[PYTHON] Ein Amateur hat in den Sommerferien in einem kostenlosen Arbeitszimmer seine eigene Spiel-KI von Grund auf neu erstellt
0. Einleitung
Dies ist eine Aufzeichnung, dass der Autor eines College-Studenten im dritten Jahr, der bis vor einem Monat keinerlei Kenntnisse über das Lernen der Verstärkung hatte (bis vor zwei Monaten fast keine Kenntnisse über maschinelles Lernen), versuchte, durch Tappen eine kleine Spiel-KI zu machen. Dies ist ein Level-Artikel. Ich bin eine unerfahrene Person
- Organisieren und bestätigen Sie Ihr Verständnis
- Lassen Sie sachkundige Personen die Punkte ausgleichen, die nicht erreicht werden können ――Ich weiß nichts über Bestärkungslernen, aber ich bin interessiert. Aber ich habe keine Unterrichtsmaterialien zur Hand. Ich hoffe, es wird ein Tutorial für diejenigen, die sagen
Ich bin gekommen, um diesen Artikel zu schreiben, um zu schlagen. Wenn Sie interessiert sind, lesen Sie es bitte herzlich. Wir freuen uns über Ihre Kommentare und Vorschläge.
0-1. Referenzen
Als ich das Bestärkungslernen lernte, las ich zuerst das Buch "Einführung in die Stärkung der Lerntheorie für IT-Ingenieure" (Etsuji Nakai)](https://enakai00.hatenablog.com/entry/2020/06/18/084700). Ich kaufte es als Lehrbuch und las es klebrig. Vielen Dank für Ihre Hilfe beim Schreiben, deshalb werde ich es hier vorstellen.
Außerdem möchte ich darauf hinweisen, dass ein Teil des Quellcodes im Artikel dem in diesem Buch sehr ähnlich ist. Bitte beachten Sie.
Bevor ich dann das Lernen der Verstärkung lernte, las ich zwei Bücher, "Einführung in das maschinelle Lernen ab Python" und "Deep Learning from Zero" (beide von O'Reilly Japan), und ich habe bis zu einem gewissen Grad über maschinelles Lernen und Deep Learning gelesen, daher werde ich dies auch veröffentlichen. Stellen. Letzteres kann insbesondere zum Verständnis des AI-Implementierungsteils nützlich sein.
0-2. Rauer Artikelfluss
In diesem Artikel werden zunächst die Spiele vorgestellt, die die KI lernen und Ziele setzen wird. Als nächstes werde ich die theoretische Geschichte über das verstärkte Lernen und den diesmal verwendeten DQN-Algorithmus organisieren und schließlich den Quellcode offenlegen, das Lernergebnis überprüfen und die Probleme und Verbesserungspläne auflisten, die dort aufgetaucht sind. .. Ich wäre Ihnen dankbar, wenn Sie sich nur die Teile ansehen könnten, die Sie interessieren.
Nachtrag. Als ich es schrieb, wurde die theoretische Ausgabe schwerer als ich erwartet hatte. Wenn Sie eine theoretische Persönlichkeit wie der Autor haben, kann es Spaß machen, klebrig zu sein. Wenn Sie diese Art von Motivation nicht haben, ist es möglicherweise besser, sie in einer moderaten Spur zu halten.
0-3. Zu verwendende Sprache
Mit Hilfe von Python. Der Autor läuft mit Jupyter Notebook. (Vielleicht funktioniert es in anderen Umgebungen als der Visualisierungsfunktion auf der Platine, aber ich habe es nicht bestätigt. Die Visualisierungsfunktion ist keine große Sache, sodass Sie sich nicht so viele Sorgen machen müssen.)
Außerdem werde ich am Höhepunkt das Deep-Learning-Framework "TensorFlow" ein wenig verwenden. Ich möchte den Code bis zum Ende ausführen! Für diejenigen, die sagen, dass eine Installation erforderlich ist, um das entsprechende Teil auszuführen, also bitte nur dort. Auch hier kann eine GPU, wenn sie verfügbar ist, mit hoher Geschwindigkeit verarbeitet werden. Da ich jedoch keine solche Umgebung oder kein solches Wissen habe, habe ich sie mit einer CPU (normal) gepusht. Wenn Sie Google Colab usw. verwenden, können Sie die GPU kostenlos verwenden, aber ich habe sie vermieden, weil ich den Unfall hasste, weil die Sitzung unterbrochen wurde. Ich werde das Urteil hier lassen.
0-4. Vorkenntnisse
Wenn Sie nur den Artikel lesen und ein Gefühl dafür bekommen, benötigen Sie keine besonderen Kenntnisse.
Um die Theorie richtig zu verstehen, reicht es aus, die Mathematik der High School (Wahrscheinlichkeit, Graduierungsformel) bis zu einem gewissen Grad zu verstehen und die Implementierung ohne Stress zu lesen. Es reicht aus, die grundlegende Grammatik von Python (Klasse) zu kennen. Wenn Sie sich über das Konzept Sorgen machen, sollten Sie es leicht überprüfen. Wenn Sie bereits Kenntnisse über Algorithmen (dynamische Planung usw.) haben, ist dies leichter zu verstehen.
Der einzige Punkt ist, dass das neuronale Netzwerk ein Feld ist, das sich erheblich ändern wird, wenn Sie es in diesem Artikel nicht erklären und wenn Sie über Kenntnisse verfügen. Ich werde eine Erklärung wie "Bitte denken Sie so darüber nach" abgeben, daher denke ich, dass dies Ihr Verständnis nicht beeinträchtigt, wenn Sie es schlucken. Wenn Sie es jedoch richtig wissen möchten, empfehle ich Ihnen, es separat zu tun.
Gehen wir zur Hauptgeschichte! !!
1. Einführung der Spiele, die wir behandeln
Ich habe ** 2048 Spiele ** als Lernthema gewählt (↓ so). Wissen Sie

Ich werde die Regeln später erklären, aber es ist so einfach, dass Sie es verstehen werden. Es gibt viele Smartphone-Apps und Webversionen. Probieren Sie es aus.
1-1. Regeln
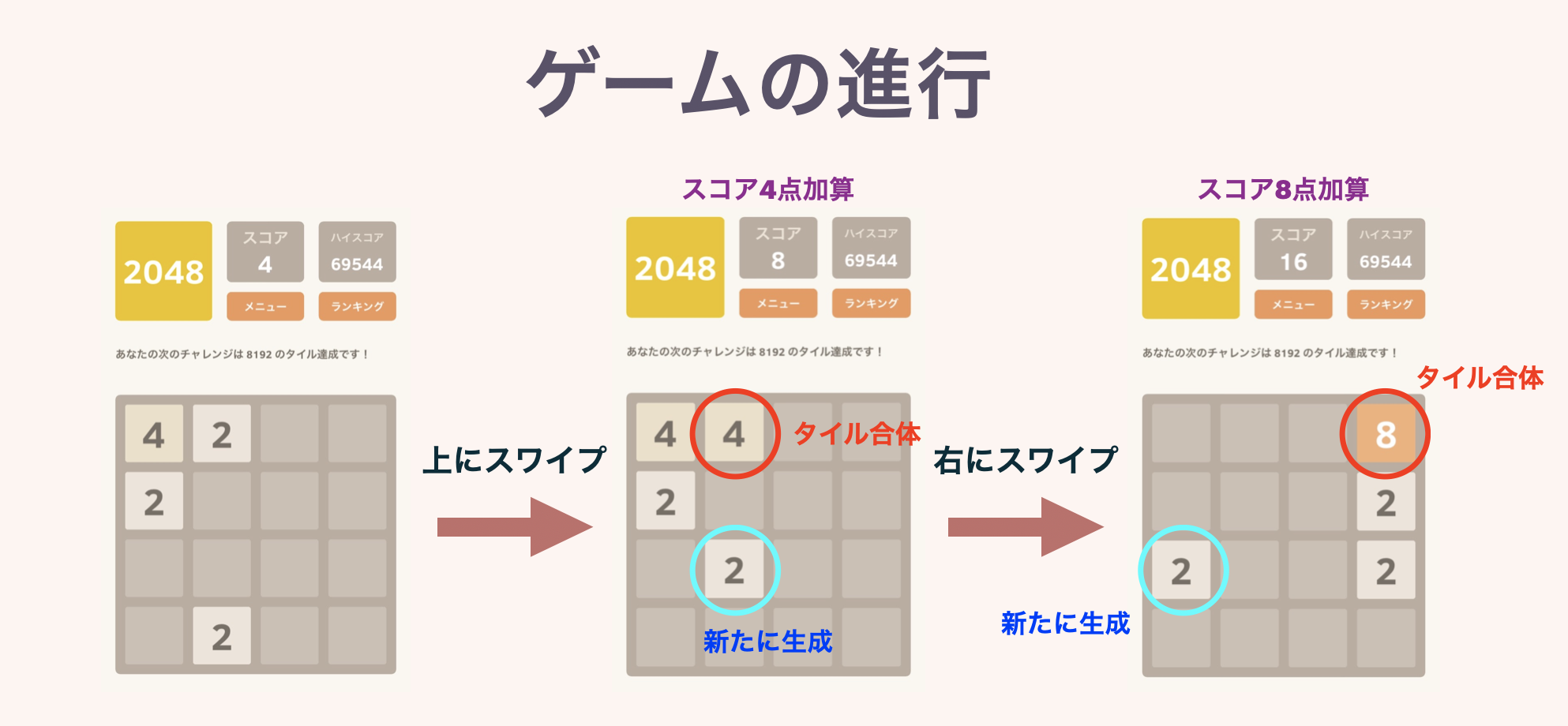
Ein Plättchen mit einer Potenz von 2 wird auf das Brett mit 4 $ \ mal $ 4 Feldern gelegt. Zu Beginn des Spiels werden "2" oder "4" Kacheln auf 2 zufällig ausgewählten Feldern platziert.
In jeder Runde wählt der Spieler eine von vier Richtungen, nach oben, unten, links und rechts, und wischt oder drückt einen Knopf. Dann gleiten alle Kacheln auf dem Brett in diese Richtung. Wenn zu diesem Zeitpunkt Kacheln mit derselben Nummer kollidieren, werden sie zusammengeführt und die Anzahl erhöht sich zu einer einzigen Kachel. Zu diesem Zeitpunkt werden die auf den erstellten Kacheln geschriebenen Zahlen als Punkte hinzugefügt.
Am Ende jeder Runde wird auf einem der leeren Felder ein neues Plättchen "2" oder "4" erstellt. Wenn Sie sich nicht in eine Richtung bewegen können, ist das Spiel beendet. Streben Sie bis dahin eine hohe Punktzahl an! Es ist ein Spiel namens. Wie der Name dieses Spiels andeutet, besteht das Ziel darin, zunächst "2048 Plättchen zu machen".
↓ Es ist eine Illustration. Die Regeln sind wirklich einfach.
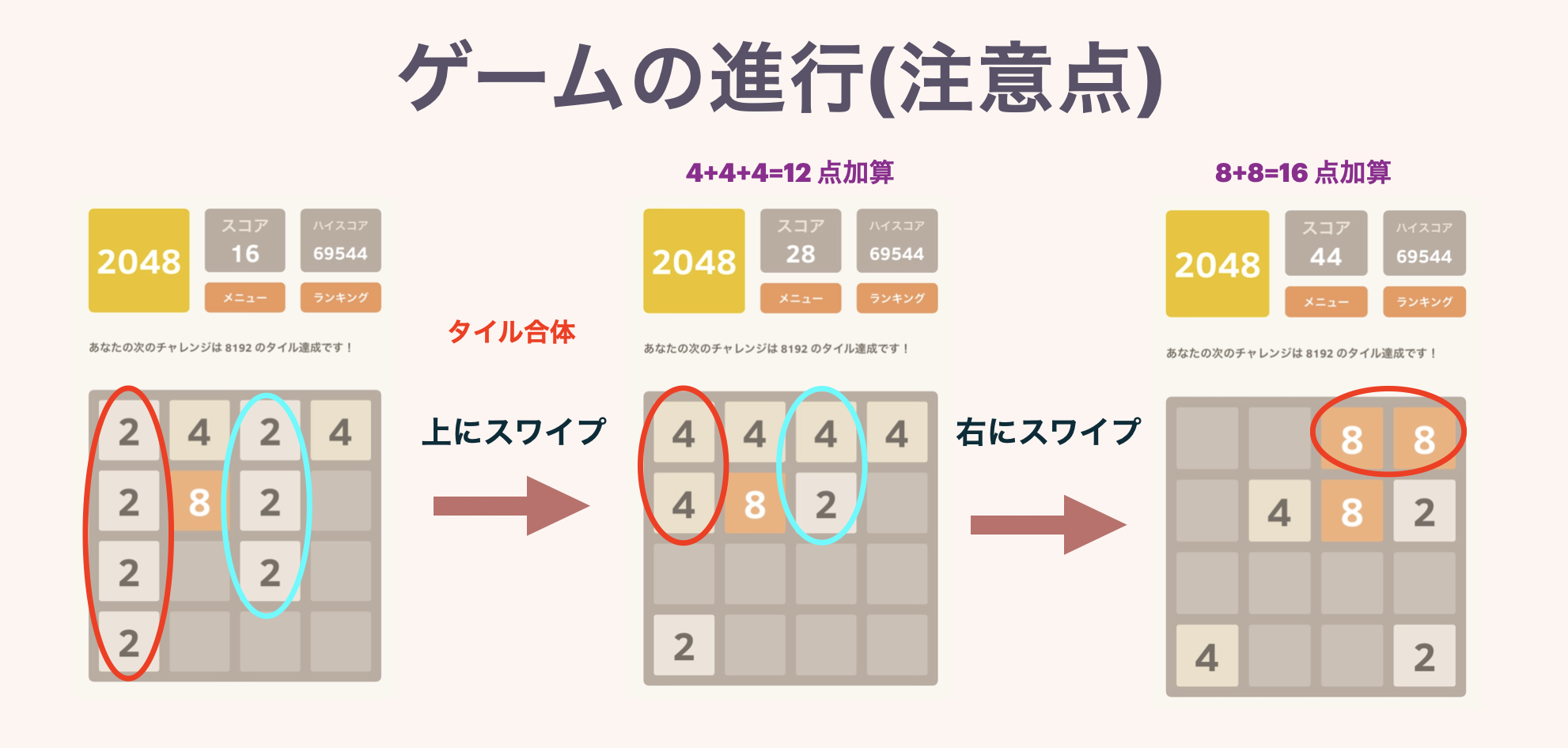
Die zweite Abbildung zeigt das Verhalten, wenn drei oder mehr Kacheln mit derselben Nummer aneinandergereiht sind. Wenn mehrere Kacheln gleichzeitig abgeschlossen sind, wird die Punktzahl ordnungsgemäß hinzugefügt.

1-2. Tipps für dieses Spiel
Es gibt etwas Glück in diesem Spiel, aber die Punktzahl spiegelt wahrscheinlich die Fähigkeiten des Spielers wider. Mit anderen Worten, es ist ein "Spiel, das Sie durch Lernen und Üben verbessern können". Später werde ich AI bitten, das Spiel zu üben, aber ich werde kurz die Tipps dieses Spiels aufschreiben, die ich zu diesem Zeitpunkt erhalten habe. Es wäre großartig, wenn AI diesen Trick für sich selbst lernen könnte.
Wenn Sie jedoch erfahren möchten, wie viel KI Sie erreichen können, ** empfehle ich Ihnen, es mehrmals zu spielen, ohne diesen Tipp zu sehen. ** Wenn Sie wissen, wie hoch Ihre anfänglichen Fähigkeiten sind, ist es etwas einfacher zu verstehen, auf welchem Niveau Sie sich im zukünftigen KI-Lernprozess befinden. (Wenn es Ihnen nichts ausmacht, können Sie es normal öffnen.)
1-3. Ziel
Dieses Ziel werde ich mir vorerst setzen (Traum). Das Ideal ist "KI, die eine höhere Punktzahl erzielen kann als ich". Ich glaube, ich verstehe dieses Spiel bis zu einem gewissen Grad, und der Highscore von 69544 im Sukusho, den ich Ihnen zuvor gezeigt habe, ist ziemlich hoch, aber wenn AI diesen Wert überschreitet, werde ich beeindruckt sein.
Wenn eine Person, die dieses Spiel nicht kennt, zum ersten Mal spielt, ist das Spiel mit etwa 1000 bis 3000 Punkten beendet. Wenn Sie ein paar Mal spielen und sich an das Spiel gewöhnen, erhalten Sie ungefähr 5000 bis 7000 Punkte. (Es ist nur so, dass die Leute um mich herum diese Tendenz hatten. Da es nur wenige Beispiele gibt, verwenden Sie sie bitte als Referenz.) Wie ich später erklären werde, erhalten Sie durchschnittlich nur etwa 1000 Punkte, wenn Sie Ihre Hand völlig zufällig auswählen.
Nachdem wir über das Spiel 2048 gesprochen haben, wollen wir uns intensiv mit dem Hauptthema befassen!
2. Mit Theorie bewaffnet
Vor der Implementierung werden wir die Theorie organisieren, die die Grundlage für diese KI-Kreation des Spiels bildet ~~ oder so ~~. Ich möchte den Fluss von den Grundlagen des Verstärkungslernens zum diesmal verwendeten DQN verfolgen. Der Autor wird auch Schritt für Schritt schreiben, während er obenkyo macht, also lasst uns gemeinsam unser Bestes geben.
2-1. Über die Stärkung des Lernens
Erstens ist das verstärkte Lernen ein Bereich des maschinellen Lernens, des überwachten Lernens und des unbeaufsichtigten Lernens. Verstärkungslernen besteht darin, einen ** Agenten ** zu definieren, der sich in einer bestimmten Umgebung bewegt, mit dem Lernprozess fortfährt, während wiederholt Daten gesammelt werden, und das optimale Verhalten zu lernen, das die "Belohnung" maximiert, die erzielt werden kann. Es ist der Fluss von. Es scheint, dass das verstärkte Lernen in der KI von Shogi and Go, die oft gehört wird, und in der automatischen Fahrtechnik angewendet wird.
Im Folgenden werde ich das Thema der 2048-Spiele festlegen, aber auch ein wenig mehr technische Begriffe einbeziehen und sie organisieren.
2-1-1. Aktionsrichtlinie
Um mit dem Verstärkungslernen zu beginnen, definieren Sie zuerst den "** Agenten ", der das Spiel tatsächlich spielt (es ist subtil, wenn gesagt wird, dass der Agent selbst in dieser Implementierung definiert wurde, aber sogar praktisch das Spiel Ich denke, es ist gut, sich der Existenz des Spielens bewusst zu sein. Stellen Sie außerdem " Belohnung " im Spiel ein, um dem Agenten den Zweck zu geben, "die Belohnung am Ende des Spiels zu maximieren". Das Festlegen der Belohnung ist ein wichtiger Faktor. Während des Spiels trifft der Agent auf verschiedene Bretter und muss die " Aktion " auswählen, die dort ausgeführt werden soll. Jedes Board wird in Bezug auf das Lernen der Verstärkung als " Zustand **" bezeichnet.
Der Abschluss der Agentenschulung bedeutet letztendlich, dass "die beste Aktion a für alle Staaten bekannt ist". Es ist leicht zu verstehen, wenn Sie "○ × Spiel" als Beispiel betrachten. Dieses Spiel wird immer ein Unentschieden sein, solange beide Parteien ihr Bestes geben. Dies bedeutet, dass Sie, wenn Sie sich alle möglichen Zustände (Bretter) "merken", ein unbesiegter ○ × Spielleiter werden, ohne die extremen Regeln zu kennen.
Hier definieren wir den Begriff "** Verhaltensrichtlinie **". Dies ist eine "Regel, in der der Agent für jeden Status eine Aktion auswählt". Ein Agent mit einer festen Verhaltensrichtlinie spielt das Spiel, indem er den nächsten Zug nach bestimmten Regeln (nun, es ist eine Maschine) wie eine Maschine auswählt. Der Zweck des intensiven Lernens kann als Optimierung dieser Verhaltensrichtlinie und Suche nach der optimalen Verhaltensrichtlinie umformuliert werden. Im Beispiel des Spiels ○ × ist es die optimale Aktionsrichtlinie, den besten Zügen zu folgen, die man sich merken sollte.
Darüber hinaus scheint es üblich zu sein, die Verhaltensrichtlinie mit dem Symbol $ \ pi $ auszudrücken.
2-1-2. Statuswertfunktion
Ich habe vor einiger Zeit gelernt, aber ich werde anfangen darüber zu sprechen, wie man konkret lernt.
Definieren Sie zunächst die ** Statuswertfunktion ** $ v_ \ pi (s) $. Dies ist eine Funktion, die eine bestimmte Aktionsrichtlinie π annimmt und den Zustand s als Argument verwendet. Der Rückgabewert ist "der erwartete Wert der Gesamtbelohnungen, die nach der Gegenwart erhalten werden, wenn man vom Zustand s ausgeht und bis zum Ende des Spiels weiterhin Aktionen gemäß der Aktionsrichtlinie π auswählt".
?? Es mag sein, aber wenn Sie darüber nachdenken, ist es keine große Sache. Wenn die Aktionsrichtlinie festgelegt ist, gibt der Wert der Statuswertfunktion an, "wie gut jede Karte ist".
Ich werde es zeigen, weil es sich (persönlich) besser anfühlt, die Formel zu verwenden. Alle Symbole, die plötzlich erscheinen, geben Bedeutung.
Ja, dies ist die Gleichung, die die Zustandswertfunktion im Allgemeinen erfüllt. Dies nennt man die ** Bellman-Gleichung **.
- $ p (r, s '\ | \ s, a) $ steht für "bedingte Wahrscheinlichkeit, dass r als Belohnung erhalten wird, wenn Aktion a aus Zustand s ausgewählt wird und in Zustand s' übergeht". Ich werde. (Selbst wenn Sie dieselbe Aktion auf demselben Brett auswählen, wird diese Maßnahme ergriffen, da Sie nicht immer dasselbe Belohnungs- / Übergangsziel erhalten. In 2048 Spielen ist die Position neu generierter Kacheln beispielsweise zufällig. .)
- $ r + v_ \ pi (s ') $ ist "wenn a in der ersten Aktion ausgewählt wird, wird die Belohnung r erhalten und der Zustand wechselt in den Zustand s', und dann wird die Aktionsrichtlinie π bis zum Ende des Spiels befolgt. , Der erwartete Wert der Summe der Belohnungen, die von nun an erhalten werden können. “
- $ \ pi (a \ | \ s) $ steht für "bedingte Wahrscheinlichkeit, dass Aktion a in Status s in Aktionsrichtlinie π ausgewählt wird". (Wenn π keine probabilistische Aktionsauswahl enthält, kann diese entfernt werden.)
Um das Obige zusammenzufassen, drückt das innere Sigma "den erwarteten Wert der Summe der Belohnungen aus, die von nun an erhalten werden können, wenn Aktion a aus dem aktuellen Zustand s ausgewählt wird und dann gemäß π handelt". Durch Summieren der Aktionen mit dem äußeren Sigma wird es außerdem "der erwartete Wert der Gesamtbelohnung, die bis zum Ende des Spiels erhalten wird, wenn die Aktion kontinuierlich gemäß der Aktionsrichtlinie π aus dem aktuellen Status s ausgewählt wird".
Ergänzende Informationen zum "Diskontsatz" In der Belman-Gleichung von (1) wird im Allgemeinen ein Parameter namens ** Abzinsungssatz ** eingeführt (das Symbol ist γ). Dieses Mal habe ich mich jedoch entschieden, mich nicht damit zu befassen, da es sich um einen Ausdruck handelt, der (1) entspricht, weil im Implementierungsteil $ \ gamma = 1 $ festgelegt wurde und der Grad des Verständnisses des Autors gering ist. Es tut uns leid.
Die obige Gleichung (1) zeigt eher die Berechnungsmethode als die Definition der Zustandswertfunktion. Nur ein Punkt, wenn der Wert der Zustandswertfunktion für den Endzustand (Spiel über Bord) im Voraus als 0 definiert ist, kann die Zustandswertfunktion für alle Zustände auf den vorherigen Zustand und den vorherigen Zustand zurückgeführt werden. Sie können den Wert von berechnen. Es ist ein Bild, dass sich der Wert der korrekten Zustandswertfunktion allmählich vom Endzustand ausbreitet. In der Mathematik der High School ist es eine schrittweise Formel, und in Bezug auf Algorithmen ist es eine ** dynamische Planungsmethode **.
Ich werde mich nicht weiter mit dynamischer Planung befassen. Es kann jedoch zu beachten sein, dass zur Durchführung dieser Berechnung mindestens eine Schleife für alle Zustände ausgeführt werden muss.
Nun, ich habe die Zustandswertfunktion selbst definiert, aber am Ende wird noch nicht gezeigt, was "Lernen" bewirkt. Ich werde diese Frage als nächstes beantworten.
2-1-3. Verhaltensstatuswertfunktion
Die oben beschriebene Zustandswertfunktion bestimmt, ob jeder Zustand gut oder schlecht ist, unter der Voraussetzung, dass die Aktionsrichtlinie π festgelegt ist. Mit anderen Worten, es kann die Verhaltensrichtlinie π nicht selbst verbessern. Hier erfahren Sie, wie Sie eine bessere Verhaltensrichtlinie erhalten. Hier bedeutet jedoch die Tatsache, dass die Aktionspolitik "besser" ist "Für jeden Zustand s gilt $ v_ {\ pi1} (s) \ leq v_ {\ pi2} (s) $." Es ist bestimmt, dass. (Π2 ist eine "bessere" Verhaltensrichtlinie als π1.)
Es hat einen sehr ähnlichen Namen, definiert aber die ** Aktionsstatuswertfunktion ** $ q_ \ pi (s, a) $. Dies stellt "den erwarteten Wert der Gesamtbelohnung dar, der von nun an erhalten werden kann, wenn Aktion a aus dem aktuellen Status s ausgewählt wird und dann die Aktion kontinuierlich gemäß der Aktionsrichtlinie π ausgewählt wird". Das? Wie einige von Ihnen vielleicht gedacht haben, erscheint dies vollständig in einem Teil von Gleichung (1). Das ist,
ist. Damit wird Gleichung (1)
Kann ausgedrückt werden als.
Jetzt werde ich sofort eine Schlussfolgerung ziehen. So verbessern Sie Ihre Verhaltensrichtlinie ** "Beziehen Sie sich für alle Aktionen a, die im aktuellen Status s ausgewählt werden können, auf den Wert der Aktionsstatuswertfunktion $ q_ {\ pi} (s, a) $ und wählen Sie die Aktion a aus, die dies maximiert. Korrigieren "**.
Das Fazit lautet: "Ignorieren Sie die aktuelle Verhaltensrichtlinie für nur einen Zug, betrachten Sie eine andere Welt und ändern Sie die Richtlinie, um den Zug auszuwählen, der am besten zu sein scheint." Ich denke, Sie können intuitiv verstehen, dass Sie immer mehr "bessere" Richtlinien erhalten, wenn Sie diese Verbesserung fortsetzen. Es ist möglich, dies mathematisch darzustellen, aber es ist ziemlich mühsam, deshalb werde ich es hier weglassen.
2-1-4. Zusammenfassung bisher
Ich habe viel gesagt, aber vorerst habe ich mich niedergelassen, also werde ich es kurz zusammenfassen. Der Ablauf, bis der Agent die optimale Verhaltensrichtlinie erfährt, ist
- Legen Sie vorerst die Aktionsrichtlinie $ \ pi $ entsprechend fest. --Berechnen Sie die Statuswertfunktion $ v_ {\ pi} (s) $ durch dynamische Programmierung. --Aktion - Die Zustandswertfunktion $ q_ {\ pi} (s, a) $ wird nach Gleichung (2) berechnet. --Erstellen Sie eine neue Verhaltensrichtlinie $ \ pi '$ mit der oben beschriebenen Methode.
- Ersetzen Sie dieses $ \ pi '$ durch die erste Aktionsrichtlinie π und wiederholen Sie dieselbe Operation.
ist. Wenn Sie dies die ganze Zeit wiederholen, kann der Agent eine immer bessere Verhaltensrichtlinie erhalten. Dies ist der Mechanismus des "Lernens" beim verstärkten Lernen.
2-2. Q-Learning
Der oben zusammengefasste Algorithmus ist zweifellos der richtige Lernalgorithmus, hat jedoch den Nachteil, dass die Richtlinie erst am Ende eines Spiels verbessert wird und "die aktuelle Verhaltensrichtlinie nicht immer zum Ende des Spiels führt". Es gibt. Dies ist bei 2048 Spielen nicht der Fall, aber dies ist ein großes Problem bei der Anwendung auf allgemeine Spiele (z. B. Labyrinthe). Die Lösung für diesen Punkt ist der ** Q-Learning ** -Algorithmus, der dieses Mal implementiert wurde und im Folgenden erläutert wird.
2-2-1. Off-Policy
Hier definieren wir nur die Begriffe. Wir sind nur bestrebt, die Verhaltensrichtlinie zu verbessern. Wenn Sie jedoch sorgfältig darüber nachdenken, ist es beim Abspielen und Sammeln von Daten durch einen Agenten nicht erforderlich, Daten gemäß der aktuellen Richtlinie für optimales Verhalten zu sammeln. Betrachten wir daher eine Methode zum "Verschieben eines Agenten gemäß einer anderen Richtlinie als der zu verbessernden Richtlinie und zum Sammeln von Daten". Dies wird als ** Off-Policy ** -Datenerfassung bezeichnet.
2-2-2. Gierige Politik
Ich werde jetzt ein wenig daran erinnert, aber ich definiere den Begriff ** Greedy Policy **. Dies ist eine "Aktionsrichtlinie, die keine probabilistischen Elemente enthält und weiterhin Aktionen auswählt". Die Richtlinie ist so, dass die bedingte Wahrscheinlichkeit $ \ pi (a \ | \ s) $, die in den Gleichungen (1) und (3) erscheint, nur für ein bestimmtes a 1 und für andere Aktionen 0 ist. Es kann auch umformuliert werden als.
Wenn in der Greedy-Richtlinie π der Zustand s definiert ist, ist eine Aktion festgelegt, sodass die Aktion als $ \ pi (s) $ ausgedrückt wird.
Zu diesem Zeitpunkt im Allgemeinen
Wird erhalten. Dies wird als ** Verhaltens-Bellman-Gleichung für die Zustandswertfunktion ** bezeichnet. Nach dieser Formel wird der Wert auf der linken Seite unter Verwendung der Belohnung r berechnet, wenn Aktion a im Zustand s und im Zustand s ', $ q_ {\ pi} (s', \ pi (s ')) $ des Übergangsziels ausgewählt wird. Sie können es erneut versuchen. Mit dieser Formel muss die Statuswertfunktion nicht durchlaufen werden.
Das Folgende ist eine Übersicht über Q-Learning unter Verwendung von Gleichung (5).
2-2-3. TD-Methode
In dem zu Beginn erläuterten Algorithmus wurde festgestellt, dass die Richtlinie nicht verbessert werden kann, ohne auf das Ende eines Spiels zu warten. Andererseits gibt es eine Methode, um die Aktualisierungsverarbeitung in dem Moment durchzuführen, in dem Daten für eine Runde gesammelt werden. Dies wird als "** TD-Methode (Temporal-Difference-Methode) **" bezeichnet, und die TD-Methode, die Daten außerhalb der Richtlinie sammelt, wird als Q-Learning bezeichnet. In diesem Fall kann KI beim Sammeln von Daten klug sein, sodass Sie die Situation vermeiden können, in der Sie das Ziel des Labyrinths nicht für immer erreichen können.
Die Aktualisierung wird unter Verwendung von Gleichung (5) durchgeführt. Der Wert von $ p (r, s '\ | \ s, a) $ ist anfangs unbekannt, ein ungefährer Wert wird aus den erhaltenen Daten berechnet, und durch Sammeln der Daten wird der Wert näher an den wahren Wert. Gleichzeitig wird auch der Wert der Aktionsstatuswertfunktion geändert.
Beim eigentlichen Q-Learning scheint der Wert jedoch durch die folgende Formel anstelle der Formel (5) korrigiert zu werden. (Das Gefühl, den Wert der Aktionszustandswertfunktion näher an $ r + q_ {\ pi} (s ', \ pi (s')) $ heranzuführen, bleibt gleich.)
α ist ein Parameter, der das Gewicht der Korrektur anpasst und als ** Lernrate ** bezeichnet wird. (Dies ist völlig meine Erwartung, aber es ist Speicher, den Wert von $ p (r, s '\ | \ s, a) $ für alle (s, a) Paare beizubehalten und zu aktualisieren. Ich denke, es gibt viele Fälle, in denen es schwierig ist.)
Ja. Ich habe es gegen Ende etwas locker erklärt, aber um ehrlich zu sein, habe ich diese Formel im Implementierungsteil nicht verwendet, also war ich etwas weniger motiviert. Was jedoch wichtig ist, ist die Idee, dass Sie eine bessere Verhaltensrichtlinie erhalten können, indem Sie die Funktion für den Aktionsstatuswert aktualisieren, während Sie Daten mit einer Richtlinie außerhalb der Richtlinie erfassen und die Aktion auswählen, die diesen Wert maximiert **. Der darauf basierende Mechanismus des Produktionsalgorithmus ist unten dargestellt, und der lange theoretische Abschnitt ist geschlossen.
2-3. DQN
Im theoretischen Teil haben wir zuerst den grundlegenden Mechanismus des verstärkenden Lernens erklärt und dann eine Methode namens Q-Learning beschrieben, die es effizienter macht. Der aktuelle Algorithmus weist jedoch immer noch ein schwerwiegendes Problem auf. Der Punkt ist, dass der Lernprozess nicht endet, wenn es zu viele mögliche Zustände gibt.
Bei herkömmlichen Algorithmen muss, egal wie unterschätzt, die Anzahl möglicher Zustände berechnet und der Wert der Aktionszustandswertfunktion für alle Zustände berechnet werden (dies wird natürlich viele Male wiederholt. Sie erhalten eine bessere Politik). Die Anzahl der Operationen, die Python pro Sekunde ausführen kann, beträgt höchstens 10 ^ {7} $ Mal, während die Anzahl der Zustände in 2048 Spielen 16 Quadrate auf dem Brett beträgt und ungefähr 12 ^ {16} $ beträgt. Korrekt. Wenn man bedenkt, dass es viele Male um eine Schleife dieser Länge geht, scheint das Lernen nie zu Ende zu sein. Wenn Sie anfangen, über die Anzahl der Shogi-Zustände zu sprechen und gehen, wird es niemals enden. (Ich bin mit Pythons Rechengeschwindigkeit nicht so vertraut, deshalb habe ich sie aufgeschrieben, aber sie endet vorerst nicht.)
Um dieses Problem zu lösen, muss ** DQN ** ein großartiges ** neuronales Netzwerk ** hervorbringen und Q-Learning durchführen. DQN ist eine Abkürzung für Deep Q Network.
2-3-1. Neuronales Netz
Ich werde in diesem Artikel noch einmal nicht auf die detaillierte Theorie und den Mechanismus neuronaler Netze eingehen. Hier werde ich die minimale Sicht auf die Welt beschreiben, die notwendig ist, um den Lernmechanismus von 2048 Game AI zu verstehen. (Tatsächlich bin ich auch eine unerfahrene Person, es tut mir leid, dass ich die Tiefe nicht kenne.)
Neuronale Netze werden beim ** tiefen Lernen ** verwendet, aber um es klar auszudrücken, dies ist eine "Funktion". (Multi-Variable-Eingabe und Multi-Variable-Ausgabe sind die Standardeinstellungen). Bereiten Sie viele einfache lineare Funktionen vor, leiten Sie die Eingabe durch sie und fügen Sie etwas Verarbeitung hinzu. Nachdem dieser Vorgang in mehreren Ebenen wiederholt wurde, wird die Ausgabe in irgendeiner Form ausgegeben. Das ist ein neuronales Netzwerk. Durch Optimieren der Anzahl der internen Funktionen, der Art der Verarbeitung und der Anzahl der Ebenen können Sie sich wirklich flexibel in verschiedene Funktionen umwandeln. (Im Folgenden wird das neuronale Netzwerk manchmal als "NN" abgekürzt.)
Und das neuronale Netzwerk hat eine weitere wichtige Funktion. Das ist ** Parametereinstellung **. Früher wurde der Inhalt von NN festgelegt und als Funktion bearbeitet. Durch die Ausgabe der "richtigen Antwort" an NN zur gleichen Zeit wie die Eingabe wird der Wert des in der internen Funktion enthaltenen Parameters ausgegeben, sodass ein Wert ausgegeben wird, der der richtigen Antwort nahe kommt. Kann geändert werden. Dies bedeutet, dass das neuronale Netzwerk "lernen" kann, so dass es eine Funktion mit den gewünschten Eigenschaften wird.
Dieses Mal werden wir die Leistung des Frameworks ** TensorFlow ** für die Implementierung nutzen, daher denke ich, dass es in Ordnung ist, den Inhalt vorerst zu verstehen. Obenkyo wird eine weitere Gelegenheit nutzen.
2-3-2. Convolutional Neural Network (CNN)
Es gibt eine Art von NN namens ** Convolution Neural Network **. Dies ist die Art, die für die Bilderkennung usw. verwendet wird, und es ist besser, die Eigenschaften der zweidimensionalen Streuung des Eingangs (genau wie die Plattenoberfläche) zu erfassen, als einfach den Eingabewert anzugeben. Also werde ich es dieses Mal benutzen. Das war's vorerst.
2-3-3. In Q-Learning integrieren
Die Verwendung von NN besteht darin, "ein neuronales Netzwerk zu erstellen, das den Wert der Aktionszustandswertfunktion aus dem Zustand und der Aktion der Karte berechnet". Es wurde gesagt, dass die herkömmliche Methode zum Finden von $ q_ {\ pi} (s, a) $ für alle Zustände / Aktionen unmöglich sei, aber wenn ein solches NN erstellt werden könnte, wäre es "irgendwie ähnlich". Sie können erwarten, dass Sie den besten Zug auswählen können, indem Sie auf die Tafel schauen, auf der steht "Es gibt einen Teil, der kommuniziert".
Ich verstehe es mit einem Ausdruck. Ähnlich wie bei den Gleichungen (5) und (6) besteht der Zweck von Q-Learning darin, den Wert von $ q_ {\ pi} (s, a) $ zu aktualisieren. Daher ist der Eingang von NN auch der Zustand der Karte selbst + die ausgewählte Aktion.
Da wir das Berechnungsergebnis näher an $ r + q_ {\ pi} (s ', \ pi (s')) $ bringen wollen, werden wir dies als "richtigen Antwortwert" verwenden und eine NN-Lernverarbeitung durchführen. Obwohl dies nur im Bereich der "Funktionsnäherung" der Fall ist, ist zu erwarten, dass sich die Leistung (ungefähre Genauigkeit) durch Wiederholung des Datenerfassungs- und Lernprozesses stetig verbessert.
Das Obige ist das Gesamtbild des diesmal verwendeten DQN. Ich denke, es ist schneller, sich den Code für die jeweilige Geschichte anzusehen, also werde ich ihn später veröffentlichen.
2-4. Zusammenfassung der Weltanschauung
Der theoretische Teil ist länger geworden als erwartet (Gachi). Lassen Sie uns hier das ganze Bild neu organisieren und mit dem Implementierungsteil fortfahren.
―― Beim verstärkten Lernen wird die Aktionsrichtlinie verbessert, sodass der Agent das Spiel spielt und die erhaltene Belohnung maximiert wird. --Aktion - Wenn der Wert der Statuswertfunktion für jeden Status / jede Aktion genau berechnet werden kann, ist die beste Bewegung auf allen Karten bekannt. ――Q-Learning besteht darin, Daten außerhalb der Richtlinie zu erfassen und den Wert der Aktionsstatus-Wertfunktion jederzeit zu aktualisieren.
- Wenn die Anzahl der Zustände zu groß ist, ist sie so wie sie ist nicht steuerbar, sodass die Verhaltenszustandswertfunktion unter Verwendung eines neuronalen Netzwerks approximiert und berechnet wird und Daten gesammelt werden, um diesen NN-Lernprozess durchzuführen. (DQN)
Danke für deine harte Arbeit! Auch wenn Sie es nicht gut verstehen, können Sie es durch Lesen des Codes verstehen. Gehen Sie also bitte hin und her. Es tut mir leid, wenn meine theoretische Zusammenfassung einfach nicht gut ist. Zumindest sollten einige Teile fehlen. Wenn Sie also besser lernen möchten, sollten Sie einige andere Bücher ausprobieren.
Diesmal ist es wirklich das Ende der Theorie. Fahren wir mit dem Code ↓ ↓ fort
3. Implementierung
Dann werde ich immer mehr Code einfügen. Wenn Sie es von oben anbringen, ist es möglicherweise möglich, es zu reproduzieren (obwohl es nicht möglich ist, genau das gleiche Ergebnis zu erzielen, da es voller Codes mit Zufallszahlen ist). Bitte verzeihen Sie mir auch, wenn Sie an verschiedenen Stellen unschönen Code sehen können.
Derzeit werden hier nur die Elemente eingefügt, die importiert werden sollen. Bitte machen Sie alle folgenden Codes unter dieser Annahme. (Bitte beachten Sie, dass es tatsächlich unnötige Module enthalten kann)
2048.py
import numpy as np
import copy, random, time
from tensorflow.keras import layers, models
from IPython.display import clear_output
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib
matplotlib.rcParams['font.size'] = 20
import pickle
from tensorflow.keras.models import load_model
3-1. Definition der Spielklasse
Implementieren Sie zunächst 2048 Spiele im Code. Es ist lang, aber der Inhalt ist dünn, also schauen Sie es sich bitte mit dieser Absicht an. Es ist nicht auf diesen Code beschränkt, aber es ist möglicherweise besser, ihn anzusehen, da er am Ende einen japanischen Kommentar enthält. Dann.
2048.py
class Game:
def __init__(self):
self.restart()
def restart(self):
self.board = np.zeros([4,4])
self.score = 0
y = np.random.randint(0,4)
x = np.random.randint(0,4)
self.board[y][x] = 2
while(True):
y = np.random.randint(0,4)
x = np.random.randint(0,4)
if self.board[y][x]==0:
self.board[y][x] = 2
break
def move(self, a):
reward = 0
if a==0:
for y in range(4):
z_cnt = 0
prev = -1
for x in range(4):
if self.board[y][x]==0: z_cnt += 1
elif self.board[y][x]!=prev:
tmp = self.board[y][x]
self.board[y][x] = 0
self.board[y][x-z_cnt] = tmp
prev = tmp
else:
z_cnt += 1
self.board[y][x-z_cnt] *=2
reward += self.board[y][x-z_cnt]
self.score += self.board[y][x-z_cnt]
self.board[y][x] = 0
prev = -1
elif a==1:
for x in range(4):
z_cnt = 0
prev = -1
for y in range(4):
if self.board[y][x]==0: z_cnt += 1
elif self.board[y][x]!=prev:
tmp = self.board[y][x]
self.board[y][x] = 0
self.board[y-z_cnt][x] = tmp
prev = tmp
else:
z_cnt += 1
self.board[y-z_cnt][x] *= 2
reward += self.board[y-z_cnt][x]
self.score += self.board[y-z_cnt][x]
self.board[y][x] = 0
prev = -1
elif a==2:
for y in range(4):
z_cnt = 0
prev = -1
for x in range(4):
if self.board[y][3-x]==0: z_cnt += 1
elif self.board[y][3-x]!=prev:
tmp = self.board[y][3-x]
self.board[y][3-x] = 0
self.board[y][3-x+z_cnt] = tmp
prev = tmp
else:
z_cnt += 1
self.board[y][3-x+z_cnt] *= 2
reward += self.board[y][3-x+z_cnt]
self.score += self.board[y][3-x+z_cnt]
self.board[y][3-x] = 0
prev = -1
elif a==3:
for x in range(4):
z_cnt = 0
prev = -1
for y in range(4):
if self.board[3-y][x]==0: z_cnt += 1
elif self.board[3-y][x]!=prev:
tmp = self.board[3-y][x]
self.board[3-y][x] = 0
self.board[3-y+z_cnt][x] = tmp
prev = tmp
else:
z_cnt += 1
self.board[3-y+z_cnt][x] *= 2
reward += self.board[3-y+z_cnt][x]
self.score += self.board[3-y+z_cnt][x]
self.board[3-y][x] = 0
prev = -1
while(True):
y = np.random.randint(0,4)
x = np.random.randint(0,4)
if self.board[y][x]==0:
if np.random.random() < 0.2: self.board[y][x] = 4
else: self.board[y][x] = 2
break
return reward
Ich beschloss, die Spielklasse "Brett" und "Punktzahl" verwalten zu lassen. Wie der Name schon sagt, ist es das Board und die aktuelle Punktzahl. Die Karte wird durch ein zweidimensionales Numpy-Array dargestellt.
Bei der "Neustart" -Methode werden Kacheln mit "2" an zwei zufälligen Stellen auf dem Brett platziert, die Punktzahl auf 0 gesetzt und das Spiel gestartet. (In der Erläuterung der Regeln in Kapitel 1 habe ich gesagt, dass "2" oder "4" auf der ersten Tafel platziert ist, aber nur "2" im Code erscheint. Zu diesem Zeitpunkt habe ich die Spielklasse implementiert. Zuerst habe ich falsch verstanden, dass es nur "2" war. Bitte vergib es, weil es fast keine Auswirkungen auf das Spiel hat.)
Die "move" -Methode nimmt die Art der Aktion als Argument, ändert die Tafel entsprechend und addiert die Punktzahl. Als Rückgabewert wird die in dieser einen Runde hinzugefügte Punktzahl zurückgegeben, die später verwendet wird. (In dieser Studie wurde die Punktzahl im Spiel als "Belohnung" verwendet, die der Agent erhält.) Aktionen werden durch Ganzzahlen von 0 bis 3 dargestellt und jeweils mit links, oben, rechts und unten verknüpft. Die Implementierung von Board-Änderungen ist ein nutzlos langes Indexkneten, wahrscheinlich weniger lesbar. Sie müssen es nicht ernsthaft lesen. Es mag möglich sein, schöner zu schreiben, aber bitte vergib mir hier (´ × ω × `)
Außerdem wird in der letzten while-Schleife eine neue Kachel generiert. Dies mag auch eine ineffiziente Implementierung in Bezug auf den Algorithmus sein, aber ich habe sie gewaltsam getroffen. Ich bereue es. Eine Kachel mit "2" oder "4" wird generiert, aber aufgrund der Lichtstatistik des Autors ging es um "2 wird mit einer Wahrscheinlichkeit von 80% auftauchen", also habe ich es so implementiert. Eigentlich mag es ein bisschen anders sein, aber diesmal werden wir es tun.
Beachten Sie, dass die Methode "Verschieben" davon ausgeht, dass eine "auswählbare" Aktion eingegeben wird. (Da die Richtung, in die sich das Brett nicht bewegt, während des Spiels nicht ausgewählt werden kann.) Verwenden Sie dazu die folgende Funktion.
3-2. Beurteilung auswählbarer Aktionen
In Zukunft wird es viele Situationen geben, in denen Sie wissen möchten, ob jede Aktion auf jeder Karte "auswählbar" ist, z. B. bei der Eingabe in die oben beschriebene "Verschieben" -Methode. Daher haben wir "is_invalid_action" als Beurteilungsfunktion vorbereitet. Beachten Sie, dass es das Board und die Aktion gibt und ** True zurückgibt, wenn es sich um eine Aktion handelt, die nicht ausgewählt werden kann **.
Außerdem ist dieser Code der Methode "Verschieben" sehr ähnlich und nur nutzlos lang, sodass er in die Dreiecksmarkierung darunter gefaltet wird. Bitte schließen Sie es, sobald Sie den Inhalt kopieren. Weil es nicht gut ist.
`is_invalid_action`
2048.py
def is_invalid_action(state, a):
spare = copy.deepcopy(state)
if a==0:
for y in range(4):
z_cnt = 0
prev = -1
for x in range(4):
if spare[y][x]==0: z_cnt += 1
elif spare[y][x]!=prev:
tmp = spare[y][x]
spare[y][x] = 0
spare[y][x-z_cnt] = tmp
prev = tmp
else:
z_cnt += 1
spare[y][x-z_cnt] *= 2
spare[y][x] = 0
prev = -1
elif a==1:
for x in range(4):
z_cnt = 0
prev = -1
for y in range(4):
if spare[y][x]==0: z_cnt += 1
elif spare[y][x]!=prev:
tmp = spare[y][x]
spare[y][x] = 0
spare[y-z_cnt][x] = tmp
prev = tmp
else:
z_cnt += 1
spare[y-z_cnt][x] *= 2
spare[y][x] = 0
prev = -1
elif a==2:
for y in range(4):
z_cnt = 0
prev = -1
for x in range(4):
if spare[y][3-x]==0: z_cnt += 1
elif spare[y][3-x]!=prev:
tmp = spare[y][3-x]
spare[y][3-x] = 0
spare[y][3-x+z_cnt] = tmp
prev = tmp
else:
z_cnt += 1
spare[y][3-x+z_cnt] *= 2
spare[y][3-x] = 0
prev = -1
elif a==3:
for x in range(4):
z_cnt = 0
prev = -1
for y in range(4):
if spare[3-y][x]==0: z_cnt += 1
elif spare[3-y][x]!=prev:
tmp = state[3-y][x]
spare[3-y][x] = 0
spare[3-y+z_cnt][x] = tmp
prev = tmp
else:
z_cnt += 1
spare[3-y+z_cnt][x] *= 2
spare[3-y][x] = 0
prev = -1
if state==spare: return True
else: return False
3-3. Visualisierung der Plattenoberfläche
KI kann problemlos lernen, auch wenn es keine Funktion gibt, das Board zu zeigen, aber wir haben es geschafft, weil wir Menschen einsam sind. Da das Hauptthema jedoch nicht hier ist, lasse ich die Entschuldigung ganz aus.
2048.py
def show_board(game):
fig = plt.figure(figsize=(4,4))
subplot = fig.add_subplot(1,1,1)
board = game.board
score = game.score
result = np.zeros([4,4])
for x in range(4):
for y in range(4):
result[y][x] = board[y][x]
sns.heatmap(result, square=True, cbar=False, annot=True, linewidth=2, xticklabels=False, yticklabels=False, vmax=512, vmin=0, fmt='.5g', cmap='prism_r', ax=subplot).set_title('2048 game!')
plt.show()
print('score: {0:.0f}'.format(score))
Ich habe nur die minimalen Funktionen mit der Heatmap reproduziert (wirklich das Minimum). Sie müssen die Details dazu nicht lesen, ich denke, Sie können einfach den Hirntod kopieren. So sieht es tatsächlich aus.
3-4. Spielen
Wenn Sie nur lernen möchten, ist dieser Schritt völlig unnötig, aber da es eine große Sache ist, lassen Sie uns das Spiel Python Version 2048 spielen, also habe ich eine solche Funktion geschrieben. Das ist auch ziemlich schlampig und man muss es nicht ernsthaft lesen. Wenn Sie Ihr Bestes geben, können Sie die Benutzeroberfläche so komfortabel gestalten, wie Sie möchten, aber es ist nicht das Hauptthema, also werde ich es verlassen.
2048.py
def human_play():
game = Game()
show_board(game)
while True:
a = int(input())
if(is_invalid_action(game.board.tolist(),a)):
print('cannot move!')
continue
r = game.move(a)
clear_output(wait=True)
show_board(game)
Wenn Sie nun "human_play ()" ausführen, wird das Spiel gestartet. Geben Sie eine Zahl von 0 bis 3 ein, um das Brett zu verschieben.
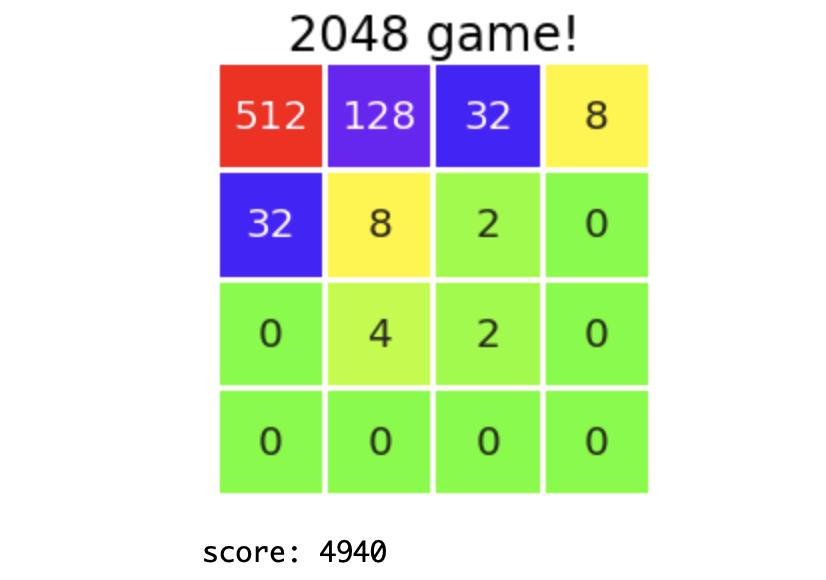
Das Brett erscheint so und Sie können spielen. Immerhin ist es schwer, die Tafel zu sehen. Mit diesem Code ist das Spiel übrigens beendet, sobald Sie versehentlich etwas anderes als eine Zahl eingeben, ohne dass Fragen gestellt werden. Ich kenne die Benutzeroberfläche nicht. Da dies kein Urteil über das Spielende enthält, können Sie das Spiel verlassen, indem Sie seltsame Eingaben vornehmen, indem Sie die vorherigen Spezifikationen nutzen. Ich kenne die Benutzeroberfläche nicht.
Lassen wir den Computer dieses Spiel zu diesem Zeitpunkt spielen.
2048.py
def random_play(random_scores):
game = Game()
show_board(game)
gameover = False
while(not gameover):
a_map = [0,1,2,3]
is_invalid = True
while(is_invalid):
a = np.random.choice(a_map)
if(is_invalid_action(game.board.tolist(),a)):
a_map.remove(a)
if(len(a_map)==0):
gameover = True
is_invalid = False
else:
r = game.move(a)
is_invalid = False
time.sleep(1)
clear_output(wait=True)
show_board(game)
random_scores.append(game.score)
Ich habe dir gesagt, du sollst den Computer spielen lassen, aber es ist eine Funktion, mit der du sehen kannst, was passiert, wenn du eine Hand völlig zufällig auswählst. Nehmen Sie ein geeignetes Array als Argument (versteckte Linie). Dieses Argument spielt für die Anzeige keine Rolle. Führen Sie es daher wie "random_play ([])" entsprechend aus. Das Spiel verläuft wie eine Animation.
Wie Sie aus der Ansicht sehen können, gibt es zu diesem Zeitpunkt kein Gefühl, mit dem Willen zu spielen (natürlich, weil er zufällig ist). Lassen Sie uns daher an dieser Stelle die Fähigkeit (durchschnittliche Punktzahl usw.) erfassen. Ich habe ein Array als Argument genommen, um dies zu tun. Kommentieren Sie in der Funktion random_play den Code für die Board-Visualisierung aus (3. Zeile von oben und 2. bis 4. Zeile von unten) und führen Sie dann den folgenden Code aus.
2048.py
random_scores = []
for i in range(1000):
random_play(random_scores)
print(np.array(random_scores).mean())
print(np.array(random_scores).max())
print(np.array(random_scores).min())
Ich habe 1000 Mal ein Testspiel gemacht und die durchschnittliche Punktzahl, die höchste Punktzahl und die niedrigste Punktzahl überprüft. Die Ausführung endet unerwartet bald. Das Ergebnis wird sich je nach Ausführung leicht ändern, aber in meinen Händen
- Durchschnittliche Punktzahl: ** 1004.676 Punkte **
- Höchste Punktzahl: ** 2832 Punkte **
- Niedrigste Punktzahl: ** 80 Punkte **
Ich habe das Ergebnis. Man kann sagen, dass dies die Kraft der KI ist, die nichts gelernt hat. Wenn Sie also im Durchschnitt weit über 1000 Punkte erreichen, können Sie sagen, dass Sie ein wenig gelernt haben. Da die höchste Punktzahl von 1000 Spielen ungefähr auf diesem Niveau liegt, denke ich, dass das Überschreiten von 3000 Punkten ein Bereich ist, der allein mit Glück nur schwer zu erreichen ist. Betrachten wir die späteren Lernergebnisse, die auf diesem Bereich basieren.
3-5 Erstellen eines neuronalen Netzwerks
Hier implementieren wir ein neuronales Netzwerk, das die Person ist, die den Wert der Verhaltenszustandswertfunktion berechnet und auch die gesammelten Daten zum Lernen empfängt. All dieser problematische Teil hat jedoch die Form eines runden Einwurfs in ** TensorFlow **, sodass Sie sich die Black Box als Black Box vorstellen können. Halten Sie vorerst den Code fest.
2048.py
class QValue:
def __init__(self):
self.model = self.build_model()
def build_model(self):
cnn_input = layers.Input(shape=(4,4,1))
cnn = layers.Conv2D(8, (3,3), padding='same', use_bias=True, activation='relu')(cnn_input)
cnn_flatten = layers.Flatten()(cnn)
action_input = layers.Input(shape=(4,))
combined = layers.concatenate([cnn_flatten, action_input])
hidden1 = layers.Dense(2048, activation='relu')(combined)
hidden2 = layers.Dense(1024, activation='relu')(hidden1)
q_value = layers.Dense(1)(hidden2)
model = models.Model(inputs=[cnn_input, action_input], outputs=q_value)
model.compile(loss='mse')
return model
def get_action(self, state):
states = []
actions = []
for a in range(4):
states.append(np.array(state))
action_onehot = np.zeros(4)
action_onehot[a] = 1
actions.append(action_onehot)
q_values = self.model.predict([np.array(states), np.array(actions)])
times = 0
first_a= np.argmax(q_values)
while(True):
optimal_action = np.argmax(q_values)
if(is_invalid_action(state, optimal_action)):
q_values[optimal_action][0] = -10**10
times += 1
else: break
if times==4:
return first_a, 0, True #gameover
return optimal_action, q_values[optimal_action][0], False #not gameover
Es ist in Form der Klasse "QValue" implementiert. Diese Instanz wird selbst zum Lernziel (genauer gesagt zur Mitgliedsvariablen "Modell"). Und die Methode "build_model" in der ersten Hälfte ist eine Funktion, die zum Zeitpunkt der Instanziierung ausgeführt wird und ein neuronales Netzwerk erstellt.
Ich werde einen Überblick über die Methode "build_model" geben, aber ich werde nicht jede "NN-Sprache" im Detail erklären. Hmmm, ich denke es ist okay. Ich denke, dass diejenigen, die sich auskennen, lesenswert sind. (Gleichzeitig gibt es möglicherweise Raum für Verbesserungen. Bitte bringen Sie mir bei ...)
Ich werde das Convolutional Neural Network (CNN) verwenden, über das ich im theoretischen Teil gesprochen habe. Dies liegt daran, dass ich erwartet hatte, die zweidimensionale Ausdehnung der Platine zu erfassen. Als Eingabe nehmen wir ein 4x4-Array, das der Platinenoberfläche entspricht, und ein Array mit der Länge 4, das der Auswahl der Aktionen entspricht. Die Aktionsauswahl erfolgt durch ** One-Hot-Codierung **, bei der eine der vier Positionen durch ein Array von 1 und der Rest durch ein Array von 0 dargestellt wird, anstatt 0 bis 3 einzugeben. Zum Falten werden acht Arten von 3x3-Filtern verwendet. Außerdem werden die Auffüll-, Vorspannungs- und Aktivierungsfunktion angegeben. Als verborgene Schichten haben wir eine Schicht mit 2048 Neuronen und eine Schicht mit 1024 Neuronen vorbereitet und schließlich die Ausgabeschicht definiert. ReLU wird als Aktivierungsfunktion der verborgenen Schicht verwendet. Zusätzlich wird der minimale quadratische Fehler als Fehlerfunktion für die Parametereinstellung übernommen.
Die Erklärung zu NN ist hier zusammengefasst. Selbst wenn Sie überhaupt nicht verstehen, ist es in Ordnung, wenn Sie nur denken, dass Sie NN definiert haben, obwohl Sie den Inhalt nicht kennen.
Es gibt eine andere Methode namens "get_action". Dies entspricht dem Schritt "Berechnen des Wertes der Aktionszustandswertfunktion mit einem neuronalen Netzwerk". Nehmen Sie den Board-Status "state" als Argument, bereiten Sie One-Hot-Ausdrücke für vier Arten von Aktionen vor und fügen Sie vier Eingaben in das NN ein. Dieses Eindringen kann mit der "Vorhersage" -Methode erfolgen, die ursprünglich von Tensorflow bereitgestellt wurde. Als Ausgabe von NN wird der Wert der Aktionsstatuswertfunktion für vier Arten von Aktionen im Status zurückgegeben. Die allgemeine Rolle dieser Methode besteht darin, die Aktion mit dem größten Wert mit der Funktion np.argmax abzurufen.
Ich vermassle es in der zweiten Hälfte, aber dies prüft, ob die aus dem Wert der Aktionsstatuswertfunktion ausgewählte Aktion auf der Platine ausgewählt (beweglich) werden kann. Wenn dies nicht möglich ist, wählen Sie die Aktion erneut aus, die den Wert der Aktionsstatuswertfunktion erhöht. Darüber hinaus stellt diese Methode fest, dass das Spiel beendet ist. Es gibt drei Rückgabewerte für die Methode "get_action", aber in dieser Reihenfolge "die ausgewählte Aktion, die Aktion für dieses Brett / diese Aktion - den Wert der Statuswertfunktion und ob das Brett das Spiel beendet hat oder nicht".
3-6. Spielen Sie das Spiel basierend auf dem Lernen
Ich habe versucht, es früher ganz zufällig zu spielen, aber dieses Mal werde ich es spielen, indem ich die Lernergebnisse einbeziehe. Die folgende Funktion "get_episode" spielt ein Spiel. (Beim Verstärkungslernen wird ein Spiel oft als ** Episode ** bezeichnet.)
2048.py
def get_episode(game, q_value, epsilon):
episode = []
game.restart()
while(True):
state = game.board.tolist()
if np.random.random() < epsilon:
a = np.random.randint(4)
gameover = False
if(is_invalid_action(state, a)):
continue
else:
a, _, gameover = q_value.get_action(state)
if gameover:
state_new = None
r = 0
else:
r = game.move(a)
state_new = game.board.tolist()
episode.append((state, a, r, state_new))
if gameover: break
return episode
Bereiten Sie ein Array mit dem Namen "Episode" vor, spielen Sie ein Spiel, erstellen Sie einen Satz "Aktueller Status, ausgewählte Aktion, zu diesem Zeitpunkt erhaltene Belohnung, Status des Übergangsziels" und speichern Sie ihn kontinuierlich im Array. Das ist die Grundoperation. Die hier gesammelten Daten werden für die spätere Lernverarbeitung verwendet. Verwenden Sie zum Auswählen einer Aktion die zuvor definierte Methode q_value.get_action. Dadurch wird der beste Zug vor Ort ausgewählt (und mit Ihren aktuellen Fähigkeiten). Darüber hinaus wird das Ende der Episode erkannt, indem das Spiel über die mit dieser Methode durchgeführte Beurteilung verwendet wird.
Eine Sache zu beachten ist, dass "es nicht immer den Lernergebnissen in jeder Runde folgt." Die Funktion "get_episode" verwendet das Argument "epsilon", dh die "Wahrscheinlichkeit, eine Aktion während des Spiels zufällig auszuwählen, ohne dem Lernergebnis zu folgen". Durch Mischen zufälliger Aktionsauswahlen können Sie verschiedene Boards lernen und erwarten, eine intelligentere KI zu werden.
Auf diese Weise wird die Aktionsrichtlinie, die "im Grunde eine Aktion mit der Greedy-Richtlinie auswählt, aber zufällige Aktionen mit einer Wahrscheinlichkeit von $ \ epsilon $ mischt", als ** ε-Greedy-Richtlinie ** bezeichnet. Wie viel der Wert von ε eingestellt werden muss, ist ein wichtiges und schwieriges Thema. (Normalerweise sind es ungefähr 0,1 bis 0,2.)
Diese Funktion kann auch mit der Greedy-Richtlinie gespielt werden, indem "epsilon = 0" gesetzt wird. Mit anderen Worten, es ist ein Spiel der "vollen Kraft der KI" zu dieser Zeit, ohne zufällige Aktionen. Die Funktion show_sample zum Messen der Fähigkeit von AI-kun ist unten gezeigt.
2048.py
def show_sample(game, q_value):
epi = get_episode(game, q_value, epsilon=0)
n = len(epi)
game = Game()
game.board = epi[0][0]
# show_board(game)
for i in range(1,n):
game.board = epi[i][0]
game.score += epi[i-1][2]
# time.sleep(0.2)
# clear_output(wait=True)
# show_board(game)
return game.score
Die Grundvoraussetzung besteht jedoch darin, die Funktion "get_episode" unter "epsilon = 0" auszuführen. Danach wird die Karte mithilfe der Episodenaufzeichnung reproduziert. Es ist, als würde man der Schachpartitur im Shogi folgen. Es gibt einen auskommentierten Teil in der Funktion, aber wenn Sie dies abbrechen, können Sie es mit Animation sehen. (Wie bei der Funktion random_play können Sie die Geschwindigkeit der Animation steuern, indem Sie den Wert für "time.sleep" anpassen.) Die endgültige Punktzahl wird als Rückgabewert ausgegeben. Auf diese Weise können Sie das Lernergebnis grob erfassen, indem Sie zwischen den Lernprozessen "show_sample" einfügen.
Jetzt implementieren wir den Lernalgorithmus!
3-7. Lernprozess
Definieren Sie eine Funktion "Zug", die NN trainiert. Es ist etwas lang, aber nicht so schwierig. Bitte lesen Sie es ruhig. Ich werde es ein wenig sorgfältig erklären.
2048.py
def train(game, q_value, num, experience, scores):
for c in range(num):
print()
print('Iteration {}'.format(c+1))
print('Collecting data', end='')
for n in range(20):
print('.', end='')
if n%10==0: epsilon = 0
else: epsilon = 0.1
episode = get_episode(game, q_value, epsilon)
experience += episode
if len(experience) > 50000:
experience = experience[-50000:]
if len(experience) < 5000:
continue
print()
print('Training the model...')
examples = experience[-1000:] + random.sample(experience[:-1000], 2000)
np.random.shuffle(examples)
states, actions, labels = [], [], []
for state, a, r, state_new in examples:
states.append(np.array(state))
action_onehot = np.zeros(4)
action_onehot[a] = 1
actions.append(action_onehot)
if not state_new:
q_new = 0
else:
_1, q_new, _2 = q_value.get_action(state_new)
labels.append(np.array(r+q_new))
q_value.model.fit([np.array(states), np.array(actions)], np.array(labels), batch_size=250, epochs=100, verbose=0)
score = show_sample(game, q_value)
scores.append(score)
print('score: {:.0f}'.format(score))
Es gibt 5 Argumente, um "Spielklasseninstanz" Spiel ", zu trainierendes Modell (QValue-Instanz)" q_value ", Anzahl der zu lernenden" num ", Array zum Speichern der gesammelten Daten" Erfahrung ", Lernergebnis Es ist ein Array "Scores" zu setzen (Scores). Follow-up für Details.
Die Schleife wird um den Betrag von "num" gedreht. Hier unterscheidet sich "einmaliges Lernen" völlig vom einmaligen Spielen. Ich werde den Ablauf eines Lernens erklären.
Das Lernen ist in zwei Schritte unterteilt: Sammeln von Daten und Aktualisieren von NN. Im Datenerfassungsteil wird die Funktion "get_episode" 20 Mal aktiviert (kurz gesagt, das Spiel wird 20 Mal gespielt). Grundsätzlich werden Daten durch die ε-Greedy-Richtlinie von ε = 0,1 erfasst, aber nur zweimal von 20 Spielen mit der Greedy-Richtlinie (ε = 0), die keine zufälligen Aktionen mischt und die Daten erfasst. Wenn Sie die beiden Spielarten auf diese Weise mischen, scheint es einfacher zu sein, eine Vielzahl von Brettern zu lernen und das Brett zu integrieren, wenn das Spiel lange Zeit andauert.
Alle gesammelten Daten werden in "Erfahrung" gebracht. Wenn die Länge dieses Arrays 50000 überschreitet, werden die ältesten Daten gelöscht. Der nächste Modellaktualisierungsschritt wird übersprungen, bis 5000 Daten erfasst sind.
Um das Modell zu aktualisieren, extrahieren Sie Daten aus "Erfahrung" und erstellen Sie ein neues "Beispiel" -Array. Zu diesem Zeitpunkt werden 1000 Teile aus den neuesten Daten ausgewählt und 2000 Teile werden zufällig aus dem verbleibenden Teil ausgewählt und gemischt. Auf diese Weise scheint es weniger wahrscheinlich zu sein, dass die Lernergebnisse verzerrt sind, während neue Daten in das Lernen einbezogen werden.
In der nächsten for-Anweisung werden wir uns den Inhalt von "Beispiel" einzeln ansehen. Da es in Bezug auf die Berechnungsgeschwindigkeit effizienter ist, NNs gemeinsam einzugeben, als einzelne Daten zu empfangen, werden wir uns darauf vorbereiten. Geben Sie unter "Zustände", "Aktionen" und "Beschriftungen" die Karte des aktuellen Status, den One-Hot-Ausdruck der auszuwählenden Aktion und den Wert der "richtigen Antwort" der Aktionsstatus-Wertfunktion zu diesem Zeitpunkt ein.
In Bezug auf den Wert der richtigen Antwort wird dies als $ r + q_ {\ pi} (s ', \ pi (s')) $ festgelegt, wie in der Theorie-Ausgabe "2-2-3. TD-Methode" erläutert. Auf diese Weise wird die Ausgabe von NN so geändert, dass sie sich hier nähert. Dies entspricht "r + q_new" im Code. "q_new" ist der "erwartete Wert der Belohnung, der erhalten wird, wenn Sie die ganze Zeit gemäß der aktuellen Richtlinie aus dem Übergangszielstatus handeln", und dies ist der zweite Status, wenn der nächste Status an die "q_value.get_action" -Methode übergeben wird. Da es der Ausgabe entspricht (dem nächsten Zustand und der Aktion für die beste Bewegung dorthin - dem Wert der Zustandswertfunktion), wird es als solcher erfasst. Außerdem wird "q_new" für den Spielübergangsstatus auf 0 gesetzt.
NN trainiert mit der folgenden Methode "q_value.model.fit". Bitte lassen Sie diesen Inhalt separat. Die NN-Eingaben "Zustände" und "Aktionen" werden als Argumente angegeben, und "Bezeichnungen" werden als korrekter Antwortwert angegeben. Sie müssen sich keine Gedanken über "batch_size" und "epochs" machen, aber das Festlegen dieser Werte wirkt sich auf die Genauigkeit Ihres Lernens aus (ich bin nicht ganz sicher, ob dies die richtige Einstellung ist). verbose = 0 unterdrückt nur unnötige Protokollausgaben.
Nachdem der Lernprozess mit der Methode "fit" abgeschlossen ist, starten Sie die Funktion "show_sample" und lassen Sie AI mit aller Kraft spielen. Während der Ausgabe der endgültigen Punktzahl als Protokoll wird diese im Array "Scores" gespeichert und später zur Berechnung der durchschnittlichen Punktzahl verwendet. Das Obige ist das ganze Bild von "einem Lernen". Die Funktion "Zug" wiederholt dies.
Ergänzung zu `batch_size` und` epochs` Ich sagte, dass Sie sich darüber keine Sorgen machen müssen, aber ich denke, es lohnt sich, nur die Umrisse zu kennen, also werde ich sie leicht organisieren. Beim NN-Lernen werden die Eingabedaten nicht auf einmal gelernt, sondern in kleine Abschnitte unterteilt, die als "Mini-Batch" bezeichnet werden. Anschließend wird jeder Batch gelernt. Die Größe dieses Stapels ist "batch_size". Im obigen Code beträgt die Eingabegröße 3000 und batch_size 250, sodass sie in 12 Mini-Batchs unterteilt ist. Dann wird die einmalige Durchführung des Lernprozesses für alle Eingabedaten in der Einheit ** Epoche ** gezählt. Im obigen Code ergeben 3000 Eingaben und 12 Stapel 1 Epoche. Der Parameter "Epochen" gibt an, wie viele Epochen der Lernprozess wiederholt werden soll. Da hier Epochen = 100 eingestellt sind, wird der Ablauf der Chargenteilung → Lernen über alles 100 Mal wiederholt. Es ist eine grobe Zusammenfassung, aber neuronale Netze sind schwierig \ (^^) /
4. Ausführung und Beobachtung lernen
Dies ist das Ende der Implementierung des Modells / der Funktion. Lassen Sie uns danach tatsächlich lernen und sehen, wie es wächst! Ich schreibe auch leicht Artikel ...
Achtung: Zu den hier gezeigten Lernergebnissen Es ist, als ob der von Ihnen ausgeführte Code und das Ergebnis unverändert im Artikel veröffentlicht werden. In Wirklichkeit ist der Lernprozess jedoch teilweise anders, da Sie mit dem Lernen fortgefahren sind, während Sie damit gespielt und ihn geändert haben. (Insbesondere wurden die Daten für die ersten 30 Male mit ε = 0,2 gesammelt, und in den alten Tagen waren die Spezifikationen der Methode "get_action" geringfügig unterschiedlich. Die Daten können in der Mitte weggeblasen werden.) Bitte beachten Sie das nur. Darüber hinaus wird die unmittelbar danach angezeigte Ausgabe von 10 Lernzeiten durch eine spätere erneute Ausführung des Codes ergänzt (die Ausgabe zu diesem Zeitpunkt wurde weggeblasen) und unterscheidet sich von der Lernaufzeichnung des Modells, die in Zukunft berücksichtigt werden soll. .. Schauen Sie nicht genauer hin> <
4-1. Versuchen Sie es mit dem Zug
Erstellen Sie zunächst eine Instanz der Klasse "Game" und der Klasse "QValue" und anderer.
2048.py
game1 = Game()
q_value1 = QValue()
exp1 = []
scores1 = []
Die Nummerierung 1 hat keine besondere Bedeutung. Irgendwie. Damit ist die Vorbereitung auf das Lernen abgeschlossen. Beginnen wir mit der Funktion "Zug".
2048.py
%%time
train(game1, q_value1, 10, exp1, scores1)
Nur das. Dies wird 10 Lernsitzungen machen. Die "%% Zeit" in der ersten Zeile ist wie ein magischer Befehl und misst die Zeit, die zur Ausführung benötigt wird. Der Grund dafür ist, dass das Lernen viel Zeit in Anspruch nimmt. Nur für diese 10 Male dauert es ungefähr 30 Minuten. Da jedoch die "Zug" -Funktion so implementiert ist, dass der Fortschrittsstatus jederzeit ausgegeben wird, ist es einfacher, als durch die unsichtbare Dunkelheit zu gehen. Werfen wir einen Blick auf die Ausgabe.
Iteration 1
Collecting data....................
Iteration 2
Collecting data....................
Iteration 3
Collecting data....................
Training the model...
score: 716
Iteration 4
Collecting data....................
Training the model...
score: 908
Iteration 5
Collecting data....................
Training the model...
score: 596
...
Wie bei "Iteration 3" können Sie sofort sehen, wie viele Schleifen Sie gerade durchlaufen. Der Datenerfassungsteil wird angezeigt, während "Datenerfassung ..." angezeigt wird, und der Modellaktualisierungsteil wird angezeigt, während "Training des Modells ..." angezeigt wird. In den ersten beiden Fällen hat die Länge von "exp1" nicht 5000 erreicht und das Modellupdate wird übersprungen.
Nach jedem Lernen wird ein Spiel ohne zufällige Aktion gespielt und die Punktzahl angezeigt. Dieses Ergebnis wird in "Scores1" gespeichert, sodass Sie später Statistiken sammeln können.
Alles was Sie tun müssen, ist dies zu wiederholen. Führen Sie den folgenden Code aus, um weitere 90 Lernvorgänge durchzuführen.
2048.py
%%time
train(game1, q_value1, 90, exp1, scores1)
exp1 und score1 werden wiederverwendet und das Lernen wird vollständig von der vorherigen Fortsetzung fortgesetzt.
Wie Sie sehen können, braucht dieses Lernen wirklich Zeit. In meiner Umgebung scheint es 5 bis 6 Stunden pro 100 Mal zu sein. Vor kurzem stöhnte Mac-kun die ganze Nacht, während ich schlief. Wenn Sie interessiert sind, können Sie die gleiche Erfahrung machen, indem Sie Zeit finden und mit der Berechnung fortfahren.
Unter der Annahme, dass 100 Lernvorgänge abgeschlossen wurden, lassen Sie uns die Änderungen in der "vollen Leistungsbewertung" während dieses Zeitraums grob darstellen. Verwenden Sie "Scores1".
2048.py
x = np.arange(len(scores1))
plt.plot(x, scores1)
plt.show()
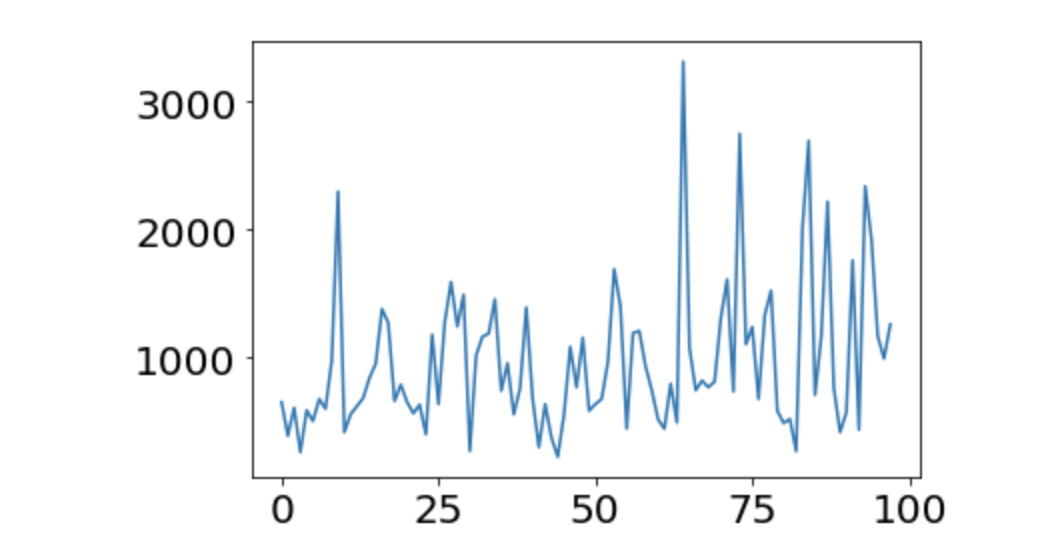
Hmm. Es ist schwer zu sagen, dass dies ein wenig gelernt ist. Die durchschnittliche Punktzahl betrug 974,45. Es wächst überhaupt nicht. Es scheint, dass etwas mehr Lernen erforderlich ist.
4-2. Speichern Sie die Lernergebnisse vorübergehend
Dieses Lernen ist wahrscheinlich ein langer Weg, also lassen Sie uns nur die Konservierungsmethode festlegen. Sie können "exp1" und "Scores1" mit der ** pickle ** -Funktion von Python speichern. Pickle kann nicht für das Tensorflow-Modell verwendet werden, aber die Speicherfunktion ist ursprünglich vorgesehen. Der Code wird unten angezeigt. Speichern Sie ihn daher unter einem aussagekräftigen Namen.
2048.py
wfile = open('filename1.pickle', 'wb')
pickle.dump(exp1, wfile)
pickle.dump(scores1, wfile)
wfile.close()
q_value1.model.save('q_backup.h5')
Gehen Sie wie folgt vor, um das gespeicherte Objekt abzurufen.
2048.py
myfile = open('filename1.pickle', 'rb')
exp1_r = pickle.load(myfile)
scores1_r = pickle.load(myfile)
q_value1_r = QValue()
q_value1_r.model = load_model('q_backup.h5')
Das r nach dem Namen soll ein Akronym für Wiederherstellung sein. q_value1 speichert das Modell darin, nicht die QValue-Instanz. Nachdem Sie also nur die Instanz erstellt haben, laden Sie das Modell und ersetzen Sie es. Da die Instanz der Spielklasse nicht speziell erlernt wurde, ist es kein Problem, wenn Sie bei Bedarf eine neue erstellen.
Es wird empfohlen, das Lernen so sorgfältig aufzuzeichnen. Dies kann nicht nur eine Gegenmaßnahme sein, wenn Daten in der Mitte fliegen, sondern es ist auch möglich, das Modell später mitten im Lernen zu ziehen und die Leistung zu vergleichen. (Ich bedauere, dies nicht getan zu haben.)
4-3 Zug wiederholen
Ich hatte das Gefühl, dass das 100-mal trainierte Modell noch unerfahren war, also habe ich einfach die "Zug" -Funktion gedreht. Aus dem Fazit ließ ich sie 1500 Mal lernen. Es dauert ungefähr 4 Tage, auch ohne Unterbrechung. Seien Sie also vorbereitet, wenn Sie nachahmen möchten ...
Zur Zeit habe ich 1500 Mal "Scores" leicht analysiert. Die Bewertungen wurden jeweils 100 Mal gelernt, und das Bewertungsband wurde durch 1000 Punkte geteilt, und die Tabelle zeigt, ob die Bewertungen für jedes Bewertungsband erhalten wurden. Ich habe auch die durchschnittliche Punktzahl berechnet, also werde ich sie arrangieren. Es ist nicht leicht in Worten zu erklären, also werde ich den Tisch kleben. (Als Referenz werde ich auch die Punkteverteilung von Tokizoyas völlig zufälligen 1000 Spielen veröffentlichen.)
| Anzahl des Lernens | 0000~ | 1000~ | 2000~ | 3000~ | 4000~ | 5000~ | average |
|---|---|---|---|---|---|---|---|
| zufällig | 529 | 415 | 56 | 0 | 0 | 0 | 1004.68 |
| 1~100 | 61 | 30 | 6 | 1 | 0 | 0 | 974.45 |
| 101~200 | 44 | 40 | 9 | 6 | 1 | 0 | 1330.84 |
| 201~300 | 33 | 52 | 12 | 1 | 0 | 0 | 1234.00 |
| 301~400 | 35 | 38 | 18 | 7 | 2 | 0 | 1538.40 |
| 401~500 | 27 | 52 | 18 | 3 | 0 | 0 | 1467.12 |
| 501~600 | 49 | 35 | 11 | 4 | 1 | 0 | 1247.36 |
| 601~700 | 23 | 50 | 20 | 5 | 2 | 0 | 1583.36 |
| 701~800 | 45 | 42 | 11 | 2 | 0 | 0 | 1200.36 |
| 801~900 | 38 | 42 | 16 | 4 | 0 | 0 | 1396.08 |
| 901~1000 | 19 | 35 | 40 | 4 | 0 | 2 | 1876.84 |
| 1001~1100 | 21 | 49 | 26 | 3 | 1 | 0 | 1626.48 |
| 1101~1200 | 22 | 47 | 18 | 13 | 0 | 0 | 1726.12 |
| 1201~1300 | 18 | 55 | 23 | 4 | 0 | 0 | 1548.48 |
| 1301~1400 | 25 | 51 | 21 | 2 | 1 | 0 | 1539.04 |
| 1401~1500 | 33 | 59 | 7 | 1 | 0 | 0 | 1249.40 |
HM. Wie wär es damit. Mit fortschreitendem Lernen steigt die durchschnittliche Punktzahl allmählich an. Sogar eine Linie mit 3000 Punkten, die in 1000 zufälligen Spielen nicht einmal erreicht werden konnte, ist nach ein wenig Lernen so viel herausgekommen. Derzeit kann gesagt werden, dass "es Spuren des Lernens gibt".
Als ich AI-kuns Spiel nach dem Lernen sah, verspürte ich eine andere Absicht als zuvor (nun, die Menschen fanden einfach selbst Regelmäßigkeit). Es mag schwierig zu verstehen sein, ob es sich nur um die momentane Boardoberfläche handelt, aber ich werde sie vorstellen, weil ich die Szene ausgeschnitten habe.
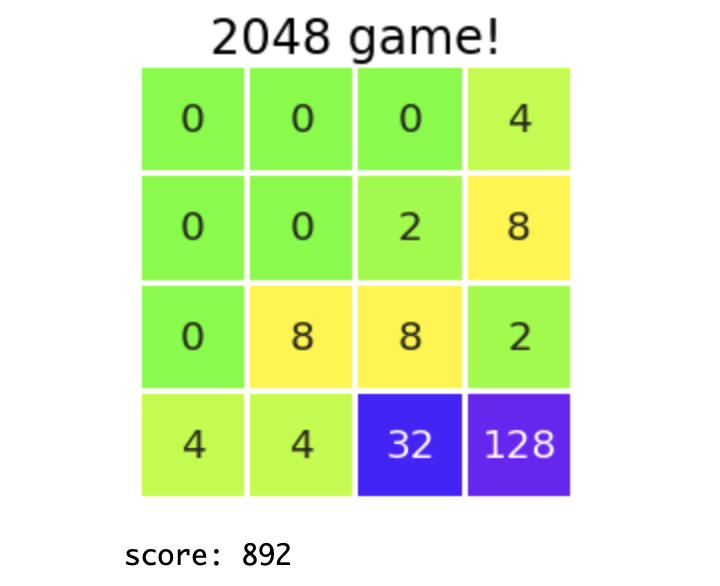
Es gibt viele Ecken und Kanten, aber die Richtlinie bestand darin, eine große Anzahl in der unteren rechten Ecke zu sammeln. Dies ist die gleiche Methode, die ich in "1-2. Tipps für dieses Spiel" eingeführt habe. Es ist interessant, dass ich diesen Trick lernen konnte, obwohl ich ihn von hier aus nicht implementiert habe: "Lerne, große Zahlen in den Ecken zu sammeln". Persönlich war ich ziemlich beeindruckt.
Die Realität ist jedoch, dass es immer noch schwierig ist, mehr als 4000 Punkte zu bekommen. Ich hörte 1500 Mal auf zu lernen, nur weil es nur eine Frage der Zeit war und wie Sie sehen, schien die Punktzahl nicht mehr zu wachsen. Eigentlich weiß ich es nicht, aber ich hatte das Gefühl, dass ich selbst dann keine große Verbesserung der Leistung erwarten könnte, wenn ich weiterhin den gleichen Lernalgorithmus wie er anwenden würde.
Der Grund, warum die Punktzahl in der zweiten Hälfte nicht gestiegen ist, sondern eher deprimiert zu sein schien, mag auf Pech zurückzuführen sein, aber ich hatte das Gefühl, dass sich die Leistung normal verschlechtert hatte. Um es etwas genauer auszudrücken, ich vermute, dass sich die Qualität des Inhalts der zum Lernen verwendeten Daten "Erfahrung" verschlechtert hat (das Advanced Board ist in einen Teufelskreis geraten, in dem das Lernen nicht so viel ist). Jedenfalls denke ich nicht, dass das Modell nach 1500 Trainings derzeit das stärkste ist.
Bei genauerer Betrachtung der obigen Tabelle wählte ich "das Modell am Ende des Lernens von 1200" als vorläufig stärkste KI. Nun, es sind 50 Schritte und 100 Schritte. Es war gut, es gefroren zu halten. Der Grund, warum ich mich für das Stärkste entschieden habe, ist, dass ich "einen Algorithmus implementieren werde, der einen besseren Zug zu wählen scheint, während das trainierte Modell so bleibt, wie es ist".
Deshalb werde ich das Modell zu diesem Zeitpunkt laden. Lassen wir dieses Kind sein Bestes geben.
2048.py
game1200 = Game()
q_value1200 = QValue()
q_value1200.model = load_model('forth_q_value1_1200.h5')
- Da ich das Modell gerade unter diesem Namen gespeichert habe, ist es normalerweise unmöglich, diesen Code fest einzufügen. In Zukunft ist es derzeit unmöglich zu reproduzieren, wenn Sie nicht in Ihrer eigenen Umgebung lernen und ein Modell erstellen. Es tut uns leid. Es ist mühsam, das trainierte Modell irgendwo zu teilen, aber ich frage mich, ob Nachfrage besteht ...
4-4. 1 Lies die Schergen
Es gibt kein Lernen in der Zukunft. Unter Beibehaltung des NN-Modells erstellen wir eine Aktionsrichtlinie, mit der wir das Spiel besser spielen können. (Es tut mir leid zu sagen, dass der Code vorbei ist. Es gibt noch.)
Bisher bestand die Verhaltensrichtlinie darin, "den Wert der Aktionsstatuswertfunktion für alle Aktionen zu berechnen und die Aktion auszuwählen, die sie maximiert" für einen bestimmten Status. Dies ist der Prozess, der von der Methode "get_action" ausgeführt wurde. Wir werden dies verbessern und einen Algorithmus implementieren, der "einen weiteren Zug im nächsten Zustand liest und den Zug auswählt, der am besten zu sein scheint". Fügen Sie zuerst den Code ein.
2048.py
def get_action_with_search(game, q_value):
update_q_values = []
for a in range(4):
board_backup = copy.deepcopy(game.board)
score_backup = game.score
state = game.board.tolist()
if(is_invalid_action(state, a)):
update_q_values.append(-10**10)
else:
r = game.move(a)
state_new = game.board.tolist()
_1, q_new, _2 = q_value.get_action(state_new)
update_q_values.append(r+q_new)
game.board = board_backup
game.score = score_backup
optimal_action = np.argmax(update_q_values)
if update_q_values[optimal_action]==-10**10: gameover = True
else: gameover = False
return optimal_action, gameover
Es ist eine Funktion, die die herkömmliche Methode "get_action", "get_action_with_search", ersetzt. Drehen Sie die for-Schleife für 4 Aktionen. Wählen Sie aus dem aktuellen Status zunächst einmal eine Aktion aus, um zum nächsten Status überzugehen. Halten Sie die Belohnung r zu diesem Zeitpunkt und betrachten Sie den nächsten Schritt aus dem nächsten Zustand. Dies ist "q_value.get_action (state_new)". Diese Methode gibt den Wert der Aktionsstatuswertfunktion für die beste Aktion als zweite Ausgabe zurück und nimmt ihn daher als "q_new" an. Hier ist "r + q_new" "die Summe der Belohnung, die durch Auswahl der Aktion a aus dem aktuellen Zustand und der Aktion aus dem Übergangsziel - dem Maximalwert der Zustandswertfunktion" erhalten wird. Der Mechanismus dieser Funktion besteht darin, diesen Wert für vier Aktionstypen a zu ermitteln und die Aktion auszuwählen, die ihn maximiert. (Gleichzeitig wird auch das Spiel über das Urteil durchgeführt.)
Da diese Richtlinie eher einen Zug als eine Metapher liest, ist zu erwarten, dass die Genauigkeit der Auswahl des besten Zugs höher ist als die herkömmliche Aktionsauswahl. Fügen Sie "get_action_with_search" auch in andere Funktionen ein.
`get_episode2`
2048.py
def get_episode2(game, q_value, epsilon):
episode = []
game.restart()
while(True):
state = game.board.tolist()
if np.random.random() < epsilon:
a = np.random.randint(4)
gameover = False
if(is_invalid_action(state, a)):
continue
else:
# a, _, gameover = q_value.get_action(state)
a, gameover = get_action_with_search(game, q_value)
if gameover:
state_new = None
r = 0
else:
r = game.move(a)
state_new = game.board.tolist()
episode.append((state, a, r, state_new))
if gameover: break
return episode
`show_sample2`
2048.py
def show_sample2(game, q_value):
epi = get_episode2(game, q_value, epsilon=0)
n = len(epi)
game = Game()
game.board = epi[0][0]
# show_board(game)
for i in range(1,n):
game.board = epi[i][0]
game.score += epi[i-1][2]
# time.sleep(0.2)
# clear_output(wait=True)
# show_board(game)
show_board(game)
print("score: {}".format(game.score))
return game.score
Das heißt, es ist genau das gleiche, außer dass die Aktionsauswahlfunktion wirklich ersetzt wird, also werde ich sie falten. Bitte schließen Sie es, sobald Sie den Inhalt sehen und verstehen.
Dies ist wirklich das Ende des Kratzens. Überprüfen Sie schließlich die Ergebnisse und beenden Sie!
4-5. Endergebnis
Ich werde Ihnen "q_value1200" bringen, der vor einiger Zeit als der vorläufigste Stärkste zertifiziert wurde. Ich bat dieses Kind, 100 Mal mit aller Kraft zu spielen, und analysierte es, als hätte es es in "4-3. Zug wiederholen" (ich werde es später veröffentlichen).
2048.py
scores1200 = []
for i in range(100):
scores1200.append(show_sample(game1200, q_value1200))
Darüber hinaus haben wir sie mit demselben Modell gebeten, 100 Mal mit dem Einhand-Look-Ahead-Algorithmus zu spielen.
2048.py
scores1200_2 = []
for i in range(100):
scores1200_2.append(show_sample2(game1200, q_value1200))
Organisieren Sie die Ergebnisse.
| Modell- | 0000~ | 1000~ | 2000~ | 3000~ | 4000~ | 5000~ | 6000~ | average |
|---|---|---|---|---|---|---|---|---|
| Normal | 15 | 63 | 17 | 5 | 0 | 0 | 0 | 1620.24 |
| 1 Vorausschau | 5 | 41 | 32 | 11 | 6 | 2 | 3 | 2388.40 |
Ja. Der herkömmliche Algorithmus hat die gleiche Leistung wie die Modelle, die wir zuvor gesehen haben, aber derjenige, der 1 Vorausschau eingeführt hat, hat die Leistung deutlich verbessert. glücklich. Insbesondere ist es gut, dass bei einem guten Durchfluss mit 3-mal mehr als 6000 Punkten das Potenzial besteht, eine hohe Punktzahl anzustreben. Die höchste Punktzahl von 100 war ** 6744 Punkte **. Das endgültige Brett zu diesem Zeitpunkt wird platziert.
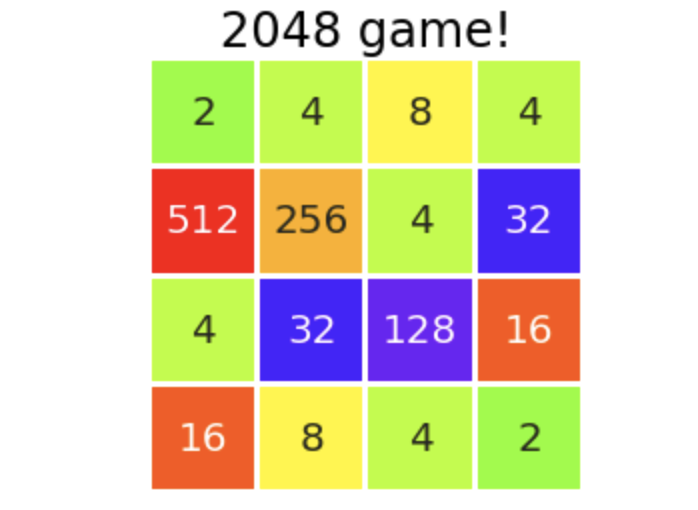
Es ist das letzte, also ist es gestört, aber es scheint, dass wir auf diesem Level spielen können, selbst wenn wir Menschen es tun, werden wir das Hündchen verlieren. Ich habe das Ziel, "eine höhere Punktzahl als ich selbst zu erreichen", das ich mir vor langer Zeit gesetzt habe, nicht erreicht, aber ich werde vorerst aufhören, es zu verbessern. Die Sommerferien sind vorbei. (Nein, mein Highscore von 69544 ist nicht zu stark ...?)
5. Schlussfolgerung
Danke für deine harte Arbeit! (Wenn Sie so weit lesen möchten, vielen Dank. Es tut mir leid, dass ich es lange auf meiner Seite geschrieben habe.
Rückblickend wollte ich die Leistung wirklich ein wenig verbessern. Es ist nicht schlecht für eine hohe Punktzahl, aber im Durchschnitt ist es nur so intelligent wie ein menschliches Erstspiel ...
Eigentlich habe ich darüber nachgedacht, den Verbesserungsplan von hier aus etwas genauer zu betrachten, aber es scheint, dass er zu lang sein wird und der Unterricht plötzlich ab morgen (derzeit 3:00 Uhr morgens) beginnt, also geht es darum, Notizen zu schreiben. Ich werde es in Zukunft an mich selbst weitergeben.
- Wiederholen Sie das Lernen einfach etwas mehr. (Ich denke, es ist ein bisschen schwierig, aber ...) --Versuchen Sie, den Wert von "epsilon" zu ändern. (Ich weiß nicht, ob es angehoben oder abgesenkt werden soll. Es kann sich jedoch lohnen, zu versuchen, ε im Verlauf des Lernens kleiner zu machen.)
- Erhöhen Sie die Länge von "Erfahrung" und "Beispiel"? Ich werde versuchen. (Mit fortschreitendem Lernen wird eine Episode länger. Die aktuelle Situation ist möglicherweise nicht sehr angemessen.)
- Versuchen Sie, die Karteneingabe für CNN in Kacheln zu unterteilen, anstatt sie zu gruppieren. (Ich denke, das ist ziemlich vielversprechend. Gegenwärtig kann NN möglicherweise nicht zwischen "2" - und "4" -Kacheln unterscheiden. Bedenken wie. Wahrscheinlich wird der Rechenaufwand zunehmen, aber dies bedeutet eindeutig für jede Kachel. Da sie unterschiedlich sind, sollten sie meines Erachtens separat eingegeben werden.)
- Schwache
batch_sizeundepochs. (Dies ist ein Mangel an Verständnis, aber es wirkt sich auf die Lerngenauigkeit aus ... Ich habe nicht das Gefühl, einen geeigneten Wert finden zu können.) - Lass uns lernen, wie du (der Autor) spielst. (Es scheint zeitlich ziemlich nervig zu sein, aber es scheint zu Ergebnissen zu führen. Ich höre, dass Shogi professionelles Schach lernt. Ich frage mich, ob es gut umgesetzt werden kann ...) ――Lesen und weiter spielen. (Nun, aber ich weiß nicht ... das Gefühl ist schlecht)
Ist es ungefähr so? Bestenfalls ist es ein Plan, an den ich aufgrund mangelnden Selbststudiums und Lernens denken kann. Ich würde mich sehr freuen, wenn Sie mir sagen könnten, dass ich das noch einmal versuchen sollte. (Im Gegenteil, bitte versuchen Sie diese Verbesserungspläne in meinem Namen.)
Wenn ich bisher alles ernsthaft zusammenstelle, bin ich sehr froh, dass Hoi Hoi-Fehler und neue Entdeckungen aus der Theorie hervorgegangen sind, die ich einmal verstehen wollte. Wenn Sie eines Tages kostenlos mit Kugeln recherchieren, können Sie einen Artikel wie diesen schreiben. Warten Sie also bitte auf die neue Arbeit. Wir können 2048 Spiel AI ein wenig mehr verfolgen.
Das ist es wirklich. Wenn Sie es interessant finden, tauchen Sie bitte tiefer in die Welt des verbesserten Lernens ein!
Das Ende
Ich habe das Ende der Sommerferien nur für einen Tag verpasst. Vergib mir.
Recommended Posts