[PYTHON] Tensorflow scheint es, dass sogar der Eigenwert der Matrix automatisch unterschieden werden kann
Zusammenfassung
Selbst wenn in Tensorflow die Diagonalisierung (Eigenwert) der Matrix in der Mitte gefunden werden kann, wenn eine automatische Differenzierung nach der Gradientenmethode durchgeführt wird, scheint sie durch die automatische Differenzierungs- und Gradientenmethode problemlos minimiert werden zu können.
Ich habe auch eine Methode zum manuellen "apply_gradient" mit "GradientTape" und eine Methode zum "Minimieren" der Verlustfunktion durch automatische Differenzierung hinzugefügt.
Version
- Tensorflow 2.1.0
- Python 3.7.3 (Anaconda)
- Windows 10
Der Punkt
Wenn Sie eine geeignete 3-mal-3-Matrix $ A $ vorbereiten und ihren Eigenwert $ \ lambda $ berechnen, wird die Differenzierung jeder Komponente der Matrix $ A $ gegen den kleinsten Eigenwert $ \ lambda_0 $ $ d \ lambda_0 / Wenn Sie dA $ berechnen möchten (es handelt sich um eine 3-mal-3-Matrix, da dies für jede Komponente gilt).
Sie können $ d \ lambda_0 / dA $ mit dem folgenden Code berechnen. Da es sich im Eager-Modus befindet, verwenden Sie "GradientTape ()", um das Berechnungsdiagramm für die Differentialberechnung zu erfassen.
import tensorflow as tf
A = tf.random.uniform(shape=(3, 3))
with tf.GradientTape() as g:
g.watch(A)
val, vec = tf.linalg.eigh(A)
val0 = val[0]
grad0 = g.gradient(val0, A)
print(A)
print(val)
print(grad0)
A
tf.Tensor(
[[0.6102723 0.17637432 0.38962376]
[0.3735156 0.6306771 0.19141042]
[0.34370267 0.7677151 0.4024818 ]], shape=(3, 3), dtype=float32)
val
tf.Tensor([-0.25994763 0.34044334 1.5629349 ], shape=(3,), dtype=float32)
grad0
tf.Tensor(
[[ 5.3867564e-04 0.0000000e+00 0.0000000e+00]
[ 3.0038984e-02 4.1877732e-01 0.0000000e+00]
[-3.5372321e-02 -9.8626012e-01 5.8068389e-01]], shape=(3, 3), dtype=float32)
Schließlich wird spekuliert, dass "acht" nur die untere Hälfte verwendet, da nur die untere Hälfte ungleich Null ist.
Tatsächlich wird die Slice-Operation als "val0 = val [0]" ausgeführt, was der Hauptpunkt ist. Mit anderen Worten, es geht nicht nur darum, den eindeutigen Wert zu finden. G.gradient (val, A) ohne einen einzigen Wert auszuschneiden funktioniert problemlos, aber ich habe der einfachen Erklärung mit mathematischen Formeln Priorität eingeräumt.
Auch "val0 = val [0]", aber es wird in der "GradientTape ()" - Umgebung durchgeführt. Wenn in dieser Umgebung nicht alle Vorgänge ausgeführt werden, mit denen Sie die Differentiale auf diese Weise verbinden möchten, gibt g.gradient () None zurück.
Anwendung
Aufgrund der automatischen Differenzierung ist es möglich, Operationen davor und danach einzufügen. Ich werde es von jetzt an versuchen.
Status
Bereiten Sie 6 Werte vor, ordnen Sie sie in einer symmetrischen Matrix an und berechnen Sie die Eigenwerte. Entweder gilt dies für eine bestimmte Bedingung, oder der Fehler wird als differenzierte Fehlerfunktion berechnet.
- Berechnung vor Eigenwert: Matrixstruktur
- Berechnung nach Eigenwert: Summe der Fehler zwischen Eigenwert und Zielwert
Als nächstes aktualisieren wir den ursprünglichen Wert mit der Gradientenmethode, bei der es sich anscheinend um eine maschinelle Lernbibliothek namens Tensorflow handelt.
$ r $ enthält 6 Komponenten der symmetrischen 3x3-Matrix, und $ t = (t_0, t_1, t_2) $ sind die gewünschten Eigenwerte.
r = \left(r_0, r_1, \cdots, r_5\right)
Sortieren Sie dies
A_h=\left(\begin{array}{ccc}
\frac{1}{2} r_0 & 0 & 0 \\
r_3 & \frac{1}{2} r_1 & 0 \\
r_5 & r_4 & \frac{1}{2} r_2
\end{array}
\right)
A = A_h + A_h^T
Konstruieren Sie die Matrix $ A $ as und ermitteln Sie den eindeutigen Wert. Angenommen, $ \ lambda = (\ lambda_0, \ lambda_1, \ lambda_2) $ ist ein Array von drei eindeutigen Werten von $ A $
L = \sum_{i=0}^2\left(t_i - \lambda_i\right)^2
Ist die Verlustfunktion. $ R $ trainieren
\frac{\partial L}{\partial r_n} = \sum_{i,j,k}\frac{\partial A_{ij}}{\partial r_n}\frac{\partial \lambda_k}{\partial A_{ij}}\frac{\partial L}{\partial \lambda_k}
Ist eine notwendige Berechnung. $ \ Frac {\ partielle \ lambda_k} {\ partielle A_ {ij}} $ in der Mitte ist die Differenzierung der Eigenwerte durch die Komponenten der Matrix.
Analysierend kann es berechnet werden, indem die Lösung $ \ lambda $ von $ \ det (A- \ lambda I) = 0 $ gefunden wird, aber ehrlich gesagt, wenn es 3 Dimensionen überschreitet, ist es nicht verwaltbar, es sei denn, es ist eine sehr spärliche Matrix. .. Daher verlasse ich mich auf den Tensorfluss, der numerische Berechnungen durchführen kann.
Manueller Differentialanruf
Zuallererst ist es ärgerlich, aber wie man den Prozess verfolgt.
Vorbereitung
r = tf.Variable(initial_value=tf.random.uniform(shape=[6]))
t = tf.constant([1.0, 1.0, 1.0])
"r" enthält 6 Komponenten der symmetrischen 3x3-Matrix, und "t" sind die gewünschten Eigenwerte. Hier wird "r" als Anfangswert eine einheitliche Zufallszahl gegeben. Außerdem ist "t" alles 1.
Berechnung zur automatischen Differenzierung
with tf.GradientTape() as g:
g.watch(r)
A = 0.5*tf.linalg.diag(r[0:3])
A = A + tf.pad(tf.linalg.diag(r[3:5]), [[0, 1], [1, 0]], "CONSTANT")
A = A + tf.sparse.to_dense(tf.sparse.SparseTensor(indices=[[0, 2]], values=[r[5]], dense_shape=(3, 3)))
A = A + tf.transpose(A)
eigval, eigvec = tf.linalg.eigh(A)
d = tf.reduce_sum((eigval - t)**2)
Da die Verarbeitung von hier aus das Ziel der automatischen Differenzierung ist, erfolgt sie in "GradientTape".
Es gibt zwei Möglichkeiten, eine bestimmte Komponente von "A" durch "r" zu ersetzen. Eine besteht darin, "diag" zur Einführung zu verwenden und die andere darin, "SparseTensor" zu verwenden.
Ich habe tf.linalg.diag als Funktion verwendet, um drei diagonale Komponenten und zwei Komponenten daneben anzuordnen.
Ich verwende jedoch "pad", um es an einer Stelle von der diagonalen Komponente anzuordnen, aber das Dokument führt die Option ein, es an einer Stelle anzuordnen, die mit der Option "k" von der Diagonale versetzt ist. Und wenn du es benutzt
A = A + tf.linalg.diag(r[3:5], k=1)
Ich kann schreiben, aber irgendwie hat die Option "k" nicht funktioniert. Also benutze ich absichtlich "Pad".
Als Methode, um nur einen von $ r_5 $ an der Ecke der Matrix festzulegen, hat Tensor keine Indexspezifikation wie numpy zugewiesen, daher ist dies problematisch, sondern wird durch Hinzufügen über eine dünn besetzte Matrix festgelegt. Hat.
Nach der Konstruktion von "A" ist es normal, die Diagonalisierung "acht" und die Verlustfunktion zu berechnen. Hier ist die Verlustfunktion $ L $ d. Es tut mir leid, dass es kompliziert ist.
Berechnung der Differenzierung
grad_dr = g.gradient(d, r)
Noch einmal, d ist die Verlustfunktion $ L $.
Ein Tensol der Länge 6 wird "grad_dr" zugewiesen. Dies hat den Zweck dieses Artikels erreicht.
Wert aktualisieren
Verwenden Sie einen geeigneten Optimierer.
opt = tf.keras.optimizers.Adam()
opt.apply_gradients([(grad_dr, r), ])
Weil Sie hier Differenzierung verwenden können
opt.minimize(d, var_list=[r])
Dann
TypeError: 'tensorflow.python.framework.ops.EagerTensor' object is not callable
Ich bekomme den Fehler. Dies liegt daran, dass das erste Argument "d" eine Funktion ohne Argument sein muss, die eine Verlustfunktion zurückgibt, nicht "Tensor". Diese Methode wird später beschrieben.
Ausgabebeispiel
Zum Beispiel das anfängliche "r"
<tf.Variable 'Variable:0' shape=(6,) dtype=float32, numpy=
array([0.12108588, 0.8856114 , 0.00449729, 0.22199583, 0.8411281 ,
0.54751956], dtype=float32)>
Zu dieser Zeit ist "A"
tf.Tensor(
[[0.12108588 0.22199583 0.54751956]
[0.22199583 0.8856114 0.8411281 ]
[0.54751956 0.8411281 0.00449729]], shape=(3, 3), dtype=float32)
Es wird sein. Dann das Differential $ \ frac {dL} {dr} $ der Verlustfunktion
tf.Tensor([-1.757829 -0.22877683 -1.991005 0.88798404 3.3645139 2.1900787 ], shape=(6,), dtype=float32)
Wurde berechnet. Wenn Sie dies wie "opt.apply_gradients ([(grad_dr, r),])" anwenden, ist der Wert von "r"
<tf.Variable 'Variable:0' shape=(6,) dtype=float32, numpy=
array([0.12208588, 0.8866114 , 0.00549729, 0.22099583, 0.8401281 ,
0.5465196 ], dtype=float32)>
Sie können sehen, dass es sich geringfügig vom ersten Wert "[0,12108588, 0,8856114, 0,00449729, 0,22199583, 0,8411281, 0,54751956]" unterscheidet.
Zur Konvergenz
Warum willst du es wiederholen? Wenn die Optimierung erfolgreich ist, erhalten Sie eine symmetrische Matrix mit allen 1 Eigenwerten, wie durch t festgelegt.
while d > 1e-8:
with tf.GradientTape() as g:
g.watch(r)
A = 0.5*tf.linalg.diag(r[0:3])
A = A + tf.pad(tf.linalg.diag(r[3:5]), [[0, 1], [1, 0]], "CONSTANT")
A = A + tf.sparse.to_dense(tf.sparse.SparseTensor(indices=[[0, 2]], values=[r[5]], dense_shape=(3, 3)))
A = A + tf.transpose(A)
eigval, eigvec = tf.linalg.eigh(A)
d = tf.reduce_sum((eigval - t)**2)
grad_dr = g.gradient(d, r)
opt.apply_gradients([(grad_dr, r), ])
print("---------------")
print(r)
print(eigval)
print(d)
d ist der quadratische Fehler und wiederholt sich in der while-Schleife, bis er einen bestimmten Wert unterschreitet.
Wenn du das machst
---------------
<tf.Variable 'Variable:0' shape=(6,) dtype=float32, numpy=
array([0.10630785, 0.18287621, 0.14753745, 0.16277793, 0.7271476 ,
0.08771187], dtype=float32)>
tf.Tensor([-0.56813365 0.07035071 0.9315046 ], shape=(3,), dtype=float32)
tf.Tensor(3.3279824, shape=(), dtype=float32)
---------------
<tf.Variable 'Variable:0' shape=(6,) dtype=float32, numpy=
array([0.10730778, 0.18387613, 0.14853737, 0.16177836, 0.72614765,
0.0867127 ], dtype=float32)>
tf.Tensor([-0.5661403 0.07189684 0.9309651 ], shape=(3,), dtype=float32)
tf.Tensor(3.3189366, shape=(), dtype=float32)
---------------
<tf.Variable 'Variable:0' shape=(6,) dtype=float32, numpy=
array([0.10830763, 0.18487597, 0.1495372 , 0.1607792 , 0.72514784,
0.08571426], dtype=float32)>
tf.Tensor([-0.564147 0.07343995 0.9304282 ], shape=(3,), dtype=float32)
tf.Tensor(3.3099096, shape=(), dtype=float32)
Folgendes wird weggelassen
Sie können sehen, dass sich r und A nach und nach ändern. Wenn es konvergiert,
<tf.Variable 'Variable:0' shape=(6,) dtype=float32, numpy=
array([ 9.9999946e-01, 9.9999988e-01, 9.9999732e-01, 6.9962436e-05,
4.2644251e-07, -1.1688111e-14], dtype=float32)>
tf.Tensor([0.9999294 0.9999973 1.0000702], shape=(3,), dtype=float32)
tf.Tensor(9.917631e-09, shape=(), dtype=float32)
ist geworden. A scheint eine Einheitsmatrix zu sein. Nach mehreren Versuchen war es dasselbe, so dass das Finden einer Matrix mit nur einem Eigenwert auf diese Weise zu einer Einheitsmatrix führt.
Wenn Sie die Anzahl der Schleifen zählen, sind anscheinend Tausende von Schritten erforderlich, z. B. 3066, 2341, 3035.
So erhalten Sie eine automatische Differenzierung und Aktualisierungsverarbeitung
Der Punkt ist, minim () zu verwenden.
Informationen zum Aufbau der symmetrischen Matrix "A" finden Sie oben im Abschnitt "Berechnung zur automatischen Differenzierung".
r = tf.Variable(initial_value=tf.random.uniform(shape=[6]))
t = tf.constant([1.0, 1.0, 1.0])
def calc_eigval(r):
A = 0.5*tf.linalg.diag(r[0:3])
A = A + tf.pad(tf.linalg.diag(r[3:5]), [[0, 1], [1, 0]], "CONSTANT")
A = A + tf.sparse.to_dense(tf.sparse.SparseTensor(indices=[[0, 2]], values=[r[5]], dense_shape=(3, 3)))
A = A + tf.transpose(A)
eigval, eigvec = tf.linalg.eigh(A)
return eigval
def calc_loss(r):
eigval = calc_eigval(r)
d = tf.reduce_sum((eigval - t)**2)
return d
opt = tf.keras.optimizers.Adam()
loss = lambda: calc_loss(r)
while d > 1e-8:
opt.minimize(loss, var_list=[r])
print("---------------")
print(r)
print(calc_eigval(r))
print(calc_loss(r))
calc_eigval ist eine Funktion, die einen eindeutigen Wert zurückgibt, und calc_loss ist eine Funktion, die eine Verlustfunktion berechnet.
loss ist eine Funktion, die die Verlustfunktion basierend auf dem Wert von r zu diesem Zeitpunkt berechnet und den Tensor zurückgibt, wenn die Funktionloss ()ist.
Das erste Argument von "minimieren" erfordert eine Funktion ohne ein solches Argument. Damit
Ich habe einen Fehler erhalten, als ich "d", das von "gradientTape" berechnet wurde, an "minimieren" übergeben habe.
Sie können calc_eigval in calc_loss schreiben, aber ich wollte sehen, wie sich die Eigenwerte während der Schleife geändert haben, also habe ich eine andere Funktion vorbereitet.
"def calc_loss (r)" und "loss = lambda: calc_loss (r)" sind die Punkte für die Verwendung von "minim". Wenn Sie calc_loss von Anfang an ohne Argumente definieren, haben Sie nicht das Gefühl, Sie könnten es einfach an minim übergeben.
Jedenfalls muss ich es jetzt nicht mehr selbst schaffen.
Wenn Sie den obigen Code wie mit der Hauptfunktion ausführen, wird der Konvergenzzustand ausgegeben.
Andere
Als Bonus etwa 4 Muster, die die Konvergenz von Eigenwerten mit zufälligen Anfangswerten begannen. Die Zeilen sind <font color = # 1f77b4> Eigenwert 1 </ font>, Eigenwert 2 </ font> bzw. <font color = # 2ca02c> Eigenwert 3 </ font>. Das rechte Ende ist 1, was das Ziel der Konvergenz ist, und Sie können sehen, dass es richtig funktioniert.
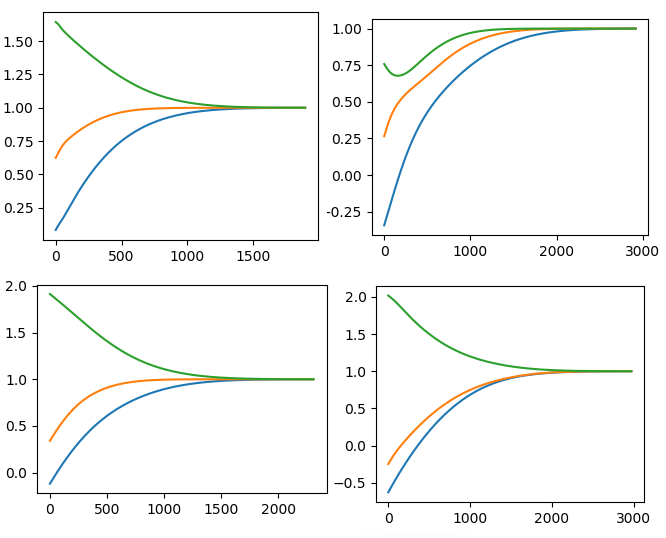
Eine Differenzierung höherer Ordnung ist auch durch Verschachteln von "GradientTape ()" möglich. Es scheint, dass die Abdeckung der automatischen Differenzierung breiter ist als ich erwartet hatte.
Der Grund für den Hauptartikel von "GradientTape" ist, dass ich zunächst nicht wusste, wie man "Minimieren" verwendet, und dachte, ich müsste "apply_gradient" manuell ausführen. Nachdem ich den größten Teil des Artikels geschrieben hatte, wusste ich, wie man es mit "Minimieren" macht.
Recommended Posts