[PYTHON] Verstehen Sie die k-means-Methode
Einführung
Ich habe zusammengefasst, was ich über die k-means-Methode gelernt habe. Dies ist der grundlegendste Clustering-Algorithmus.
Referenz
Zum Verständnis der k-means-Methode habe ich mich auf Folgendes bezogen.
- Einführung in maschinelles Lernen für die Sprachverarbeitung (Natural Language Processing Series) Daiya Takamura (Autorin), Manabu Okumura (betreut) Herausgeber, Corona
- Essenz des maschinellen Lernens Koichi Kato (Autor) Herausgeber; SB Creative Co., Ltd.
k-means Methodenübersicht
Was ist die k-Mittelwert-Methode?
Die k-means-Methode ist ein Algorithmus, der die Daten zuerst in geeignete Cluster unterteilt und dann die Daten so anpasst, dass sie unter Verwendung des Durchschnitts der Cluster gut aufgeteilt werden. Die k-means-Methode (als k-Punkt-Mittelungsmethode bezeichnet), da es sich um einen Algorithmus handelt, der k Cluster beliebiger Bezeichnung erstellt.
k-bedeutet Methodenalgorithmus
Insbesondere folgt das k-Mittelwert-Verfahren den folgenden Schritten.
- Ordnen Sie jedem Punkt $ x_ {i} $ zufällig Cluster zu
- Berechnen Sie den Schwerpunkt für die jedem Cluster zugewiesenen Punkte
- Berechnen Sie für jeden Punkt den oben berechneten Abstand vom Schwerpunkt und weisen Sie ihn dem Cluster mit dem nächstgelegenen Abstand neu zu.
- Wiederholen Sie die Schritte 2 und 3, bis sich der zugewiesene Cluster nicht mehr ändert.
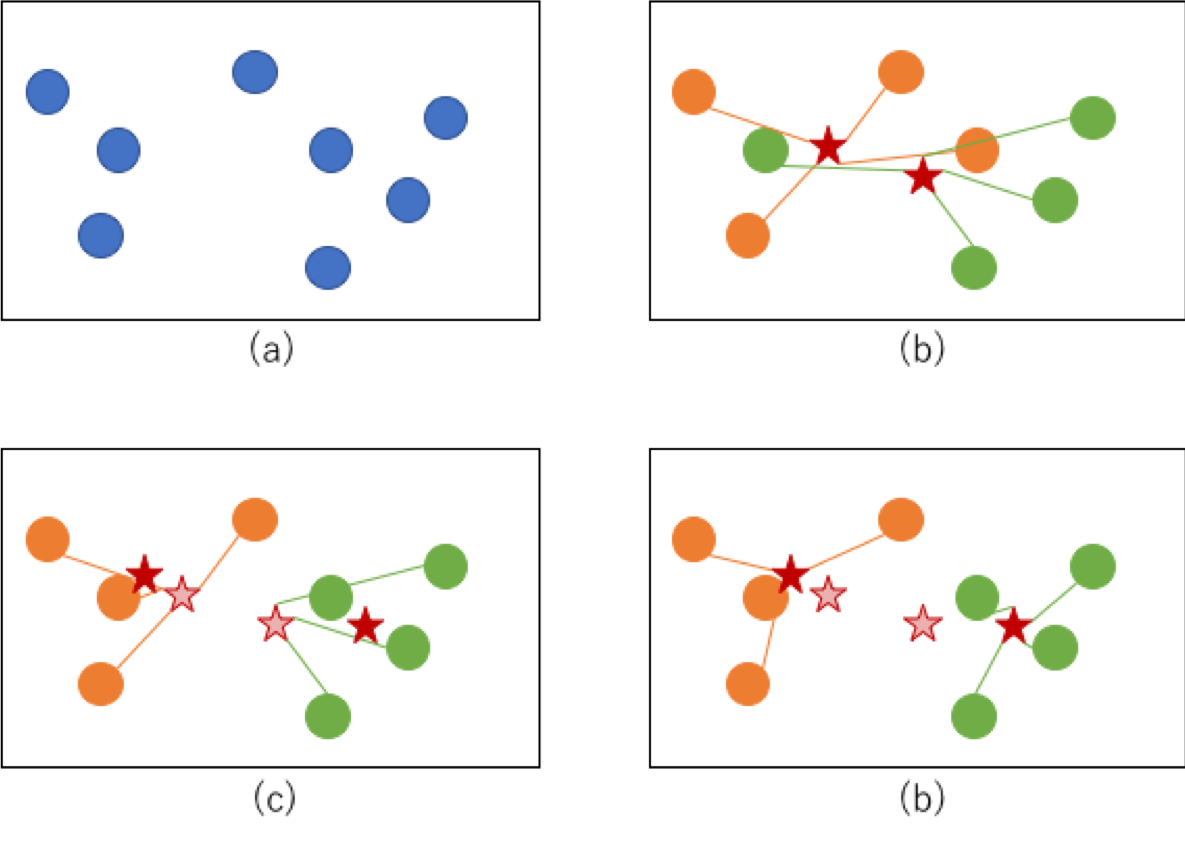
In der Abbildung ausgedrückt ist es ein Bild, dass der Cluster in der Reihenfolge (a) → (b) → (c) → (d) konvergiert, wie unten gezeigt. In Schritt (b) werden zunächst jedem Punkt Cluster zugewiesen und der Schwerpunkt berechnet (der Schwerpunkt wird durch den roten Stern angezeigt). In (c) wird der Cluster basierend auf dem Abstand von seinem Schwerpunkt neu zugewiesen. (Der neue Schwerpunkt wird durch den roten Stern und der alte Schwerpunkt durch den dünnen roten Stern angezeigt.) Wenn dieser Vorgang wiederholt wird und der Cluster auf eine Weise konvergiert, die sich nicht wie in (d) ändert, ist der Vorgang abgeschlossen.
Implementieren Sie die k-means-Methode
Implementierung der k-means-Methode ohne Verwendung der Bibliothek
Essenz des maschinellen Lernens Ein Memo wird in den Code geschrieben.
import numpy as np
import itertools
class KMeans:
def __init__(self, n_clusters, max_iter = 1000, random_seed = 0):
self.n_clusters = n_clusters
self.max_iter = max_iter
self.random_state = np.random.RandomState(random_seed)
def fit(self, X):
#Generieren Sie einen Generator, der wiederholt Beschriftungen für die angegebene Anzahl von Clustern erstellt (0).,1,2,0,1,2,0,1,2...(Mögen)
cycle = itertools.cycle(range(self.n_clusters))
#Weisen Sie jedem Datenpunkt zufällig Cluster-Beschriftungen zu
self.labels_ = np.fromiter(itertools.islice(cycle, X.shape[0]), dtype = np.int)
self.random_state.shuffle(self.labels_)
labels_prev = np.zeros(X.shape[0])
count = 0
self.cluster_centers_ = np.zeros((self.n_clusters, X.shape[1]))
#Endet, wenn sich der Cluster, zu dem jeder Datenpunkt gehört, nicht ändert oder eine bestimmte Anzahl von Wiederholungen überschreitet
while (not (self.labels_ == labels_prev).all() and count < self.max_iter):
#Berechnen Sie den Schwerpunkt jedes Clusters zu diesem Zeitpunkt
for i in range(self.n_clusters):
XX = X[self.labels_ == i, :]
self.cluster_centers_[i, :] = XX.mean(axis = 0)
#Runden Sie den Abstand zwischen jedem Datenpunkt und dem Schwerpunkt jedes Clusters ab
dist = ((X[:, :, np.newaxis] - self.cluster_centers_.T[np.newaxis, :, :]) ** 2).sum(axis = 1)
#Denken Sie an die vorherige Clusterbezeichnung. Wenn sich das vorherige Label und das Label nicht ändern, wird das Programm beendet.
labels_prev = self.labels_
#Weisen Sie als Ergebnis der Neuberechnung die Bezeichnung des Clusters zu, der der Entfernung am nächsten liegt
self.labels_ = dist.argmin(axis = 1)
count += 1
def predict(self, X):
dist = ((X[:, :, np.newaxis] - self.cluster_centers_.T[np.newaxis, :, :]) ** 2).sum(axis = 1)
labels = dist.argmin(axis = 1)
return labels
Überprüfung
Im Folgenden wird überprüft, ob mit diesem Algorithmus tatsächlich Clustering möglich ist.
import matplotlib.pyplot as plt
#Erstellen Sie einen geeigneten Datensatz
np.random.seed(0)
points1 = np.random.randn(80, 2)
points2 = np.random.randn(80, 2) + np.array([4,0])
points3 = np.random.randn(80, 2) + np.array([5,8])
points = np.r_[points1, points2, points3]
np.random.shuffle(points)
#Erstellen Sie ein Modell, das in drei Cluster unterteilt werden soll
model = KMeans(3)
model.fit(points)
print(model.labels_)
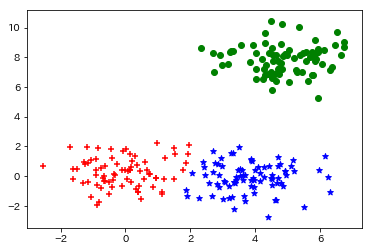
Dann sieht die Ausgabe so aus. Sie können sehen, dass die Beschriftungen den drei hervorragend zugeordnet sind.
[1 0 2 1 0 0 2 0 1 2 0 0 2 0 2 2 0 0 2 1 2 0 1 2 0 1 2 1 0 1 0 0 0 2 0 2 0
1 1 0 0 0 0 1 2 0 0 0 2 1 0 2 1 0 2 0 2 1 1 1 1 1 0 2 0 2 2 0 0 0 0 0 2 0
2 2 2 1 0 2 1 2 0 0 2 0 1 2 1 1 1 2 2 2 1 2 2 2 1 2 1 0 0 0 0 0 2 0 1 0 1
2 0 1 1 0 1 2 1 1 1 2 2 1 2 1 0 1 1 2 0 1 0 1 1 1 0 2 1 0 0 1 2 2 2 1 0 0
0 2 2 2 0 0 1 2 0 2 2 2 1 2 2 2 2 2 1 1 0 1 2 1 1 2 0 1 1 1 1 0 2 1 0 1 1
2 1 2 2 2 1 2 0 1 2 2 2 0 0 0 0 1 1 2 1 1 1 2 2 0 0 1 1 2 0 0 1 0 1 1 2 1
0 1 2 1 0 1 2 2 1 1 2 1 2 1 0 1 1 2]
Lassen Sie uns dies mit matplotlib veranschaulichen.
markers = ["+", "*", "o"]
color = ['r', 'b', 'g']
for i in range(3):
p = points[model.labels_ == i, :]
plt.scatter(p[:, 0], p[:, 1], marker = markers[i], color = color[i])
plt.show()
Hier ist die Ausgabe. Sie können sehen, dass das Clustering problemlos abgeschlossen ist.
 Next
Diese k-means-Methode hat das Problem, dass sich die Genauigkeit in Abhängigkeit von der Zuordnung des ersten zufälligen Clusters ändert. Ich möchte die Implementierung von k-means ++ in Frage stellen, mit der versucht wird, dieses Problem zu lösen.
Next
Diese k-means-Methode hat das Problem, dass sich die Genauigkeit in Abhängigkeit von der Zuordnung des ersten zufälligen Clusters ändert. Ich möchte die Implementierung von k-means ++ in Frage stellen, mit der versucht wird, dieses Problem zu lösen.