[PYTHON] EDA von Krankenversicherungsprämie und Rückgabeproblem
Überblick
Da es die Möglichkeit gibt, Mitarbeiter zu schulen, die keine Kenntnisse über maschinelles Lernen im Unternehmen haben, haben wir beschlossen, Unterrichtsmaterialien für EDA-, Clustering- und Regressionsprobleme unter Verwendung von US-Krankenversicherungsprämiendaten zu erstellen. Der Datensatz verwendet Kaggles this. Das Gefühl, das ich grob gemacht habe, mag ein wenig schwierig erscheinen, deshalb werde ich es nicht für Unterrichtsmaterialien verwenden Lassen Sie uns eine einfachere separat vorbereiten
- Umsetzungszeitraum: November 2020 --Umwelt: Google Colaboratory
Datensatz
Die Struktur von insurance.csv ist in der folgenden Abbildung dargestellt. Gebühren, die auf Krankenkassenprämien hinweisen, werden anhand dieser Rendite prognostiziert
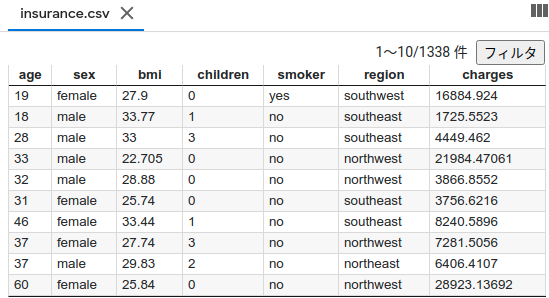
Veröffentlichen Sie die Beschreibung für jede Spalte Columns age: age of primary beneficiary sex: insurance contractor gender, female, male bmi: Body mass index, providing an understanding of body, weights that are relatively high or low relative to height, objective index of body weight (kg / m ^ 2) using the ratio of height to weight, ideally 18.5 to 24.9 children: Number of children covered by health insurance / Number of dependents smoker: Smoking region: the beneficiary's residential area in the US, northeast, southeast, southwest, northwest. charges: Individual medical costs billed by health insurance
EDA(Explanatory Data Analysis) Einige Wörter sind möglicherweise unbekannt Der Prozess der ersten Bestätigung der Struktur des zu analysierenden Datensatzes und der Festlegung einer Strategie für die Analyse (glaube ich) Erfordert Werkzeugtyp, Vertrautheit und Intuition Da die Analysemethode für jede Person unterschiedlich ist, behalten Sie bitte Folgendes nur als Referenz bei.
Öffnen Sie zunächst die Datei und überprüfen Sie den Inhalt und die Daten auf fehlende Elemente.
import numpy as np
import pandas as pd
import os
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('insurance.csv')
#Anzeige des Datensatzes
print(df.tail())
#Auf NaN prüfen
df.isnull().sum()
 Sie können sehen, dass es keine Mängel gibt (zum Glück, weil es ein wenig problematisch ist, wenn es gibt)
Da es kategoriale Daten enthält, digitalisieren Sie diese mit LabelEncoder.
Sie können sehen, dass es keine Mängel gibt (zum Glück, weil es ein wenig problematisch ist, wenn es gibt)
Da es kategoriale Daten enthält, digitalisieren Sie diese mit LabelEncoder.
#Codierung von Kategoriedaten
# sex
le = LabelEncoder()
le.fit(df.sex.drop_duplicates())
df.sex = le.transform(df.sex)
# smoker or not
le.fit(df.smoker.drop_duplicates())
df.smoker = le.transform(df.smoker)
# region
le.fit(df.region.drop_duplicates())
df.region = le.transform(df.region)
#Anzeige des Datensatzes
print(df.tail())
 Ersetzt durch eine Ganzzahl
Schauen Sie sich den Gesamtkorrelationskoeffizienten an und treffen Sie die erklärenden Variablen, die die Gebühren beeinflussen
Ersetzt durch eine Ganzzahl
Schauen Sie sich den Gesamtkorrelationskoeffizienten an und treffen Sie die erklärenden Variablen, die die Gebühren beeinflussen
print(df.corr())
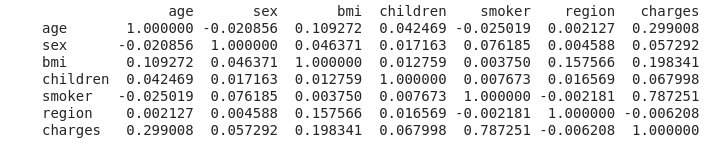 Raucher zeigt eine sehr starke Korrelation bei 0,787251
Als nächstes kommt das Alter von 0,299008 und ich mache mir Sorgen, dass der Korrelationskoeffizient von bmi (= Gewicht / Größe ^ 2), der den Grad der Fettleibigkeit anzeigt, kleiner ist als ich erwartet hatte.
Es ist jedoch eine einmalige Berechnung mit nur ".corr ()", daher bin ich froh, dass ich Python verwendet habe.
Raucher zeigt eine sehr starke Korrelation bei 0,787251
Als nächstes kommt das Alter von 0,299008 und ich mache mir Sorgen, dass der Korrelationskoeffizient von bmi (= Gewicht / Größe ^ 2), der den Grad der Fettleibigkeit anzeigt, kleiner ist als ich erwartet hatte.
Es ist jedoch eine einmalige Berechnung mit nur ".corr ()", daher bin ich froh, dass ich Python verwendet habe.
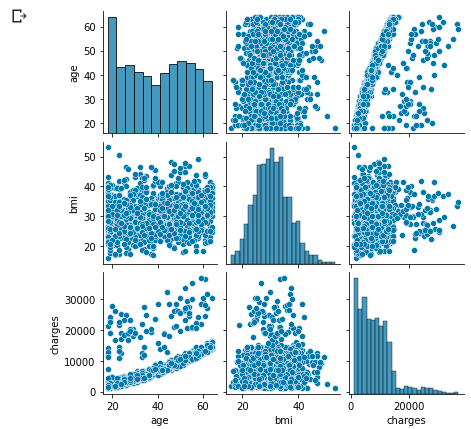
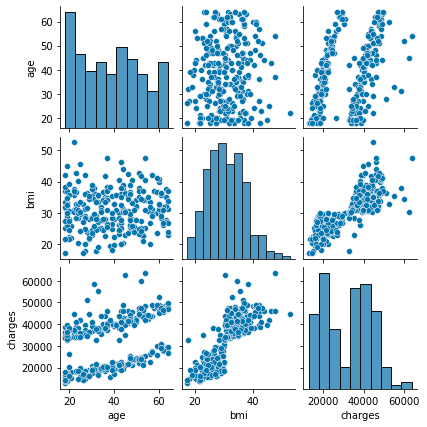
Zeigen Sie die gesamte Distribution an
sns.pairplot(df.loc[:, ['age', 'sex', 'bmi', 'children', 'smoker', 'region', 'charges']], height=2);
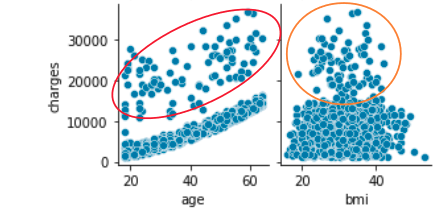
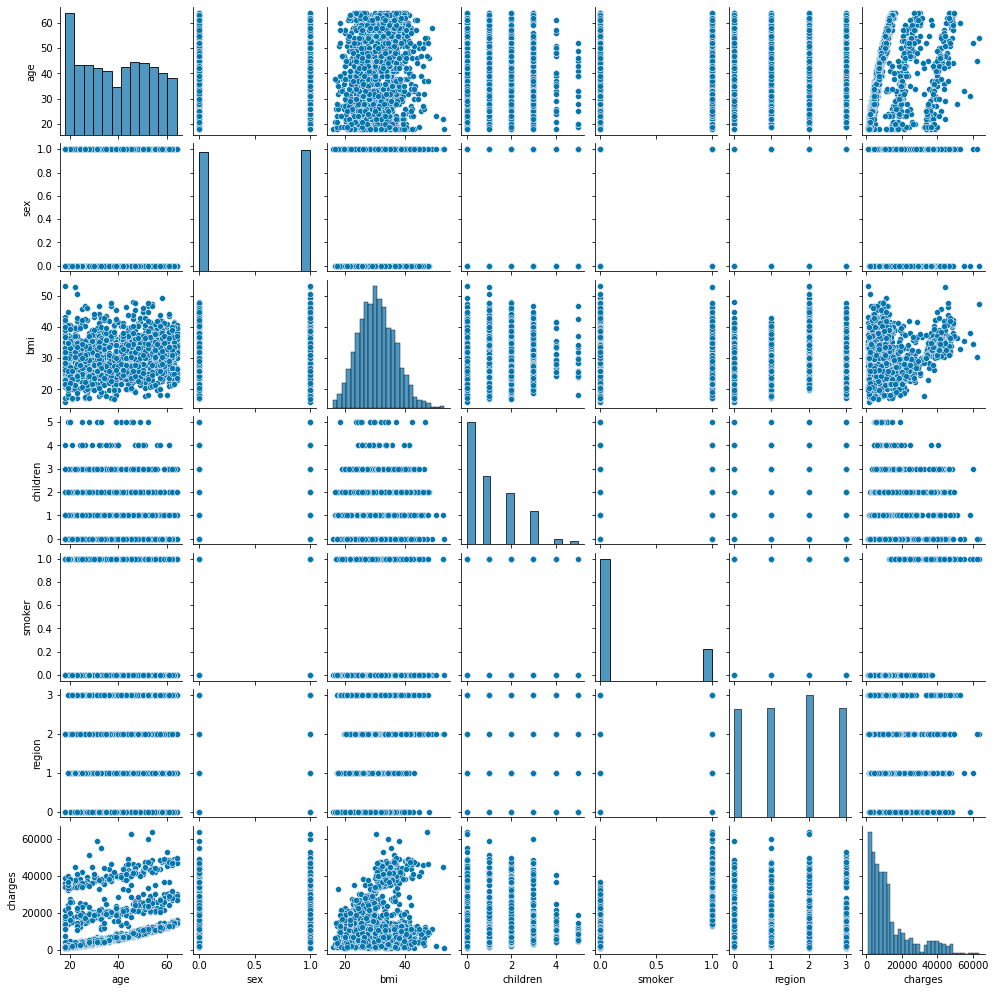 Die charakteristische Verteilung ist unten gezeigt, konzentrieren Sie sich also auf Alter, Bmi, Raucher.
Es scheint, dass es in 3 Gruppen unterteilt werden kann, aber analysieren Sie, warum es in 3 Gruppen unterteilt wurde
Die charakteristische Verteilung ist unten gezeigt, konzentrieren Sie sich also auf Alter, Bmi, Raucher.
Es scheint, dass es in 3 Gruppen unterteilt werden kann, aber analysieren Sie, warum es in 3 Gruppen unterteilt wurde
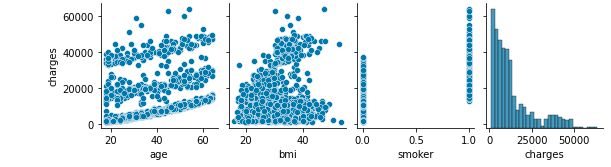 Die Altersgebührenverteilung ist sehr charakteristisch
Lassen Sie uns in den Raucher graben, der stark korreliert war
Die Altersgebührenverteilung ist sehr charakteristisch
Lassen Sie uns in den Raucher graben, der stark korreliert war
# smoker-Werfen wir einen Blick auf die Gebühren
sns.boxplot(x="smoker", y="charges", data=df)
#Bestätigen Sie mit Nummer
df_s0 = df[df['smoker'] == 0] #Nichtraucher
df_s1 = df[df['smoker'] == 1] #Raucher
pd.set_option('display.max_rows', 20)
pd.set_option('display.max_columns', None)
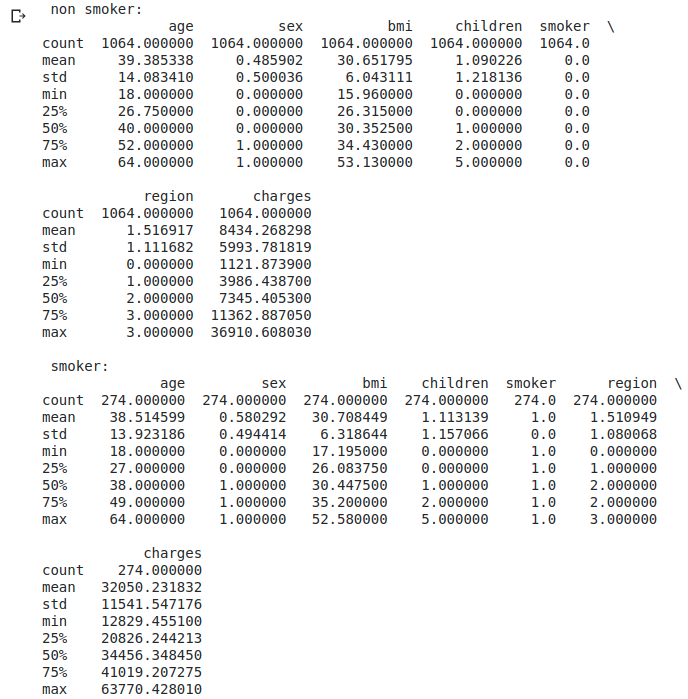
print(' non smoker:\n' + str(df_s0.describe()))
print('\n smoker:\n' + str(df_s1.describe()))
print('\n Krankenkassenprämien für Nichtraucher' + str(df_s1['charges'].mean() / df_s0['charges'].mean()) + 'Es dauert doppelt so viel.')
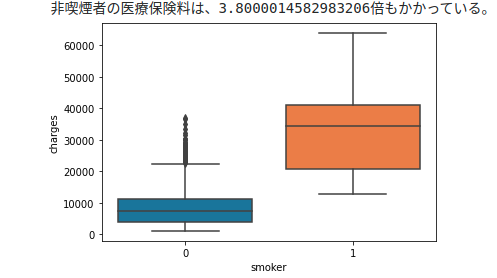
Das Box-Whisker-Diagramm zeigt, dass Nichtraucher den hohen Peaks links vom Ladungshistogramm entsprechen.
Umgekehrt kann man sagen, dass die Orange des Rauchers eine Ansammlung von zwei Bergen mit einem Histogramm mit niedrigen Ladungen ist.
Überprüfen Sie die Verteilung nur für Nichtraucher
sns.pairplot(df_s0.loc[:, ['age', 'bmi', 'charges']], height=2);
 Die oben erwähnte Altersgebührenverteilung könnte getrennt werden
Diese charakteristische Verteilung scheint davon beeinflusst worden zu sein, ob geraucht wird oder nicht
Die oben erwähnte Altersgebührenverteilung könnte getrennt werden
Diese charakteristische Verteilung scheint davon beeinflusst worden zu sein, ob geraucht wird oder nicht
 Selbst Nichtraucher gehen unabhängig vom Alter mit konstanter Rate ins Krankenhaus. Stellt dies also die obere Streuung der Altersgebührenverteilung dar?
Diese Streuung und die Streuung der bmi-Ladungsverteilung scheinen miteinander verbunden zu sein. Versuchen Sie es also mit Clustering.
Selbst Nichtraucher gehen unabhängig vom Alter mit konstanter Rate ins Krankenhaus. Stellt dies also die obere Streuung der Altersgebührenverteilung dar?
Diese Streuung und die Streuung der bmi-Ladungsverteilung scheinen miteinander verbunden zu sein. Versuchen Sie es also mit Clustering.
from sklearn.cluster import KMeans
#from sklearn.cluster import MiniBatchKMeans
df_wk = df_s0.drop(['sex', 'children', 'smoker', 'region'], axis=1)
kmeans_model = KMeans(n_clusters=2, random_state=1, init='k-means++', n_init=10, max_iter=300, tol=0.0001, algorithm='auto', verbose=0).fit(df_wk)
#kmeans_model = MiniBatchKMeans(n_clusters=2, random_state=0, max_iter=300, batch_size=100, verbose=0).fit(df_wk)
df_wk['cluster'] = kmeans_model.labels_
labels = kmeans_model.labels_
print(labels.sum())
color_codes = {0:'r', 1:'g', 2:'b'}
colors = [color_codes[x] for x in labels]
ax1 = df_wk.plot.scatter(x='age', y='charges', c=colors)
ax1 = df_wk.plot.scatter(x='bmi', y='charges', c=colors)
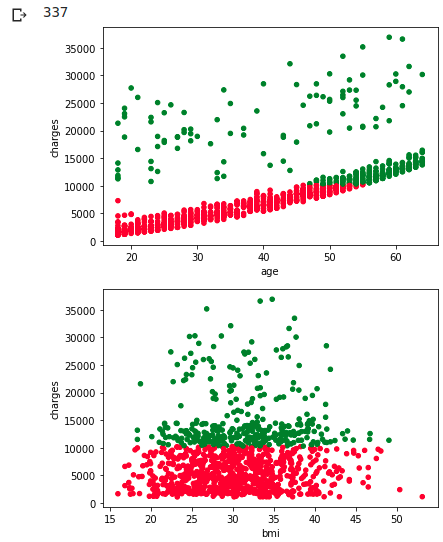 Es ist schade, dass wir sie nicht sauber trennen konnten, aber man kann sagen, dass die beiden oben genannten Verteilungskarten einander entsprechen.
Ich verstehe jedoch nicht, warum die Gebühren unabhängig von der Größe des BMI in jedem Alter hoch sind.
Ich habe Kinder und Regionen noch nicht untersucht, und es scheint, dass Kinder eher mit bmi-Variationen zu tun haben.
Wenn Sie sich die Verteilung der Nichtraucher nach Kindern (= Anzahl der abhängigen Personen) ansehen, können Sie die Beziehung zwischen Familienzusammensetzung und BMI erkennen.
Es ist schade, dass wir sie nicht sauber trennen konnten, aber man kann sagen, dass die beiden oben genannten Verteilungskarten einander entsprechen.
Ich verstehe jedoch nicht, warum die Gebühren unabhängig von der Größe des BMI in jedem Alter hoch sind.
Ich habe Kinder und Regionen noch nicht untersucht, und es scheint, dass Kinder eher mit bmi-Variationen zu tun haben.
Wenn Sie sich die Verteilung der Nichtraucher nach Kindern (= Anzahl der abhängigen Personen) ansehen, können Sie die Beziehung zwischen Familienzusammensetzung und BMI erkennen.
df_c0 = df_s0[df_s0['children'] == 0] # children = 0
df_c1 = df_s0[df_s0['children'] == 1] # children = 1
df_c2 = df_s0[df_s0['children'] == 2] # children = 2
df_c3 = df_s0[df_s0['children'] == 3] # children = 3
df_c4 = df_s0[df_s0['children'] == 4] # children = 4
df_c5 = df_s0[df_s0['children'] == 5] # children = 5
plt.figure(figsize=(12, 6))
plt.hist([df_c0['charges'], df_c1['charges'], df_c2['charges'], df_c3['charges'], df_c4['charges'], df_c5['charges']]
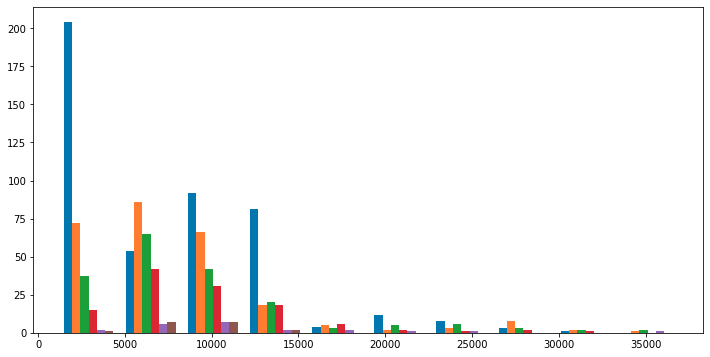
Wenn wir uns das Histogramm für Gebühren> 15000 ansehen, können wir keine Merkmale in Bezug auf Gebühren und Anzahl der Kinder erkennen Ist es schließlich nur "weil selbst Nichtraucher unabhängig vom Alter mit einer bestimmten Rate ins Krankenhaus gehen"? Testen Sie, ob bmi normalerweise zu Gebühren> 15000 verteilt wird
df_b0 = df_s0[df_s0['charges'] > 15000] # children = 0
plt.hist([df_b0['bmi']])
import scipy.stats as stats
stats.probplot(df_b0['bmi'], dist="norm", plot=plt)
stats.shapiro(df_b0['bmi'])
(0.9842953681945801, 0.3445127308368683)
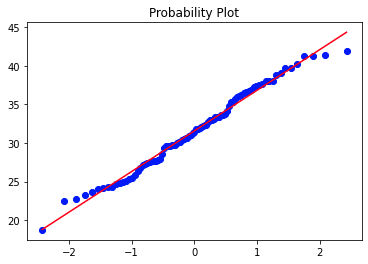 Weder das Histogramm noch das QQ-Diagramm noch der Shapiro-Wilke-Test (p-Wert = 0,3445) zeigen, dass nicht gesagt werden kann, dass die Verteilung normal ist.
Immerhin habe ich die Ursache nicht wirklich verstanden
Lassen wir es wegen der Normalverteilung als natürliche Verteilung ...
Weder das Histogramm noch das QQ-Diagramm noch der Shapiro-Wilke-Test (p-Wert = 0,3445) zeigen, dass nicht gesagt werden kann, dass die Verteilung normal ist.
Immerhin habe ich die Ursache nicht wirklich verstanden
Lassen wir es wegen der Normalverteilung als natürliche Verteilung ...
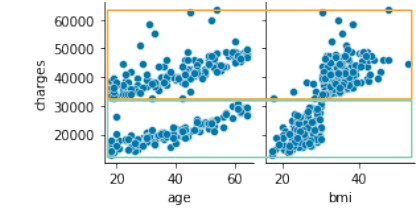
Überprüfen Sie diesmal die Verteilung nur durch Raucher
sns.pairplot(df_s1.loc[:, ['age', 'bmi', 'charges']], height=2);
 Intuitiv scheint es, dass Alter und BMI übereinstimmen, wie in der folgenden Abbildung gezeigt.
Intuitiv scheint es, dass Alter und BMI übereinstimmen, wie in der folgenden Abbildung gezeigt.
 Versuchen Sie das Clustering wie bei einem Nichtraucher
Versuchen Sie das Clustering wie bei einem Nichtraucher
df_wk = df_s1.drop(['sex', 'children', 'smoker', 'region'], axis=1)
kmeans_model = KMeans(n_clusters=2, random_state=1, init='k-means++', n_init=10, max_iter=300, tol=0.0001, algorithm='auto', verbose=0).fit(df_wk)
df_wk['cluster'] = kmeans_model.labels_
labels = kmeans_model.labels_
print(labels.sum())
color_codes = {0:'r', 1:'g', 2:'b'}
colors = [color_codes[x] for x in labels]
ax1 = df_wk.plot.scatter(x='age', y='charges', c=colors)
ax1 = df_wk.plot.scatter(x='bmi', y='charges', c=colors)
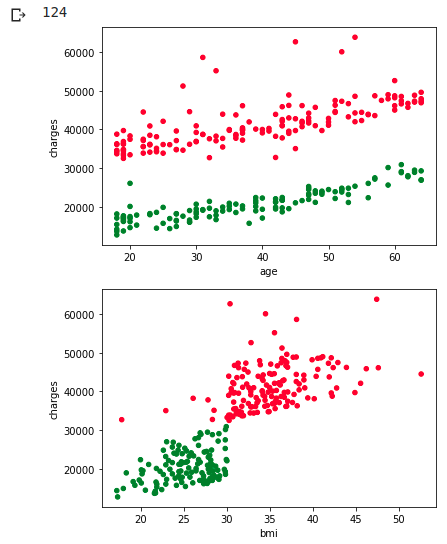 Wie ich erwartet hatte, konnte ich es diesmal sauber trennen
Wie ich erwartet hatte, konnte ich es diesmal sauber trennen
EDA Schlussfolgerung
Menschen mit hohem BMI haben unabhängig von ihren Rauchgewohnheiten hohe Krankenkassenprämien, aber das Alter spielt keine Rolle (es tut meinen Ohren weh ...) Aus den Daten des Rauchers ging hervor, dass die Krankenversicherungsprämie nach bmi = 30 weiter steigen wird. Da diese Grenze zu klar ist, kann es zu administrativen Einschränkungen kommen, z. B. das gewaltsame Hinzufügen teurer Inspektionsgegenstände, wenn diese 30 überschreiten.
sns.regplot(x="bmi", y="charges", data=df_wk)
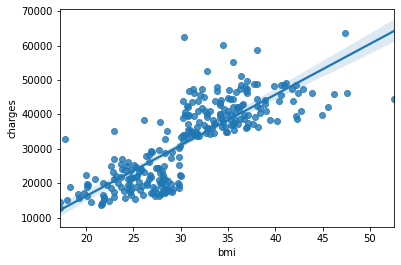 Mit anderen Worten, zum Beispiel ist aus dieser EDA ersichtlich, dass die oben gezeigte Regressionslinie nicht gezogen werden sollte.
Mit anderen Worten, zum Beispiel ist aus dieser EDA ersichtlich, dass die oben gezeigte Regressionslinie nicht gezogen werden sollte.
Einfache Regression, Problem der multiplen Regression
Versuchen Sie für Nichtraucher, die Gebühren als Regressionsproblem vorherzusagen Insbesondere bewertet RMSE den Unterschied in der Genauigkeit der Ladungsvorhersage zwischen einfacher Regression (nur Alter) und multipler Regression (Alter, bmi). Wir werden die Clustering-Ergebnisse nicht verwenden, daher lassen wir die enthaltenen Variationen.
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import mean_squared_error
from sklearn import metrics
from sklearn import linear_model
cv_alphas = [0.01, 0.1, 1, 10, 100] #Α zur Gegenprüfung
df_wk = df_s0.drop(['sex', 'children', 'smoker', 'region'], axis=1)
#Auswertung und Darstellung der Vorhersageergebnisse
def regression_prid(clf_wk, df_wk, intSample=20, way='single'):
arr_wk = df_wk.values[:intSample]
arr_age, arr_agebmi, arr_charges = arr_wk[:,0], arr_wk[:,0:2], arr_wk[:,2]
if way == 'single':
arr_prid = clf_wk.predict(arr_age.reshape([intSample,1]))
titel1='simple regression'
titel2='RMSE(single) =\t'
else:
arr_prid = clf_wk.predict(arr_agebmi.reshape([intSample,2]))
titel1='multiple regression'
titel2='RMSE(multi) =\t'
rmse = np.sqrt(mean_squared_error(arr_charges, arr_prid))
print(titel2 + str(rmse))
#Handlung
arr_chart = df_wk.values[:intSample].reshape([intSample,3])
arr_chart = np.hstack([arr_chart, arr_prid.reshape([intSample,1])])
fig = plt.figure(figsize=(8, 5))
ax = fig.add_subplot(1,1,1)
ax.scatter(arr_chart[:,0],arr_chart[:,2], c='red')
ax.scatter(arr_chart[:,0],arr_chart[:,3], c='blue')
ax.set_title(titel1)
ax.set_xlabel('age')
ax.set_ylabel('charges')
fig.show()
Einfache Regression nach der Methode der kleinsten Quadrate
clf = linear_model.LinearRegression()
#Einfaches Regressionsproblem
clf.fit(df_wk[['age']], df_wk['charges'])
regression_prid(clf, df_wk, 50, 'single')
#Problem der multiplen Regression
clf.fit(df_wk[['age', 'bmi']], df_wk['charges'])
regression_prid(clf, df_wk, 50, 'multi')
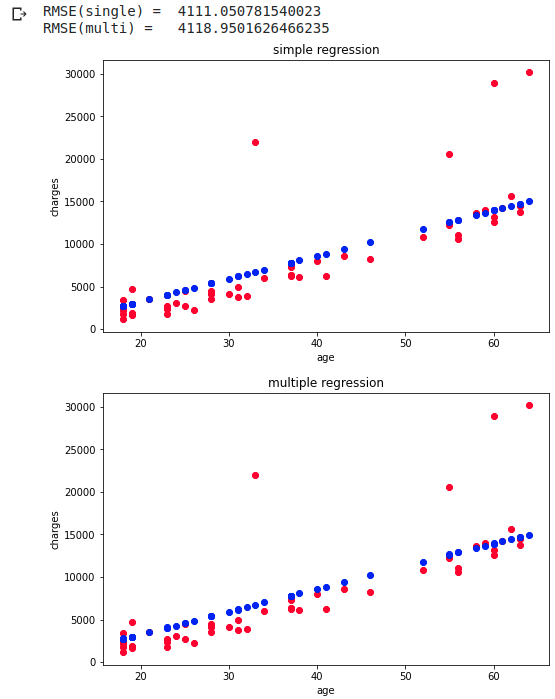
Die Oberseite ist eine einfache Regression, die nach Alter vorhergesagt wird, und die Unterseite ist eine multiple Regression, die nach Alter und BMI vorhergesagt wird. RMSE wird mit 20 Punkten vorhergesagt, und die einfache Regression ist etwas genauer Da die Originaldaten nahezu linear sind, ist die Vorhersage sowohl in einfachen als auch in mehreren Regressionen gerade.
Rückkehr durch L2-Regularisierung
Ridge RidgeCV CV steht übrigens für Closs Validation und Cross Validation. Bitte googeln Sie für Details der Gegenüberstellung
cv_flag = True # True:Gegenüberstellung
if cv_flag:
clf = linear_model.RidgeCV(alphas=cv_alphas ,cv=3, normalize=False)
#Einfaches Regressionsproblem
clf.fit(df_wk[['age']], df_wk['charges'])
print("alpha =\t", clf.alpha_)
regression_prid(clf, df_wk, 50, 'single')
#Problem der multiplen Regression
clf.fit(df_wk[['age', 'bmi']], df_wk['charges'])
print("alpha =\t", clf.alpha_)
regression_prid(clf, df_wk, 50, 'multi')
else:
clf = linear_model.Ridge(alpha=1.0)
#Einfaches Regressionsproblem
clf.fit(df_wk[['age']], df_wk['charges'])
regression_prid(clf, df_wk, 50, 'single')
#Problem der multiplen Regression
clf.fit(df_wk[['age', 'bmi']], df_wk['charges'])
regression_prid(clf, df_wk, 50, 'multi')
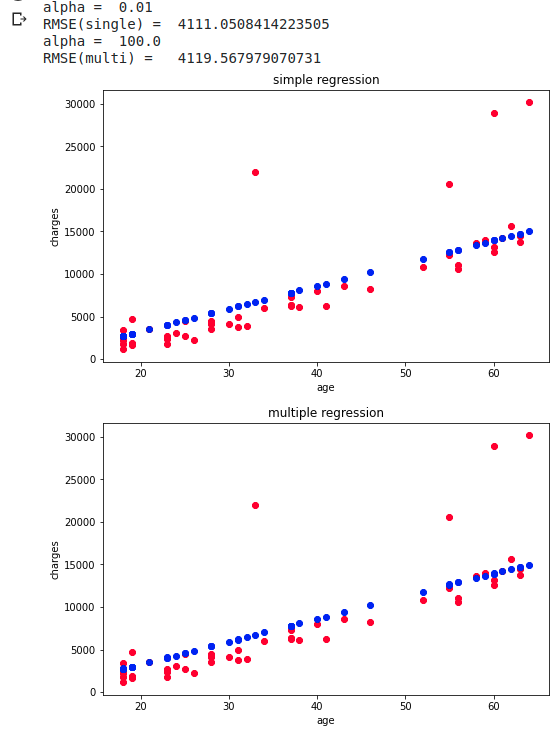
Ich habe versucht, mithilfe der Kreuzungsüberprüfung vorherzusagen, aber schließlich ist die multiple Regression nicht besser
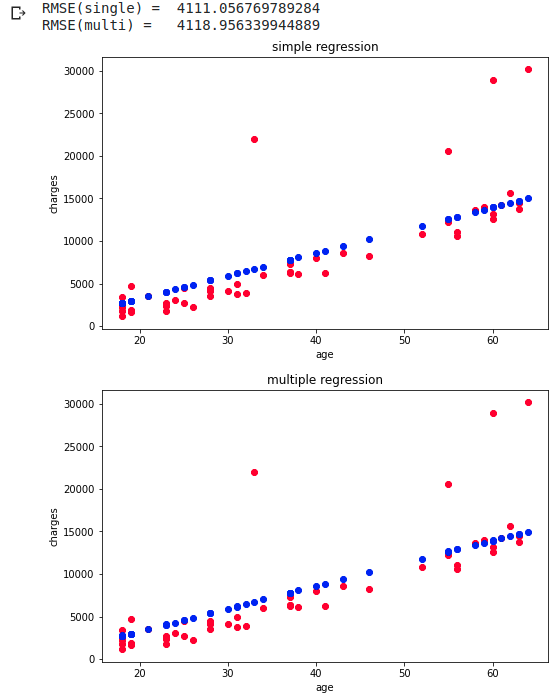
RMSE ändert sich ohne Gegenüberstellung nicht viel Da die Ladungen linear ansteigen, ist es meines Erachtens schwierig geworden, den Genauigkeitsunterschied aufgrund der Regressionsmethode herauszufinden.
Rückkehr durch L1-Regularisierung
Lasso LassoCV Wird weggelassen, da Ridge im obigen Code nur durch Lasso ersetzt wird RMSE war nahezu unverändert
Recommended Posts