[PYTHON] Identifizierung wichtiger Zeichen-Itemgetter und TfidfVectorizer-
Auslösen
Mit dem Artikel Getter, der in Code of 1st Place im Mercari-Wettbewerb erschien. Ich habe TfidfVectorizer nicht wirklich verstanden.
Zusammenfassung
itemgetter → Jedes Element kann aus iterablen Elementen extrahiert werden (Objekte, in die für Anweisungen wie Listen und Zeichenfolgen geschrieben werden kann).
TfidfVectorizer → Wird bei der Berechnung wichtiger Zeichen in einem Satz verwendet. Je höher die Punktzahl, desto häufiger wird das Dokument angezeigt, was darauf hinweist, dass die Zeichen in anderen Dokumenten mit geringerer Wahrscheinlichkeit angezeigt werden.
itemgetter
Das aufrufbare Objekt, das das name-Element erhält, wird in der ersten Zeile zurückgegeben. In der zweiten Zeile wird nur das Namenselement extrahiert.
qiita.rb
from operator import itemgetter
item=itemgetter("name")
item({'name':['taro','yamada'], 'age':[5,6]})

TfidfVectorizer
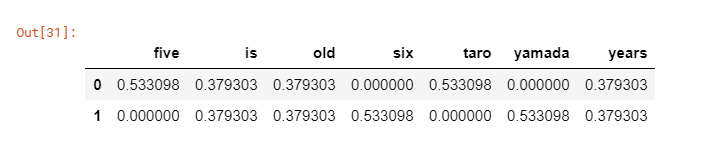
Es wird bei der Berechnung von [TF-IDF] verwendet (https://qiita.com/AwaJ/items/5937665d5a4152cc24cf "Qiita"). TF-IDF wird verwendet, um wichtige Zeichenfolgen in einem Dokument zu identifizieren. Im Wettbewerb werden damit die Markennamen der ausgestellten Produkte quantifiziert. Im folgenden Beispiel werden fünf, sechs, Taro und Yamada häufig und nicht in anderen Dokumenten angezeigt, sodass die Punktzahl hoch ist.
qiita.rb
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer as Tfidf
sample_string= np.array(['taro is five years old','yamada is six years old'])
tfidf=Tfidf(max_features=100000, token_pattern='\w+')
x=tfidf.fit_transform(sample_string)
pd.DataFrame(y.toarray(), columns=tfidf.get_feature_names())

Kombinierte Verwendung von Itemgetter, TfidfVectorizer, Pipeline
Es leitet eine Instanz von itemgetter ("name") und eine Instanz von Tfidf weiter. Nachdem das Namenselement durch .transform extrahiert wurde, wird die Wichtigkeit des Namenselements berechnet. Klicken Sie hier für die Pipeline
qiita.rb
from sklearn.pipeline import make_pipeline, make_union, Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer as Tfidf
from operator import itemgetter
from sklearn.preprocessing import FunctionTransformer
import pandas as pd
def on_field(f: str, *vec) -> Pipeline:
return make_pipeline(FunctionTransformer(itemgetter(f), validate=False), *vec)
df=pd.DataFrame({'string':['taro is five years old','yamada is six years old'], 'age':[5,6]})
Pipeline=on_field('string', Tfidf(max_features=100000, token_pattern='\w+'))
Pipeline.fit(df)
data=Pipeline.transform(df)
pd.DataFrame(data.toarray(),columns=tfidf.get_feature_names())
Recommended Posts