[PYTHON] Trainingsdaten und Testdaten (Was sind X_train und y_train?) ①
Diesmal im betreuten Lernen Beschreibt Trainingsdaten und Testdaten.
■ Trainingsdaten und Testdaten
Trainingsdaten: Daten zum Erstellen von Modellformeln (Formeln, die Datenrelevanz darstellen) Testdaten: Daten, um zu überprüfen, wie genau die erstellte Formel ist
Selbst wenn Sie die Relevanz von Daten durch einen Ausdruck ausdrücken können, wäre es ein Problem, wenn Sie nicht über die Daten verfügen, um sie zu testen.
Lassen Sie mich nun anhand eines einfachen konkreten Beispiels erklären.
Zum Beispiel, wenn Sie die folgenden Daten haben:
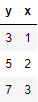 Teilen Sie nun die Daten in dieser Tabelle wie folgt auf.
Teilen Sie nun die Daten in dieser Tabelle wie folgt auf.
Trainingsdaten
 Testdaten
Testdaten
 Zu diesem Zeitpunkt möchte ich zuerst die Relevanz der Daten ermitteln.
Betrachten Sie Kandidaten für y- und x-Formeln (Modellformeln) aus Trainingsdaten.
Zu diesem Zeitpunkt möchte ich zuerst die Relevanz der Daten ermitteln.
Betrachten Sie Kandidaten für y- und x-Formeln (Modellformeln) aus Trainingsdaten.
Kandidat 1: $ y = 3x $ Kandidat 2: $ y = 2x + 1 $
Ich habe eine Modellformel aus den Trainingsdaten erstellt. Dies allein sagt uns jedoch nicht, ob diese Formel wirklich gilt. Deshalb haben wir Testdaten zur Verifizierung.
Überprüfen Sie, ob die folgenden Daten für die erstellte Modellformel gelten.
Sie können dies überprüfen, indem Sie x in den Testdaten in die Modellformel einsetzen und prüfen, ob es wirklich y ist.
Kandidat 1: $ y = 3x = 3 \ times3 = 9 $
Kandidat 2: $ y = 2x + 1 = 2 \ times3 + 1 = 7 $
Richtige Antwort: $ y = 7 $
Aus diesem Grund in Bezug auf die diesmal vorbereiteten Daten Es stellt sich heraus, dass Kandidat 2 genauer ist als Kandidat 1.
Auf diese Weise wird beim maschinellen Lernen die Relevanz von Daten aus Trainingsdaten ermittelt (Erstellen einer Modellformel). Wir haben einen Mechanismus, um zu überprüfen, ob die Testdaten tatsächlich korrekt sind.
■ Wenden Sie X_train, y_train an
Was genau sind X_train, y_train, X_test, y_test?
Zug: Trainingsdaten (Abkürzung für Training) Test: Testdaten (Daten, die die Modellformel verifizieren)
Wenn es auf die diesmal vorbereiteten Daten angewendet wird, sieht es so aus.
Trainingsdaten
 Testdaten
Testdaten
 Betrachten Sie nach wie vor die Modellformel aus den Trainingsdaten.
Betrachten Sie nach wie vor die Modellformel aus den Trainingsdaten.
Kandidat 1: $ y = 3x $ Kandidat 2: $ y = 2x + 1 $
Dies vervollständigt die Modellformel. Danach werden wir anhand von Testdaten überprüfen, wie genau diese sind.
Setzen Sie zuvor x der Testdaten in die Modellformel ein, um den vorhergesagten Wert y zu erhalten. Ich habe überprüft, ob es mit dem tatsächlichen y übereinstimmt.
Der zu diesem Zeitpunkt vorhergesagte Wert wird als y_pred ausgedrückt. (Vorhersagen)
Testdaten
Kandidat 1: $ y_ {pred} = 3x_ {test} = 3 \ times3 = 9 $
Kandidat 2: $ y_ {pred} = 2x_ {test} + 1 = 2 \ times3 + 1 = 7 $
Richtige Antwort: $ y_ {test} = 7 $
Daher wurde in der Modellformel diesmal erstellt Es stellt sich heraus, dass Kandidat 2 genauer ist.
Mit anderen Worten, es ist unten zusammengefasst.
X_train, y_train: Daten zum Erstellen von Modellausdrücken (Ausdrücke von Datenrelevanz) X_test: Daten zum Zuweisen zum Modellausdruck und zum Geben Ihrer eigenen Antwort y_pred y_test: Richtig korrekte Antwortdaten (wie die Modellantwort der Mathematik) für die Beantwortung mit Ihrem eigenen y_pred
Es ist ein wenig verwirrend, dass nur y_test als Modellantwort behandelt wird, nicht wahr?
Beim überwachten Lernen (mit Testdaten), grundsätzlich basierend auf dieser Idee Wir erstellen und verifizieren verschiedene Modellformeln.
Recommended Posts