Asynchrone Verarbeitung in Python: Asyncio-Reverse-Referenz
Es gab nicht viele praktische Beispiele für Pythons Asyncio und Async / await, daher habe ich basierend auf den gesammelten Informationen eine beispielbasierte umgekehrte Referenz erstellt. Es ist jedoch ein Rätsel, was wahr ist, da es in diesem Bereich wirklich keine Informationen gibt. Wenn Sie also Informationen haben, können Sie sich gerne an uns wenden.
Die diesmal vorgestellten Beispiele sind in der folgenden Zusammenfassung zusammengefasst. Ich hoffe, Sie können sich bei der Implementierung darauf beziehen.
icoxfog417/asyncio_examples.py
Einführung
Python verfügt über drei Pakete, die für die parallele Verarbeitung verwendet werden können: "Threading", "Multiprocessing" und "Asyncio". Schauen wir uns zunächst diese Unterschiede an.
Der Unterschied zwischen diesen Paketen entspricht direkt dem Unterschied zwischen "Multi-Thread", "Multi-Prozess" und "Nicht-Blockieren". Zunächst zum Unterschied zwischen Multithread und Multiprozess.
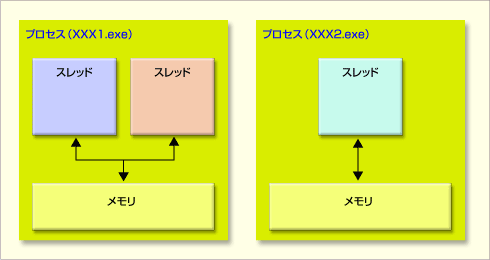 In solchen Fällen wird der 1. Multithread verwendet (1/2)
In solchen Fällen wird der 1. Multithread verwendet (1/2)
Ein Prozess ist eine Verarbeitungseinheit mit eigenem Speicher. Bei einer sogenannten Multi-Core-CPU kann dieser Prozess jedem Kern zugeordnet und effizient verarbeitet werden (obwohl es nicht unmöglich ist, mehr Prozesse als die Anzahl der Kerne zu erstellen). Es wird ineffizient). Ein Thread ist eine Verarbeitungseinheit innerhalb eines Prozesses, und Threads zwischen denselben Prozessen teilen sich den Speicher.
Non-Blocking wurde geboren, um die Schwächen des Multithreading zu überwinden. Es gibt einen Unterschied in der Methode zur Verarbeitung einer großen Anzahl von Anforderungen (Referenz: Einführung in Node.js).
- Multi-Thread: Erstellen Sie Threads für jede Anfrage-> Wenn es viele Anfragen gibt, wird es schwierig sein (C10K-Problem)
- Nicht blockierend: Behandeln Sie mehrere Anforderungen in einem Thread
- Wenn Sie eine bestimmte Anfrage bisher bearbeitet haben, fahren Sie mit der Verarbeitung anderer Anfragen fort. Wenn diese beendet ist, verarbeiten Sie sie so, als wäre es das Original ...
Daher können Multi-Thread und Nicht-Blocking nicht zusammenleben, da sie Threads unterschiedlich behandeln, aber beide können (theoretisch) mit Multi-Prozess kombiniert werden.
Asyncio und async / await, die dieses Mal behandelt werden, sind Funktionen zum Implementieren einer nicht blockierenden Verarbeitung. Bitte beachten Sie diesen Punkt zuerst.
Grundlegend: So schreiben Sie einen nicht blockierenden Prozess
Zunächst werde ich vorstellen, wie eine nicht blockierende Verarbeitung auf der Basis von Asyncio geschrieben wird. Darüber hinaus ist diese nicht blockierende Verarbeitung in den folgenden Fällen effektiv und anwendbar.
- Es gibt eine starke Verarbeitung, die einen Engpass darstellen kann
- Der Prozess findet in großer Anzahl statt
- Die Reihenfolge, in der die Prozesse abgeschlossen sind, spielt keine Rolle
Insbesondere denke ich, dass die Seitenerfassung von der URL und die Datenerfassung von der DB anwendbar sind, aber bitte beachten Sie, dass "die Reihenfolge des Abschlusses der Verarbeitung keine Rolle spielt".
Das Folgende ist ein einfaches Beispiel (extrahiert aus dem ersten Beispiel).
import asyncio
Seconds = [
("first", 5),
("second", 0),
("third", 3)
]
async def sleeping(order, seconds, hook=None):
await asyncio.sleep(seconds)
if hook:
hook(order)
return order
async def basic_async():
# the order of result is nonsequential (not depends on order, even sleeping time)
for s in Seconds:
r = await sleeping(*s)
print("{0} is finished.".format(r))
return True
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(basic_async())
Der Kern des Prozesses ist basic_async. Hier wird der als "schlafen" bezeichnete Vorgang (im Bild entspricht dies dem Vorgang "schwer, aber die Verarbeitungsreihenfolge spielt keine Rolle") wiederholt.
Die von loop = asyncio.get_event_loop () erzeugte Ereignisschleife ist für die Ausführung des Prozesses verantwortlich, und dies ist der "nicht blockierende Thread". Grundsätzlich wird hier die Funktion (asyncio.coroutine) "async" übergeben und verarbeitet ("loop.run_until_complete (basic_async ())").
Wenn Sie "r = Warte auf Schlaf (* s)" betrachten, wartet es darauf, dass die Verarbeitung mit "Warten" abgeschlossen wird. Wenn ich das allein betrachte, denke ich, dass es dasselbe ist wie eine normale for-Anweisung, da es darauf wartet, dass die Verarbeitung jedes Mal abgeschlossen wird, und tatsächlich ist dies in diesem Beispiel der Fall. Wie Sie sehen können, sind die Ergebnisse immer in der folgenden Reihenfolge:
first is finished.
second is finished.
third is finished.
Ist es nicht asynchron! Dieses "Warten" funktioniert jedoch tatsächlich bei paralleler Verarbeitung, wie unten beschrieben.
Wenn "Warten" erledigt ist, beginnt etwas Schweres. Wenn Sie diesen Punkt erreichen, startet der Thread "andere Dinge in der Ereignisschleife". Wenn die von await durchgeführte Verarbeitung abgeschlossen ist, kehrt sie zur Aufgabe zurück und setzt die Verarbeitung fort.
Wenn Sie sie daher wie unten gezeigt parallel verarbeiten, können Sie sehen, dass jede Aufgabe ausgeführt wird (seien Sie vorsichtig, wenn Sie das folgende Skript ausführen, da es nicht wie durch "run_forever" angegeben endet).
async def basic_async(num):
# the order of result is nonsequential (not depends on order, even sleeping time)
for s in Seconds:
r = await sleeping(*s)
print("{0}'s {1} is finished.".format(num, r))
return True
if __name__ == "__main__":
loop = asyncio.get_event_loop()
# make two tasks in event loop
asyncio.ensure_future(basic_async(1))
asyncio.ensure_future(basic_async(2))
loop.run_forever()
Wenn Sie sich das Ausführungsergebnis ansehen, können Sie sehen, dass wenn 1 ausgeführt wird und "Warten" erreicht ist, 2 gestartet wird, wenn 1 von "Warten" zurückkehrt, es zu 1 zurückkehrt und fortfährt und so weiter. ..
1's first is finished.
2's first is finished.
1's second is finished.
2's second is finished.
1's third is finished.
2's third is finished.
Wenn sich also nur eine Coroutine in der Ereignisschleife befindet, hat async / await keine Auswirkung. Dies ist wichtig und muss beachtet werden.
Lassen Sie uns am Ende der Grundlagen die verwirrenden asynchronen Objekte bereinigen.
coroutine: Der Rückgabewert der asynchronen Funktion istcoroutine.- Wenn es eine Funktion "async def hoge (): xxx" gibt, ist "hoge ()" ein "coroutine" -Objekt, anstatt sofort eine Rückgabe zurückzugeben.
Future: Zurückgestelltes Objekt in jQuery- Ausführungsergebnisse können mit
set_resultundset_exceptionweitergegeben werden Task- Eine Unterklasse von "Future", die die Ausführung verwaltet. Ich schaffe es nicht direkt (oder besser gesagt, ich sollte es nicht), also kümmert es mich nicht wirklich.
Es handelt sich tatsächlich um "Coroutine" oder "Future", und die meisten Funktionen unterstützen beide. coroutine kann mit asyncio.ensure_future ( create_task in Task konvertiert werden. Es gibt auch eine Methode namens create_task, die eine Aufgabe sein kann, aber es gibt grundsätzlich keinen Unterschied zwischen diesen beiden Methoden (http://stackoverflow.com/questions/33980086/whats-the-difference-between-loop). -create-task-asyncio-async-sure-future-and)).
Lassen Sie uns nun sehen, wie mehrere Aufgaben in der Ereignisschleife tatsächlich behandelt werden.
Ich möchte parallel verarbeiten (feste Länge)
Wenn die Anzahl der Prozesse, die Sie parallel ausführen möchten, im Voraus festgelegt wurde, können Sie alle gleichzeitig parallel verarbeiten. Die dafür bereitgestellten Funktionen sind "asyncio.gather" und "asyncio.wait".
Erstens das Muster von "asyncio.gather"
async def parallel_by_gather():
# execute by parallel
def notify(order):
print(order + " has just finished.")
cors = [sleeping(s[0], s[1], hook=notify) for s in Seconds]
results = await asyncio.gather(*cors)
return results
if __name__ == "__main__":
loop = asyncio.get_event_loop()
results = loop.run_until_complete(parallel_by_gather())
for r in results:
print("asyncio.gather result: {0}".format(r))
Dieses asyncio.gather hat wie üblich eine unbestimmte Ausführungsreihenfolge, aber es hat die nette Eigenschaft, dass es die verarbeiteten Ergebnisse in der Reihenfolge zurückgibt, in der sie übergeben wurden ([hier](http: //docs.python.). jp / 3 / library / asyncio-task.html # asyncio.gather) Siehe). Dies ist nützlich, wenn Sie die Reihenfolge des ursprünglichen Arrays im Ausführungsergebnis beibehalten möchten, während Sie die asynchrone Verarbeitung ausführen.
- Wenn Sie das Wörterbuchsystem verwenden, beachten Sie bitte, dass die Reihenfolge des Wörterbuchs selbst unbestimmt ist (ich bin festgefahren). Im Fall von Dictionary kann nicht garantiert werden, dass die Schlüssel in der Reihenfolge der Definition angezeigt werden.
Die andere ist, "asyncio.wait" zu verwenden.
async def parallel_by_wait():
# execute by parallel
def notify(order):
print(order + " has just finished.")
cors = [sleeping(s[0], s[1], hook=notify) for s in Seconds]
done, pending = await asyncio.wait(cors)
return done, pending
if __name__ == "__main__":
loop = asyncio.get_event_loop()
done, pending = loop.run_until_complete(parallel_by_wait())
for d in done:
dr = d.result()
print("asyncio.wait result: {0}".format(dr))
Das Ergebnis von "Warten" wird mit "Fertig" und "Ausstehend" zurückgegeben. Beachten Sie, dass Sie das Ergebnis beim Abrufen mit result () abrufen müssen (wenn während der Verarbeitung eine Ausnahme auftritt, wird die Ausnahme übersprungen, wenn result () ausgeführt wird).
Ich möchte parallel verarbeiten (unbestimmte Länge)
Ich wusste, wie viele parallele Prozesse früher ausgeführt werden mussten, aber die Länge ist möglicherweise nicht festgelegt (Stream usw.), wenn Anforderungen nacheinander eingehen.
In einem solchen Fall ist die Verarbeitung mit Queue möglich.
async def queue_execution(arg_urls, callback, parallel=2):
loop = asyncio.get_event_loop()
queue = asyncio.Queue()
for u in arg_urls:
queue.put_nowait(u)
async def fetch(q):
while not q.empty():
u = await q.get()
future = loop.run_in_executor(None, requests.get, u)
future.add_done_callback(callback)
await future
tasks = [fetch(queue) for i in range(parallel)]
return await asyncio.wait(tasks)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
results = []
def store_result(f):
results.append(f.result())
loop.run_until_complete(queue_execution([
"http://www.google.com",
"http://www.yahoo.com",
"https://github.com/"
], store_result))
for r in results:
print("queue execution: {0}".format(r.url))
Dies ist eine feste Länge und übergibt eine Reihe von URLs, daher verwende ich Queue nicht sehr oft ... Der Punkt ist, eine "Warteschlange" mit "asyncio.Queue" zu erstellen und immer mehr Verarbeitungsziele mit "put_nowait" darin zu platzieren (wenn Sie die Größe der Warteschlange festlegen, verwenden Sie "put", um eine Warteschlange zu erstellen. Sie können blockieren, bis es kostenlos ist).
async def fetch wird weiter verarbeitet, es sei denn , queue ist leer. Dieses Mal führen wir "fetch" parallel aus, so viele wie "parallel". Es sieht also so aus, als ob eine "Warteschlange" von zwei "Coroutinen" gemeinsam genutzt wird.
Beachten Sie, dass das Abrufen der Python-URL (urllib.request.urlopen) den Prozess blockiert. [Hier](http://stackoverflow.com/questions/22190403/how-could-i-use-requests- Ich habe versucht, es mit Bezug auf in-asyncio zu implementieren), aber es lief nicht parallel (wahrscheinlich muss ich "warten", nachdem ich alle "run_in_executor" beendet habe?). Wenn Sie parallel arbeiten möchten, ist es sicherer, aiohttp zu verwenden.
Wie in loop.run_in_executor (None, request.get, u) gezeigt, können Sie jedoch [Future] normale Funktionen mit run_in_executor [http://docs.python.jp/3/" ausführen. library / asyncio-eventloop.html # asyncio.BaseEventLoop.run_in_executor) kann auch in anderen Fällen als Technik verwendet werden.
Ich möchte die Anzahl der Ausführungen parallel steuern
Insbesondere beim Scraping usw. ist es sehr schwierig, die URLs von 1000 Inhalten auf einer bestimmten Site gleichzeitig zu verarbeiten. Daher möchten Sie möglicherweise die Anzahl der parallel ausgeführten Prozesse steuern. Das zu diesem Zeitpunkt verwendete ist "Semaphor".
async def limited_parallel(limit=3):
sem = asyncio.Semaphore(limit)
# function want to limit the number of parallel
async def limited_sleep(num):
with await sem:
return await sleeping(str(num), num)
import random
tasks = [limited_sleep(random.randint(0, 3)) for i in range(9)]
return await asyncio.wait(tasks)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
done, pending = loop.run_until_complete(limited_parallel())
for d in done:
print("limited parallel: {0}".format(d.result()))
Es ist einfach zu bedienen. Warten Sie einfach, bis Semaphore von with await sem in der asynchronen Funktion verfügbar ist, mit der Sie die Anzahl der gleichzeitigen Ausführungen steuern möchten.
Ich möchte eine Rückrufverarbeitung durchführen, nachdem die asynchrone Verarbeitung abgeschlossen ist
Wenn Sie nach Abschluss des Prozesses einen bestimmten Prozess ausführen möchten, können Sie "add_done_callback" in "asyncio.Future" verwenden. Im Folgenden wird "coroutine" von "asyncio.ensure_future" in "Task" konvertiert und der empfangene Rückruf hinzugefügt.
async def future_callback(callback):
futures = []
for s in Seconds:
cor = sleeping(*s)
f = asyncio.ensure_future(cor)
f.add_done_callback(callback)
futures.append(f)
await asyncio.wait(futures)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
results = []
def store_result(f):
results.append(f.result())
loop.run_until_complete(future_callback(store_result))
for r in results:
print("future callback: {0}".format(r))
Wenn ich es tun möchte, kann ich dem Rückruf mehr Zukunft hinzufügen, aber ich denke, es ist ein kompliziertes Rätsel und ich denke, es ist besser aufzuhören (ich habe ein paar Stunden kostbaren Urlaub verschwendet).
Ich möchte einen Iterator erstellen, der asynchron verarbeitet
Wenn Sie die Verarbeitung als Iterator nicht blockierend streamen möchten, z. B. nacheinander aus der Datenbank lesen, können Sie Ihren eigenen Iterator erstellen.
def get_async_iterator(arg_urls):
class AsyncIterator():
def __init__(self, urls):
self.urls = iter(urls)
self.__loop = None
def __aiter__(self):
self.__loop = asyncio.get_event_loop()
return self
async def __anext__(self):
try:
u = next(self.urls)
future = self.__loop.run_in_executor(None, requests.get, u)
resp = await future
except StopIteration:
raise StopAsyncIteration
return resp
return AsyncIterator(arg_urls)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
async def async_fetch(urls):
ai = get_async_iterator(urls)
async for resp in ai:
print(resp.url)
loop.run_until_complete(async_fetch([
"http://www.google.com",
"http://www.yahoo.com",
"https://github.com/"
]))
Die Punkte sind "aiter" und "anext", die asynchrone Version des regulären Iterators. Sie können await in anext verwenden. Beachten Sie bei der Verwendung, dass es mit "async for resp in ai" und "async for" iteriert wird.
Ich möchte eine nicht blockierende Verarbeitung in mehreren Prozessen durchführen (unbestätigt).
Ganz am Anfang habe ich gesagt, dass Multi-Prozess und Non-Blocking (theoretisch) zusammenleben können, aber wie geht das? Ich kenne den genauen Punkt nicht, da es ein Rätsel ist, wie zu überprüfen ist, ob es sich um mehrere Prozesse + nicht blockierende handelt, aber ich werde es vorerst veröffentlichen.
import asyncio
import concurrent.futures
loop = asyncio.get_event_loop()
executor = concurrent.futures.ProcessPoolExecutor()
loop.set_default_executor(executor)
Quelle
- Cleanly shutdown the IO loop when using an executor
- How to properly create and run concurrent tasks using python's asyncio module?
Der Standard-Executor verwendet ThreadPoolExecutor, daher werde ich dies in ProcessPoolExecutor ändern. Dies führt wahrscheinlich zu einer nicht blockierenden Verarbeitung von Prozess zu Prozess. Wie bei der Mehrfachverarbeitung können Sie von der Parallelverarbeitung profitieren, indem Sie nur die CPU-Kerne verteilen.
Umgekehrt ist es für einen Prozess jedoch nicht effizient, mehr als die Anzahl der CPU-Kerne zu duplizieren, und es ist nicht geeignet, wenn Sie viele URLs parallel erfassen möchten (dies ist besser für Threads geeignet). Ich denke, Sie sollten es je nach Situation richtig verwenden. Wenn Sie Angst haben, den Standardwert festzulegen, können Sie ihn nur verwenden, wenn Sie eine bestimmte Funktion mit [run_in_executor] ausführen (http://docs.python.jp/3/library/asyncio-eventloop.html#executor). Ich denke.
Unten finden Sie eine Prozessversion des Warteschlangenbeispiels (ich denke, das funktioniert am besten). Die print_num ist out, weil ein Fehler aufgetreten ist, wenn es sich nicht um eine globale Funktion handelt (verwenden Sie pickle, um den Prozess zu duplizieren?).
def print_num(num):
print(num)
async def async_by_process():
executor = concurrent.futures.ProcessPoolExecutor()
queue = asyncio.Queue()
for i in range(10):
queue.put_nowait(i)
async def proc(q):
while not q.empty():
i = await q.get()
future = loop.run_in_executor(executor, print_num, i)
await future
tasks = [proc(queue) for i in range(4)] # 4 = number of cpu core
return await asyncio.wait(tasks)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(async_by_process())
Das Obige ist eine Zusammenfassung von Pythons Asyncio.
Recommended Posts