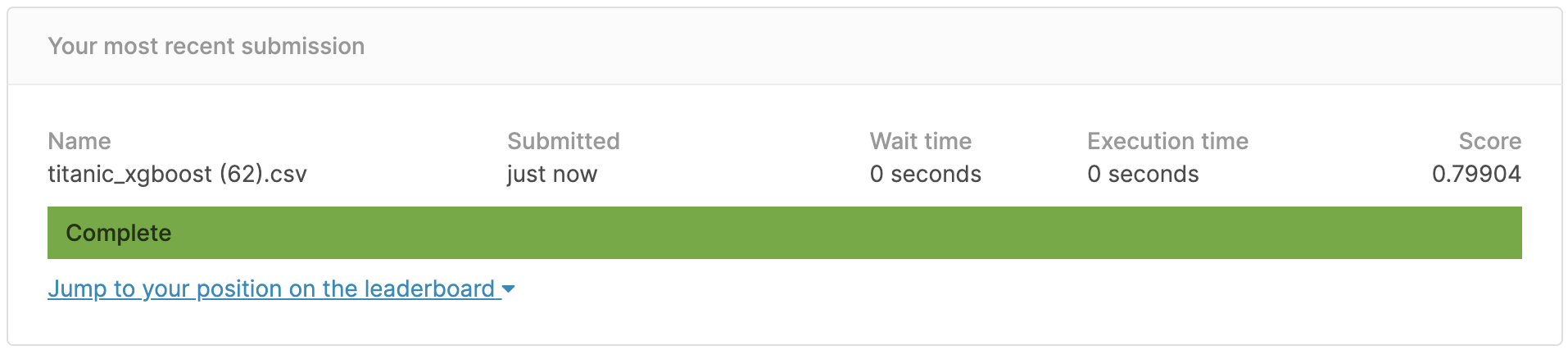 Die korrekte Antwortrate betrug ** 79,9% **, was nicht 80% erreichte, aber es scheint, dass sie durch Anpassen der Parameter des Modells 80% erreichen kann.
Die korrekte Antwortrate betrug ** 79,9% **, was nicht 80% erreichte, aber es scheint, dass sie durch Anpassen der Parameter des Modells 80% erreichen kann.
Zusammenfassung
Dieses Mal habe ich versucht, den vorhergesagten Wert tatsächlich an kaggle zu senden.
Kabinendaten, von denen ich dachte, dass sie nicht als Feature verwendet werden können, weil viele Werte fehlen. Als ich jedoch versuchte, jeden fehlenden Wert zu kennzeichnen, erhöhte sich die Genauigkeitsrate des vorhergesagten Werts **, und die Feature-Menge kann verwendet werden, wenn die Daten ordnungsgemäß verarbeitet werden. Ich habe herausgefunden, dass. Wenn Sie Vorhersagen treffen, ohne Merkmale wie Tarif und Alter zu klassifizieren, verbessern sich ** Logloss- und Genauigkeitswerte **, ** aber die Genauigkeitsrate der vorhergesagten Werte verbessert sich nicht **. Ich war der Meinung, dass es möglich sein würde, ein geeignetes Modell ohne Überlernen zu erstellen, indem man es anhand des Unterschieds in der Überlebensrate klassifiziert, anstatt die Merkmalsmenge so zu verwenden, wie sie ist.
Wenn Sie Meinungen oder Vorschläge haben, würden wir uns freuen, wenn Sie einen Kommentar abgeben oder eine Anfrage bearbeiten könnten.
Websites und Bücher, auf die ich mich bezog
Kaggle Tutorial Das Top 2% Know-how der Titanic pyhaya’s diary Buch: [Datenanalysetechnologie, die mit Kaggle gewinnt](https://www.amazon.co.jp/Kaggle%E3%81%A7%E5%8B%9D%E3%81%A4%E3%83%87% E3% 83% BC% E3% 82% BF% E5% 88% 86% E6% 9E% 90% E3% 81% AE% E6% 8A% 80% E8% A1% 93-% E9% 96% 80% E8 % 84% 87-% E5% A4% A7% E8% BC% 94-ebook / dp / B07YTDBC3Z)