[PYTHON] Bbox-Optimierung für benutzerdefinierte Datensätze [COCO-Format]
Bbox-Optimierung für benutzerdefinierte Datensätze
Wenn auf die Verwendung von Selbstdaten in maskrcnn usw. geschlossen wird, kann diese optimiert werden, wenn nur eine Kategorie vorhanden ist.
Zum Beispiel, wenn die Höhe und Breite vorbestimmt sind oder wenn die Größe ungefähr bekannt ist, bevor auf die Größe geschlossen wird, wenn der Ankerkasten erzeugt wird Wenn Sie etwas in der Nähe dieser Form erstellen, werden die Berechnungskosten und die Genauigkeit verbessert.
Wenn eine Ankerbox in der FPN-Ebene erstellt wird
Die Anfangsgröße ist (0,5,1,0,2,0) Das Seitenverhältnis beträgt (32, 64, 128, 256, 512)
ist. (Für Facebook / Maskrcnn-Benchmark)
Um abzuschätzen, welche Größe gut ist, werden die Fläche und das Seitenverhältnis unter Verwendung der Informationen des Polygons der mit Anmerkungen versehenen Maske in ein Histogramm umgewandelt.
import IPython
import os
import json
import random
import numpy as np
import requests
from io import BytesIO
from math import trunc
from PIL import Image as PILImage
from PIL import ImageDraw as PILImageDraw
import base64
import pandas as pd
import numpy as np
# Load the dataset json
class CocoDataset():
def __init__(self, annotation_path, image_dir):
self.annotation_path = annotation_path
self.image_dir = image_dir
self.colors = colors = ['blue', 'purple', 'red', 'green', 'orange', 'salmon', 'pink', 'gold',
'orchid', 'slateblue', 'limegreen', 'seagreen', 'darkgreen', 'olive',
'teal', 'aquamarine', 'steelblue', 'powderblue', 'dodgerblue', 'navy',
'magenta', 'sienna', 'maroon']
json_file = open(self.annotation_path)
self.coco = json.load(json_file)
json_file.close()
self.process_categories()
self.process_images()
self.process_segmentations()
def display_info(self):
print('Dataset Info:')
print('=============')
for key, item in self.info.items():
print(' {}: {}'.format(key, item))
requirements = [['description', str],
['url', str],
['version', str],
['year', int],
['contributor', str],
['date_created', str]]
for req, req_type in requirements:
if req not in self.info:
print('ERROR: {} is missing'.format(req))
elif type(self.info[req]) != req_type:
print('ERROR: {} should be type {}'.format(req, str(req_type)))
print('')
def display_licenses(self):
print('Licenses:')
print('=========')
requirements = [['id', int],
['url', str],
['name', str]]
for license in self.licenses:
for key, item in license.items():
print(' {}: {}'.format(key, item))
for req, req_type in requirements:
if req not in license:
print('ERROR: {} is missing'.format(req))
elif type(license[req]) != req_type:
print('ERROR: {} should be type {}'.format(req, str(req_type)))
print('')
print('')
def display_categories(self):
print('Categories:')
print('=========')
for sc_key, sc_val in self.super_categories.items():
print(' super_category: {}'.format(sc_key))
for cat_id in sc_val:
print(' id {}: {}'.format(cat_id, self.categories[cat_id]['name']))
print('')
def print_segmentation(self):
self.segmentations = {}
data = []
for segmentation in self.coco['annotations']:
area = segmentation['area']
print(area)
bbox = segmentation['bbox']
aspect = bbox[2]/bbox[3]
print(bbox)
print(aspect)
data.append([area,aspect])
df = pd.DataFrame(data)
df.to_csv('out.csv')
print(df)
annotation_path = "Pfad der kommentierten Coco-JSON-Datei"
image_dir = 'Pfad zu dem Ordner, in dem die Bilder gespeichert sind'
coco_dataset = CocoDataset(annotation_path, image_dir)
coco_dataset.print_segmentation()
Wenn Sie dies tun, erhalten Sie eine CSV mit der Fläche und dem Seitenverhältnis, wie unten gezeigt.

Danach werde ich ein Diagramm mit Excel erstellen.
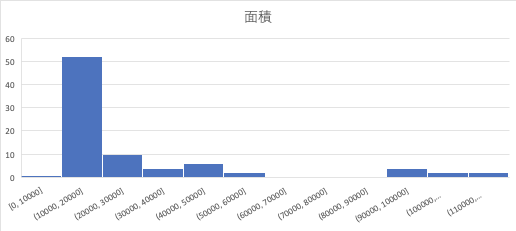
In diesem Fall können Sie sehen, dass die Fläche häufig um 10000 liegt.
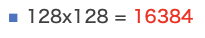 Diesmal weiß ich also, dass die Größe von 128 Ankern wichtig ist.
Diesmal weiß ich also, dass die Größe von 128 Ankern wichtig ist.
Sie können sehen, dass es schön wäre, wenn wir 256 oder 512 machen könnten, die größer als diese Größe sind. Im Gegenteil, es stellt sich heraus, dass die Größe von 64 fast nicht vorhanden ist, sodass sie gelöscht werden kann.
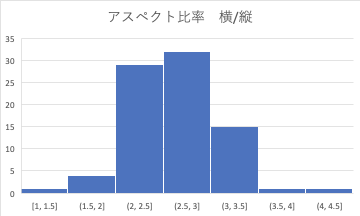
Wenn Sie das Seitenverhältnis auf die gleiche Weise betrachten, können Sie sehen, dass es diesmal nur sehr wenige Stellen gibt, an denen die Höhe: Breite 0,5 beträgt.
 Sie können sehen, dass Sie es herum einstellen sollten.
Sie können sehen, dass Sie es herum einstellen sollten.
Zusammenfassung
Mit der obigen Methode können Sie den optimalen Parameter für die Ankerbox finden, wenn es nur wenige Kategorien gibt. Ich hoffe es kann optimiert werden.