[LINUX] Wiedereinführung in Docker
Seit 2016 sind fast vier Jahre vergangen, um Docker bei der Arbeit einzusetzen. Ich werde versuchen, das Wissen über Docker zu organisieren, das ich bisher aufgrund des technischen Chats des Unternehmens fragmentarisch gelernt habe. Dieser Satz befasst sich mit der Technologie, die hinter Docker verwendet wird, warum Docker ursprünglich erstellt wurde, und nicht mit den Operationsbefehlen von Docker und dem Schreiben einer Docker-Datei.
Inhaltsverzeichnis
- Rückblick auf die Entwicklung der IT-Infrastruktur
- Virtualisierung
- Docker
- Eigenschaften von Docker
~ Rückblick auf die Entwicklung der IT-Infrastruktur ~
Die IT-Infrastruktur hat etwa 70 Jahre nach der Erfindung der Computer verschiedene Entwicklungen erfahren. In diesem Prozess wurden verschiedene Technologien entwickelt, um eine effiziente Nutzung der IT-Infrastrukturressourcen zu ermöglichen. Der Ursprung der aktuellen Servervirtualisierung wurde in den 1970er Jahren zur Virtualisierungstechnologie für Mainframes. Danach wurde die x86-CPU-Servervirtualisierung mit der Geburt von VMWare um 1999 sofort gefördert.
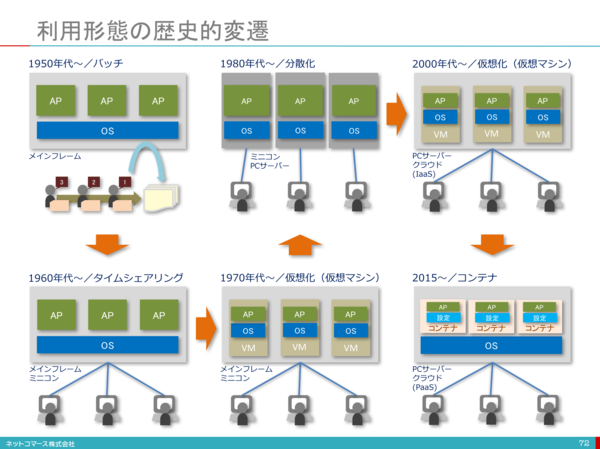 Die Abbildung basiert auf [1].
Die Abbildung basiert auf [1].
Unverzichtbar in der Cloud-Ära ~ Virtualisierung ~
Es gibt verschiedene Arten der Virtualisierung, auch wenn sie als Virtualisierung bezeichnet wird. Es gibt viele Schlüsselwörter wie Netzwerkvirtualisierung, Servervirtualisierung und Anwendungsvirtualisierung. Hier wird hauptsächlich die Servervirtualisierung zusammengefasst.
Servervirtualisierung
Die Servervirtualisierung soll auf einem physischen Server so ausgeführt werden, als wären es mehrere Server. Die Servervirtualisierung führt zu einer Kostenreduzierung, indem die Anzahl der Server verringert wird. Was für eine Methode ist die Servervirtualisierung? Immer wenn ich im Internet nach Virtualisierung suche, erhalte ich das Wort, dass es Host- und Hypervisor-Typen gibt. Wenn man sich jedoch die Definition von Hypervisor in Wikipedia ansieht, kann man sagen, dass alle diese beiden Typen tatsächlich Hypervisoren sind. Erstens [Hypervisor](https://ja.wikipedia.org/wiki/%E3%83%8F%E3%82%A4%E3%83%91%E3%83%BC%E3%83%90% E3% 82% A4% E3% 82% B6) [2] ist ein Steuerungsprogramm zur Realisierung einer virtuellen Maschine (Virtual Machine), die eine der Computervirtualisierungstechnologien in Bezug auf Computer darstellt. Wird manchmal als virtueller Monitor oder virtuelles Betriebssystem bezeichnet. Nach der Definition von Wikipedia gibt es zwei Arten von Hypervisoren.
- Typ 1 ("Native" oder "Bare Metal") Hypervisor
Der Hypervisor wird direkt auf der Hardware ausgeführt, und alle Betriebssysteme (Gastbetriebssysteme) werden auf dem Hypervisor ausgeführt. "Hypervisor" im engeren Sinne bezieht sich nur darauf.
Produkt: Microsoft Hyper-V, Citrix XenServer

- Typ 2 ("Host") Hypervisor
Ein anderes Betriebssystem wird zuerst auf der Hardware ausgeführt (dieses Betriebssystem wird als Host-Betriebssystem bezeichnet), dann wird der Hypervisor ausgeführt (als Anwendung des Host-Betriebssystems) und dann wird ein anderes Betriebssystem (dieses Betriebssystem) auf dem Hypervisor ausgeführt. Dies ist eine Methode zum Ausführen eines Betriebssystems (als Gastbetriebssystem bezeichnet). Im engeren Sinne ist Typ 2 nicht im Hypervisor enthalten.
Produkte: Oracle VirtualBox, Parallels Parallels Workstation und Parallels Desktop
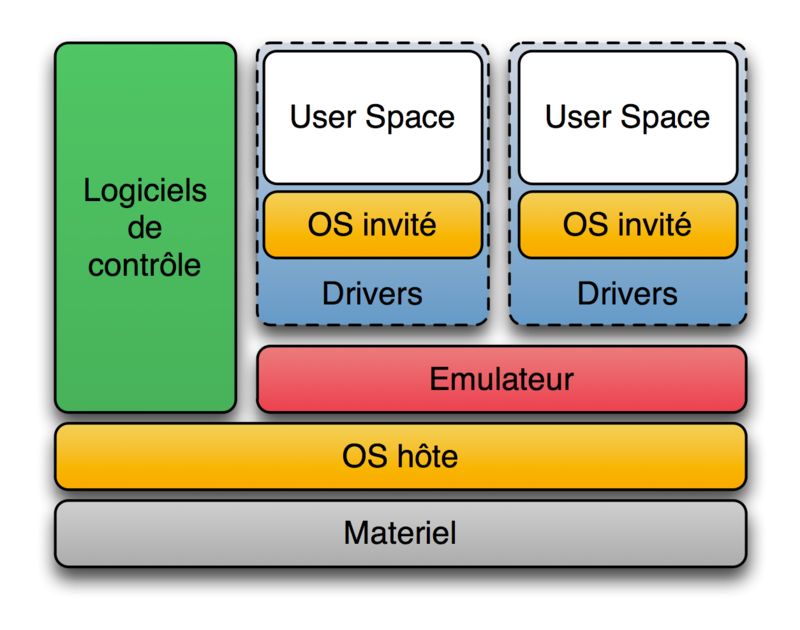
Gehostete Virtualisierung wird häufig als Hypervisor Type2 und Hypervisor Type1 bezeichnet.
Typ 1 hat den Vorteil einer hohen Verarbeitungsgeschwindigkeit, da die Ressourcen vollständig getrennt sind und jeder virtuelle Server direkt mit der Hardware interagiert. Zum anderen hat es auch den Nachteil hoher Installationskosten.
Typ 2 hat den Vorteil geringer Installationskosten, da Sie einen virtuellen Server sofort erstellen können, indem Sie die Virtualisierungssoftware auf dem Host-Betriebssystem installieren. Der virtuelle Server interagiert jedoch über das Host-Betriebssystem mit der Hardware, sodass der Overhead groß ist. Dies hat den Nachteil, dass die Verarbeitungsgeschwindigkeit verlangsamt wird.
Linux container (LXC) Normalerweise verwenden in einem auf einem physischen Server installierten Host-Betriebssystem mehrere Anwendungen, die auf einem Betriebssystem ausgeführt werden, dieselben Systemressourcen. Zu diesem Zeitpunkt teilen sich mehrere Betriebsanwendungen ein Verzeichnis zum Speichern von Daten und kommunizieren mit derselben auf dem Server festgelegten IP-Adresse. Wenn die von mehreren Anwendungen verwendeten Middleware- und Bibliotheksversionen unterschiedlich sind, muss daher darauf geachtet werden, dass die Anwendungen des anderen nicht beeinträchtigt werden [3]. Durch die Virtualisierung des Servers ist es möglich, das oben genannte Problem vollständig zu lösen, indem das gesamte Betriebssystem getrennt und eine Anwendung in jedem virtuellen Betriebssystem implementiert wird. Wenn Sie dies jedoch tun, ist die Auslastungsrate des physischen Servers sehr hoch. Es wird schlecht sein. Aus diesem Grund hat Hypervisor hier eine hochwertige, leichtgewichtige Virtualisierungstechnologie entwickelt.
LXC (Englisch: Linux Containers) [4] ist ein mehrfach isoliertes Linux-System auf einem Steuerungshost, auf dem ein Linux-Kernel ausgeführt wird. Virtualisierungssoftware auf Betriebssystemebene, die ausgeführt wird (Container).
Der Linux-Kernel bietet eine Funktion namens cgroups, mit der Sie Ressourcen (CPU, Speicher, Block-E / A, Netzwerk usw.) begrenzen und priorisieren können, für die Sie virtuelle Maschinen verwenden müssen. Abwesend. Sie können auch die Namespace-Isolationsfunktion verwenden, um die Betriebssystemumgebung aus Sicht der Anwendung vollständig zu isolieren und Prozessbäume, Netzwerke, Benutzerkennungen und bereitgestellte Dateisysteme zu virtualisieren. Kann umgewandelt werden in.
LXC kombiniert Kernel-Gruppen mit Unterstützung für isolierte Namespaces, um eine isolierte Umgebung für Anwendungen bereitzustellen. cgroup cgroups (Kontrollgruppen) [5] begrenzt und isoliert die Verwendung von Prozessgruppenressourcen (CPU, Speicher, Festplatten-E / A usw.) Linux-Kernel-Funktionen. Rohit Seth begann seine Entwicklung im September 2006 unter dem Namen "Prozesscontainer", wurde 2007 in cgroups umbenannt und im Januar 2008 in den Linux-Kernel 2.6.24 integriert. Seitdem wurden viele Funktionen und Controller hinzugefügt.
Die Erklärung von Linux man [6] lautet wie folgt.
Control groups, usually referred to as cgroups, are a Linux kernel feature which allow processes to be organized into hierarchical groups whose usage of various types of resources can then be limited and monitored. The kernel's cgroup interface is provided through a pseudo-filesystem called cgroupfs. Grouping is implemented in the core cgroup kernel code, while resource tracking and limits are implemented in a set of per-resource-type subsystems (memory, CPU, and so on).
Subsysteme sollten als Ressourcenmodul des Kernels verstanden werden. Die von cgroup gesteuerten Subsysteme sind wie folgt.
cpu (since Linux 2.6.24; CONFIG_CGROUP_SCHED)
Cgroups can be guaranteed a minimum number of "CPU shares"
when a system is busy. This does not limit a cgroup's CPU
usage if the CPUs are not busy. For further information, see
Documentation/scheduler/sched-design-CFS.txt.
In Linux 3.2, this controller was extended to provide CPU
"bandwidth" control. If the kernel is configured with CON‐
FIG_CFS_BANDWIDTH, then within each scheduling period (defined
via a file in the cgroup directory), it is possible to define
an upper limit on the CPU time allocated to the processes in a
cgroup. This upper limit applies even if there is no other
competition for the CPU. Further information can be found in
the kernel source file Documentation/scheduler/sched-bwc.txt.
cpuacct (since Linux 2.6.24; CONFIG_CGROUP_CPUACCT)
This provides accounting for CPU usage by groups of processes.
Further information can be found in the kernel source file
Documentation/cgroup-v1/cpuacct.txt.
cpuset (since Linux 2.6.24; CONFIG_CPUSETS)
This cgroup can be used to bind the processes in a cgroup to a
specified set of CPUs and NUMA nodes.
Further information can be found in the kernel source file
Documentation/cgroup-v1/cpusets.txt.
memory (since Linux 2.6.25; CONFIG_MEMCG)
The memory controller supports reporting and limiting of
process memory, kernel memory, and swap used by cgroups.
Further information can be found in the kernel source file
Documentation/cgroup-v1/memory.txt.
devices (since Linux 2.6.26; CONFIG_CGROUP_DEVICE)
This supports controlling which processes may create (mknod)
devices as well as open them for reading or writing. The
policies may be specified as allow-lists and deny-lists.
Hierarchy is enforced, so new rules must not violate existing
rules for the target or ancestor cgroups.
Further information can be found in the kernel source file
Documentation/cgroup-v1/devices.txt.
freezer (since Linux 2.6.28; CONFIG_CGROUP_FREEZER)
The freezer cgroup can suspend and restore (resume) all pro‐
cesses in a cgroup. Freezing a cgroup /A also causes its
children, for example, processes in /A/B, to be frozen.
Further information can be found in the kernel source file
Documentation/cgroup-v1/freezer-subsystem.txt.
net_cls (since Linux 2.6.29; CONFIG_CGROUP_NET_CLASSID)
This places a classid, specified for the cgroup, on network
packets created by a cgroup. These classids can then be used
in firewall rules, as well as used to shape traffic using
tc(8). This applies only to packets leaving the cgroup, not
to traffic arriving at the cgroup.
Further information can be found in the kernel source file
Documentation/cgroup-v1/net_cls.txt.
blkio (since Linux 2.6.33; CONFIG_BLK_CGROUP)
The blkio cgroup controls and limits access to specified block
devices by applying IO control in the form of throttling and
upper limits against leaf nodes and intermediate nodes in the
storage hierarchy.
Two policies are available. The first is a proportional-
weight time-based division of disk implemented with CFQ. This
is in effect for leaf nodes using CFQ. The second is a throt‐
tling policy which specifies upper I/O rate limits on a
device.
Further information can be found in the kernel source file
Documentation/cgroup-v1/blkio-controller.txt.
perf_event (since Linux 2.6.39; CONFIG_CGROUP_PERF)
This controller allows perf monitoring of the set of processes
grouped in a cgroup.
Further information can be found in the kernel source file
tools/perf/Documentation/perf-record.txt.
net_prio (since Linux 3.3; CONFIG_CGROUP_NET_PRIO)
This allows priorities to be specified, per network interface,
for cgroups.
Further information can be found in the kernel source file
Documentation/cgroup-v1/net_prio.txt.
hugetlb (since Linux 3.5; CONFIG_CGROUP_HUGETLB)
This supports limiting the use of huge pages by cgroups.
Further information can be found in the kernel source file
Documentation/cgroup-v1/hugetlb.txt.
pids (since Linux 4.3; CONFIG_CGROUP_PIDS)
This controller permits limiting the number of process that
may be created in a cgroup (and its descendants).
Further information can be found in the kernel source file
Documentation/cgroup-v1/pids.txt.
rdma (since Linux 4.11; CONFIG_CGROUP_RDMA)
The RDMA controller permits limiting the use of RDMA/IB-spe‐
cific resources per cgroup.
Further information can be found in the kernel source file
Documentation/cgroup-v1/rdma.txt.
Beispiel: Begrenzen Sie die CPU-Auslastung
Cgroup-Operationen werden über ein Dateisystem namens cgroupfs ausgeführt. Grundsätzlich wird cgroupfs beim Booten von Linux automatisch gemountet.
$ mount | grep cgroup
cgroup on /sys/fs/cgroup/unified type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
Von hier aus können Sie mit cgroup die CPU-Auslastung Ihrer App begrenzen. Alle Operationen werden mit Ubuntu 18.04 durchgeführt.
- Erstellen Sie zunächst ein einfaches Endlosschleifen-c-Programm.
loop_sample_cpu.c
#include <stdio.h>
int main(){
while(1){
}
}
Kompilieren Sie das Programm.
$ gcc -o loop_sample_cpu loop_sample_cpu.c
Ich werde das machen.
$./loop_sample_cpu
Überprüfen Sie die CPU-Auslastungsrate. Die Auslastungsrate von loop_sample_cpu liegt nahe bei 100%.
zhenbin@zhenbin-VirtualBox:~$ top
top - 14:51:45 up 28 min, 1 user, load average: 0.29, 0.08, 0.02
Tasks: 175 total, 2 running, 140 sleeping, 0 stopped, 0 zombie
%Cpu(s): 98.6 us, 1.4 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8345424 total, 6421164 free, 875200 used, 1049060 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 7187568 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10403 zhenbin 20 0 4372 764 700 R 95.0 0.0 0:19.75 loop_sample_cpu
9547 zhenbin 20 0 3020252 278368 108992 S 2.3 3.3 0:09.34 gnome-shell
10342 zhenbin 20 0 870964 38352 28464 S 1.0 0.5 0:00.88 gnome-termi+
9354 zhenbin 20 0 428804 95048 61820 S 0.7 1.1 0:02.25 Xorg
922 root 20 0 757084 82776 45764 S 0.3 1.0 0:00.50 dockerd
1 root 20 0 159764 8972 6692 S 0.0 0.1 0:01.06 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0+
7 root 20 0 0 0 0 I 0.0 0.0 0:00.15 kworker/u2:+
8 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
9 root 20 0 0 0 0 S 0.0 0.0 0:00.13 ksoftirqd/0
10 root 20 0 0 0 0 I 0.0 0.0 0:00.16 rcu_sched
11 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
12 root -51 0 0 0 0 S 0.0 0.0 0:00.00 idle_inject+
13 root 20 0 0 0 0 I 0.0 0.0 0:00.11 kworker/0:1+
- Fügen Sie cgroup ein CPU-Limit hinzu Erstellen Sie einen Ordner unter / sys / fs / cgroup / cpu, cpuacct.
$ cd /sys/fs/cgroup/cpu,cpuacct
$ mkdir loop_sample_cpu
$ cd loop_sample_cpu
Fügen Sie die PID von loop_sample_cpu zu cgroup hinzu. Hier ist nur der Root-Benutzer fertig.
$ sudo su
$ echo 10403 > cgroup.procs
Fügen Sie ein CPU-Limit hinzu. Es gibt einige Arten von Ressourcenbeschränkungen im Ordner loop_sample_cpu, aber dieses Mal arbeiten wir an diesen beiden. Die Bedeutung anderer Elemente finden Sie in [7].
-
cpu.cfs_period_us Gibt das Intervall in Mikrosekunden (µs, hier jedoch als "us" angegeben) an, um den Zugriff auf CPU-Ressourcen nach cgroup neu zuzuweisen. Wenn die Aufgaben in der cgroup für 0,2 Sekunden pro Sekunde Zugriff auf eine einzelne CPU benötigen, setzen Sie cpu.cfs_quota_us auf 200000 und cpu.cfs_period_us auf 1000000. Die Obergrenze für den Parameter cpu.cfs_quota_us beträgt 1 Sekunde und die Untergrenze 1000 Mikrosekunden.
-
cpu.cfs_quota_us Gibt die Gesamtzeit in Mikrosekunden (µs, hier jedoch als "us" angegeben) an, die alle Aufgaben in einer cgroup über einen bestimmten Zeitraum ausgeführt werden (definiert in cpu.cfs_period_us). Wenn alle Aufgaben in der cgroup die durch das Kontingent angegebene Zeit verbrauchen, wird die Aufgabe für die in diesem Zeitraum angegebene verbleibende Zeit gedrosselt und darf erst im nächsten Zeitraum ausgeführt werden. Setzen Sie cpu.cfs_quota_us auf 200000 und cpu.cfs_period_us auf 1000000, wenn die Aufgaben in der cgroup 0,2 Sekunden pro Sekunde Zugriff auf eine einzelne CPU benötigen. Beachten Sie, dass die Kontingent- und Periodenparameter auf CPU-Basis arbeiten. Setzen Sie beispielsweise cpu.cfs_quota_us auf 200000 und cpu.cfs_period_us auf 100000, damit der Prozess die beiden CPUs vollständig nutzen kann. Wenn Sie den Wert von cpu.cfs_quota_us auf -1 setzen, bedeutet dies, dass die cgroup das CPU-Zeitlimit nicht einhält. Dies ist auch der Standardwert für alle cgroups (außer root cgroup).
Begrenzen Sie die CPU auf 20% pro Kern. (Alle 10 ms sind nur 10 ms CPU-Zeit verfügbar.)
$ echo 10000 > cpu.cfs_quota_us
$ echo 50000 > cpu.cfs_period_us
Die CPU-Auslastung von loop_sample_cpu ist auf 20% begrenzt.
zhenbin@zhenbin-VirtualBox:~$ top
top - 15:06:05 up 42 min, 1 user, load average: 0.40, 0.72, 0.57
Tasks: 181 total, 2 running, 146 sleeping, 0 stopped, 0 zombie
%Cpu(s): 23.8 us, 1.0 sy, 0.0 ni, 75.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8345424 total, 6366748 free, 912068 used, 1066608 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 7134248 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10403 zhenbin 20 0 4372 764 700 R 19.9 0.0 12:16.90 loop_sample_cpu
9547 zhenbin 20 0 3032212 287524 111556 S 1.7 3.4 0:18.14 gnome-shell
9354 zhenbin 20 0 458868 125556 77832 S 1.3 1.5 0:06.06 Xorg
10342 zhenbin 20 0 873156 40500 28464 S 1.0 0.5 0:03.34 gnome-termi+
9998 zhenbin 20 0 1082256 120516 36164 S 0.3 1.4 0:01.92 gnome-softw+
1 root 20 0 159764 8972 6692 S 0.0 0.1 0:01.12 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0+
7 root 20 0 0 0 0 I 0.0 0.0 0:00.24 kworker/u2:+
8 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
9 root 20 0 0 0 0 S 0.0 0.0 0:00.16 ksoftirqd/0
10 root 20 0 0 0 0 I 0.0 0.0 0:00.22 rcu_sched
11 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
12 root -51 0 0 0 0 S 0.0 0.0 0:00.00 idle_inject+
14 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/0
Namespace Namespace [8] ist eine globale Systemressource, die mit einer Abstraktionsschicht im Namespace abgedeckt ist. Es ist ein Mechanismus, der den Prozess so erscheinen lässt, als hätten sie ihre eigenen separaten globalen Ressourcen. Änderungen an globalen Ressourcen sind für andere Prozesse sichtbar, die Mitglieder des Namespace sind, jedoch nicht für andere Prozesse. Eine Verwendung von Namespaces besteht darin, Container zu implementieren.
Beispiel: Netzwerk-Namespace
Mit dem Netzwerk-Namespace können zwei virtuelle Netzwerke auf einer Netzwerkkarte erstellt werden.
- Erstellen Sie einen Netzwerk-Namespace
zhenbin@zhenbin-VirtualBox:~$ sudo unshare --uts --net /bin/bash
root@zhenbin-VirtualBox:~# hostname container001
root@zhenbin-VirtualBox:~# exec bash
root@container001:~# ip link set lo up
root@container001:~# ifconfig
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
root@container001:~# echo $$ # $$Ist die PID des Befehls selbst(Prozess ID)Zu setzende Variable
1909
- Erstellen Sie eine virtuelle Netzwerkschnittstellenverbindung. In [9] finden Sie eine Erläuterung der virtuellen Netzwerkschnittstelle. Starten Sie eine neue Shell. Erstellen Sie ein Linkpaar.
$ sudo ip link add veth0 type veth peer name veth1
Weisen Sie dem soeben erstellten Netzwerk-Namespace veth1 zu.
$ sudo ip link set veth1 netns 1909
Richten Sie veth0 ein
$ sudo ip address add dev veth0 192.168.100.1/24
$ sudo ip link set veth0 up
Richten Sie veth1 mit der Shell von container001 ein.
$ sudo ip address add dev veth1 192.168.100.2/24
$ sudo ip link set veth1 up
Sie können jetzt zwischen dem Host und container001 kommunizieren.
zhenbin@zhenbin-VirtualBox:~$ ping 192.168.100.2
PING 192.168.100.2 (192.168.100.2) 56(84) bytes of data.
64 bytes from 192.168.100.2: icmp_seq=1 ttl=64 time=0.019 ms
64 bytes from 192.168.100.2: icmp_seq=2 ttl=64 time=0.037 ms
^C
--- 192.168.100.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.019/0.028/0.037/0.009 ms
Einführung in Docker, um LXC voll auszunutzen
Frühere Versionen von Docker verwendeten LXC als Treiber für die Containerausführung, wurden jedoch in Docker v0.9 zu einer Option und werden in Docker v1.10 nicht mehr unterstützt. Nachfolgendes Docker verwendet eine von Docker entwickelte Bibliothek namens libcontainer, um cgroup und Namespace zu steuern.
Hier ist ein wichtiger Punkt. Docker ist keine Virtualisierungstechnologie! Wenn überhaupt, existiert es als Management-Tool für Gruppen und Namespaces. Es ist ein Tool, das Entwicklern und Server-Betreibern die Verwendung der vom Linux-Kernel bereitgestellten Virtualisierungsfunktionen erleichtert. Darüber hinaus hat das Vorhandensein von Dockerfile und Docker Hub die Kapselung und Portabilität von Anwendungen verbessert!
Jetzt möchte ich die Merkmale der Docker-Ressourcenisolation und der Kontrolle über die allgemeinen Docker-Befehle hervorheben.
Beispiel: Begrenzen Sie die CPU-Auslastung des Containers mit Docker.
- Erstellen Sie einen Docker-Container, der Ihre Anwendung enthält.
Erstellen Sie ein Ubuntu-basiertes Docker-Image, das das zuvor erstellte Programm loop_sample_cpu.c enthält.
FROM ubuntu
RUN apt update && apt install -y gcc
WORKDIR /src
COPY loop_sample_cpu.c .
RUN gcc -o loop_sample_cpu loop_sample_cpu.c
CMD ./loop_sample_cpu
Erstellen Sie das Docker-Image.
docker build -t ubuntu_cpu .
- Starten Sie einen Container ohne CPU-Einschränkungen.
docker run -d ubuntu_cpu
Schauen wir uns die CPU-Auslastung an.
zhenbin@zhenbin-VirtualBox:~/workspace/presentation$ top
top - 17:06:45 up 43 min, 1 user, load average: 0.89, 0.56, 0.37
Tasks: 178 total, 2 running, 142 sleeping, 0 stopped, 0 zombie
%Cpu(s): 99.0 us, 1.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8345424 total, 6156972 free, 894060 used, 1294392 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 7184360 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8853 root 20 0 4372 804 740 R 94.0 0.0 0:15.97 loop_sample_cpu
1253 zhenbin 20 0 3020528 278012 108704 S 2.0 3.3 0:31.41 gnome-shell
1056 zhenbin 20 0 424560 90824 55364 S 1.3 1.1 0:09.92 Xorg
1927 zhenbin 20 0 877384 44356 28584 S 1.3 0.5 0:08.01 gnome-terminal-
1 root 20 0 225292 9040 6724 S 0.0 0.1 0:01.62 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H-kb
8 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
9 root 20 0 0 0 0 S 0.0 0.0 0:00.29 ksoftirqd/0
10 root 20 0 0 0 0 I 0.0 0.0 0:00.31 rcu_sched
11 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
12 root -51 0 0 0 0 S 0.0 0.0 0:00.00 idle_inject/0
14 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/0
15 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs
16 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 netns
- Starten Sie einen Container, der die CPU begrenzt.
docker run -d --cpu-period=50000 --cpu-quota=10000 ubuntu_cpu
Lassen Sie uns die CPU-Auslastung überprüfen.
zhenbin@zhenbin-VirtualBox:~$ top
top - 17:08:50 up 45 min, 1 user, load average: 0.77, 0.68, 0.45
Tasks: 178 total, 2 running, 141 sleeping, 0 stopped, 0 zombie
%Cpu(s): 25.8 us, 2.3 sy, 0.0 ni, 71.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8345424 total, 6160808 free, 892384 used, 1292232 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 7188556 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9066 root 20 0 4372 800 740 R 19.9 0.0 0:04.36 loop_sample+
1253 zhenbin 20 0 3017968 275536 106144 S 3.0 3.3 0:32.83 gnome-shell
1056 zhenbin 20 0 422000 88336 52876 S 2.7 1.1 0:10.59 Xorg
1927 zhenbin 20 0 877380 44468 28584 S 2.0 0.5 0:08.54 gnome-termi+
580 root 20 0 776548 46696 24888 S 0.3 0.6 0:02.71 containerd
1202 zhenbin 20 0 193504 2912 2536 S 0.3 0.0 0:03.92 VBoxClient
1461 zhenbin 20 0 441756 22836 17820 S 0.3 0.3 0:00.09 gsd-wacom
1475 zhenbin 20 0 670048 23676 18316 S 0.3 0.3 0:00.29 gsd-color
1 root 20 0 225292 9040 6724 S 0.0 0.1 0:01.65 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0+
8 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
9 root 20 0 0 0 0 S 0.0 0.0 0:00.30 ksoftirqd/0
10 root 20 0 0 0 0 I 0.0 0.0 0:00.32 rcu_sched
11 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
Als ich / sys / fs / cgroup / cpu, cpuacct überprüfte, stellte ich fest, dass ein Ordner namens Docker erstellt wurde.
zhenbin@zhenbin-VirtualBox:/sys/fs/cgroup/cpu,cpuacct$ ls
cgroup.clone_children cpuacct.usage cpuacct.usage_percpu_user cpu.cfs_quota_us notify_on_release user.slice
cgroup.procs cpuacct.usage_all cpuacct.usage_sys cpu.shares release_agent
cgroup.sane_behavior cpuacct.usage_percpu cpuacct.usage_user cpu.stat system.slice
cpuacct.stat cpuacct.usage_percpu_sys cpu.cfs_period_us docker tasks
Jetzt wissen wir, dass die Anwendung die Laufzeitressourcen durch die Verwendung von cgroup und Namespace im Docker begrenzt.
Funktionen von Docker
―― Wie oben erläutert, ist Docker nur ein Verwaltungstool, dh ein Prozess des Betriebssystems. Daher startet es schneller als die virtuelle Maschine.
- Gute Portabilität. Da die Docker-Datei die Umgebung (Bibliothek, Parameter) beschreibt, die die Anwendung ausführt, kann dieselbe Anwendung überall reproduziert werden. --Um einen Prozess in einem Container auszuführen. Grundsätzlich wird nicht empfohlen, dass der Docker-Container mehrere Prozesse ausführt. Das Ausführen mehrerer Prozesse macht es schließlich unmöglich, Ressourcen zu trennen. Dies entspricht dem Ausführen einer Anwendung auf dem Host in derselben Umgebung. --Kernel oder Hardware kann nicht geändert werden. Auf dem Host ausgeführte Container teilen sich den Kernel des Hosts, sodass alle Änderungen am Kernelmodul alle Container betreffen. Es gibt auch viele Einschränkungen bei der Hardware. Zum Beispiel sind Operationen wie USB ziemlich problematisch.
- Da das Dateisystem im Docker-Container im Speicher gespeichert ist, werden beim Löschen des Containers auch die Daten gelöscht. Wenn Sie also die Daten dauerhaft machen möchten, müssen Sie das Host-Dateisystem auf dem Container bereitstellen. Es wird jedoch allgemein empfohlen, dass die auf dem Docker ausgeführte Anwendung zustandslos ist.
Referenz-URL
[1] https://blogs.itmedia.co.jp/itsolutionjuku/2017/10/1it_1.html [2] https://ja.wikipedia.org/wiki/%E3%83%8F%E3%82%A4%E3%83%91%E3%83%BC%E3%83%90%E3%82%A4%E3%82%B6 [3] https://codezine.jp/article/detail/11336 [4] https://ja.wikipedia.org/wiki/LXC [5] https://ja.wikipedia.org/wiki/Cgroups [6] http://man7.org/linux/man-pages/man7/cgroups.7.html [7] https://access.redhat.com/documentation/ja-jp/red_hat_enterprise_linux/6/html/resource_management_guide/sec-cpu [8] https://linuxjm.osdn.jp/html/LDP_man-pages/man7/namespaces.7.html [9] https://gihyo.jp/admin/serial/01/linux_containers/0006
Recommended Posts